







创建项目
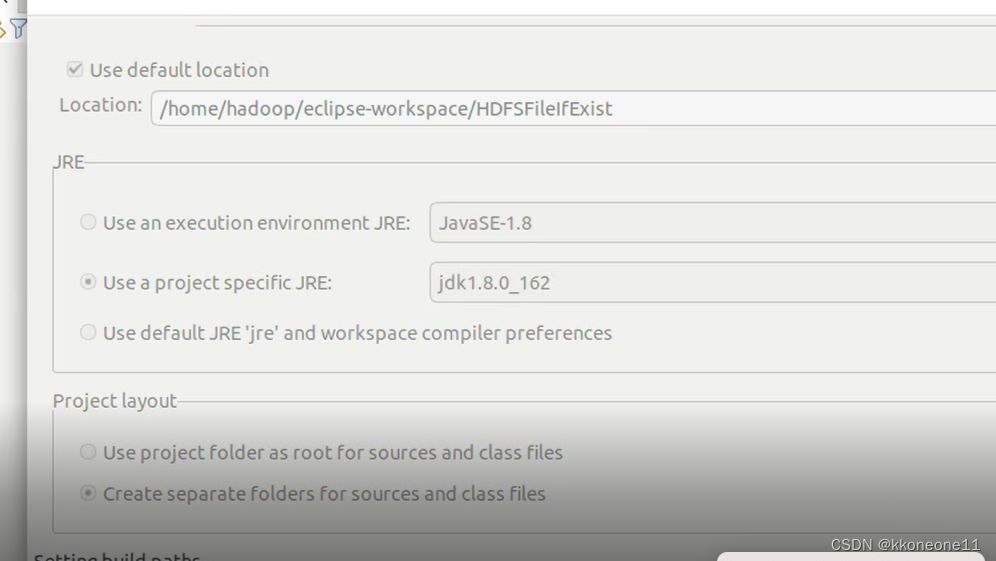
在Eclipse中创建名为HDFSFileIfExist的项目

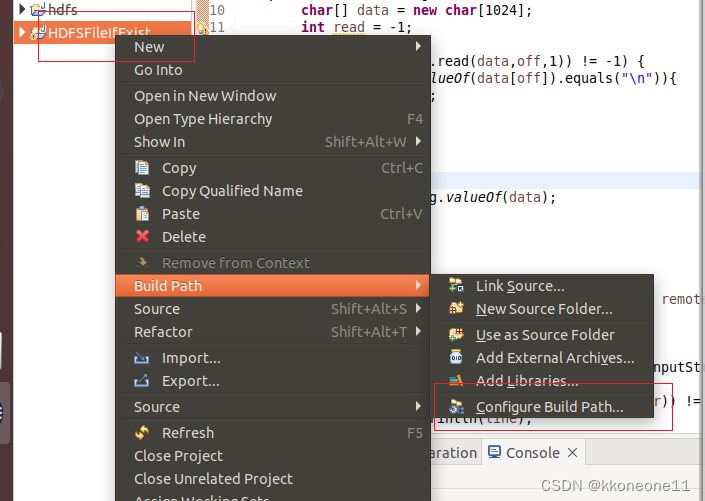
添加JAR包
对着项目右键,增加一个额外的library
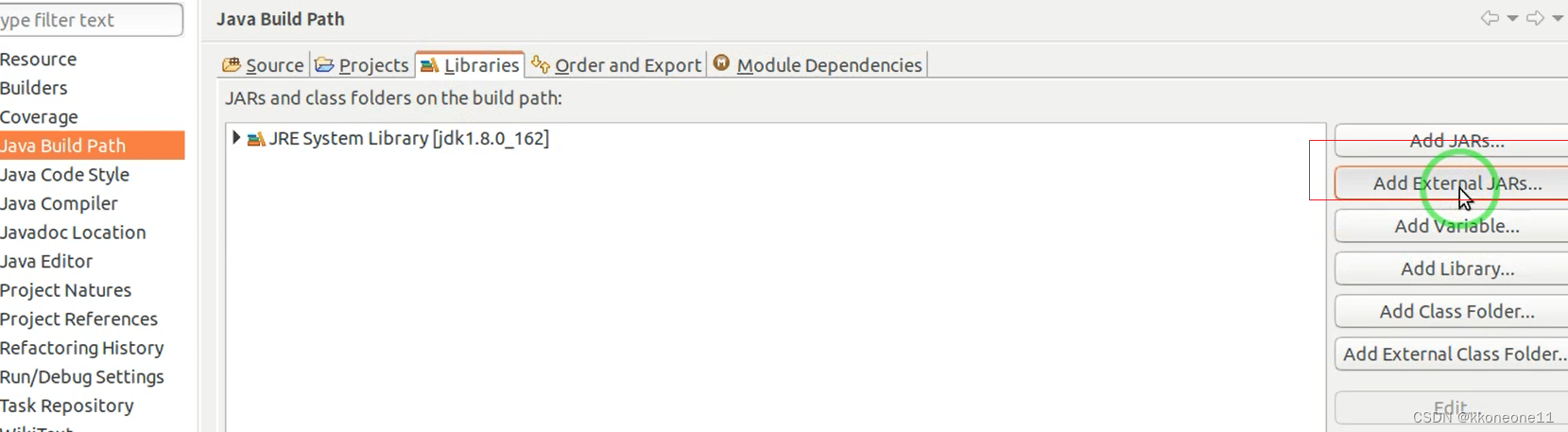
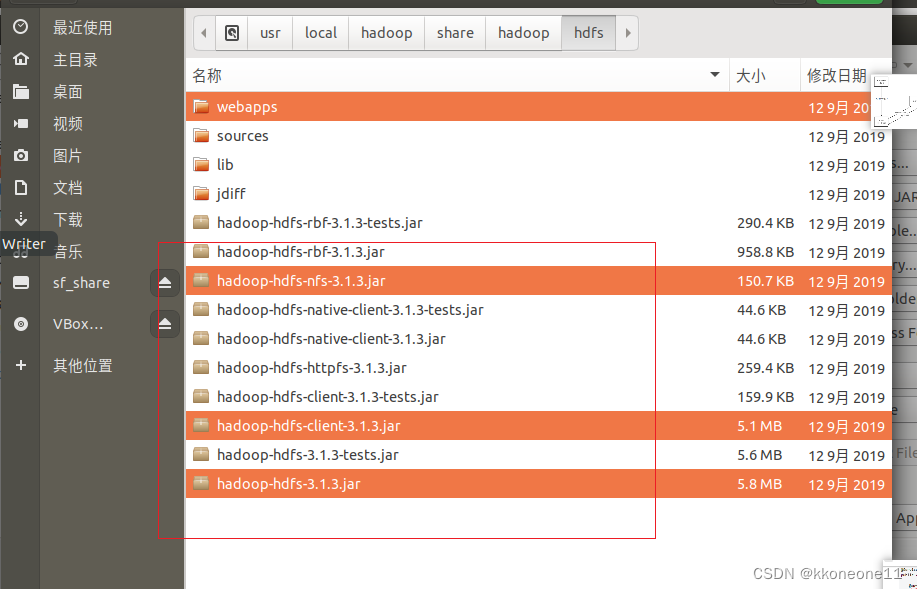
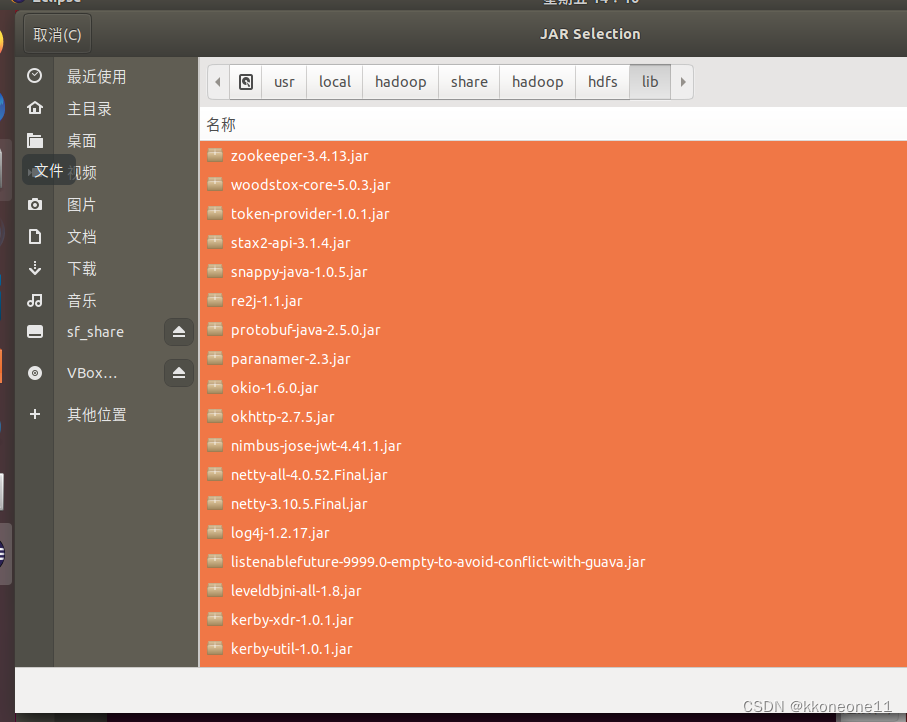
根据以下的图片添加一些jar
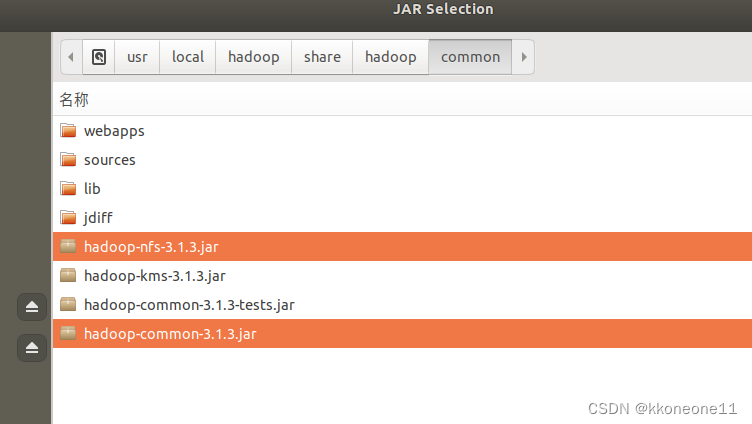
lib下的所有jar文件

操作代码
创建一个类

将HDFS下面那个文件打开,然后复制到类中


上传test到hadoop

运行
HDFSFileIfExist文件
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSFileIfExist {
public static void main(String[] args) {
try {
String fileName = "test.txt";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(fileName))) {
System.out.println("file exist");
}else {
System.out.println("file is not existed");
}
}catch(Exception e) {
e.printStackTrace();
}
}
}

打成jar包
先打开这个
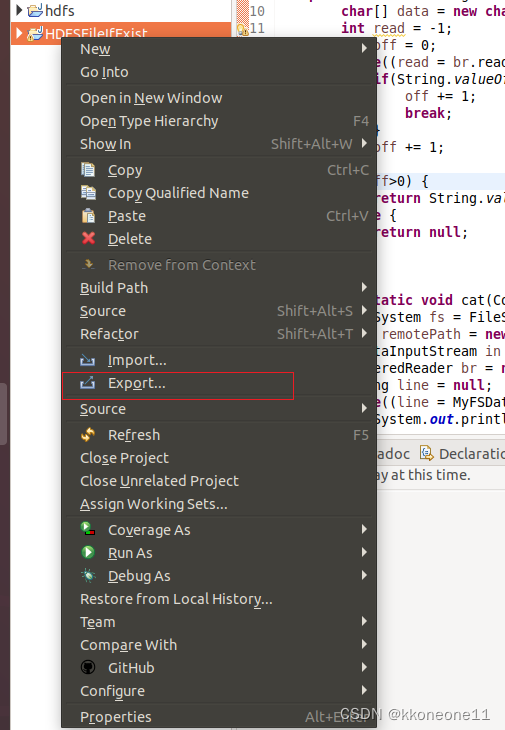
右键项目,出现了之后export即可
直接next
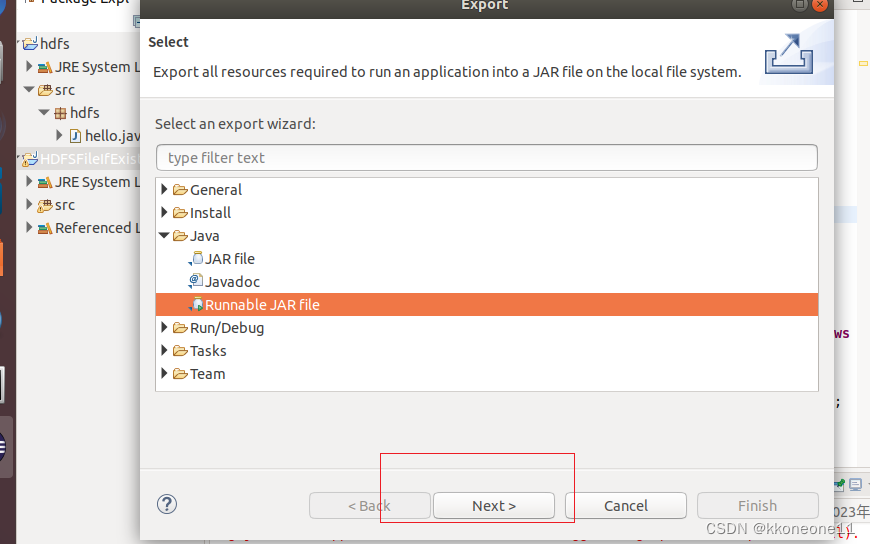
在这个目录下创建一个文件


可以进入到文件看看是否存在
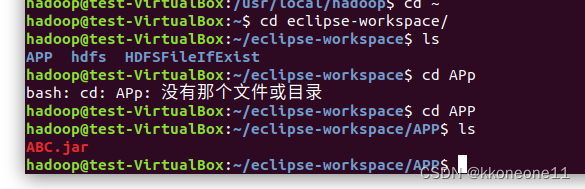
cd然后回到hadoop运行该文件
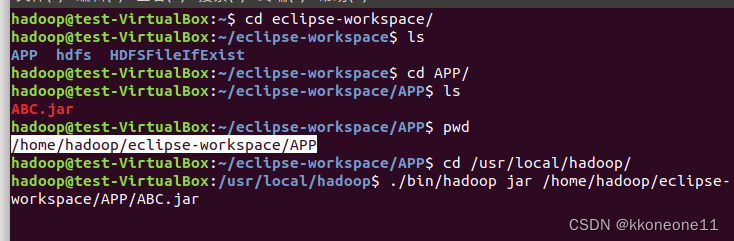
先查看,可以发现是存在

如果不存在,上传后再查看

运行MyFSDataInputStream文件
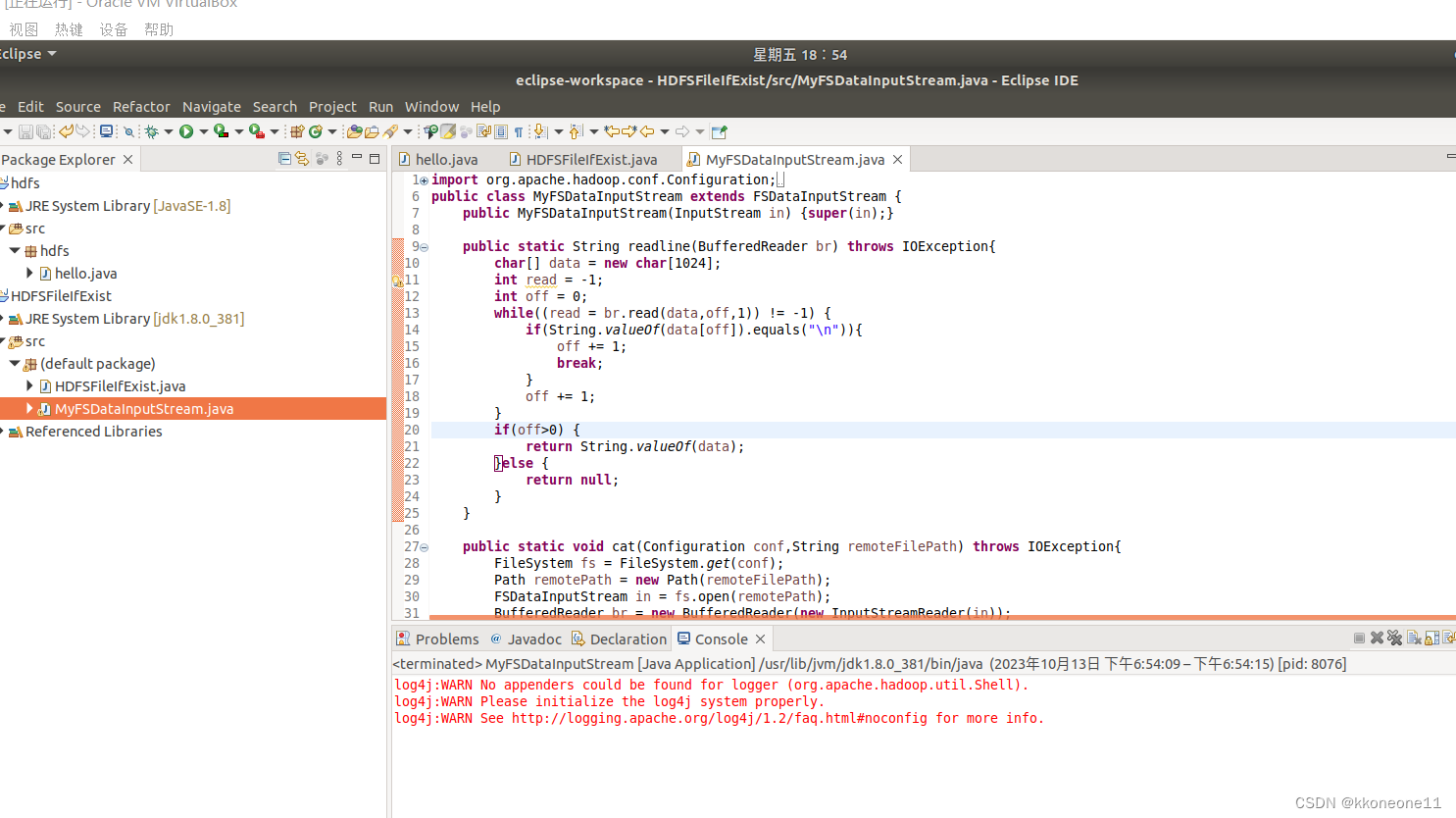
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.*;
public class MyFSDataInputStream extends FSDataInputStream {
public MyFSDataInputStream(InputStream in){
super(in);
}
/**
*实现按行读取
*每次读入-一个字符,遇到"\n"结束, 返回一行内容
*/
public static String readline(BufferedReader br) throws IOException {
char[] data = new char[ 1024];
int read = -1;
int off= 0;
// 循环执行时,br每次会从上- -次读取结束的位置继续读取
//因此该函数里,off 每次都从0开始
while ( (read = br.read(data, off, 1)) != -1 ) {
if (String.valueOf(data[off]).equals("\n")) {
off += 1;
break;
}
off += 1;
}
if (off> 0) {
return String.valueOf(data);
} else {
return null;
}
}
/**
*读取文件内容
*/
public static void cat(Configuration conf, String remoteFilePath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path remotePath = new Path(remoteFilePath);
FSDataInputStream in = fs.open(remotePath);
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String line = null;
while ( (line = MyFSDataInputStream.readline(br)) != null ) {
System.out.println(line);
}
br.close();
in.close();
fs.close();
}
/**
*主函数
*/
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.defaultFS" ,"hdfs://localhost:9000");
String remoteFilePath = "/user/hadoop/test.txt";
try {
MyFSDataInputStream.cat(conf, remoteFilePath);
} catch (Exception e){
e.printStackTrace();
}
}
}
















 2531
2531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











