






一、Redis 简介
redis是一款开源的非关系型数据库(NoSQL),是由C语言去编写,基于Key-Value的NoSQL,而且Redis是基于内存存储数据的。
NoSQL介绍
NoSQL—> 非关系型数据库 —> Not Only SQL。
常见非关系型数据库:
文档型:ElasticSearch,Solr,Mongodb
面向列:Hbase,Cassandra
官网链接:https://redis.io/
二、Redis 安装
2.1 通过下载源码编译安装
- 下载压缩文件,Centos7.9(wget https://github.com/redis/redis/archive/7.0.0.tar.gz)
注: 没有wget先安装wget------- yum install wget - 解压文件(tar -zxvf 压缩文件名)
- 安装gcc , (编译时会用到 yum install gcc)/apt-get install gcc
- 进入到解压目录中 make distclean && make
- make install
2.2 使用doker安装redis
三、java 连接redis
3. 1 创建Maven工程,导入 Jedis 依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.2.2</version>
</dependency>
3.2 测试
public class Demo01 {
public static void main(String[] args) {
//1. 连接Redis
Jedis jedis = new Jedis("192.168.66.129", 6379);
//2. 操作Redis - 因为Redis的命令是什么,Jedis的方法就是什么
jedis.set("k1", "v1");
String k1 = jedis.get("k1");
System.out.println("k1 = " + k1);
//3. 释放资源
jedis.close();
}
}
3.3 Jedis连接池的操作
public class Demo02 {
public static void main(String[] args) {
//1. 创建连接池配置信息
GenericObjectPoolConfig<Jedis> poolConfig = new GenericObjectPoolConfig<Jedis>();
poolConfig.setMaxTotal(20);// 连接池中最大的活跃数
poolConfig.setMaxIdle(10);// 最大空闲数
poolConfig.setMinIdle(5);// 最小空闲数
//2. 创建连接池
JedisPool jedisPool = new JedisPool(poolConfig, "192.168.66.129", 6379, 50000, "123");
//3. 通过连接池获取jedis对象
Jedis jedis = jedisPool.getResource();
jedis.set("k1", "v1");
System.out.println("k1 = " + jedis.get("k1"));
//释放资源
jedisPool.returnResource(jedis);
}
}
四、Redis其他配置
4.1 Redis的AUTH
通过修改Redis的配置文件,实现Redis的密码校验
redis.conf
requirepass 密码
4.2 Redis的事务
- 没有回滚(所以需要配合 watch 一起使用)
Redis的事务:一次事务操作,改成功的成功,该失败的失败。
先开启事务,执行一些列的命令,但是命令不会立即执行,会被放在一个队列中,如果你执行事务,那么这个队列中的命令全部执行,如果取消了事务,一个队列中的命令全部作废。
- 开启事务:multi
- 输入要执行的命令:被放入到一个队列中
- 执行事务:exec
- 取消事务:discard
Redis的事务想发挥功能,需要配置watch监听机制
在开启事务之前,先通过watch命令去监听一个或多个key,在开启事务之后,如果有其他客户端修改了我监听的key,事务会自动取消。
如果执行了事务,或者取消了事务,watch监听自动消除,一般不需要手动执行unwatch。
4.3 Redis持久化机制
4.3.1 RDB
RDB是Redis默认的持久化机制
RDB持久化文件,速度比较快,而且存储的是一个二进制的文件,传输起来很方便。
RDB持久化的时机:
save 900 1:在900秒内,有1个key改变了,就执行RDB持久化。
save 300 10:在300秒内,有10个key改变了,就执行RDB持久化。
save 60 10000:在60秒内,有10000个key改变了,就执行RDB持久化。
- RDB无法保证数据的绝对安全。
4.3.2 AOF
AOF持久化机制默认是关闭的,Redis官方推荐同时开启RDB和AOF持久化,更安全,避免数据丢失。
AOF持久化的速度,相对RDB较慢的,存储的是一个文本文件,到了后期文件会比较大,传输困难。
AOF持久化时机。
appendfsync always:每执行一个写操作,立即持久化到AOF文件中,性能比较低。
appendfsync everysec:每秒执行一次持久化。
appendfsync no:会根据你的操作系统不同,环境的不同,在一定时间内执行一次持久化。
- AOF相对RDB更安全,推荐同时开启AOF和RDB。
4.3.3 注意事项
同时开启RDB和AOF的注意事项:
如果同时开启了AOF和RDB持久化,那么在Redis宕机重启之后,需要加载一个持久化文件,优先选择AOF文件。
如果先开启了RDB,再次开启AOF,如果RDB执行了持久化,那么RDB文件中的内容会被AOF覆盖掉。
五、Redis 主从复制
5.1 简介
主从复制可以在一定程度上扩展redis性能,redis的主从复制和关系型数据库的主从复制类似,从机能够精确的复制主机上的内容。实现了主从复制之后,一方面能够实现数据的读写分离,降低master的压力,另一方面也能实现数据
的备份。
方式一:
5.2 配置(方式一)
假设我有三个redis实例,地址分别如下:
114.116.XX.XXX:6379
114.116.XX.XXX:6380
114.116.XX.XXX:6381
即同一台服务器上三个实例,配置方式如下:
- 将redis.conf文件更名为redis6379.conf,方便我们区分,然后把redis6379.conf再复制两份,分别为redis6380.conf和redis6381.conf。
- 打开redis6379.conf,将如下配置均加上6379,(默认是6379的不用修改),如下:
port 6379
pidfile /var/run/redis_6379.pid
logfile "6379.log"
dbfilename dump6379.rdb
appendfilename "appendonly6379.aof"
- 同理,分别打开redis6380.conf和redis6381.conf两个配置文件,将第二步涉及到6379的分别改为6380和6381。
- 输入如下命令,启动三个redis实例:
[root@localhost redis-4.0.8]# redis-server redis6379.conf
[root@localhost redis-4.0.8]# redis-server redis6380.conf
[root@localhost redis-4.0.8]# redis-server redis6381.conf
- 输入如下命令,分别进入三个实例的控制台:
[root@localhost redis-4.0.8]# redis-cli -p 6379
[root@localhost redis-4.0.8]# redis-cli -p 6380
[root@localhost redis-4.0.8]# redis-cli -p 6381
此时我就成功配置了三个redis实例了。
- 假设在这三个实例中,6379是主机,即master,6380和6381是从机,即slave,那么如何配置这种实例关系呢,很简单,分别在6380和6381上执行如下命令:
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379
OK
这一步也可以通过在两个从机的redis.conf中添加如下配置来解决:
replicaof 127.0.0.1 6379
masterauth 123
OK,主从关系搭建好后,我们可以通过如下命令可以查看每个实例当前的状态,如下:
127.0.0.1:6379> INFO replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=56,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=56,lag=0
master_replid:26ca818360d6510b717e471f3f0a6f5985b6225d
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:56
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:56
我们可以看到6379是一个主机,上面挂了两个从机,两个从机的地址、端口等信息都展现出来了。如果我们在6380上执行INFO replication,显示信息如下:
127.0.0.1:6380> INFO replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:630
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:26ca818360d6510b717e471f3f0a6f5985b6225d
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:630
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:630
我们可以看到6380是一个从机,从机的信息以及它的主机的信息都展示出来了。
7.此时,我们在主机中存储一条数据,在从机中就可以get到这条数据了。
5.3 方式二(主从结构如下图 )
搭建方式很简单,在前文基础上,我们只需要修改6381的master即可,在6381实例上执行如下命令,让6381从6380实例上复制数据,如下:
127.0.0.1:6381> SLAVEOF 127.0.0.1 6380
OK
此时,我们再看6379的slave,如下:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=0,lag=1
master_replid:4a38bbfa37586c29139b4ca1e04e8a9c88793651
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:0
只有一个slave,就是6380,我们再看6380的信息,如下:
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:70
slave_priority:100
slave_read_only:1
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=70,lag=0
master_replid:4a38bbfa37586c29139b4ca1e04e8a9c88793651
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:70
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:70
5.3 注意点
- 如果主机已经运行了一段时间了,并且了已经存储了一些数据了,此时从机连上来,那么从机会将主机上所有的数据进行备份,而不是从连接的那个时间点开始备份。
- 配置了主从复制之后,主机上可读可写,但是从机只能读取不能写入(可以通过修改redis.conf中 replica-read-only 的值让从机也可以执行写操作)。
- 在整个主从结构运行过程中,如果主机不幸挂掉,重启之后,他依然是主机,主从复制操作也能够继续进行。
六、哨兵模式
当主机宕机时,就会发生群龙无首的情况,如果在主机宕机时,能够从从机中选出一个来充当主机,那么就不用我们每次去手动重启主机了,这就涉及到一个新的话题,那就是哨兵模式。
所谓的哨兵模式,其实并不复杂,我们还是在我们前面的基础上来搭建哨兵模式。假设现在我的master是6379,两个从机分别是6380和6381,两个从机都是从6379上复制数据。先按照上文的步骤,我们配置好一主二仆,然后在redis目录下打开sentinel.conf文件,做如下配置:
sentinel monitor mymaster 127.0.0.1 6379 1
sentinel auth-pass mymaster 123
其中mymaster是给要监控的主机取的名字,随意取,后面是主机地址,最后面的2表示有多少个sentinel认为主机挂掉了,就进行切换(我这里只有一个,因此设置为1)。好了,配置完成后,输入如下命令启动哨兵:
redis-sentinel sentinel.conf
然后启动我们的一主二仆架构,启动成功后,关闭master,观察哨兵窗口输出的日志,如下:
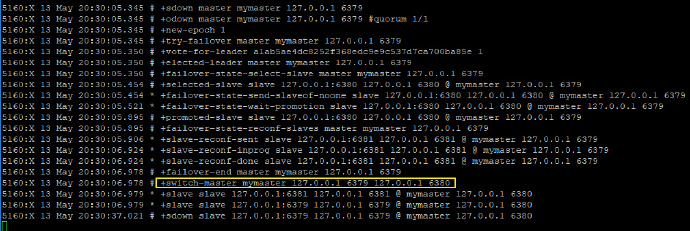
小伙伴们可以看到,6379挂掉之后,redis内部重新举行了选举,6380重新上位。此时,如果6379重启,也不再是扛把子了,只能屈身做一个slave了。
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。因此我们还需要集群来进一步提升redis性能,这个问题我们将在后面说到。
七、Redis集群
集群原理
Redis 集群架构如下图:
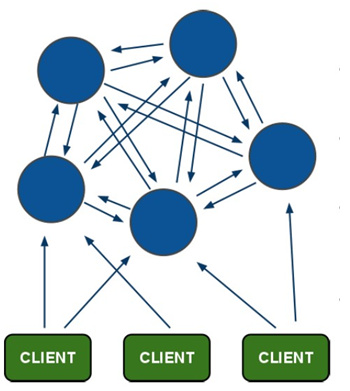
Redis 集群运行原理如下:
- 所有的 Redis 节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
- 节点的 fail 是通过集群中超过半数的节点检测失效时才生效
- 客户端与 Redis 节点直连,不需要中间 proxy 层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- Redis-cluster 把所有的物理节点映射到 [0-16383]slot 上,cluster (簇)负责维护
node<->slot<->value。Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个key-value 时,Redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,Redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
怎么样投票
投票过程是集群中所有 master 参与,如果半数以上 master 节点与 master 节点通信超过 cluster-node-timeout 设置的时间,认为当前 master 节点挂掉。
怎么样判定节点不可用
- 如果集群任意 master 挂掉,且当前 master 没有 slave.集群进入 fail 状态,也可以理解成集群的 slot 映射 [0-16383] 不完整时进入 fail 状态。
- 如果集群超过半数以上 master 挂掉,无论是否有 slave,集群进入 fail 状态,当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误。
ruby 环境
Redis 集群管理工具 redis-trib.rb 依赖 ruby 环境,首先需要安装 ruby 环境:
安装 ruby:
yum install ruby
yum install rubygems
但是这种安装方式装好的 ruby 版本可能不适用,如果安装失败,可以参考这篇文章解决redis requires Ruby version >= 2.2.2。
集群搭建
首先我们对集群做一个简单规划,假设我的集群中一共有三个节点,每个节点一个主机一个从机,这样我一共需要 6 个 Redis 实例。首先创建 redis-cluster 文件夹,在该文件夹下分别创建 7001、7002、7003、7004、7005、7006 文件夹,用来存放我的 Redis 配置文件,如下:

将 Redis 也在 redis-cluster 目录下安装一份,然后将 redis.conf 文件向 7001-7006 这 6 个文件夹中分别拷贝一份,拷贝完成后,分别修改如下参数:
port 7001
#bind 127.0.0.1
cluster-enabled yes
cluster-config-XXXXX7001.conf
protected no
daemonize yes
masterauth 123
这是 7001 目录下的配置,其他的文件夹将 7001 改为对应的数字即可。修改完成后,进入到 redis 安装目录中,分别启动各个 redis,使用刚刚修改过的配置文件,如下:
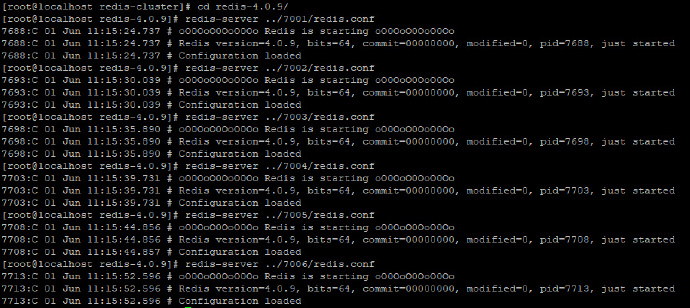
启动成功后,我们可以查看 redis 进程,如下:
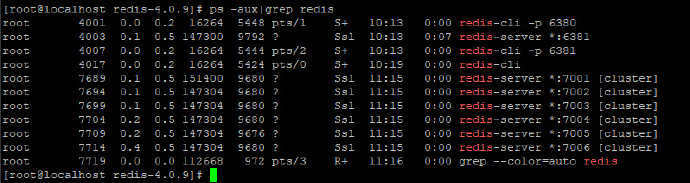
这个表示各个节点都启动成功了。接下来我们就可以进行集群的创建了,首先将 redis/src 目录下的 redis-trib.rb 文件拷贝到 redis-cluster 目录下,然后在 redis-cluster 目录下执行如下命令:
./src/redis-cli --cluster create --cluster-replicas 1 192.168.91.130:7001 192.168.91.130:7002 192.168.91.130:7003 192.168.91.130:7004 192.168.91.130:7005 192.168.91.130:7006 -a 123
旧版写法(Redis5之前)
./redis-trib.rb create --replicas 1 192.168.248.128:7001 192.168.248.128:7002 192.168.248.128:7003 192.168.248.128:7004 192.168.248.128:7005 192.168.248.128:7006
注意,replicas 后面的 1 表示每个主机都带有 1 个从机,执行过程如下:
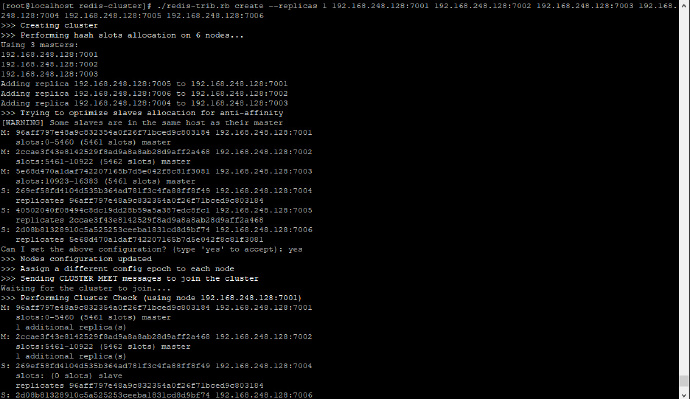
注意创建过程的日志,每个redis都获得了一个编号,同时日志也说明了哪些实例做主机,哪些实例做从机,每个从机的主机是谁,每个主机所分配到的hash槽范围等等。
查询集群信息
集群创建成功后,我们可以登录到 Redis 控制台查看集群信息,注意登录时要添加 -c 参数,表示以集群方式连接,如下:
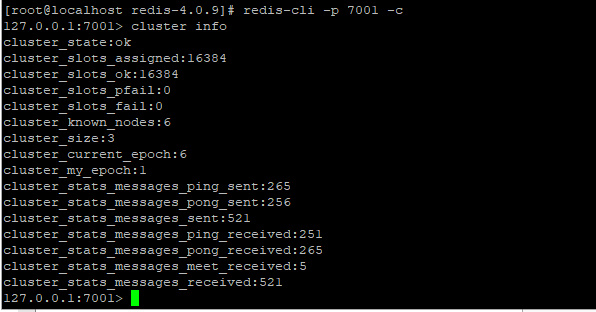

添加主节点
首先我们准备一个端口为 7007 的主节点并启动,准备方式和前面步骤一样,启动成功后,通过如下命令添加主节点:
redis-6.2.5/src/redis-cli -a 123 -p 7001 --cluster add-node 127.0.0.1:7007 127.0.0.1:7001
./redis-trib.rb add-node 127.0.0.1:7007 127.0.0.1:7001
主节点添加之后,我们可以通过 cluster nodes 命令查看主节点是否添加成功,此时我们发现新添加的节点没有分配到 slot,如下:

没有分配到 slot 将不能存储数据,此时我们需要手动分配 slot,分配命令如下:
redis-6.2.5/src/redis-cli -a 123 -p 7001 --cluster reshard 127.0.0.1:7001
./redis-trib.rb reshard 127.0.0.1:7001
后面的地址为任意一个节点地址,在分配的过程中,我们一共要输入如下几个参数:
- 一共要划分多少个 hash 槽出来?就是我们总共要给新添加的节点分多少 hash 槽,这个参数依实际情况而定,如下:

- 这些划分出来的槽要给谁,这里输入 7007 节点的编号,如下:

- 要让谁出血?因为 hash 槽目前已经全部分配完毕,要重新从已经分好的节点中拿出来一部分给 7007,必然要让另外三个节点把吃进去的吐出来,这里我们可以输入多个节点的编号,每次输完一个点击回车,输完所有的输入 done 表示输入完成,这样就让这几个节点让出部分 slot,如果要让所有具有 slot 的节点都参与到此次 slot 重新分配的活动中,那么这里直接输入 all 即可,如下:

OK,主要就是这几个参数,输完之后进入到 slot 重新分配环节,分配完成后,通过 cluster nodes 命令,我们可以发现 7007 已经具有 slot 了,如下:

OK,刚刚我们是添加主节点,我们也可以添加从节点,比如我要把 7008 作为 7007 的从节点,添加方式如下:
redis-6.2.5/src/redis-cli -a 123 -p 7001 --cluster add-node 127.0.0.1:7008 127.0.0.1:7001 --cluster-slave --cluster-master-id 8e8eedb372b9dc36a57ff81d4b4b4634f3f2bffa
./redis-trib.rb add-node --slave --master-id 79bbb30bba66b4997b9360dd09849c67d2d02bb9 192.168.31.135:7008 192.168.31.135:7007
其中 79bbb30bba66b4997b9360dd09849c67d2d02bb9 是 7007 的编号。
删除节点
删除节点也比较简单,如下:
redis-6.2.5/src/redis-cli -a 123 -p 7001 --cluster del-node 127.0.0.1:7001 ce53609f0fc6b0af5daf2ce37d6c4ec5798c7d98
./redis-trib.rb del-node 127.0.0.1:7005 4b45eb75c8b428fbd77ab979b85080146a9bc017
注意 4b45eb75c8b428fbd77ab979b85080146a9bc017 是要删除节点的编号。
再注意:删除已经占有 hash 槽的结点会失败,报错如下:
[ERR] Node 127.0.0.1:7005 is not empty! Reshard data away and try again.
需要将该结点占用的 hash 槽分配出去(分配方式与上文一致,不赘述)。
Jedis 操作 RedisCluster
public class RedisCluster {
public static void main(String[] args) {
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.91.128", 7001));
nodes.add(new HostAndPort("192.168.91.128", 7002));
nodes.add(new HostAndPort("192.168.91.128", 7003));
nodes.add(new HostAndPort("192.168.91.128", 7004));
nodes.add(new HostAndPort("192.168.91.128", 7005));
nodes.add(new HostAndPort("192.168.91.128", 7006));
nodes.add(new HostAndPort("192.168.91.128", 7007));
JedisPoolConfig config = new JedisPoolConfig();
//连接池最大空闲数
config.setMaxIdle(300);
//最大连接数
config.setMaxTotal(1000);
//连接最大等待时间,如果是 -1 表示没有限制
config.setMaxWaitMillis(30000);
//在空闲时检查有效性
config.setTestOnBorrow(true);
JedisCluster cluster = new JedisCluster(nodes, 15000, 15000, 5, "javaboy", config);
String set = cluster.set("k1", "v1");
System.out.println(set);
String k1 = cluster.get("k1");
System.out.println(k1);
}
}















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









