







目录

insert常用语句
1、mysql中insert语句的语法一
insert into tablename(字段1名称,字段2名称,…) values(字段1值,字段2值,…)
示例如下:
向表tb1中插入一条数据,插入数据对应的字段为name和age,name的值为tom,age为33。
insert into tbl (name,age) values ('tom',33);向表tb1中插入多条数据,具体含义同上,只不过是插入多条语句。
insert into tbl (name,age) values ('jerry',22),('naruto',28);也可以不指定字段,表示对应每个字段都会有插入的数据。
insert into tb1 values (4,'Sasuke',28),(5,'hinata',25);2、mysql中insert语句的语法二
除了使用上述的语法插入数据,我们还能够使用如下语法
insert into tablename set 字段1名称=字段1值,字段2名称=字段2值
示例如下:
insert into tbl set id=2,name="test",age=18,gender='M';聪明如你一定发现了,上述两种语法的不同之处在于,字段名称与字段值是否分开了,使用set的方式字段名与字段值是在一起的。
除了这一点不同之处,其实,他们还有另外一点不同,就是,使用set的方式插入数据时,insert语句中字段的顺序可以与表中字段的顺序不同,而第一种语法中,字段顺序必须与表中字段的顺序相同。
3、mysql的模式sqlmode
还需要注意的是,mysql默认的sqlmode为宽松模式,这意味着即使插入的数据并不是完全符合数据类型的要求,也有可能插入数据。示例如下:

可以从上图中看到,tb表中的name字段的数据类型为char(5),也就是说name字段最多只能插入5个字符,当我们插入的数据为naruto时,超过了5个字符的长度,但是仍然插入成功了,插入的数据自动被截取为narut,少了一个字母”o”,同理,age字段的值的最大取值为255,当我们插入大于255的数据时,数据自动变为了255,这样虽然能够插入数据,但是跟我们预期不一样,这种情况就属于对数据的校验不严格导致的,我们再看另一种情况,如下图:

tb1表中的name字段是不允许为空的,并且name字段没有对应的默认值,但是我们如果不对name字段设置对应的值,数据也能插入,mysql自动将其值设置为了空字符串,如果按照严格的标准,这样应该不允许插入数据。上述两种情况都属于对数据的校验不严格造成的。
解决办法:
如果我们不期望这样的事情发生,可以通过设置sql_mode参数的值进行严格限制,我们可以通过运行时设置的方式,与修改配置文件的方式设置sql_mode。此时,如果你想要在不重启的mysql情况让以后的所有连接都遵循严格的限制,需要先在运行时设置中,将global.sql_mode变量的值设置为TRADITIONAL(使用的存储引擎为innodb),同时在配置文件中设置sql_mode=TRADITIONAL(使用的存储引擎为innodb),以免重启后失效。
sql_mode最常用的几种重要模式如下:
ANSI:宽松模式,对插入数据进行校验,如果不符合定义类型或长度,对数据截断保存,报警告信息,默认应该就是这种。
STRICT_TRANS_TABLES:只在事务型表中进行严格限制。
STRICT_ALL_TABLES:对所有表进行严格限制。
TRADITIONAL :严格模式,当插入数据时,进行数据的严格校验,错误的数据将不能被插入,报error错误。用于事物时,会进行事物的回滚,官方提醒我们说,如果我们使用的存储引擎是非事务型的存储引擎(比如myisam),当我们使用这种模式时, 如果执行非法的插入或更新数据操作时,可能会出现部分完成的情况。
delete常用语句
删除数据的语句比较简单,主要是通过where子句给定删除的范围,而where子句的示例可以参考select常用语句,但是删除前请确定给定的条件没有任何问题,在不确定的情况下不要随意删除数据。
如下语句表示删除tb1中的所有数据,也就是清空tb1表,非常危险,切勿随意使用。
delete from tb1;根据给定的条件删除数据,在不确定的情况下或者没有备份的情况下,请勿随意删除数据
delete from tb1 where age=22;
delete from tb1 where name rlike '^t.*';如下语句表示,从tb1表中找出age>30的数据行,然后将这些行按照age进行降序排列,排列后删除第一个。
delete from tb1 where age > 30 order by age desc limit 1;update常用语句
修改数据的语句也比较简单,主要是通过where子句给定修改的范围,而where子句的示例可以参考select常用语句,执行更新语句之前请确定给定的条件是正确的,因为不加任何条件的更新语句表示更新表中的所有字段,如果你不确定要这么做,这样是非常危险的,所以执行update语句之前,也要再三确定条件给定正确。
如下语句表示更新tb1表中所有行的age字段的值为28,这种语句比较危险,除非你确定这样做,否则切勿执行。
update tb1 set age = 28;如下语句表示将tb1表中id号为13的行中的name字段的值改为luffy.
update tb1 set name='luffy' where id=13;如下语句同上,只是一次修改了多个字段的值。
update tb1 set name='luffy',age=25 where id=13;select 基本语句
最简单最粗暴的查询语句如下,查询tb1表中的所有数据,如果表中的数据量巨大,那么使用如下语句纯属作死,非必要情况下,一般不要这样对数据进行查询,在如下示例中,为了方便总结,可能会经常使用这种查询方式。
select * from tb1;表示从tb1表中查询出所有数据,但是只显示前3行。
select * from tb1 limit 3;从tb1表中查询出name字段与age字段的数据,即使这样写,也没有比上例的语句好多少,它仍然是显示表中的所有行的指定字段,表中的数据量较大时,这样写也是非常不好的,除非必要,一般不要这样写。
select name,age from tb1;从tb1表中查询出符合条件的数据,使用where字句给定条件,带有筛选条件的查询语句则会比上面两种查询语句好很多。
如下语句表示从tb1表中查询出age等于25的行的name和age字段。
select name,age from tb1 where age = 25;查出tb1表中age不等于28的数据。
select * from tb1 where age != 28;如下两条语句均表示从tb1表中查询出age大于等于25并且小于等于28的数据。
select * from tb1 where age >= 25 and age <=28;
select name,age from tb1 where age between 25 and 28;如下语句表示从tb1表中查询出age等于25或者等于28的数据。
select * from tb1 where age = 25 or age = 28;如下语句表示从tb1表中查询出age不在25到28区间中的数据。
select * from tb1 where age not between 25 and 28;
select * from tb1 where age < 25 or age > 28;使用like结合通配符进行模糊查询,如下语句表示查询tb1表中name字段以j开头的数据,”%”在查询语句中表示”任意长度的任意字符”
select * from tb1 where name like 'j%';如下语句表示查询tb1表中name字段以t开头,并且只有三个字符的数据,”_”在查询语句中表示”任意单个字符”,下例中的语句,表示t后面的两个字符可以是任意字符。
select * from tb1 where name like 't__';也许你觉得还不够灵活,或许你更习惯使用正则表达式作为匹配条件,没有关系,满足你,我们可以使用rlike结合正则表达式,对字符数据进行模糊查询,所以,查询语句能有多强大的功能,就看你的正则表达式运用的有多熟练了。
如下语句表示查询出tb1表中name字段以 t 开头的所有数据,正则表达式的含义此处不再赘述。
select * from tb1 where name rlike '^t.*';我们还可以从指定的列表中匹配对应的条件,使用in关键字指定列表,示例如下,如下语句表示从tb1表中查找出age等于22、23、24或25中的任意一个的行的所有数据。
select * from tb1 where age in (22,23,24,25);除了使用in,我们还可以使用not in,聪明如你一定秒懂,not in就是in的对立面,比如,查询出tb1表中age不等于28、43、33的数据。
select * from tb1 where age not in (28,33,43);我们可以对查询出的数据进行排序,如下示例表示查询tb1表中的所有数据,并且按照age的值从小到大进行升序排序,asc表示升序排序,asc可省,默认使用升序排序。
select * from tb1 order by age;
select * from tb1 order by age asc;如下示例表示查询tb1表中的所有数据,并且按照age的值从大到小进行降序排序。
select * from tb1 order by age desc;查询tb1表中的所有数据,并且按照age的值从大到小进行降序排序,如果多行之间的age字段的值相同时,这些行再根据name字段进行升序排序。
select * from tb1 order by age desc,name asc;我们可以在查询某字段的时候去重,使用DISTINCT关键字表示去重查询,比如,查询学生的年龄并去重显示年龄。
select distinct age from students;我们也可以在查询时给字段添加别名,以便显示为我们指定的列名。
select name as StuName,age from tb1;select 分组与聚合
select语句中group by 的使用,见名知义,group by就是用来分组的。
而我们之所以要对数据进行分组,往往是为了在分组以后,对分组后的数据进行聚合操作。我们先从简单的操作开始总结。
首先查看一下students表中的数据。

students表中的数据如上图所示。
使用students表中的数据,进行分组,我们可以根据性别分组,也可以根据年龄分组。比如,我们根据性别对上述数据进行分组,示例如下:

可以看到,根据性别分组后,只分出了两组,因为性别只有男和女两种,所以只分出了两组。
而且每组只显示一条数据,也就是每组的第一条数据,注意,这可能与我们想象的不太一样,分组后每组只显示一条数据。
分组的目的往往是对分组后的数据进行”聚合操作”,示例如下:

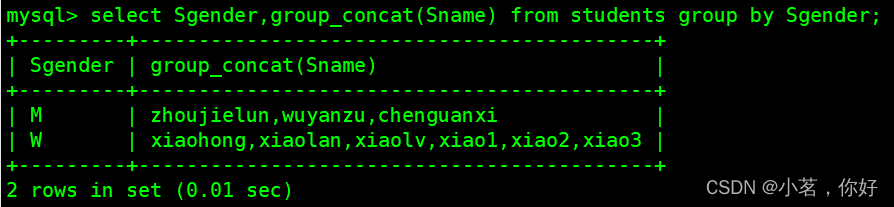
上例中,我们通过性别对数据进行了分组,然后算出了每组中的人员数量,也就是说,我们算出了女性有6人,男性有3人。
count(StuId)就是一种”聚合操作”,表示算出分组后的每组的stuid的数量,这就是所谓的”分组的目的往往是为了聚合操作”的含义。
count()是一种聚合函数,这个聚合函数能够算出对应数据的条目数量。
按照性别分组,然后,算出男生与女生的平均年龄,可以使用如下语句:

聪明如你一定猜到了,avg( )也是一种聚合函数,avg(Sage)就是求年龄的平均值。
mysql中常用的聚合函数,如下:
min(col):返回指定列的最小值
max(col):返回指定列的最大值
avg(col):返回指定咧的平均值
count(col):返回指定列中非null值的个数
sum(col):返回指定列的所有值之和
group_concat(col):返回指定列的值,但是会分组显示,也就是说分组显示指定列组合后的结果,这样说不容易明白,我们来看个例子,比如,将学生表中的学生按性别分组,并且显示男生组有哪些学生,女生组有哪些学生,示例如下:
那么,如果我们想要对分组后的信息再次过滤,该怎么办呢,举个例子,如下:

从上例可以看出,如果想要对分组过后的信息再次过滤,可以使用having关键字。
总结一些常用示例,如下:
查询students表,以性别为分组,求出分组后的年龄之和。
select Sgender,sum(Sage) from students group by Sgender;查询students表,以ClassId分组,显示平均年龄大于25的ClassId。
select ClassId,avg(Sage) as average from students group by ClassId having average > 25;查询students表,以性别字段Sgender分组,显示各组中年龄大于29的学员的年龄的总和。
select Sgender,sum(Sage) from students where Sage > 29 group by Sgender;select 多表查询
多表查询顾名思义就是数据同时从多张表中获得,查询语句牵扯到多张表,多表查询有多种语法,多种使用场景,不同的场景需要不同的语法,我们先不考虑那么多,从头开始理解一下多表查询。
1、交叉连接:cross join
既然是多表查询,那么我们先来看看两张非常简单的表,我们就以这两张表为例,进行演示。

上图中,我们通过两条语句分别查询了表1与表2的内容,t1表中有3条数据,t2表中有2条数据,那么同时查两张表,查询内容如下:

上图中,我们只是单纯的将两张表使用同一条select语句查询了出来,并没有添加任何额外的过滤条件,仔细观察查询出的数据,可以发现,当使用上图中的语句时,t1表中的每一行记录,都与t2表中的任意一条记录相关联;同样,t2表也与t1表中的任意一条记录相关联。
换句话说,两张表中的数据会以下图中的方式被”交叉连接”在一起,然后展示出来:
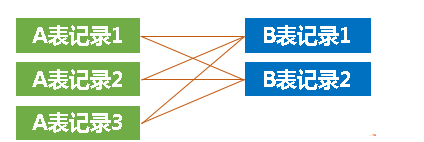
当然,上述示例中,t1表中有3条数据,t2表中有2条数据,所以”交叉连接”后如上图,如果t1表中有3条记录,t2表中也有3条记录,那么交叉连接后的结果如下图:
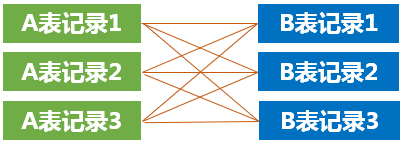
我们把上述”没有任何限制条件的连接方式”称之为”交叉连接”,”交叉连接”后得到的结果跟线性代数中的”笛卡尔乘积”一样。
上述示例中,我们只使用了数据较少的两张表,如果我们同时将多张表使用上述语句查询,而且每张表中的数据较多,那么可以想象,我们得到结果的时间可能会非常长,而且得到结果以后,可能也没有太大的意义。所以,通过交叉连接的方式进行多表查询的这种方法,我们并不常用,而且我们应该尽量避免这种查询。
“交叉连接”的英文为”cross join”,上述示例中的语句我们可以换一种写法,两种写法能够获取到相同的结果,示例如下:

其实,上图中的写法才是官方建议的最标准的写法,即为使用”cross join”将多张表使用”交叉连接”连接起来。当然,我们也可以将多张表使用”cross join”连接起来,比如将t1,t2,t3三张表使用”cross join”连接起来,示例语句如下:
select * from t1 cross join t2 cross join t3;2、内连接:inner join
既然”交叉连接”不常用,那么肯定有其他的常用的多表查询方式---内连接。
那么什么是”内连接”呢?我们可以把”内连接”理解成”两张表中同时符合某种条件的数据记录的组合”,这样说不容易理解,我们来动手做一个小例子,示例如下:
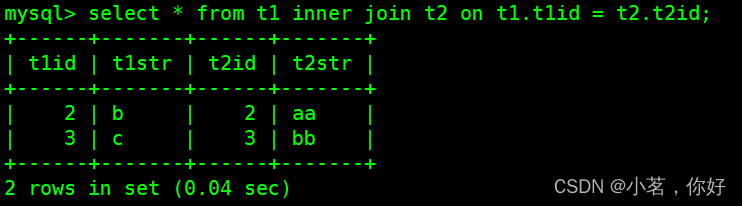
上图中的sql语句就使用了”内连接”,上图中的sql语句查询出了t1表与t2表中id号相同的记录,并把两表中id号相同的记录连接在了一起,我们对比着”内连接”的概念,来理解上图中的sql语句,内连接就是”两张表中同时符合某种条件的数据记录的组合”。
那么上图中,”t1.t1id = t2.t2id”就是所谓的”符合某种条件”,上图中查询出的结果就是”两张表中同时符合某种条件的数据记录的组合”,这其实就是所谓的”内连接”。在mysql中,”内连接”的语句与 ”交叉连接”的语句的不同之处就是”内连接”语句比”交叉连接”有更多的限制条件,这样理解”内连接”,会不会容易一点呢?
下边我们用图示的方法来描述什么是内连接:
我们把t1表与t2表当做两个集合,把t1id与t2id分别当这做两个集合中的元素,可以理解为下图。
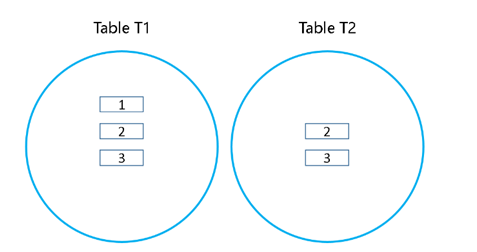
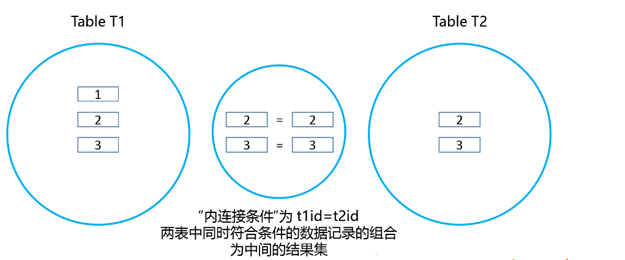
还记得我们刚才使用的”内连接”查询语句吗,”内连接”查询语句如下。
select * from t1 inner join t2 where t1.t1id = t2.t2id;即t1id与t2id相同的记录被查询了出来,从结果来看,由于t2表中并不存在id号为1的记录,所以,只查询出了两张表中id号相同的记录,用图表示如下:
但是,”内连接”还能够分为多种,比如”等值连接”和”不等连接”,刚才示例中使用的内连接就属于”等值连接”,聪明如你一定想到了,内连接是否属于”等值连接”取决于”连接条件”中有没有使用”=”。
那么我们给出一个”不等连接”的示例,如下。
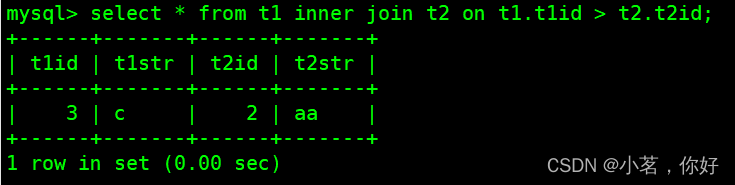
上图中的”内连接”就属于”不等连接”,同样,下图中的”内连接”也属于”不等连接”,只要”连接条件”中没有使用”=”作为连接条件的都为”不等连接”

那么,用”图示”的方法表示上图中的”内连接”语句,可以参考下图。
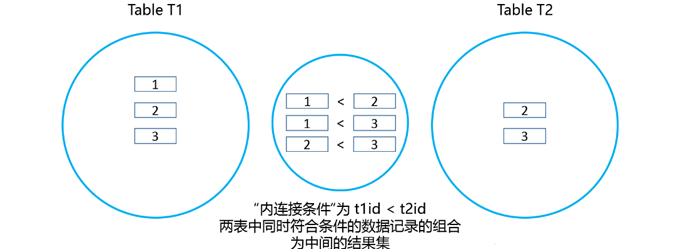
从上图中可以发现,使用”内连接”语句查询出的结果集是两个集合中”同时满足条件的数据”的”组合”,所以我们并不能单纯的用”交集”去表示这个组合。
就以上图为例,按照”交集”的定义,属于集合A且同时属于集合B的元素所组成的集合被称为交集,但是上图中,id号为1的元素只属于t1表,在t2表中并不存在id号为1的元素,但是,上图中间的结果集就是”内连接”查询出的结果。所以,我们不能单纯的用”交集”表示”内连接”,但是,我们可以从另一个角度定义”交集”,”交集”为两个集合中同时满足条件的数据的组合,那么,我们可以把 ”内连接”查询出的结果集用下图表示。
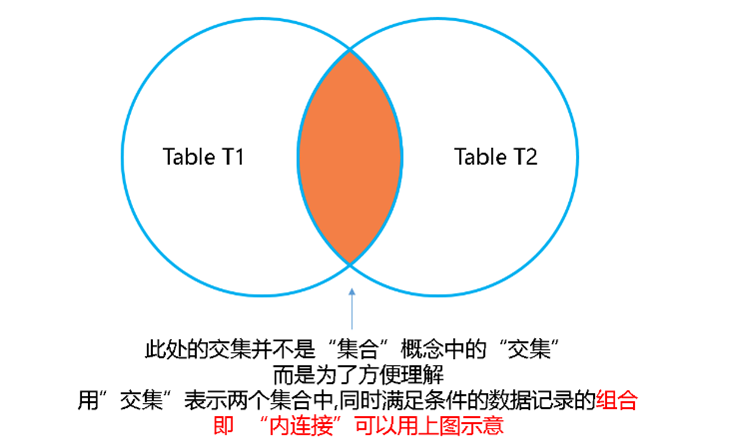
通过上图去理解”内连接”,可能更容易理解一点。
3、外连接:left join , right join
“外连接”分为两种,”左外连接”和”右外连接”,我们只要搞明白其中的任意一个,就能明白另一个是什么意思,有了之前的”交叉连接”和”内连接”的基础,再看”外连接”,就容易多了。
”左外连接”的英文原文为”left outer join”,可以使用”left outer join”将两张表进行左外链接。
将两张表使用”左外连接”连接起来,示例如下:

在同样的连接条件下,”左外连接”查询出的数据更多一点,多出的一行记录由t1表中的id号为1的记录和一条”空记录”组成。
可是t2表中并不存在id号为1的记录啊,为什么不符合连接条件的记录也会出现在查询结果呢?这就是左外连接的特性。
左外连接不仅会查询出两表中同时符合条件的记录的组合,同时还会将”left outer join”左侧的表中的不符合条件的记录同时展示出来,由于左侧表中的这一部分记录并不符合连接条件,所以这一部分记录使用”空记录”进行连接。
换句话说,左外连接”左侧的表”中的所有记录都会被展示出来,左侧表中符合条件的记录将会与右侧表中符合条件的记录相互连接组合,左侧表中不符合条件的记录将会与右侧表中的”空记录”进行连接。
上述示例中的t1表就是”left outer join”左侧的表,t2表就是”left outer join”右侧的表,连接条件就是t1id=t2id,虽然t1表中id号为1的记录不满足连接条件,但是仍然会被展示出来,t2表中会使用”空记录”与其进行连接,表示t1表中对应的记录是不满足连接条件的记录。
如果刚才的描述还是不能让你理解左外连接,那么,我们来画个图看看,仍然使用类似之前”内连接”中的”示意图”进行示意。
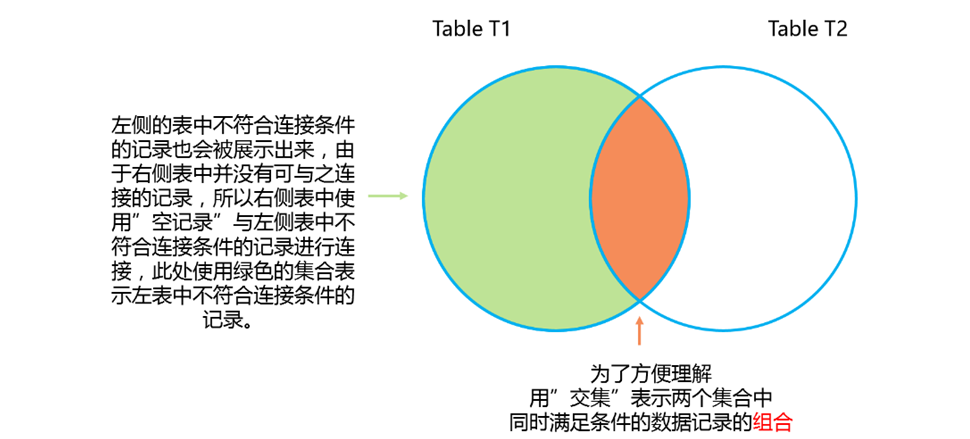
上图中,两个彩色的集合组成了左外连接查询出的结果集。既然明白了”左外连接”,那么”右外连接”就更容易理解了,左外连接是以连接左侧的表为准,不管左侧表中的记录是否符合连接条件,都会被显示出来并且右侧的表中会使用空记录与之连接,那么”右外连接”则与之相似。

上述例子中,t2表为”右外连接”右侧的表,t1表为”右外连接”左侧的表,虽然t2表中id号为3的记录并不满足连接条件,但是仍然被展示了出来,t1表中使用空记录与之相连接,那么,用图示的方法表示”右外连接”如下。
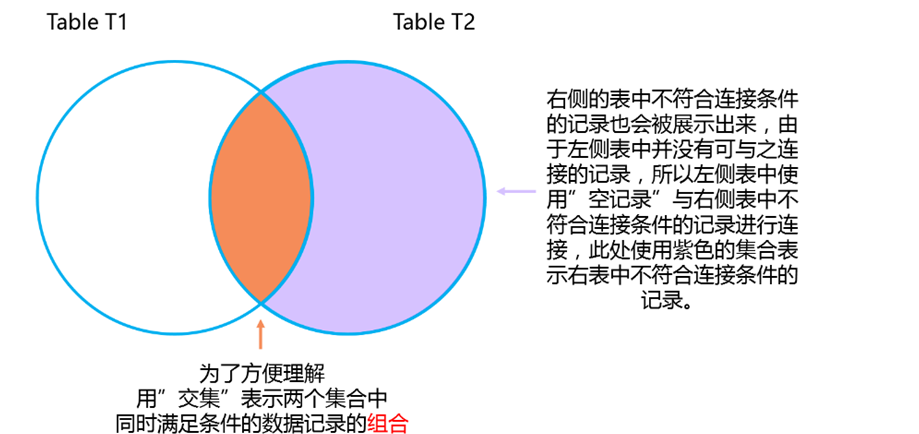














 4647
4647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









