






使用场景:
当字段类型为字符串(varchar,text等),有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率,此时可以只将字符串的一部分前缀,建立索引,降低索引的体积,提高索引的效率
语法:
indexname:索引名
tablename:表名
column:字段
n:提取字符串的前n个字符来构建索引
create index indexname on tablename(column(n));
使用规则(前缀长度):
根据索引的选择性来决定前缀的长度,选择性是指不重复的索引值和数据表中的总数的比值,索引选择性越高,则查询效率越高。
唯一索引的选择性是1,这是索引的最好选择性,性能也是最好的。
以employee表id_number举例:count(distinct id_number)得出该字段在表中不重复的数,除以总数,得出选择性为0.75

权衡选择性与前缀(或索引的体积),可以考虑使用substring,计算选择性多少合适
select count(DISTINCT substring(id_number,1,10))/ count(*) as 选择性 from employee;
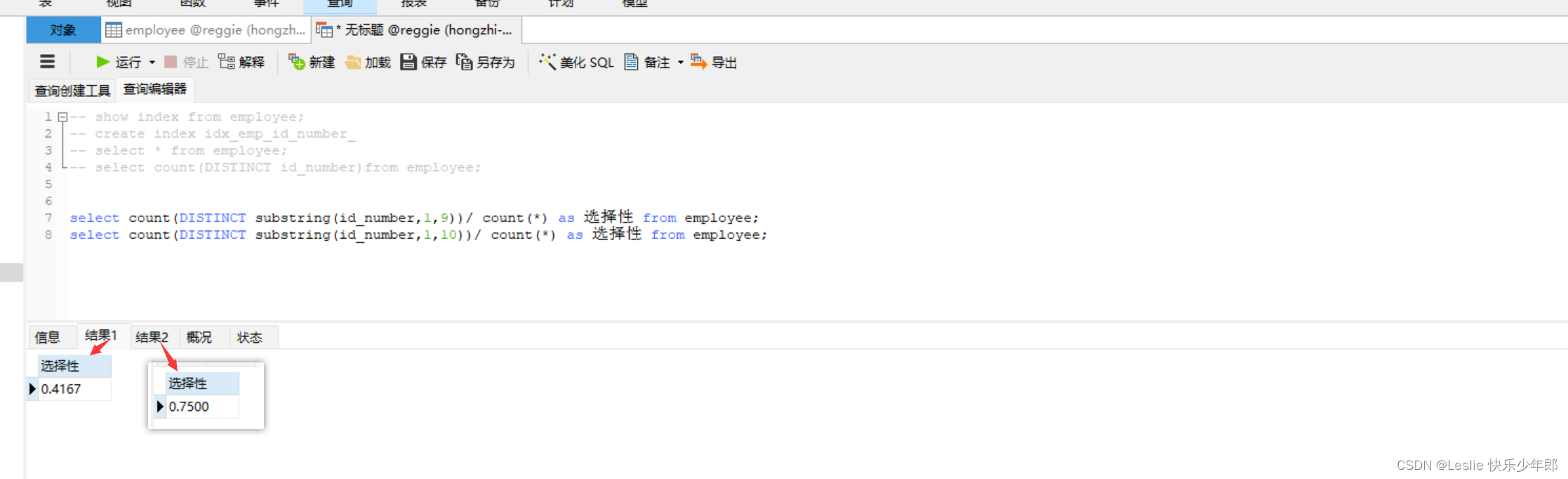
create index idx_emp_id_number_10 on employee(id_number(10));

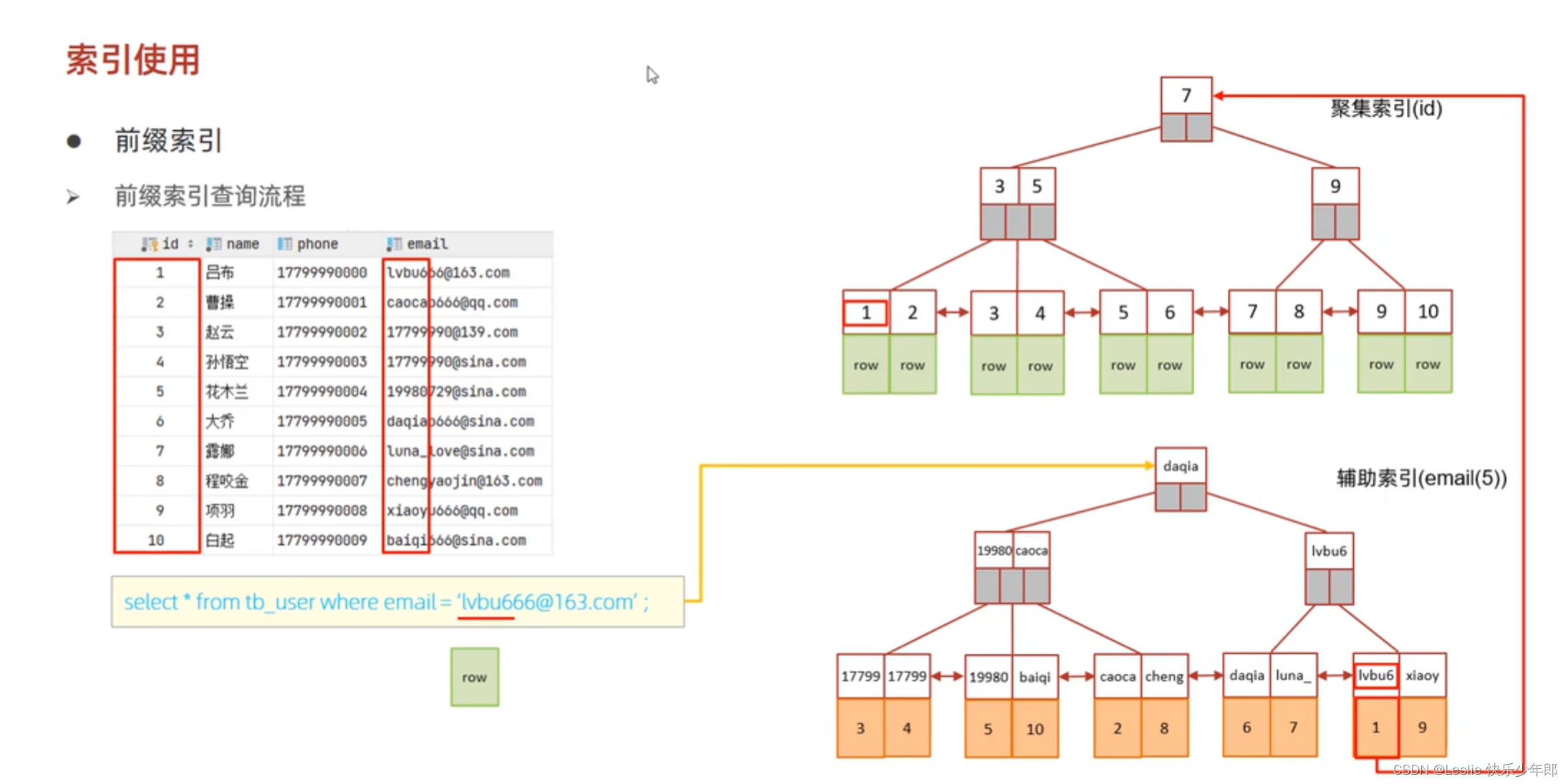
SQL分析:索引结构、查询流程
















 5151
5151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









