






简介
相比于线性分类中的S = W×X,其中W是一个矩阵,X是一个列向量,包含图像的全部像素信息。它们相乘的直接结果就是得到一个得分向量。
像数据库CIFAR-10的案例中W是一个10×3072的矩阵,X是一个3072×1的向量,他们的结果就是得到10×1的得分向量》
神经元则不同,它的计算法则是
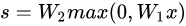
其中的W1可以是100×3072的矩阵与X相乘的到一个100×1的过度向量,max()函数是非线性的,这种非线性的函数有多种选择。W2是10×100的向量最终的到10×1的得分向量。注意非线性函数在计算上是至关重要的,如果略去这一步,那么两个矩阵将会合二为一。

前向传播计算举例
不断重复的矩阵乘法与激活函数交织。将神经网络组织成层状的一个主要原因,就是这个结构让神经网络算法使用矩阵向量操作变得简单和高效。用上面那个3层神经网络举例,输入是[3x1]的向量。一个层所有连接的强度可以存在一个单独的矩阵中。比如第一个隐层的权重W1是[4x3],所有单元的偏置储存在b1中,尺寸[4x1]。这样,每个神经元的权重都在W1的一个行中,于是矩阵乘法np.dot(W1, x)就能计算该层中所有神经元的激活数据。类似的,W2将会是[4x4]矩阵,存储着第二个隐层的连接,W3是[1x4]的矩阵,用于输出层。完整的3层神经网络的前向传播就是简单的3次矩阵乘法,其中交织着激活函数的应用。
# 一个3层神经网络的前向传播:
f = lambda x: 1.0/(1.0 + np.exp(-x)) # 激活函数(用的sigmoid)
x = np.random.randn(3, 1) # 含3个数字的随机输入向量(3x1)
h1 = f(np.dot(W1, x) + b1) # 计算第一个隐层的激活数据(4x1)
h2 = f(np.dot(W2, h1) + b2) # 计算第二个隐层的激活数据(4x1)
out = np.dot(W3, h2) + b3 # 神经元输出(1x1)
在上面的代码中,W1,W2,W3,b1,b2,b3都是网络中可以学习的参数。注意x并不是一个单独的列向量,而可以是一个批量的训练数据(其中每个输入样本将会是x中的一列),所有的样本将会被并行化的高效计算出来。注意神经网络最后一层通常是没有激活函数的(例如,在分类任务中它给出一个实数值的分类评分)。

更大的神经网络可以表达更复杂的函数。数据是用不同颜色的圆点表示他们的不同类别,决策边界是由训练过的神经网络做出的。
正则化强度是控制神经网络过拟合的好方法。看下图结果:

不同正则化强度的效果:每个神经网络都有20个隐层神经元,但是随着正则化强度增加,它的决策边界变得更加平滑。
需要记住的是:不应该因为害怕出现过拟合而使用小网络。相反,应该进尽可能使用大网络,然后使用正则化技巧来控制过拟合。















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









