






问题
根据导师的要求复原师兄的深度学习网络模型,之前把师兄的模型写了进去,结果训练后,训练loss一直处于10.6附近不下降,测试准确率一直为0%
(PS:loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD() | torch.optim.Adam())
第一次尝试
重写了一遍系统,用LeNet和AlexNet练练手,结果还是同样的问题。诡异的是,把师兄提供的数据集输入到LeNet和AlexNet中,输出的训练损失还是10.6,准确率0%。
"""标准的LeNet-5网络结构:"""
LeNet(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): AvgPool2d(kernel_size=2, stride=2, padding=0)
(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(4): ReLU()
(5): AvgPool2d(kernel_size=2, stride=2, padding=0)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=576, out_features=120, bias=True)
(8): ReLU()
(9): Linear(in_features=120, out_features=84, bias=True)
(10): ReLU()
(11): Linear(in_features=84, out_features=200, bias=True)
)
"""所处设备:cpu"""
第二次尝试
看到了AI柠檬的这篇文章
深度学习:欠拟合问题的几种解决方案
决定测试一下模型的拟合能力。于是对数据的供给动了点手脚,每次数据迭代器给的数据都是全部的数据集,并且不打乱,以此来看它是不是真的有在好好学习。
对着Debug界面看了一下午,结论是,这个模型根本不学习。我记录下每个batch的训练loss,losses两两之间相差不超过1e-4,测试的准确度自然也是0%。
我想了一下,应该不是模型的欠拟合问题。
第三次尝试
于是我决定在第三次尝试的前提下,跟踪loss的梯度,结果发现loss的梯度一直是None。
在网上逛了很多帖子,以为是自己写的网络层出了问题。因为很多帖子说不可以使用 net = net.type().to()这样的等式
# 据传应该这样写
net = net.type()
net = net.to()
也不能在网络中进行reshape()
更不能在训练函数中使用中间变量
# 很多帖子说不能这样写
pred = net(X)
l = loss(pred, y)
# 他们说应该这样写
l = loss(net(X), y)
于是我一一照做,把网络中自定义的Reshape()、DualOutput()层屏蔽掉之后,输出的训练损失还是10.6,准确率0%。
第四次尝试
打算跟踪一下每次backward()之后各层的梯度变化,学了一下Tensorboard(PyTorch下的Tensorboard 使用)后发现不好用,代码要加的东西还蛮多的。了解到的函数接口包括add_scalar()和add_graph()。前者只能跟踪标量,后者根据网络画出来的图没什么参考价值。这个结果甚至还要用命令行读取文件,在Web端查看,很麻烦。于是学了一下pytorch的hook机制(Pytorch hook机制运用),稍微改了一下训练的代码
def train_with_hook(self, data_iter, optimizer, num_epochs=10,
loss: nn.Module = nn.L1Loss(),
acc_func=single_argmax_accuracy, valid_iter=None) -> History:
# 记录损失和准确率以供绘图
history = History('train_l', 'train_acc') if not valid_iter else \
History('train_l', 'train_acc', 'valid_l', 'valid_acc')
# 注册hook
for m in self:
m.register_forward_hook(hook=BasicNN.hook_forward_fn)
m.register_full_backward_hook(hook=BasicNN.hook_backward_fn)
# 开始迭代epochs
for _ in trange(num_epochs, unit='epoch', desc='Epoch training...',
mininterval=1):
metric = Accumulator(3) # 累加批次训练损失总和,准确率,样本数
with tqdm(total=len(data_iter), unit='batch', position=0,
desc=f'Epoch{_ + 1}/{num_epochs} training...',
mininterval=1) as pbar:
for X, y in data_iter:
with torch.enable_grad():
self.train()
optimizer.zero_grad()
y_hat = self(X)
lo = loss(y_hat, y)
lo.backward()
optimizer.step()
with torch.no_grad():
correct = acc_func(y_hat, y)
num_examples = X.shape[0]
metric.add(lo.item() * num_examples, correct, num_examples)
pbar.update(1)
pbar.close()
if not valid_iter:
history.add(
['train_l', 'train_acc'],
[metric[0] / metric[2], metric[1] / metric[2]]
)
else:
valid_acc, valid_l = self.test_(valid_iter, acc_func, loss)
history.add(
['train_l', 'train_acc', 'valid_l', 'valid_acc'],
[metric[0] / metric[2], metric[1] / metric[2], valid_l, valid_acc]
)
return history
其中,self是神经网络容器对象,继承自nn.Sequential。这个方法就位于这个对象所属的类中。以上的hook实现如下:
last_forward_output = {}
@staticmethod
def hook_forward_fn(module, input, output):
"""
前向传播hook,负责记录每个模块的输入输出,并比较上一次前馈的输入输出是否相同。
:param module: 执行前馈模块
:param input: 执行前馈输入
:param output: 执行前馈输出
:return: None
"""
print(f'{module.__class__.__name__} FORWARD')
try:
last_input, last_output = BasicNN.last_forward_output.pop(module)
except:
pass
else:
flag = True
for li, i in zip(last_input, input):
flag = torch.equal(li, i) and flag
print(f'input eq: {flag}')
flag = True
for lo, o in zip(last_output, output):
flag = torch.equal(lo, o) and flag
print(f'output eq: {flag}')
BasicNN.last_forward_output[module] = input, output
print('-' * 20)
last_backward_data = {}
@staticmethod
def hook_backward_fn(module, grad_input, grad_output):
"""
反向传播hook
:param module: 执行反向传播的模块。
:param grad_input: 反向传播模块的梯度输入,对应输出部分的梯度
:param grad_output: 反向传播模块的输出梯度,对应输入部分的梯度
:return: None
"""
print(f'{module.__class__.__name__} BACKWARD')
try:
last_input, last_output = BasicNN.last_backward_data.pop(module)
except:
pass
else:
flag = True
for li, i in zip(last_input, grad_input):
if li is None or i is None:
print(f'None grad within {li} or {i}')
else:
flag = torch.equal(li, i) and flag
print(f'in_grad eq: {flag}')
flag = True
for lo, o in zip(last_output, grad_output):
if lo is None or o is None:
print(f'None grad within {lo} or {o}')
else:
flag = torch.equal(lo, o) and flag
print(f'out_grad eq: {flag}')
BasicNN.last_backward_data[module] = grad_input, grad_output
# print(f'module: {module}')
# print(f'grad_input: {grad_input}')
# print(f'grad_output: {grad_output}')
print('-' * 20)
代码参考自:pytorch | loss不收敛或者训练中梯度grad为None的问题
于是这么一运行,就发现了问题
-
前向传播在第四次训练的时候,输入和输出不再发生变化
(Answer:可能是发生了梯度消失的问题,导致权重不发生变化。可以试试增加学习率,或者把nn.Sigmoid()成nn.ReLU())
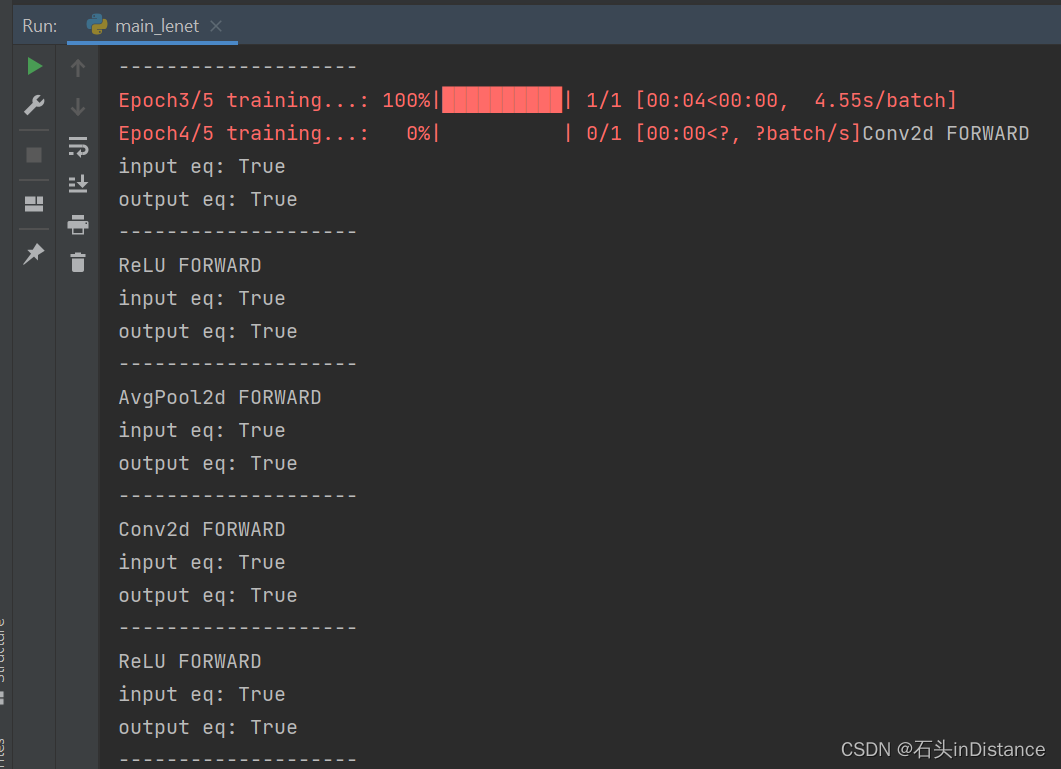
-
前向传播的输入输出不发生变化,但反向传播的梯度始终在变化
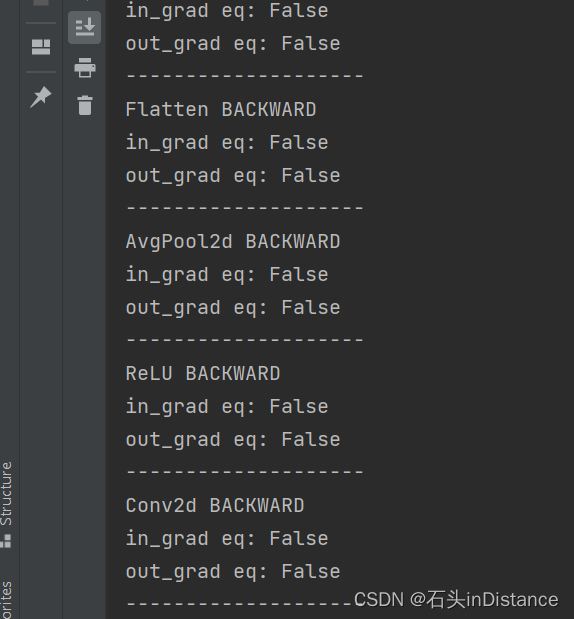
-
最后一个反向传播的模块输出的梯度始终是None。不知道这个是不是机制,还在摸索中……
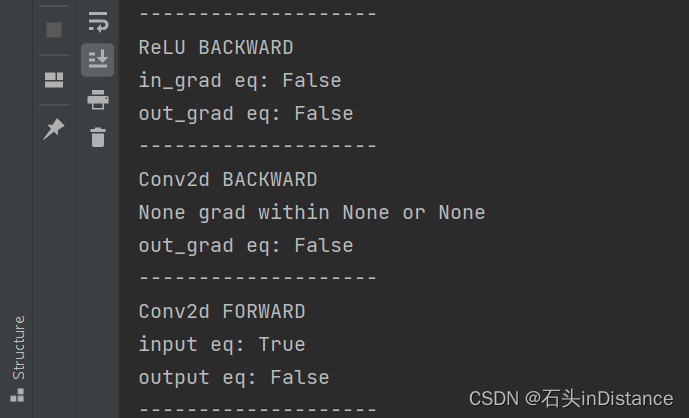
(Answer:应该是机制。在把数据集切换到FashionMNIST后,模型能够正常训练,且反向传播最后一层梯度输出仍然是None)
第五次尝试
既然用FashionMNIST数据集能够训练成功,那么我就把数据集切换回师兄采集的数据集再训练看看。将数据量改为原先的1/10后,发现模型能学动了。看来是模型拟合能力不足……
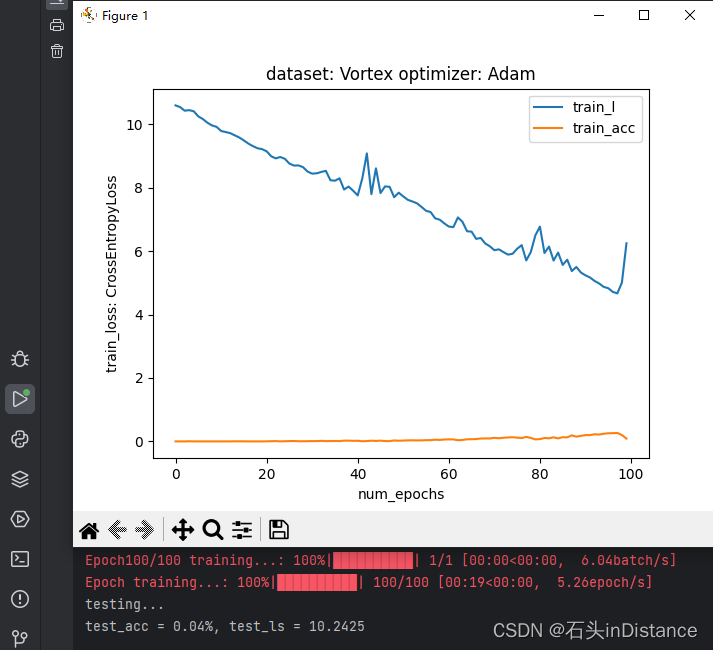
既然是拟合能力不足,那训练损失不下降的问题也许就和自定义网络层无关。为了检验自己写的网络层是否会影响模型的学习能力,于是把自己先前写的自定义层加了回来。
Reshape(nn.Module)
这一层会使模型适配各种大小的图片数据集,我给网络加入了Reshape()层用于转换图片大小以符合网络输入。这个模型的前向传播函数借鉴的是bubbliiiing大神的项目,这个项目里面写了图片的重采样函数。这个层还没有测试过全部图片大小可能性,所以使用的时候请小心!
class Reshape(nn.Module):
def __init__(self, required_shape):
super().__init__()
self.required_shape = required_shape
def forward(self, data: torch.Tensor):
# 实现将图片进行随机裁剪以达到目标shape的功能
dl = data.shape[0]
ih, iw = data.shape[-2:]
h, w = self.required_shape
# 长边放缩比例
scale = max(w / iw, h / ih)
# 计算新图片shape
new_w = int(iw * scale)
new_h = int(ih * scale)
# 计算图片缺失shape
dw = w - new_w
dh = h - new_h
# 等比例缩放数据
resizer = Resize((new_h, new_w), antialias=True)
data = resizer(data)
# 若需求图片大小较大,则进行填充
if dw > 0:
data = nn.ReflectionPad2d((0, dw, 0, 0))(data)
if dh > 0:
data = nn.ReflectionPad2d((0, 0, 0, dh))(data)
# 若需求图片大小较小,则随机取部分
if dw < 0 or dh < 0:
new_data = []
rand_w = torch.randint(0, abs(dw), (dl,)) if dw < 0 else 0
rand_h = torch.randint(0, abs(dh), (dl,)) if dh < 0 else 0
for i, _ in enumerate(data):
i_h = rand_h[i] if dh < 0 else 0
i_w = rand_w[i] if dw < 0 else 0
new_data.append(
data[i, :, i_h: i_h + h, i_w: i_w + w].reshape((1, -1, h, w))
)
data = torch.vstack(new_data)
return data
DualOutputLayer(nn.Module)
师兄的论文中,模型的输出有两列,两列分别计算。于是我设计了这样一个自定义层,按照标签集的dummy_column计算分类概率,拼接输出。
class DualOutputLayer(nn.Module):
def __init__(self, in_features, fir_out, sec_out, dropout_rate=0.,
momentum=0.) -> None:
super().__init__()
fir = nn.Sequential(
*self.__get_layers__(in_features, fir_out, dropout=dropout_rate,
momentum=momentum)
)
sec = nn.Sequential(
*self.__get_layers__(in_features, sec_out, dropout=dropout_rate,
momentum=momentum)
)
fir.apply(tools.init_wb)
sec.apply(tools.init_wb)
self.add_module('fir', fir)
self.add_module('sec', sec)
def forward(self, features):
in_features_es = [
child[1].in_features for _, child in self
]
batch_size = len(features)
feature_batch_es = [
features.reshape((batch_size, in_fea))
for in_fea in in_features_es
]
fir_out = self[0](feature_batch_es[0])
sec_out = self[1](feature_batch_es[1])
return torch.hstack((fir_out, sec_out))
def __get_layers__(self, in_features: int, out_features: int, dropout=0.,
momentum=0.) -> List[nn.Module]:
assert in_features > 0 and out_features > 0, '输入维度与输出维度均需大于0'
# layers = [nn.BatchNorm1d(in_features)]
# # 构造一个三层感知机
# trans_layer_sizes = [in_features, (in_features + out_features) // 2, out_features]
# # 对于每个layer_size加入全连接层、BN层以及Dropout层
# for i in range(len(trans_layer_sizes) - 1):
# in_size, out_size = trans_layer_sizes[i], trans_layer_sizes[i + 1]
# layers += [
# nn.Linear(in_size, out_size),
# # nn.BatchNorm1d(out_size, momentum=momentum),
# nn.LeakyReLU()
# ]
# if dropout > 0.:
# layers.append(nn.Dropout())
# # 去掉最后的Dropout层
# if type(layers[-1]) == nn.Dropout:
# layers.pop(-1)
# # 将最后的激活函数换成Softmax
# layers.pop(-1)
# 加入Softmax层
layers = [
nn.Flatten(),
nn.Linear(in_features, out_features)
]
if dropout > 0:
layers.append(nn.Dropout(dropout))
layers.append(nn.Softmax(dim=1))
return layers
def __iter__(self):
return self.named_children()
def __getitem__(self, item: int):
children = self.named_children()
for _ in range(item):
next(children)
return next(children)[1]
get_layers()中大量屏蔽的部分是我觉得最初版本生成的输出层太复杂了,于是换成了带有Softmax()的感知机。
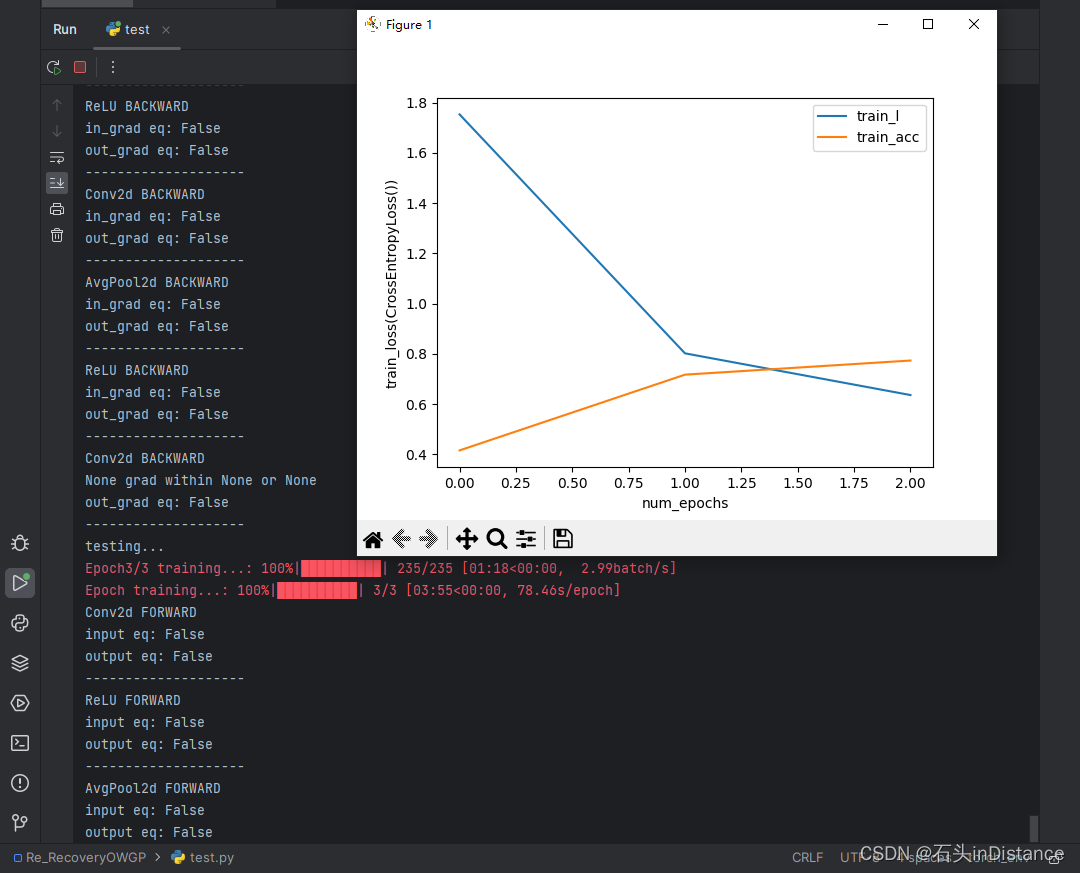
这么一通操作下来,我发现训练损失又变成一条直线了……
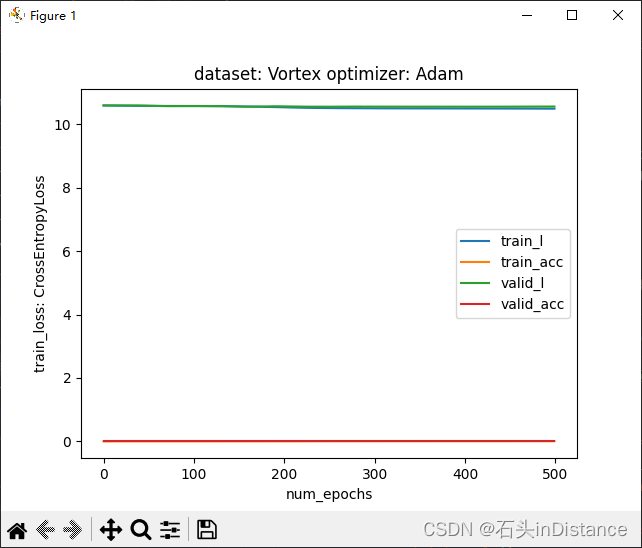
进入Debug界面后,发现损失其实是有下降的,只不过降得太少了……
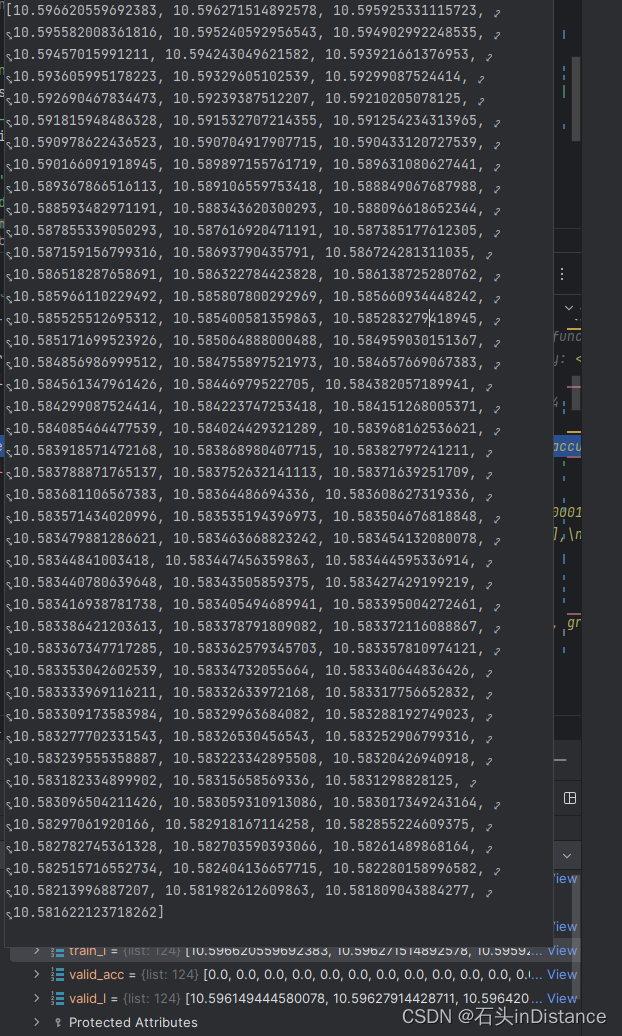
得用用matplotlib界面的放大功能,防止自己误判
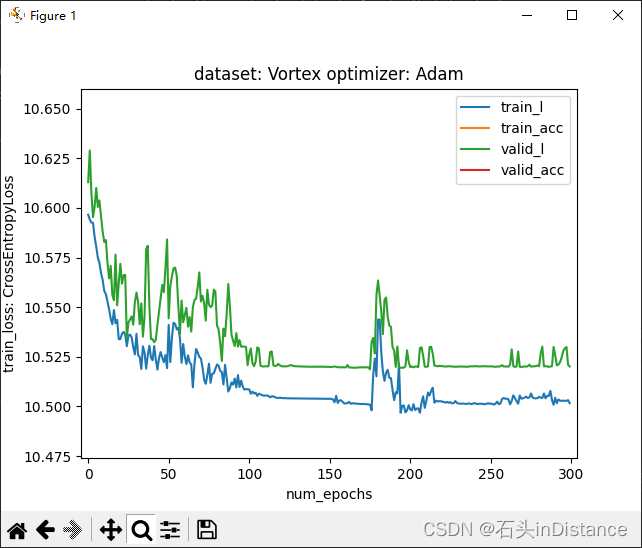
也就是说,在模型里面可以加入自定义层,虽然不会影响梯度的正常传递,但可能会使得模型训练收敛速度变慢。














 2017
2017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









