




 本文详细指导如何使用Java与Hadoop进行交互,包括启动配置、eclipse集成、配置文件设置、创建Hadoop项目并实现DFS基本操作,适合Hadoop初学者快速上手。
本文详细指导如何使用Java与Hadoop进行交互,包括启动配置、eclipse集成、配置文件设置、创建Hadoop项目并实现DFS基本操作,适合Hadoop初学者快速上手。
如何用Java操作Hadoop
首先启动配置好的Hadoop平台,使用Hadoop文件夹中sbin子文件夹中的start-all,成功是4个节点都没有shutdown掉
namenode节点
datanode节点
resourcemanage节点
nodemanage节点
打开eclipse,下载一个hadoop-eclipse-plugin-2.7.3.jar的jar包放到eclipse安装目录中的plugins子目录下.
打开eclipse,Window->Preferences->Hadoop Map/Reduce,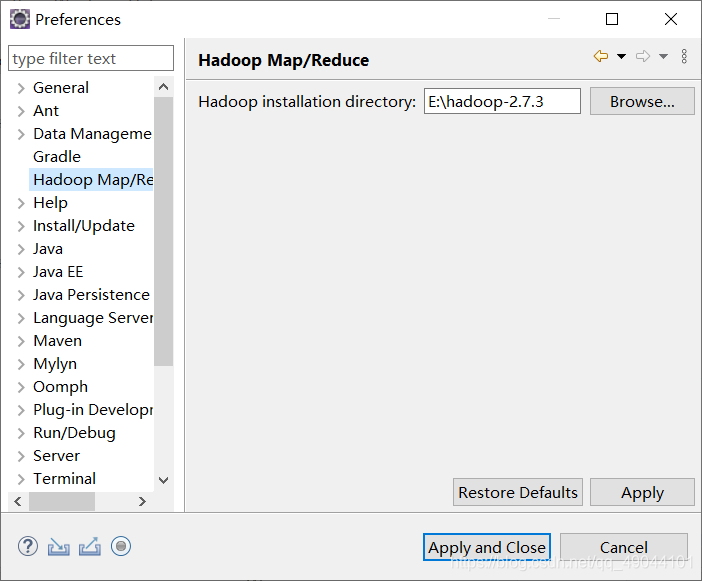
将安装目录修改为你自己的Hadoop安装目录
接下来打开window中的show view ->other选择MapReduce tools,双击eclipse下面会出来一个小黄象标志的状态栏,点击选中的小蓝象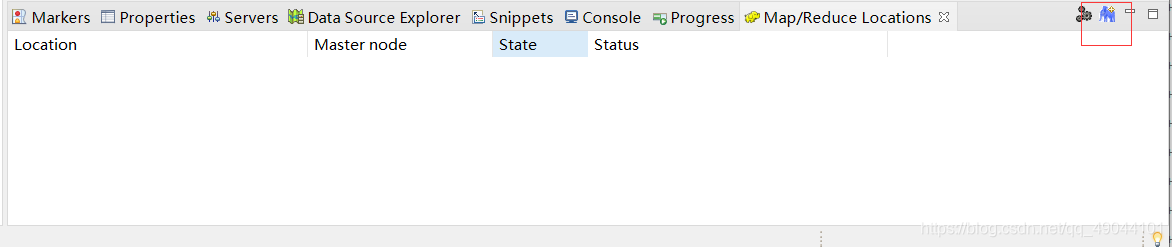
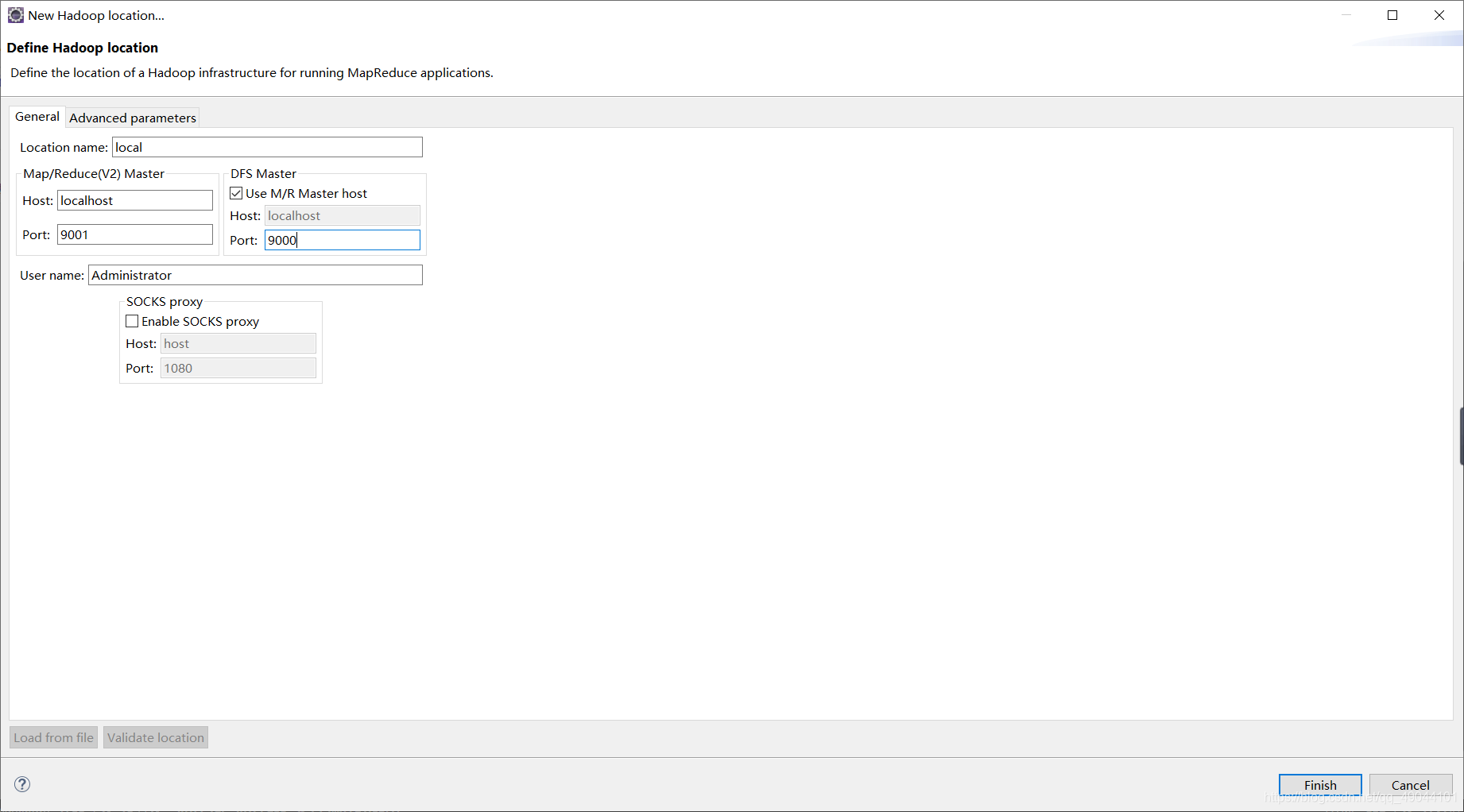
端口号分别填你配置的xml文件的端口号,我的分别是9001和9000,最后Finish
左边的工程目录会出现一个DFS的目录文件,这可以直接操作Hadoop中的增删改查
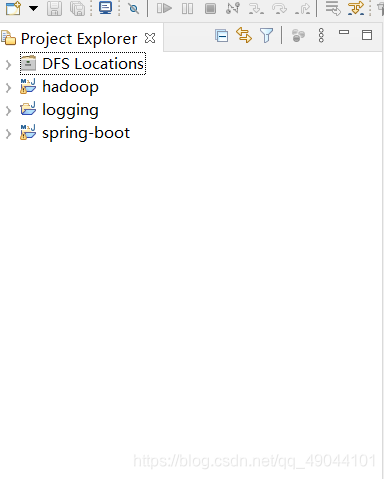
打开建立好的spring项目,将以下依赖放入到pom文件中
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
maven会自动帮你下好jar包并且放入库中
接下来建一个Java文件放入到
java代码如下:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Hadoop_hdfs {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
try {
FileSystem fileSystem = FileSystem.get(conf);
fileSystem.mkdirs(new Path("hdfs://localhost:9000/test"));
//这里面是对Hadoop进行具体操作的命令
fileSystem.copyFromLocalFile(new Path("D:/text.txt"),
new Path("/test/text.txt"));
} catch (IOException e) {
e.printStackTrace();
}
}
}
这样用Java简单操作Hadoop的步骤就完成了,增删改查后如果DFS没有显示的话可以右键Refresh一下。

















 2745
2745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}