







问题1:ZipList虽然节省内存,但是申请的内存必须是连续的内存空间,如果内存占用较多,申请内存效率很低,怎么办?
为了缓解这个问题,我们必须限制ZipList的长度和 entry 的大小
问题2:如果我们要存储大量数据,超出了 ZipList 的最佳上限怎么办?
我们可以创建多个 ZipList 来分开存储数据
问题3:数据拆分后比较分散,不方便管理和查找,这些ZipList怎么建立关联?
Redis 在 3.2 版本中引入了 QuickList ,它是一个双端链表,只不过链表的每一个节点都是一个ZipList
为了避免 QuickList 中的每个 ZipList 中的 entry 过多,redis 提供了一个配置项:
list-max-ziplist-size 来限制
如果值为正:则代表 ZipList 中的 entry 个数的最大值
如果值为负: 则代表 ZipList 的最大内存大小,有下列五种情况
-1:每个 ZipList 的内存占用不超过 4kb
-2:每个 ZipList 的内存占用不超过 8kb (默认值)
-3:每个 ZipList 的内存占用不超过 16kb
-4:每个 ZipList 的内存占用不超过 32kb
-5:每个 ZipList 的内存占用不超过 64kb

QuickList除了控制 ZipList 的大小,还可以对节点的 ZipList 做压缩,通过配置项
list-compress-depth 来控制
因为链表一般都是从首尾进行访问的 ,所以首尾是不压缩的。这个参数用来控制首尾不压缩的个数
0:(默认值)代表首尾不压缩
1: 表示首尾各有一个节点不压缩
2: 表示首尾各有两个节点不压缩
以此类推

以下是 QuickList 和 QuickListNode 的结构源码


QuickLIst的大致结构如下:
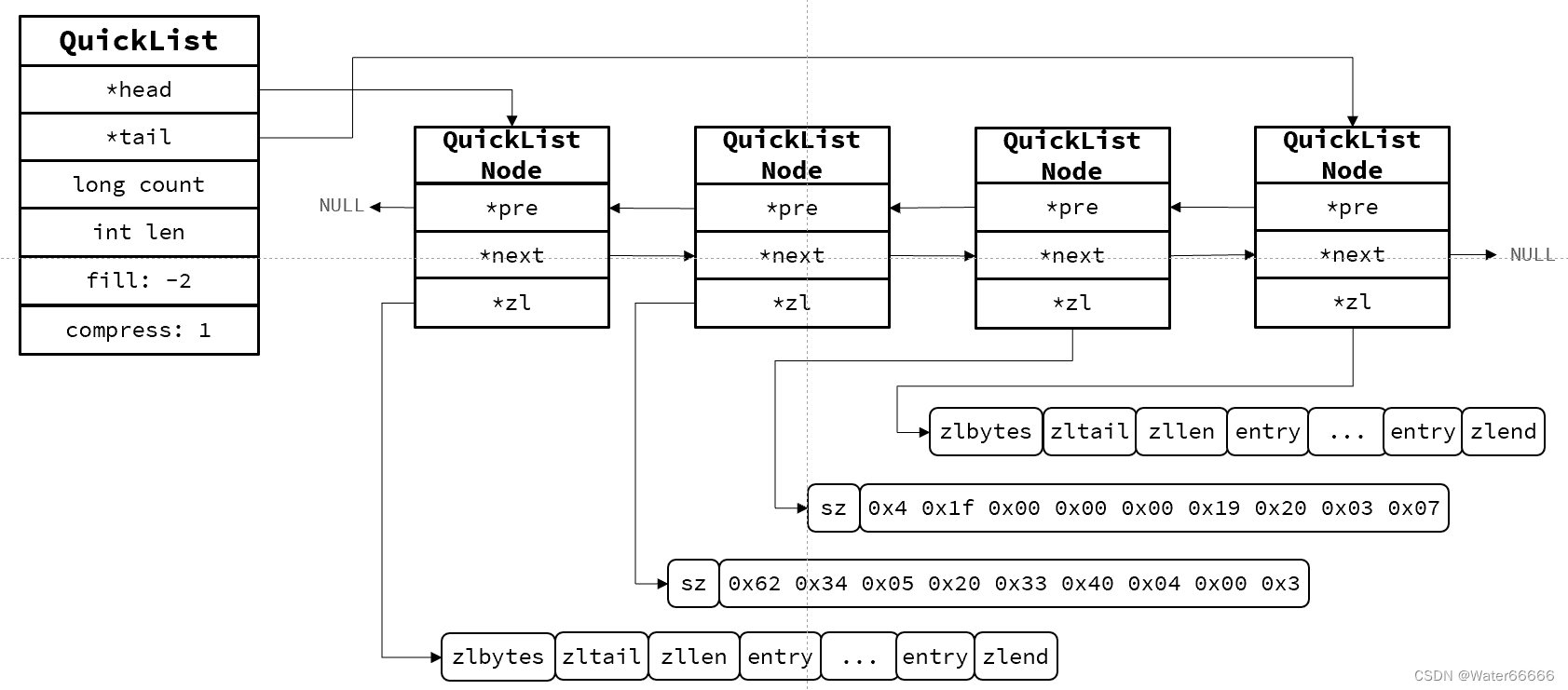
QuickList 的特点:
1.是一个节点为 ZipList 的双端链表
2.节点采用了 ZipList ,解决了传统链表的内存占用问题
3.能控制 ZipList 的大小,解决连续内存空间申请的效率问题
4.中间节点可以进行压缩,进一步节省了内存空间















 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









