







系列文章目录
【每天学一点 - 算法篇 - 排序 - 插入排序】
【每天学一点 - 算法篇 - 排序 - 希尔排序】
前言
看到自己写的内容真的有阅读量,不知道为什么居然还有一点小感动,不说了,今天就是干到一点也要写完堆排序
一、什么是堆排序
顾名思义,堆排序就是利用堆的基本有序性进行排序的方式,
那就要先了解下堆是什么
堆又叫优先队列,
因为模型很像是土堆,沙堆,水果堆,给人感觉堆这个名字其实还是很形象的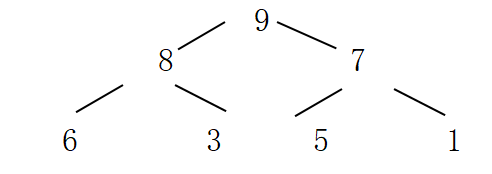
那么他又为什么叫优先队列呢,
优先的部分就是我们接下来会说的用于排序的内容,
那队列说的也就是这个模型其实是可以被表示成数组的形式,
从上到下,从左到右,依次取值,上图的堆就可以表示成数组

二、堆排序原理
1、思路
那堆这个结构又是怎么用于排序的呢,这个优先又是应该怎么解释呢
这就不得不提到堆的特性了,
每一个小三角架构内(子堆)都是上面的值(根节点)大于下面的值(子节点)
那只要把一个杂乱的队列按堆的规则排列成优先队列,那最上面的值就是比较所得的最大的值了

2、示例
多图预警

从最后一个子堆开始逐步使所有的子堆都满足堆定义条件,




因为根节点小于子节点,孙节点也小于子节点,所以根节点与子节点替换后,还要跟孙节点比较,确认是否要继续向下替换

第五次交换完成后,就可以将最大值取出,然后再构建堆,再将最大值取出,再构建堆,直至将最后一个元素取出并放入新的有序队列中,即可完成排序。
但此处空间上多占用的一个序列,考虑堆每次取出最大值后,队列长度减一,所以可以直接将每次取出的最大值还放回当前队列的队尾,直至此队列变成有序队列






按照上述方式,往复循环,直到将整个堆抽取完
3、抽象
取数组长度一半的位置就是最后一个子堆的根节点,
然后逐渐往上寻找每一个根节点,
每个根节点都要进行跟子节点的比较,并替换成较大的值
直到堆构建完成,将最大值与队尾元素交换
并除去队尾元素(以被交换的最大值)重新进行堆的构建
依次循环,最终形成有序队列
三、堆排序代码
实现方法
public int[] heapSort(int[] a) {
for (int i = a.length / 2 - 1; i >= 0; i--) {
childHeapSort(a, i, a.length);
}
for (int i = a.length - 1; i > 0; i--) {
swap(a, i);
childHeapSort(a, 0, i);
}
return a;
}
private void childHeapSort(int[] a, int i, int length) {
int child;
int tmp;
for (tmp = a[i]; leftChild(i) < length; i = child) {
child = leftChild(i);
if (child != (length - 1) && a[child] < a[child + 1]) {
child++;
}
if (tmp < a[child]) {
a[i] = a[child];
} else {
break;
}
}
a[i] = tmp;
}
private int leftChild(int i) {
return 2 * i + 1;
}
private void swap(int[] a, int i) {
int tmp = a[0];
a[0] = a[i];
a[i] = tmp;
}
测试方法
@Test
public void heapSort() {
int[] a = new int[]{3, 9, 5, 4, 8, 7, 1, 6, 2};
System.out.println(Arrays.toString(new Sort().heapSort(a)));
}
四、堆排序复杂度
先说结论
对N个互异项的随机排列进行堆排序所用比较的平均次数是2NlogN-O(NloglogN)
证明过程得等我恶补完数学知识再说了,
但是大概思路还是可以理一下的,
不管是前面说插入排序,几乎每个元素都要跟其他所有元素比一遍,也就是N*N,记作O(N2)复杂度,
还是缩减增量排序(希尔排序),根据不同的增量缩减方式,现在还没法证实的O(N3/2)复杂度,
很明显堆排序是打破了二次复杂度,每个元素每次只跟自己子堆的元素进行比较,从最下层的子节点到最上层的根节点也只有logN长度,时间复杂度明显是得到了非常大的改善
总结
其实我是想把复杂度算明白的,但是我的乌鸦嘴还真的搞到一点多了,反正前面也给自己挖坑了,就再多留一个吧。
















 1421
1421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











