








Java数据结构
Java一共有 种数据结构时我们常用的,分别是以下几种
| 集合类型 | 描述 |
|---|---|
| ArrayList | 可以动态增长和缩减的序列,类似于C++的vector |
| LinkedList | 可以在任何位置高效插入和删除的有序序列,链表 |
| ArrayDeque | 实现为循环数组的一个双端队列 |
| HashSet | 没有重复元素的无序集合 |
| TreeSet | 没有重复元素的有序集合 |
| LinkedHashSet | 记住元素插入次序的集合 |
| PriorityQueue | 优先队列 |
| HashMap | <K,V>型无序集合 |
| TreeMap | <K,V>型有序集合 |
| LinkedHashMap | 记住添加次序的<K,V>型集合 |
以上所有数据结构都有以下这几种方法,需要记牢
boolean add(E e)
//确保此集合包含指定的元素(可选操作)
boolean addAll(Collection<? extends E> c)
//将指定集合中的所有元素添加到此集合(可选操作)
void clear()
//从此集合中删除所有元素(可选操作)
boolean contains(Object o)
//如果此集合包含指定的元素,则返回 true
boolean containsAll(Collection<?> c)
//如果此集合包含指定 集合中的所有元素,则返回true
boolean equals(Object o)
//将指定的对象与此集合进行比较以获得相等性
int hashCode()
//返回此集合的哈希码值
boolean isEmpty()
//如果此集合不包含元素,则返回 true
Iterator<E> iterator()
//返回此集合中的元素的迭代器
default Stream<E> parallelStream()
//返回可能并行的 Stream与此集合作为其来源
boolean remove(Object o)
//从该集合中删除指定元素的单个实例(如果存在)(可选操作)
boolean removeAll(Collection<?> c)
//删除指定集合中包含的所有此集合的元素(可选操作)
default boolean removeIf(Predicate<? super E> filter)
//删除满足给定谓词的此集合的所有元素
boolean retainAll(Collection<?> c)
//仅保留此集合中包含在指定集合中的元素(可选操作)
int size()
//返回此集合中的元素数
default Spliterator<E> spliterator()
//创建一个Spliterator在这个集合中的元素
default Stream<E> stream()
//返回以此集合作为源的顺序 Stream
Object[] toArray()
//返回一个包含此集合中所有元素的数组
<T> T[] toArray(T[] a)
//返回包含此集合中所有元素的数组; 返回的数组的运行时类型是指定数组的运行时类型
ArrayList
ArrayList<Integer> list = new ArrayList<>(); //创建一个ArrayList
list.add(1); //向ArrayList中添加元素
list.addAll(list1); //向ArrayList中插入新的ArrayList
try {
list.add(1,2); //将2插入到第一个元素中,第一个元素到最后一个元素依次往后移
list.addAll(1,list1) //将list1中所有元素插入到list的第一个里面
} catch (IndexOutOfBoundsException e) {
//如果第一个数字 > list.size() 则会抛出异常
}
list.get(0); //向ArrayList中获取第0个元素
list.set(0,2); //将第0个元素设置为2
list.clear(); //清空list
boolean b = list.contains(1); //判断list中是否含有1
boolean b = list.isEmpty(); //判断list是否为空
int i = list.indexOf(1); //查询list中第一次出现1的位置下标,没有则返回-1
int i = list.lastIndexOf(1); //查询list中最后出现1的位置下标,没有则返回-1
int x = list.remove(0); //删除第0号元素,同时将第0号元素的值返回
boolean b = list.remove(new Integer(3)); //删除list中第一个出现3的元素
/*
* 当list为Integer类型是,list.remove(0)会被认为删除第0号元素而不是删除第一个出现0的元素
*/
System.out.prinltn(list.size()); //输出list的size大小
LinkedList
LinkedList的操作和ArrayList差不多,这里记录一些ArrayList中没有的一些API
void addFirst(E e)
在该列表开头插入指定的元素
void addLast(E e)
将指定的元素追加到此列表的末尾
boolean contains(Object o)
如果此列表包含指定的元素,则返回 true
Iterator<E> descendingIterator()
以相反的顺序返回此deque中的元素的迭代器
E getFirst()
返回此列表中的第一个元素
E getLast()
返回此列表中的最后一个元素
LinkedList和ArrayList的区别
LinkedList就是链表,ArrayList就是数组
LinkedList插入和删除中间的元素十分方便,但是随机访问的能力很弱
ArrayList插入和删除中间的元素开销大,但是随机访问的能力很强
Stack
Stack<Integer> stack = new Stack<>(); //创建一个新stack
stack.push(1); //将1压入到stack中
int x = stack.peek(); //获取栈顶元素并且不使栈顶元素出栈
int x = stack.pop(); //获取栈顶元素并且使得栈顶元素出栈
int x = stack.search(1); //查找离栈顶元素最近的1离栈顶的位置
eg: 1 2 3 4 5 1 2 3 4 5
stack.search(1); //返回值为3
stack.search(5); //返回值为5
eg: 1 2 3 4 5
stack.search(5); //返回值为-1
boolean empty()
//测试此堆栈是否为空
E peek()
//查看此堆栈顶部的对象,而不从堆栈中删除它
E pop()
//删除此堆栈顶部的对象,并将该对象作为此函数的值返回
E push(E item)
//将项目推送到此堆栈的顶部
int search(Object o)
//返回一个对象在此堆栈上的基于1的位置
Set
set可以先不声明自己的泛型,这样的set可以插入不同的类,如下所示
HashSet s = new HashSet();
s.add("Polaris111");
s.add(123456);
s.add(new BigDecimal(123.456));
System.out.println(s);
打印出来的结果如下所示

Java的set一共分为两类,不能排序HashSet和能够排序的TreeSet,接下来让我分别介绍这两个类
HashSet
基本操作
HashSet<String> s = new HashSet<>();
s.add("str1"); //添加
s.add("str2");
s.add("str3");
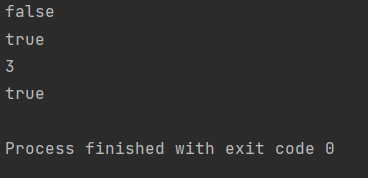
System.out.println(s.isEmpty()); //判空
System.out.println(s.contains("str1")); //判断集合是否包含元素
System.out.println(s.size()); //集合中元素个数
System.out.println(s.remove("str1")); //删除元素
s.clear(); //清空所有元素
输出结果如下所示
遍历
//第一种
Iterator it = s.iterator();
while(it.hasNext()) {
if(it.next().equals("str2")) {
it.remove();
}
}
//第二种
for(String str : s) {
System.out.println(s);
}
TreeSet
TreeSet的内部实现是红黑树,基本操作方式和HashSet相同基本相同
TreeSet<String> s = new TreeSet<>();
s.add("str1"); //添加
s.add("str2");
s.add("str3");
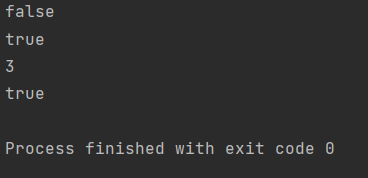
System.out.println(s.isEmpty()); //判空
System.out.println(s.contains("str1")); //判断集合是否包含元素
System.out.println(s.size()); //集合中元素个数
System.out.println(s.remove("str1")); //删除元素
s.clear(); //清空所有元素
输出结果如下所示
遍历
//第一种
Iterator it = s.iterator();
while(it.hasNext()) {
if(it.next().equals("str2")) {
it.remove();
}
}
//第二种
for(String str : s) {
System.out.println(s);
}
HashMap
HashMap<Integer, String> hashMap = new HashMap<>(); //创建元素
hashMap.put(1, "test1"); //插入元素
hashMap.put(2, "test2");
hashMap.put(3, "test3");
System.out.println(hashMap.get(1)); //取元素
System.out.println(hashMap.isEmpty()); //判空
System.out.println(hashMap.size()); //输出元素数量
//判断键是否存在
if(hashMap.containsKey(1)) {
System.out.println("1存在");
}
//判断值是否存在
if(hashMap.containsValue("test1")) {
System.out.println("test1存在");
}
hashMap.remove(1); //删除Key为1的元素
hashMap.remove(2,"test2"); //删除Key为2且值为test2的元素
hashMap.replace(3, "test4"); //将Key为3的元素的Value替换为"test4"
hashMap.replace(3, "test4", "test5"); //将Key为3且Value为"test4"的值替换为"test5"
Set<Map.Entry<Integer, String>> set = hashMap.entrySet(); //获取键
Iterator iterator = set.iterator();
while(iterator.hasNext()) {
Map.Entry<Integer, String> it = (Entry<Integer, String>) iterator.next();
System.out.println(it.getKey()); //取键
System.out.println(it.getValue()); //取值
System.out.println(it.setValue("null")); //重新设置值
}
TreeMap
TreeMap的操作与HashMap差不多,这里我写几个TreeMap特有的操作
TreeMap<Integer, String> treeMap = new TreeMap<>(); //创建元素
treeMap.put(1, "test1"); //插入元素
treeMap.put(2, "test2");
treeMap.put(3, "test3");
Integer integer = treeMap.ceilingKey(3); // 返回大于或等于给定键的键,如果没有此键,则返回null
System.out.println(integer);
Map.Entry<Integer, String> entry = treeMap.ceilingEntry(3); // 返回与大于或等于给定键的最小键相关联的键值映射,如果没有此键,则返回null
System.out.println(entry.getKey()); //取键
System.out.println(entry.getValue()); //取值
TreeMap在寻找值除了上述的操作外还有以下的操作:
Map.Entry<K,V> ceilingEntry(K key)
//返回与大于或等于给定键的最小键相关联的键值映射,如果没有此键,则 null
K ceilingKey(K key)
//返回大于或等于给定键的 null键,如果没有此键,则返回 null
Map.Entry<K,V> firstEntry()
//返回与该地图中的最小键相关联的键值映射,如果地图为空,则返回 null
K firstKey()
//返回此地图中当前的第一个(最低)键
Map.Entry<K,V> floorEntry(K key)
//返回与小于或等于给定键的最大键相关联的键值映射,如果没有此键,则 null
K floorKey(K key)
//返回小于或等于给定键的最大键,如果没有这样的键,则返回 null
SortedMap<K,V> headMap(K toKey)
//返回此地图部分的视图,其密钥严格小于 toKey
NavigableMap<K,V> headMap(K toKey, boolean inclusive)
//返回此地图部分的视图,其键值小于(或等于,如果 inclusive为真) toKey
Map.Entry<K,V> higherEntry(K key)
//返回与最小密钥相关联的密钥值映射严格大于给定密钥,如果没有这样的密钥则 null
K higherKey(K key)
//返回严格大于给定键的最小键,如果没有这样的键,则返回 null
Map.Entry<K,V> lastEntry()
//返回与该地图中最大关键字关联的键值映射,如果地图为空,则返回 null
K lastKey()
//返回当前在此地图中的最后(最高)键
Map.Entry<K,V> lowerEntry(K key)
//返回与最大密钥相关联的密钥值映射严格小于给定密钥,如果没有这样的密钥,则 null
K lowerKey(K key)
//返回严格小于给定键的最大键,如果没有这样的键,则返回 null
Map.Entry<K,V> pollFirstEntry()
//删除并返回与该地图中的最小键相关联的键值映射,如果地图为空,则返回 null
Map.Entry<K,V> pollLastEntry()
//删除并返回与该地图中最大密钥相关联的键值映射,如果地图为空,则返回 null
NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive)
//返回此地图部分的视图,其关键范围为 fromKey至 toKey
SortedMap<K,V> subMap(K fromKey, K toKey)
//返回此地图部分的视图,其关键字范围从 fromKey (含)到 toKey ,独占
SortedMap<K,V> tailMap(K fromKey)
//返回此地图部分的视图,其键大于等于 fromKey
NavigableMap<K,V> tailMap(K fromKey, boolean inclusive)
//返回此地图部分的视图,其键大于(或等于,如果 inclusive为真) fromKey
PriorityQueue
PriorityQueue默认小根堆,要想生成大根堆,可以按照如下方式生成。
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>((x,y) -> (y-x));
基本操作
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
priorityQueue.offer(1); //插入元素
priorityQueue.offer(2);
priorityQueue.offer(3);
priorityQueue.offer(4);
priorityQueue.offer(5);
System.out.println(priorityQueue.poll()); //查找队头并删除队头
System.out.println(priorityQueue.peek()); //查找队头
System.out.println(priorityQueue.size()); //输出元素数量
priorityQueue.remove(4); //删除元素如果存在
自定义排序
HashSet可以自定义排序函数,也可以让HashSet排序的类里面重载compareTo函数,操作如下所示
public int compare(String o1, String o2):比较其两个参数的顺序
static class MyClass {
public int f;
public int s;
}
static class MyComparator implements Comparator<MyClass> {
@Override
public int compare(MyClass o1, MyClass o2) {
if(o1.f != o2.f) {
if(o1.f > o2.f) {
return 1;
} else {
return -1;
}
} else {
if(o1.s > o2.s) {
return 1;
} else {
return -1;
}
}
}
}
两个对象比较的结果有三种:大于,等于,小于
如果要按照升序排序,
则o1 小于o2,返回(负数),相等返回0,01大于02返回(正数)
如果要按照降序排序
则o1 小于o2,返回(正数),相等返回0,01大于02返回(负数)
做如下测试,可以看到TreeSet按照我们给提供的接口去进行排序的
TreeSet<MyClass> treeSet = new TreeSet<>(new MyComparator());
treeSet.add(new MyClass(1, 2));
treeSet.add(new MyClass(2, 2));
treeSet.add(new MyClass(2, 3));
treeSet.add(new MyClass(4, 3));
treeSet.add(new MyClass(5, 6));
treeSet.add(new MyClass(7, 3));
Iterator it = treeSet.iterator();
while(it.hasNext()) {
System.out.println(it.next().toString());
}

也可以在声明类的时候继承Comparable接口来自定义排序方法,这样TreeSet这种排序集合在排序的时候就会执行我们自定义类中的方法
static class MyClass implements Comparable<MyClass> {
public int f;
public int s;
@Override
public int compareTo(MyClass o) {
if(this.f != o.f) {
if(this.f > o.f) {
return 1;
} else {
return -1;
}
} else {
if(this.s > o.s) {
return 1;
} else {
return -1;
}
}
}
}
同样是进行和上面一样的测试,可以发现结果是一样的,TreeSet这种排序集合在排序的时候就会执行类中的compareTo方法
TreeSet<MyClass> treeSet = new TreeSet<>();
treeSet.add(new MyClass(1, 2));
treeSet.add(new MyClass(2, 2));
treeSet.add(new MyClass(2, 3));
treeSet.add(new MyClass(4, 3));
treeSet.add(new MyClass(5, 6));
treeSet.add(new MyClass(7, 3));
Iterator it = treeSet.iterator();
while(it.hasNext()) {
System.out.println(it.next().toString());
}
结果如下所示
![[外链图片转存中...(img-GYaJayDk-1648902874793)]](https://img-blog.csdnimg.cn/dccd0e1248fa4328b258cc2707acbc37.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5peg562W56aB6Iqx6aOO,size_11,color_FFFFFF,t_70,g_se,x_16)
如果二者都不定义直接排序呢?答案是不可以的,编译器会报如下的错误:
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









