






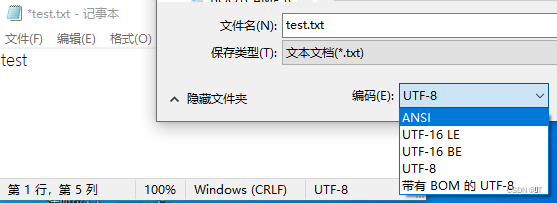
正如上图所示,txt文件有5种编码格式,分别是ANSI、UTF-8、UTF-8 with BOM、UTF-16LE、UTF-16BE。而平常我们大多数使用的是UTF-8。毕竟默认创建的就是。如果想知道其BOM编码直接划到底部。
图片中写入test的是一个不带BOM的UTF-8编码的txt(UTF-8是一个变长的字符编码),因此,我们有时读取或者写入txt时,遇到中文时就会出现乱码。因此,我们在读取时需要考虑这五种编码,其中ANSI和UTF-8可以分为一类处理(因为UTF-8的英文和其他ANSI编码几乎是对应的),剩下的只需要考虑BOM,而它的BOM反正头部几个字节,读取时需要特别处理一下。
ANSI:全英文,都是一字节一字符。
UTF-8 without BOM:只考虑了中文和英文。以字节的方式读取,使用MultiByteToWideChar,其中的CodePage选择CP_UTF8。
UTF-8 with BOM:只考虑了中文和英文。以字节方式读取,要舍去三字节。再使用UTF-8 without BOM的方法读取。
以下两个只考虑中文和英文,其他可能为4字节
UTF-16LE:小端(高位字节放高位地址):一般是Unicode编码存放在txt文件中,即宽字节,WIndow按字节读取后可直接转换为wchar_t类型。(要舍去两字节的BOM编码)
UTF-16BE:大端(高位字节放低位地址):一般是Unicode编码存放在txt文件中,即宽字节,
那么两个字节要进行反序。
wide_buffer[i] = (buffer[i * 2] << 8) | buffer[i * 2+1];
读取本人使用ReadFile按字节读取,写入使用ReadFile按字节写入。
UTF-8 with BOM : 0xFE 0xBB 0xBF 3字节 变长编码
UTF-16LE: 0xFF 0xFE 2字节 变长编码
UTF-16BE: 0xFE 0xFF 2字节 变长编码
UTF-32LE: 0xFF 0xFE 0x00 0x00 4字节 固长编码
UTF-32BE: 0x00 0x00 0xFE 0xFF 4字节 固长编码















 1202
1202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









