







文章目录
数据结构与算法
动态数组
Vector与ArrayList
-
Vector:
jdk早期的集合实现类,线程安全的(synchronized)
在创建Vector时,数组的长度就已经指定:10。
当容量不足的时候进行扩容,如果 capacityIncrement不是0,则增长为原有容量+ capacityIncrement;
如果capacityIncrement 是0则增长为原来的2倍。 -
ArrayList:
创建ArrayList对象的时候底层是空的数组
当第一次添加的时候,才会去开辟空间,默认大小是10
是线程不安全的
扩容到原来的1.5倍 -
共同点:都是采用Object[] 数组存储数据
链式存储结构
- 逻辑结构:有线性的和非线性的
- 物理结构:不要求连续的存储空间
- 存储特点:数据必须封装到“节点”中,节点包含多个数据项,数据值只是其中的一个数据项,其他的数据项用来记录与之有关的节点的地址
链表

单链表
单链表添加与实现
- 单链表采用节点存储数据,一部分存储数据,一部分存储下一个节点的地址
- 定义内部类,构建节点
两个属性:数据 data 、下一个节点的地址 next - 定义一个头节点,用于存储后来的数据
- 定义一个变量,记录节点数量
import java.util.Arrays;
public class MySingleWayList<E> {
//定义头节点
private Node head;
//定义变量 记录元素数量
private int count;
public void remove(E e) {
//0.当链表没有数据时,不能进行删除操作
if (head == null) {
System.out.println("此链表无数据,不能进行删除操作");
return;
}
//1.当元素为null时
if (e == null) {
//1.1 删除的是头节点
if (head.data == null) {
//找到头节点的下一个节点
Node node = head.next;
//方便垃圾回收器快速回收垃圾
head.data = null;
head.next = null;
//把下一个节点变成头节点
head = node;
count--;
} else {
//1.2 删除的不是头节点
Node node = head;
//定义变量,记录前一个节点
Node preNode = null;
while (node.data != null) {
//此时记录的是删除节点的前一个节点
//节点不是null,则下一个可能是null的要删除的节点的前一个节点
preNode = node;
//切换到下一个数据不为null的节点
node = node.next;
if (node.data == null) {
break;
}
}
//当node为null时,说明当前的链表内没有null数据
if (node != null) {
preNode.next = node.next;
node.next = null;
node.data = null;
count--;
}
}
}else{
//2.当元素不为null时
//1.1 删除的是头节点
if (e.equals(head.data)) {
//找到头节点的下一个节点
Node node = head.next;
//方便垃圾回收器快速回收垃圾
head.data = null;
head.next = null;
//把下一个节点变成头节点
head = node;
count--;
} else {
//1.2 删除的不是头节点
Node node = head;
//定义变量,记录前一个节点
Node preNode = null;
while (!e.equals(node.data)) {
//此时记录的是删除节点的前一个节点
//节点不是null,则下一个可能是null的要删除的节点的前一个节点
preNode = node;
//切换到下一个数据不为null的节点
node = node.next;
/*if (node.data.equals(e)) {
break;
}*/
}
//当node为null时,说明当前的链表内没有null数据
if (node != null) {
preNode.next = node.next;
node.next = null;
node.data = null;
count--;
}
}
}
}
public void add(E e) {
//0.将数据包装为节点
Node newNode = new Node(e, null);
//1.判断是否为空链表
if (head == null) {
head = newNode;
} else {
//2.不是空链表,在最后进行数据追加
Node node = head;
//寻找最后的节点
while (node.next != null) {//头节点的下一个不为空
node = node.next;
}
//将新添加的节点追加到最后
node.next = newNode;
}
//添加成功,数量+1
count++;
}
public int size() {
return count;
}
@Override
public String toString() {
//新建一个数组,存储数据
Object[] objects = new Object[count];
//遍历链表 拿到数据
Node node = head;
for (int i = 0; i < objects.length; i++) {
objects[i] = node.data;//获取节点数据并添加到数组内
node = node.next;//切换到下一个节点
}
//遍历数组返回结果
return Arrays.toString(objects);
}
private class Node {
private Object data;
private Node next;
public Node(Object data, Node next) {
this.data = data;
this.next = next;
}
}
}
public class MySingleWayListTest {
public static void main(String[] args) {
MySingleWayList<String> my = new MySingleWayList<>();
System.out.println(my.size());//0
my.add( "你好");
my.add(null);
my.add( "世界");
System.out.println(my.size());//3
System.out.println(my);//[你好, null, 世界]
my.remove("你好");
System.out.println(my.size());//2
System.out.println(my);//[null, 世界]
}
}
双链表
LinkedList存储和方法
import java.util.LinkedList;
public class LinkedListTest {
public static void main(String[] args) {
//双端循环列表
//LinkedList新增了操作头尾的方法
LinkedList<String> list = new LinkedList<>();
list.add("A");
list.add("B");
list.add("C");
list.addFirst("张三");
list.addLast("李四");
System.out.println(list);
//返回被删除的元素
String s = list.removeFirst();
System.out.println(s);
System.out.println(list);
System.out.println(list.getFirst());
}
}
二叉树
二叉树实现基本结构
二叉树分类
-
满二叉树:除最后一层无任何子节点外,每一层上的所有节点都有两个子节点的二叉树。第n层的节点数是2的n-1次方,2的n次方-1
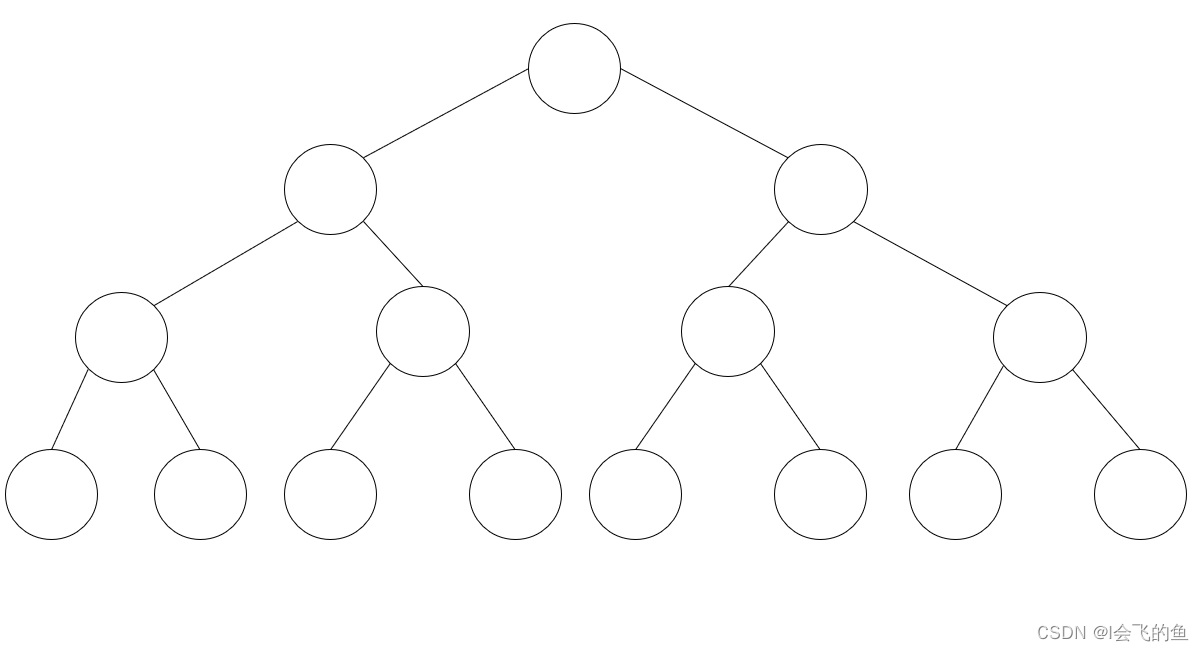
-
完全二叉树:叶节点只能出现在最底层的两层,且最底层叶节点均处于次底层叶节点的左侧
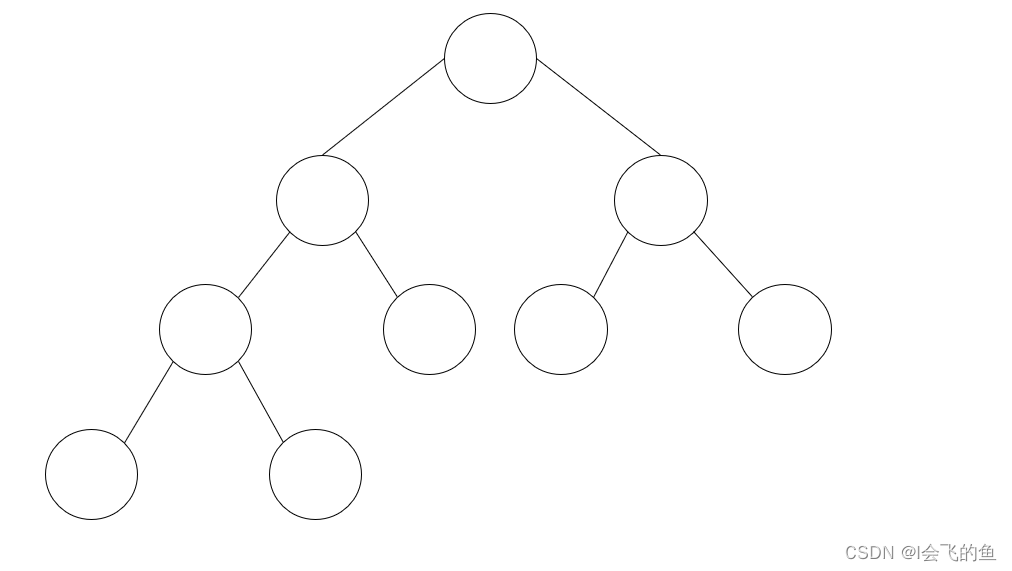
-
平衡二叉数:又被称为AVL数,具有一下性质:它是一个棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树,但不要求非叶节点都有两个子节点
二叉树遍历
- 前序(根)遍历:中左右
- 中序(根)遍历:左中右
- 后序(根)遍历:左右中
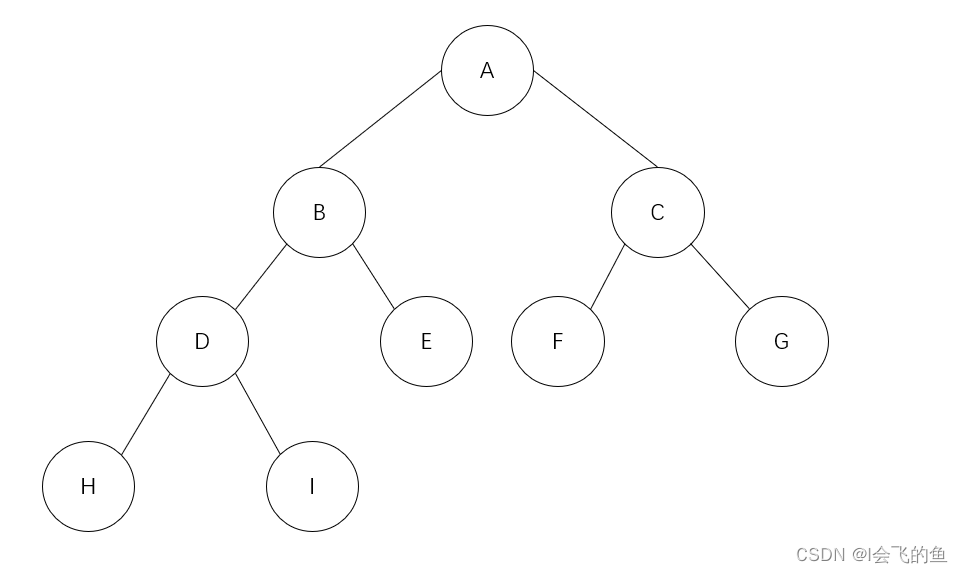
前序遍历:ABDHIECFG
中序遍历:HDIBEAFCG
后序遍历:HIDEBFGCA
栈和队列
栈操作
import java.util.Stack;
public class DataTest {
public static void main(String[] args) {
//模拟栈操作
// 入栈和出栈都是对栈顶元素而言
// 先进后出
Stack<String> stack = new Stack<>();
stack.push("你好");
stack.push("世界");
System.out.println(stack);//[你好, 世界]
//获取栈顶元素
System.out.println(stack.peek());//世界
//弹栈
System.out.println(stack.pop());//世界
//再次获取栈顶元素
System.out.println(stack.peek());//你好
}
}
队列操作
package com.zzy.data;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
public class DataTest {
public static void main(String[] args) {
//队列操作:先进先出
Queue<String> queue = new LinkedList<>();
//入队
queue.add("顾客1");
queue.add("顾客2");
queue.add("顾客3");
System.out.println(queue);//[顾客1, 顾客2, 顾客3]
//出队
queue.remove();//无元素时使用发生异常
queue.poll();//无元素时使用不发生异常
System.out.println(queue);//[顾客3]
}
}
哈希表
- hash表:顺序表+链表
- 顺序表:查找元素块;每存储一个元素,就开辟一个空间;有长度限制,如果全部采用顺序表存储,会造成空间浪费;顺序表长度永远是2^n
- 链表:不限长度;查找元素比较慢
- hash表如何进行数据存储:
- 计算一个对象的hash码
- 对hash码进行散列处理,尽量避免hash冲突
- 会采用处理后的hash码 & 顺序表长度 -1
jdk1.7hash表数据存储
1.7jdk map
-
认识成员变量:
DEFAULT_INITIAL_CAPACITY = 16;默认顺序表长度MAXIMUM_CAPACITY = 1 << 30;顺序表的最大长度
DEFAULT_LOAD_FACTOR = 0.75f;默认的加载因子
Entry<K,V>[] table;顺序表的数据类型
class Entry<K,V> implements Map.Entry<K,V>{
final K key;
V value;
Entry<K,V> next;
int hash;
}
transient int size; 集合中元素的数量
//The next size value at which to resize (capacity * load factor).
int threshold;阈(开关/阀门)值 12
- 当创建我完对象后
底层Entry类型的数组已经完成初始化长度为16
阈值的值是12
加载因子是0.75f - 调用put()方法
- 如果key为null
会将数据存储到顺序表中下标为0的位置,如果已经存在key为null的数据,则直接将新数据替换掉原来的旧数据并将旧的value进行返回 - 如果key不为null:
调用hash方法对key进行散列算法拿到hash值
indexFor(hash,数组的长度);计算在hash表内顺序表的位置
1. 当指定位置有数据时
(1)有key重复数据
如果key重复了,则将新的value替换掉旧的value并将旧的value进行返回
(2)没有重复数据:七上
新增一个节点,并将此节点放到顺序表中的第一个位置,之前的旧数据会在新数据的后面进行追加
2. 当指定位置没有数据时
新增一个entry节点
- 如果key为null
- 顺序表什么时候扩容:
- 当size >= 阈值(初始化长度 * 加载阈值)
- 要存入的位置要有数据
满足以上条件进行扩容,扩容规则:2 * table.length
加载因子如果太小,会造成顺序表太长:空间浪费
加载因子太大,会造成链表太长,影响查找元素的效率
public class Map7{
public static void main(String[] args){
HashMap<Integer,String> map = new HashMap();
/*map.put(null,"你好");
String key = map.put(null, "世界");
System.out.println(key);//你好
System.out.println(map);//{null=世界}*/
map.put(1,"世界");
map.put(16,"张三");
String oldValue = map.put(16, "李四");
System.out.println(oldValue);//张三
System.out.println(map);//{16=李四, 1=世界}
}
}
jdk1.8hash表数据存储
jdk1.7 是采用顺序表+链表
jdk1.8 是采用顺序表+链表+红黑树(二叉树):当链表数量>8的时候会转为红黑树进行存储
-
认识成员变量
默认底层数组长度:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16底层数组的最大长度
static final int MAXIMUM_CAPACITY = 1 << 30;默认的加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;树化的阈值
static final int TREEIFY_THRESHOLD = 8;非树化的阈值
static final int UNTREEIFY_THRESHOLD = 6;最小的数化容量
static final int MIN_TREEIFY_CAPACITY = 64;当前集合内元素的数量
transient int size;底层顺序表的数据类型
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
- 创建完对象之后
将加载因子给成员变量赋值了 ,没有给底层数组开辟空间

- 调用put()方法

-
第一步对key进行hash运算

如果key==null; hash:0
如果key!=null;进行位运算
为了减少hash冲突 -
当第一次调用put()
完成了对底层数组的创建 Node[] 长度是16;阈值变为12 -
1.当第一次想指定位置添加数据的时候,此位置没有数据,直接新增
2.当第二次添加 ,存储的位置是有值的;
key不重复,直接向原有数据的末尾进行元素的追加(八下)
key不重复,链表的数量已经达到8,并且底层数组的长度已经>64才会进行树化操作,将数据转为红黑树进行存储
3.当第三次添加
key重复:新数据会替换掉旧数据,并将旧数据返回
-
public class Map8 {
public static void main(String[] args) {
HashMap<Integer,String> map = new HashMap<>();
map.put(10,"你好");
map.put(20,"世界");
String oldValue = map.put(20, "张三");
System.out.println(oldValue);//世界
System.out.println(map);//{20=张三, 10=你好}
}
}
其他set集合对应的map
/*
hashSet底层采用的是hashMap存储数据,数据放到了key的位置
private static final Object PRESENT = new Object();
所有的value都共用这一个对象PRESENT
*/
HashSet<String> hashSet = new HashSet<>();
hashSet.add("张三");
hashSet.add("张三");
/*
TreeSet底层采用TreeMap存储数据
*/
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(10);
/*
LinkedHashSet底层采用的是HashMap
private static final Object PRESENT = new Object();
*/
LinkedHashSet<Integer> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add(10);















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









