







什么是异常?
- 异常是程序在“编译”或者“执行”的过程中可能出现的问题
- 比如:数组索引越界、空指针异常、 日期格式化异常,等…
- 注意:语法错误不算在异常体系中。
为什么要学习异常?
异常体系
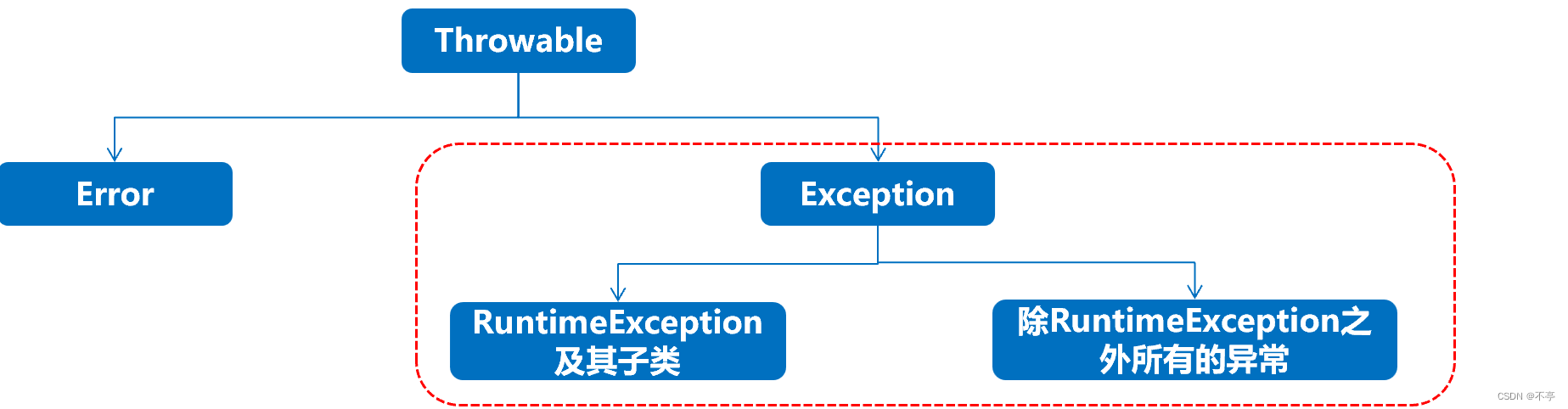
- Throwable:是异常体系的顶层类,其派生出两个重要的子类, Error 和 Exception
- Error:指的是Java虚拟机无法解决的严重问题。(系统级别问题、JVM退出等,代码无法控制。)比如:JVM的内部错误、资源耗尽等,典型代表:StackOverflowError和OutOfMemoryError,一旦发生回力乏术。
- Exception:异常产生后程序员可以通过代码进行处理,使程序继续执行。比如:感冒、发烧。我们平时所说的异常就是Exception。
异常分类
异常可能在编译时发生,也可能在程序运行时发生,根据发生的时机不同,可以将异常分为:
- 编译时异常:在程序编译期间发生的异常,称为编译时异常,也称为受检查异常(Checked Exception)
- 运行时异常:在程序执行期间发生的异常,称为运行时异常,也称为非受检查异常(Unchecked Exception),继承自RuntimeException的异常或其子类,编译阶段不报错,运行可能报错。
注意:编译时出现的语法性错误,不能称之为异常
运行时异常示例
- 数组索引越界异常: ArrayIndexOutOfBoundsException
- 空指针异常 : NullPointerException,直接输出没有问题,但是调用空指针的变量的功能就会报错。
- 数学操作异常:ArithmeticException
- 类型转换异常:ClassCastException
- 数字转换异常: NumberFormatException
运行时异常:一般是程序员业务没有考虑好或者是编程逻辑不严谨引起的程序错误。
编译时异常
String date = "2015-01-12 10:23:21";
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date d = sdf.parse(date);
System.out.println(d);
//日期解析异常:ParseException
编译时异常的作用是什么:
是担心程序员的技术不行,在编译阶段就爆出一个错误, 目的在于提醒不要出错!
异常的处理
异常处理主要的5个关键字:throw、try、catch、final、throws,下面挨个解释
防御式编程
错误在代码中是客观存在的. 因此我们要让程序出现问题的时候及时通知程序猿
主要的方式
1. LBYL: Look Before You Leap. 在操作之前就做充分的检查. 即:事前防御型
boolean ret = false;
ret = 登陆游戏();
if (!ret) {
处理登陆游戏错误;
return;
} r
et = 开始匹配();
if (!ret) {
处理匹配错误;
return;
} r
et = 游戏确认();
if (!ret) {
处理游戏确认错误;
return;
} r
et = 选择英雄();
if (!ret) {
处理选择英雄错误;
return;
缺陷:正常流程和错误处理流程代码混在一起, 代码整体显的比较混乱。
2. EAFP: It's Easier to Ask Forgiveness than Permission. "事后获取原谅比事前获取许可更容易". 也就是先操作, 遇到问题再处理. 即:事后认错型
try {
登陆游戏();
开始匹配();
游戏确认();
选择英雄();
载入游戏画面();
...
} catch (登陆游戏异常) {
处理登陆游戏异常;
} catch (开始匹配异常) {
处理开始匹配异常;
} catch (游戏确认异常) {
处理游戏确认异常;
} catch (选择英雄异常) {
处理选择英雄异常;
} catch (载入游戏画面异常) {
处理载入游戏画面异常;
}
...优势:正常流程和错误流程是分离开的, 程序员更关注正常流程,代码更清晰,容易理解代码
异常处理的核心思想就是EAFP
异常的默认处理流程:
- ①默认会在出现异常的代码那里自动的创建一个异常对象:ArithmeticException。
- ②异常会从方法中出现的点这里抛出给调用者,调用者最终抛出给JVM虚拟机。
- ③虚拟机接收到异常对象后,先在控制台直接输出异常栈信息数据。
- ④直接从当前执行的异常点干掉当前程序。
- ⑤后续代码没有机会执行了,因为程序已经死亡。

默认的异常处理机制并不好,一旦真的出现异常,程序立即死亡!
异常的抛出
在编写程序时,如果程序中出现错误,此时就需要将错误的信息告知给调用者,比如:参数检测。
在Java中,可以借助throw关键字,抛出一个指定的异常对象,将错误信息告知给调用者。具体语法如下
throw new XXXException("异常产生的原因");
【注意事项】
1. throw必须写在方法体内部
2. 抛出的对象必须是Exception 或者 Exception 的子类对象
3. 如果抛出的是 RunTimeException 或者 RunTimeException 的子类,则可以不用处理,直接交给JVM来处理
4. 如果抛出的是编译时异常,用户必须处理,否则无法通过编译
5. 异常一旦抛出,其后的代码就不会执行
捕获:
编译时异常的处理机制
编译时异常的处理形式有三种:
- 出现异常直接抛出去给调用者,调用者也继续抛出去。
- 出现异常自己捕获处理,不麻烦别人。
- 前两者结合,出现异常直接抛出去给调用者,调用者捕获处理。
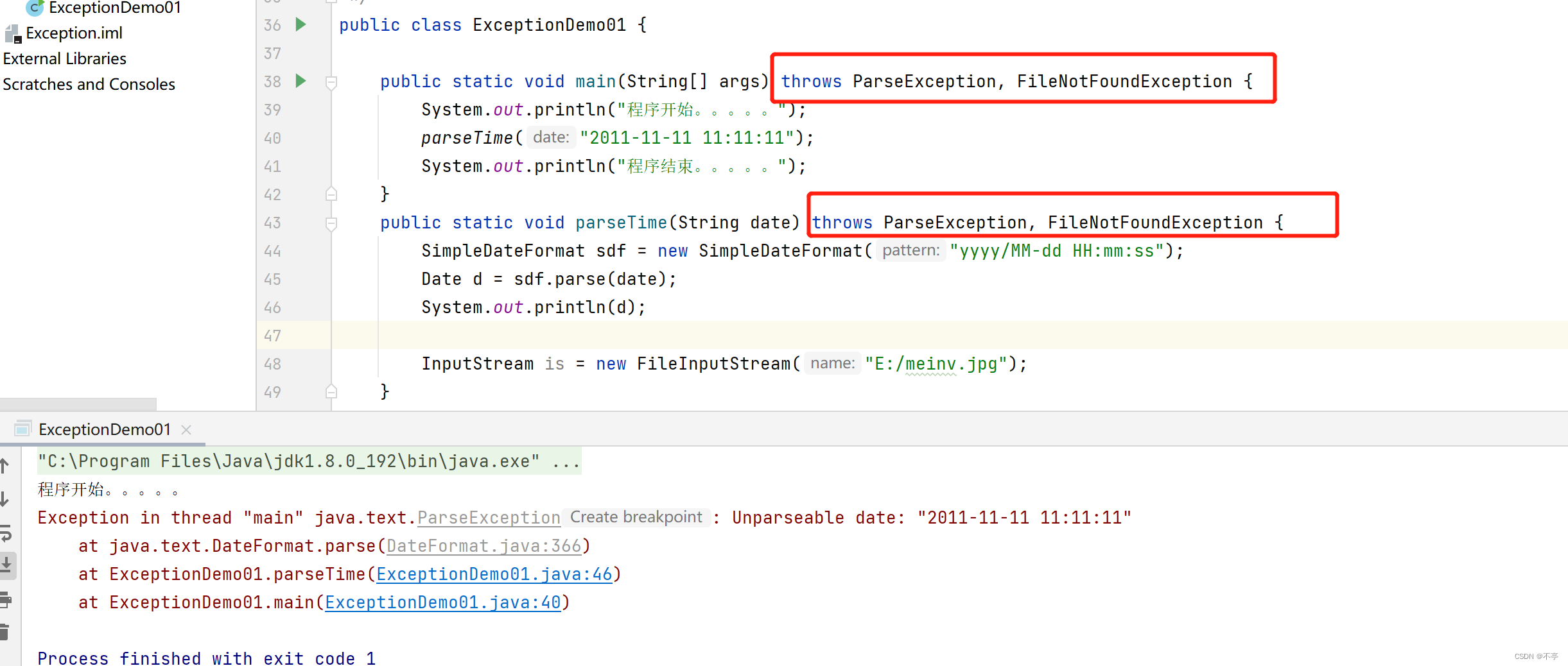
异常处理方式1 —— throws
throws:用在方法上,可以将方法内部出现的异常抛出去给本方法的调用者处理。即当前方法不处理异常,提醒方法的调用者处理异常。
这种方式的缺陷,发生异常的方法自己不处理异常,如果异常最终抛出去给虚拟机将引起程序死亡。
抛出异常格式:
修饰符 返回值类型 方法名(参数列表) throws 异常类型1,异常类型2...{
}
举个栗子:
【注意事项】
1. throws必须跟在方法的参数列表之后
2. 声明的异常必须是 Exception 或者 Exception 的子类
3. 方法内部如果抛出了多个异常,throws之后必须跟多个异常类型,之间用逗号隔开,如果抛出多个异常类型具有父子关系,直接声明父类即可。
4. 调用声明抛出异常的方法时,调用者必须对该异常进行处理,或者继续使用throws抛出
快捷方式:
将光标放在抛出异常方法上,alt + Insert 快速 处理
异常处理方式2 —— try…catch…捕获并处理
语法格式:
try{
// 将可能出现异常的代码放在这里
}catch(要捕获的异常类型 e){
// 如果try中的代码抛出异常了,此处catch捕
时,就会被捕获到
// 对异常就可以正常处理,处理完成后,跳出
}[catch(异常类型 e){
// 对异常进行处理
}finally{
// 此处代码一定会被执行到
}]
// 后序代码
// 当异常被捕获到时,异常就被处理了,这里的
// 如果捕获了,由于捕获时类型不对,那就没有
注意:
1. []中表示可选项,可以添加,也可以不用添加
2. try中的代码可能会抛出异常,也可能不会
举个栗子:

【注意事项】
- 1. try块内抛出异常位置之后的代码将不会被执行
- 2. 如果抛出异常类型与catch时异常类型不匹配,即异常不会被成功捕获,也就不会被处理,继续往外抛,直到JVM收到后中断程序----异常是按照类型来捕获的
- 3. try中可能会抛出多个不同的异常对象,则必须用多个catch来捕获----即多种异常,多次捕获
如果多个异常的处理方式是完全相同, 也可以写成这样:
catch (ArrayIndexOutOfBoundsException | NullPointerException e) {
...
}
如果异常之间具有父子关系,一定是子类异常在前catch,父类异常在后catch,否则语法错误
4.可以通过一个catch捕获所有的异常,即多个异常,一次捕获(不推荐)
由于 Exception 类是所有异常类的父类. 因此可以用这个类型表示捕捉所有异常
异常处理方式3 —— 前两者结合
在出现异常的地方把异常一层一层的抛出给最外层调用者, 最外层调用者集中捕获处理!!
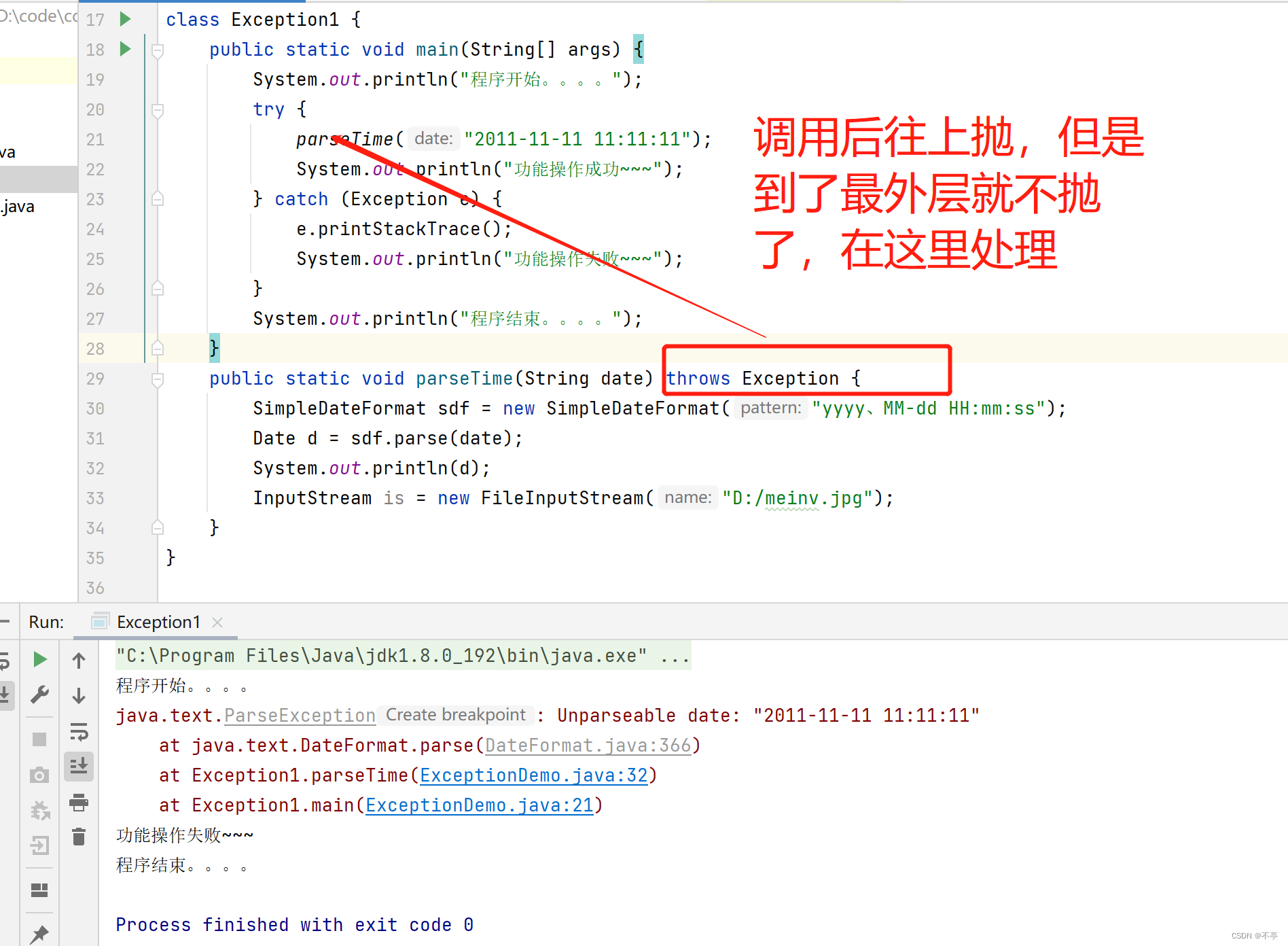
运行时异常的处理形式
finally
在写程序时,有些特定的代码,不论程序是否发生异常,都需要执行,比如程序中打开的资源:网络连接、数据库连接、IO流等,在程序正常或者异常退出时,必须要对资源进进行回收。另外,因为异常会引发程序的跳转,可能导致有些语句执行不到,finally就是用来解决这个问题的
语法格式:
try{
// 可能会发生异常的代码
}catch(异常类型 e){
// 对捕获到的异常进行处理
}finally{
// 此处的语句无论是否发生异常,都会被执行到
} // 如果没有抛出异常,或者异常被捕获处理了,这里的代码也会执行
注意:
- finally中的代码一定会执行的,一般在finally中进行一些资源清理的扫尾工作
- finally 执行的时机是在方法返回之前(try 或者 catch 中如果有 return 会在这个 return 之前执行 finally). 但是如果finally 中也存在 return 语句, 那么就会执行 finally 中的 return, 从而不会执行到 try 中原有的 return.
- 一般不建议在 finally 中写 return (被编译器当做一个警告)
自定义异常
自定义异常的必要?
- Java无法为这个世界上全部的问题提供异常类。
- 如果企业想通过异常的方式来管理自己的某个业务问题,就需要自定义异常类了。
自定义异常的好处:
可以使用异常的机制管理业务问题,如提醒程序员注意。
同时一旦出现bug,可以用异常的形式清晰的指出出错的地方。
自定义异常的分类
1、自定义编译时异常
步骤:
- 定义一个异常类继承Exception.
- 重写构造器。
- 在出现异常的地方用throw new 自定义对象抛出,
作用:编译时异常是编译阶段就报错,提醒更加强烈,一定需要处理!!
2、自定义运行时异常
步骤:
定义一个异常类继承RuntimeException.
重写构造器。
在出现异常的地方用throw new 自定义对象抛出!
作用:提醒不强烈,编译阶段不报错!!运行时才可能出现!!
【异常处理流程总结】
- 程序先执行 try 中的代码
- 如果 try 中的代码出现异常, 就会结束 try 中的代码, 看和 catch 中的异常类型是否匹配.
- 如果找到匹配的异常类型, 就会执行 catch 中的代码
- 如果没有找到匹配的异常类型, 就会将异常向上传递到上层调用者.
- 无论是否找到匹配的异常类型, finally 中的代码都会被执行到(在该方法结束之前执行).
- 如果上层调用者也没有处理的了异常, 就继续向上传递.
- 一直到 main 方法也没有合适的代码处理异常, 就会交给 JVM 来进行处理, 此时程序就会异常终止.
关于 "调用栈"
方法之间是存在相互调用关系的, 这种调用关系我们可以用 "调用栈" 来描述. 在 JVM 中有一块内存空间称为"虚拟机栈" 专门存储方法之间的调用关系. 当代码中出现异常的时候, 我们就可以使用 e.printStackTrace(); 的方式查看出现异常代码的调用栈














 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









