







1 Transformer与注意力机制详解
本文直观上详细介绍了大语言模型中十分重要的结构——Transformer,及其核心:注意力机制的原理。
1. Transformer结构
基础结构如下图所示,左侧由一系列Encoder block(编码器)构成,接收字词句输入;右侧由一系列Decoder block(解码器)构成,输出结果。
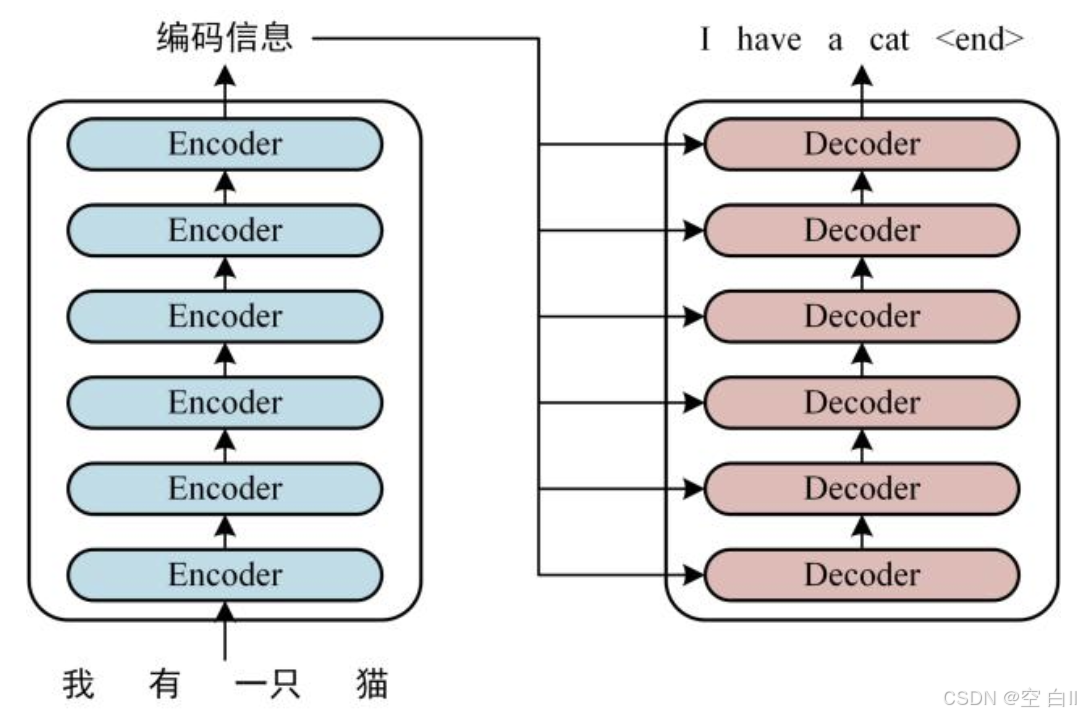
- Embedding 层:将输入的字词句转为向量表示,每个词对应一个向量表示(维度人为指定)。如上图中的“我有一只猫”,一共五个词,若embedding的维度为64,则embedding后的矩阵为5*64。
- Positional Encoding(位置编码)层:提取一句话中各个字词的前后位置关系,便于理解语义与逻辑。如“我有猫”和“猫有我”是完全不一样的意思,但所含的词是完全相同的。
- Multi-Head Attention(多头注意力机制)层:用于捕获一句话中前后字词的注意力重点,如“我有一只猫”中,“有”和“猫”两个词的注意力得分就要大于“有”和“只”的,即提取句子中的前后主要逻辑关系。
- Add&Norm层:进行残差连接和归一化
- FeedForward层:包括两层线性变换,与一层非线性变换,通常是Relu,先将数据映射到高纬度的空间再映射到低纬度的空间,提取更深层次的特征
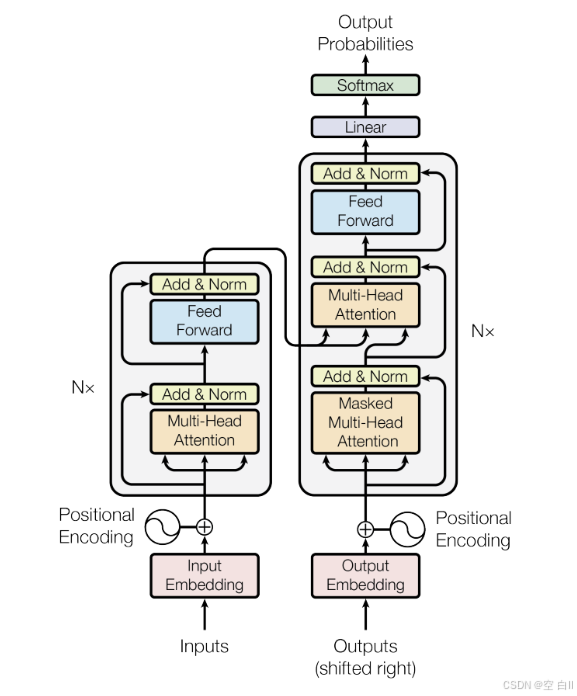
整体流程为(看完下述注意力机制再回来看会更明白些):Encoder模块对于输入提取注意力并进行线性变换,得到包括语句所有字词的信息结果,将其转换为k,v输入Decoder中;Decoder首先使用mask self attention得到前i个已知字词,将后面i+1个需要预测的字词都用mask掩盖,然后生成对应的q(查询); 最终,将两者的k,v,q共同输入Decoder的第二个self attention中计算,输出预测结果。
2. 注意力机制详解
注意力机制最核心的内容为Q、K、V三个参数,分别代表查询、键、值。其中,查询类似你在搜索引擎中输入的问题,键与值组成键值对作为庞大知识库中的内容。
- Q、K、V定义以及关系:
Q:查询(维度通常为N × d,N是序列长度(即token 数量),d是词向量的维度(即embedding的维度),即Q代表查找的目标的关键字
K:键(维度为Nd),即知识库内容V的简易总结版,用于接收查找Q的关键信息并与其进行相似度比对
V:值(维度为Nd),即每个K对应的内容 - 注意力机制计算公式为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T ( d k ) ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt(d_k)})V Attention(Q,K,V)=softmax(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











