






1.map集合是什么?
Map集合和Collection集合没有任何关系。Collection集合是以单个方式存储元素的,而Map集合是以键值对的方式存储元素,所有Map集合的Key是无序不可重复的,key和value都是引用数据类型,存的都是内存的地址。
Map集合的实现类主要为HashMap、HashTable。子接口有一个SortedMap,SortedMap有一个TreeMap实现类。
1.1 Map集合的特征
1.1 通过键-值(key-value)对的形式来存储数据
1.2 Map的实现:HashMap(使用频率最高的),TreeMap,HashTable
1.3 Map中,key可以为任意类型,但这里建议使用String,value也可以是任意类型
1.4 Map里面多个value可以是不同类型
1.5 Map里面key是可以重复的,当key重复时,后存入的数据会覆盖前面的数据
1.6 Map里面,value可以重复.
1.7 Map里面的key可以为null,但是只能有一个,多个的时候,后面的会覆盖前面的
1.8 Map中value可以是null,多个value可以同时为null。
1.9 Map中的key在底层可以理解为是一个Set
1.2 Map的常用方法
可以看出,Map中存放的是两种对象,一种称为key(键),一种称为value(值),它们在在Map中是一一对应关系,这一对对象又称做Map中的一个Entry(项);Map中的键不能重复,但值可以重复。Map接口中定义了如下常用方法:
boolean containsKey(Object key):判断是否包含指定的key
boolean containsValue(Object value):判断是否包含指定的value
V get(Object key):根据指定的key来获取对应的value
boolean isEmpty():判断集合是否为空
Set<K> keySet():Map中所有key的集合
V put(K key, V value):把指定的key-value存入Map集合
void putAll(Map<? extends K> m):把一个Map集合存入指定的Map中
V remove(Object key):根据key在Map中删除指定的key-value组合
int size():Map集合中key-value的长度
Collection<V> values():返回Map中所有的value的集合,不包括key
1.3 HashMap
import java.util.*;
public class HashMapDemo {
public static void main(String[] args) {
//1.创建HashMap对象,用来存放国家英文简写与国家中文全称
Map map = new HashMap();
//2.往HashMap添加元素(键-值对)
map.put("CN", "中华人民共和国");
map.put("RU", "俄罗斯联邦");
map.put("US", "美利坚合众国");
map.put("FR", "法兰西共和国");
//3.获取key为"CN"对应的值
String value = (String) map.get("CN");
System.out.println(value);
//4.向上集合元素的个数
System.out.println("map集合共有:"+map.size()+"个元素");
//5.判断是否存在"FR"的键
System.out.println("map集合中是否包含FR吗?"+map.containsKey("FR"));
//6 获取Map中键的集合和值得集合
System.out.println("map中key的集合:"+map.keySet());
System.out.println("map中value的集合:"+map.values());
}
}目的:遍历出map集合中所有数据
方法一:1.通过keySet()方法,找到所有key的集合,返回类型是一个Set;
2.通过Iterator迭代器,迭代出Set中的每一个key;
3.通过get(key)方法,根据上一步得到的key,来获取对应的value
Set keys = map.keySet();
Iterator iterator = keys.iterator();
while(iterator.hasNext()){
Object key = iterator.next();
Object val = map.get(key);
}方法二:1.通过values()方法,获取map集合中所有的value的集合.返回值类型为Collection(该接口是List和Set的父接口,该类型下有Iiterator迭代器,可以用来迭代)
Collection values = map.values();
Iterator iterator = values.iterator();
while(iterator.hasNext()){
Object value = iterator.next();
}方法三:1.通过entrySet()方法,得到一个Entry对象的集合,这里用Set来装载.
2.通过Set中的迭代器,迭代出每一个Entry对象.
3.针对每一个Entry对象,通过getKey()和getValue()方法,来分别获取到对应的key和value
Set entrySet = map.entrySet();
Iterator iterator = entrySet.iterator();
while(iterator.hasNext()){
Map.Entry entry = (Map.Entry)iterator.next();
Object key = entry.getKey();
Object value = entry.getValue();
}1.底层数据结构
HashMap的底层数据结构是和哈希表。
数组在查询方面效率很高,随机增删效率很低。单向链表在随机增删方面效率很高,在查询方面效率很低。
哈希表是数组和单向链表的结合体,将以上优势融合在一起。
前面写的无序不可重复此时可以解释。
无序:HashMap底层是哈希表,一个元素存进来之后不一定会存到哪个单链表上,因此取出的时候也不一定会以什么顺序取出去。
不可重复:HashMap在存入元素时,会将新存入的k与链表中的每一个key进行equals比对,如果重复则覆盖原先的value值。
HahsMap集合使用put方法时,底层会调用hashCode方法将key转换为hash值,然后根据哈希函数/哈希算法将哈希值转换为数组下标,若此下标的数组没有元素,则直接添加,若此下标的数组有链表,则将key与链表中每个节点的key进行equals比对,若都返回false,则将元素添加在链表末尾,若返回true,则将此节点的value覆盖。
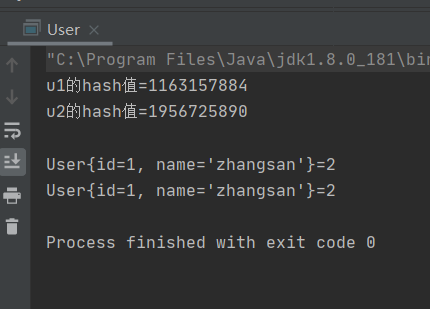
想要添加相同元素时需要重写hashCode方法使得key的哈希值不一致或者重新equals方法使得key对比时不相等。
重写hashCode
@Override
public int hashCode() {
return Objects.hash(id, name);
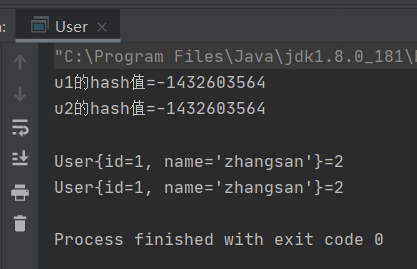
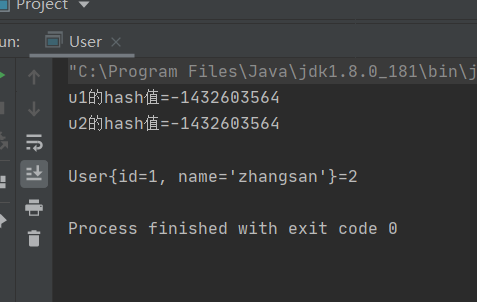
}public static void main(String[] args) {
Map<User,Integer> map=new HashMap<>();
User u1=new User(1,"zhangsan");
User u2=new User(1,"zhangsan");
System.out.println("u1的hash值="+u1.hashCode());
System.out.println("u2的hash值="+u2.hashCode());
map.put(u1,2);
map.put(u2,2);
System.out.println();
Set<Map.Entry<User, Integer>> entries = map.entrySet();
for (Map.Entry<User, Integer> entry : entries) {
System.out.println(entry.getKey()+"="+entry.getValue());
}
}
重新equals方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
Objects.equals(name, user.name);
}
重写hashCode和equals方法
存储原理:
-
它的底层会调用K的hashCode()方法得出hash值。
-
通过哈希表函数/哈希算法,将hash值转换成数组的下标.
-
下标位置上如果没有任何元素,就新创建一个Node节点,并添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









