







文章目录
- 引言
- 简单
- 力扣:1 两数之和
- 力扣:20 有效的括号
- 力扣:21 合并两个有序链表
- 力扣:22 括号生成
- 力扣:27 移除元素
- 力扣: 35 搜索插入位置
- 力扣:70 [爬楼梯](https://leetcode.cn/problems/climbing-stairs/)
- 力扣:94 二叉树的中序遍历
- 力扣:100 相同的树
- 力扣:102 二叉树的层序遍历
- 力扣:107 二叉树的层序遍历Ⅱ
- 力扣:121 [买卖股票的最佳时机](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/)
- 力扣:144 二叉树的前序遍历
- 力扣:145 二叉树的后序遍历
- 力扣:205 [同构字符串](https://leetcode.cn/problems/isomorphic-strings/)
- 力扣:206 [反转链表](https://leetcode.cn/problems/reverse-linked-list/)
- 力扣:263 丑数
- 力扣:278 [第一个错误的版本](https://leetcode.cn/problems/first-bad-version/)
- 力扣:338 比特位计数
- 力扣:392 [判断子序列](https://leetcode.cn/problems/is-subsequence/)
- 力扣:409 [最长回文串](https://leetcode.cn/problems/longest-palindrome/)
- 力扣:434 字符串中的单词数
- 力扣:441 排列硬币
- 力扣:448 找到所有数组中消失的数字
- 力扣:509 [斐波那契数](https://leetcode.cn/problems/fibonacci-number/)
- 力扣:704 [二分查找](https://leetcode.cn/problems/binary-search/)
- 力扣:724 [寻找数组的中心下标](https://leetcode.cn/problems/find-pivot-index/)
- 力扣:746 [使用最小花费爬楼梯](https://leetcode.cn/problems/min-cost-climbing-stairs/)
- 力扣:876 [链表的中间结点](https://leetcode.cn/problems/middle-of-the-linked-list/)
- 力扣:896 单调数列
- 力扣:905 [按奇偶排序数组](https://leetcode.cn/problems/sort-array-by-parity/)
- 力扣:922 按奇偶排序数组Ⅱ
- 力扣:933 [最近的请求次数](https://leetcode.cn/problems/number-of-recent-calls/)
- 力扣:1317 将整数转换为两个无零整数的和
- 力扣:1437 是否所有1都至少相隔k个元素
- 力扣:1464 数组中两元素的最大乘积
- 力扣:1480 [一维数组的动态和](https://leetcode.cn/problems/running-sum-of-1d-array/)
- 力扣:1518 [换水问题](https://leetcode.cn/problems/water-bottles/)
- 力扣:1556 [千位分隔数](https://leetcode.cn/problems/thousand-separator/)
- 力扣:1736 替换隐藏数字得到的最晚时间
- 力扣:1822 [数组元素积的符号](https://leetcode.cn/problems/sign-of-the-product-of-an-array/)
- 力扣:2335 [装满杯子需要的最短总时长](https://leetcode.cn/problems/minimum-amount-of-time-to-fill-cups/)
- 中等
- 困难
- LCP
- 剑指offer
- 数据库
- 简单
- 力扣:175 [组合两个表](https://leetcode.cn/problems/combine-two-tables/)
- 力扣:182 [查找重复的电子邮箱](https://leetcode.cn/problems/duplicate-emails/)
- 力扣:183 [从不订购的客户](https://leetcode.cn/problems/customers-who-never-order/)
- 力扣:196 [删除重复的电子邮箱](https://leetcode.cn/problems/delete-duplicate-emails/)
- 力扣:197 [上升的温度](https://leetcode.cn/problems/rising-temperature/)
- 力扣:511 [游戏玩法分析 I](https://leetcode.cn/problems/game-play-analysis-i/)
- 力扣:595 [大的国家](https://leetcode.cn/problems/big-countries/)
- 力扣:584 [寻找用户推荐人](https://leetcode.cn/problems/find-customer-referee/)
- 力扣:586 [订单最多的客户](https://leetcode.cn/problems/customer-placing-the-largest-number-of-orders/)
- 力扣:596 [超过5名学生的课](https://leetcode.cn/problems/classes-more-than-5-students/)
- 力扣:607 [销售员](https://leetcode.cn/problems/sales-person/)
- 力扣:627 [变更性别](https://leetcode.cn/problems/swap-salary/)
- 力扣:1050 [合作过至少三次的演员和导演](https://leetcode.cn/problems/actors-and-directors-who-cooperated-at-least-three-times/)
- 力扣:1084 [销售分析III](https://leetcode.cn/problems/sales-analysis-iii/)
- 力扣:1141 [查询近30天活跃用户数](https://leetcode.cn/problems/user-activity-for-the-past-30-days-i/)
- 力扣:1148 [文章浏览 I](https://leetcode.cn/problems/article-views-i/)
- 力扣:1407 [排名靠前的旅行者](https://leetcode.cn/problems/top-travellers/)
- 力扣:1471[查找每个员工花费的总时间](https://leetcode.cn/problems/find-total-time-spent-by-each-employee/)
- 力扣:1484 [按日期分组销售产品](https://leetcode.cn/problems/group-sold-products-by-the-date/)
- 力扣:1527 [患某种疾病的患者](https://leetcode.cn/problems/patients-with-a-condition/)
- 力扣:1581 [进店却未进行过交易的顾客](https://leetcode.cn/problems/customer-who-visited-but-did-not-make-any-transactions/)
- 力扣:1587 [银行账户概要 II](https://leetcode.cn/problems/bank-account-summary-ii/)
- 力扣:1667 [修复表中的名字](https://leetcode.cn/problems/fix-names-in-a-table/)
- 力扣:1693 [每天的领导和合伙人](https://leetcode.cn/problems/daily-leads-and-partners/)
- 力扣:1729 [求关注者的数量](https://leetcode.cn/problems/find-followers-count/)
- 力扣:1757 [可回收且低脂的产品](https://leetcode.cn/problems/recyclable-and-low-fat-products/)
- 力扣:1795 [每个产品在不同商店的价格](https://leetcode.cn/problems/rearrange-products-table/)
- 力扣:1837 [计算特殊奖金](https://leetcode.cn/problems/calculate-special-bonus/)
- 力扣:1890 [2020年最后一次登录](https://leetcode.cn/problems/the-latest-login-in-2020/)
- 力扣:1965 [丢失信息的雇员](https://leetcode.cn/problems/employees-with-missing-information/)
- 中等
- 困难
引言
本篇文章用于记录力扣的学习,持续每日更新
简单
力扣:1 两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
解题方式一:暴力法
class Solution {
public int[] twoSum(int[] nums, int target) {
int flag[] = new int[2];
for(int i = 0;i<nums.length-1;i++){
for(int j = i+1;j<nums.length;j++){
if(nums[i]+nums[j]==target){
flag[0]=i;
flag[1]=j;
return flag;
}
}
}
return null;
}
}
解题方式二:hashmap
class Solution {
public int[] twoSum(int[] nums, int target) {
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
map.put(nums[i],i);//注意这里存入的key是nums[i],值是i
}
for (int i = 0; i < nums.length; i++) {
//得出我们需要在map集合中找到的元素,即目标值和现遍历的数组值的差
int diff=target-nums[i];
//containsKey方法的作用是寻找map内是否存在相同的键
//如果满足存在改键,并且该键的值与本次遍历的数组下标不相等则返回
if(map.containsKey(diff) && map.get(diff)!=i){
//返回新数组
return new int[]{i,map.get(diff)};
}
}
return null;
}
}
力扣:20 有效的括号
题目:
给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
解题方式:使用栈的方式取解决
class Solution {
public boolean isValid(String s) {
if (s.length()==0||s.equals("")){
return true;
}
Stack<Character> stack = new Stack<Character>();//声明栈
char[] chars = s.toCharArray();
for (char c : chars) {//遍历
if(c=='('||c=='{'||c=='['){//如果是符号左边的则入栈
stack.push(c);
}else{//否则进入判断
if (stack.isEmpty()){//如果这个时候栈为空,则返回false
return false;
}else {
if (c==')'){
if(stack.pop()!='('){//栈顶元素出栈,并与之比较,若不是正确的元素,则返回false
return false;
}
}else if (c=='}'){
if(stack.pop()!='{'){
return false;
}
}else if (c==']'){
if(stack.pop()!='['){
return false;
}
}
}
}
}
if (stack.isEmpty()){//如果栈为空则返回true
return true;
}
//如果栈内还有元素则返回false
return false;
}
}
力扣:21 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
解题方式一:迭代法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
ListNode result = new ListNode();
ListNode cur=result;//定义结果链表指针
while (list1!=null&&list2!=null){
if(list1.val<= list2.val){
cur.next=new ListNode(list1.val);
list1=list1.next;
cur=cur.next;
}else{
cur.next=new ListNode(list2.val);
list2=list2.next;
cur=cur.next;
}
}
while (list1!=null){
cur.next=new ListNode(list1.val);
list1=list1.next;
cur=cur.next;
}
while (list2!=null){
cur.next=new ListNode(list2.val);
list2=list2.next;
cur=cur.next;
}
return result.next;
}
}
解题方式二:递归法1
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
if(list1==null&&list2==null){//防止出现两个链表都为空的情况
return list1;
}
ListNode res = new ListNode();
if (list1!=null||list2!=null){//递归条件
if (list1!=null&&list2!=null){
if (list1.val<= list2.val){
res=list1;
list1=list1.next;
}else{
res=list2;
list2=list2.next;
}
}else{
if (list1!=null){
res=list1;
list1=list1.next;
}else if (list2!=null){
res=list2;
list2=list2.next;
}
}
if (list1!=null||list2!=null){//递归条件,去除最后一次递归的结果
res.next=mergeTwoLists(list1,list2);
}
}
return res;
}
}
解题方式三:递归法2
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
if(list1==null||list2==null){
return list1==null ? list2:list1;
}
if (list1.val<= list2.val){
list1.next=mergeTwoLists(list1.next,list2);
return list1;
}else{
list2.next=mergeTwoLists(list1,list2.next);
return list2;
}
}
}
力扣:22 括号生成
数字
n代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
输入:n = 3
输出:["((()))","(()())","(())()","()(())","()()()"]
示例 2:
输入:n = 1
输出:["()"]
解题方式:回溯算法
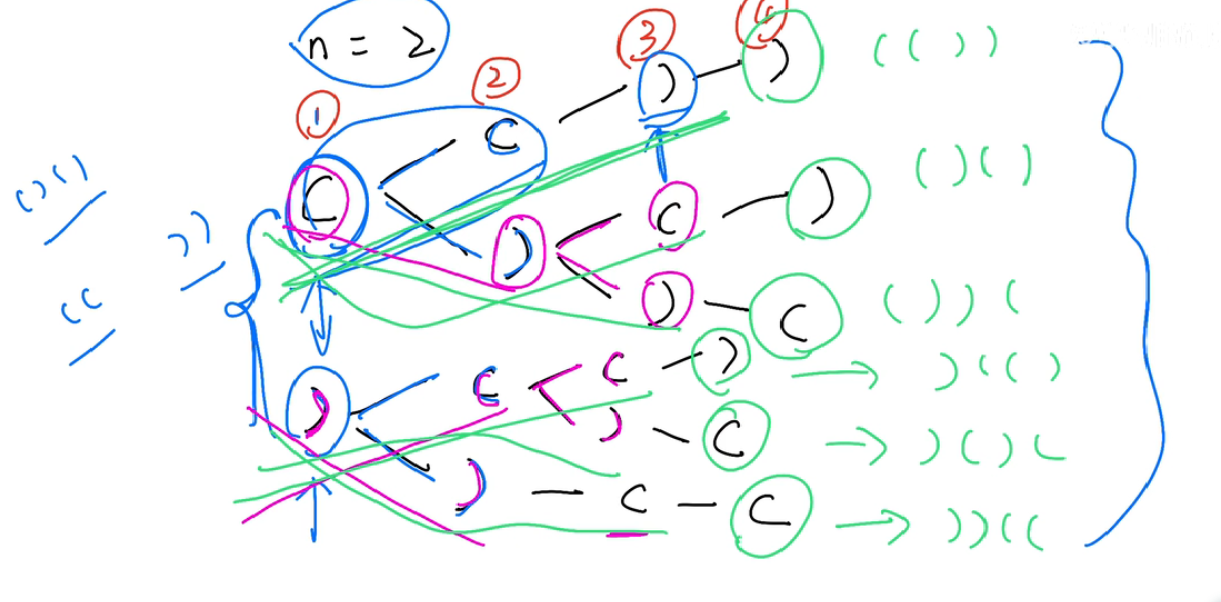
class Solution {
public List<String> generateParenthesis(int n) {
ArrayList<String> result = new ArrayList<>();
backtracking(n,result,0,0,"");
return result;
}
//n为括号对数,result为传入的列表,left为左括号数量,right为右括号数量,str为符合的字符串
public static void backtracking(int n,List<String> result,int left,int right,String str) {
//如果右括号数量大于左括号数量,则直接结束
if (right>left){
return;
}
//如果左括号数量和右括号数量相等,且等于括号对数,则将其添加至result集合中
if (left==right&&left==n){
result.add(str);
return;
}
//如果左括号数量小于总括号对数,则左括号数量+1,再次调用本方法
if (left<n){
backtracking(n,result,left+1,right,str+"(");
}
//如果右括号数量小于左括号数量,则右括号数量+1,再次调用本方法
if (right<left){
backtracking(n,result,left,right+1,str+")");
}
}
}
力扣:27 移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝 int len = removeElement(nums, val); // 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。 for (int i = 0; i < len; i++) { print(nums[i]); }
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
解题方式1:暴力交换法
class Solution {
public int removeElement(int[] nums, int val) {
int count = 0; //val出现的次数
int temp = 0; //交换变量
for (int i = 0; i < nums.length - count; i++) {
if (nums[i]==val){//如果值相等则与数组倒序的数进行交换
temp = nums[i];
nums[i] = nums[nums.length-1-count];
nums[nums.length-1-count] = temp;
count++;
i--;//检查交换过来的这个数是否不为val
}
}
return nums.length-count;
}
}
解题方式2:双指针法1
class Solution {
public int removeElement(int[] nums, int val) {
int left = 0; //左指针位置
int right = nums.length-1; //右指针位置
int temp = 0; //交换变量
while (left<=right){
if (nums[left]==val){
while (nums[right]==val){//判断指针指向值是否为val
right--;
if (right<left){
return left;
}
}
//交换
temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
right--;
}
left++;
}
return left;
}
}
解题方式3:双指针法3
class Solution {
public int removeElement(int[] nums, int val) {
//双指针法2
if (nums==null || nums.length==0){
return 0;
}
int l = 0;
int r = nums.length-1;
while (l<r){
while (l<r && nums[l] != val){
l++;
}
while (l<r && nums[r] == val){
r--;
}
int temp = nums[l];
nums[l] = nums[r];
nums[r] = temp;
}
return nums[l] ==val ? l : l+1;
}
}
力扣: 35 搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5
输出: 2
示例 2:
输入: nums = [1,3,5,6], target = 2
输出: 1
示例 3:
输入: nums = [1,3,5,6], target = 7
输出: 4
解题方式1:常规法
class Solution {
public int searchInsert(int[] nums, int target) {
if(nums == null || nums.length == 0){
return 0;
}
for (int i = 0; i < nums.length; i++) {
if (nums[i] >= target){
return i;
}
}
return nums.length;
}
}
解题方式2:二分法
class Solution {
public int searchInsert(int[] nums, int target) {
int l = 0;
int r = nums.length-1;
while (l<r){
int m = l+(r-l)/2;
if (target<nums[m]){
r=m;
}else if (target>nums[m]){
l=m+1;
}else{
return m;
}
}
return nums[l] >= target ? l : l+1 ;
}
}
力扣:70 爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
示例 1:
输入:n = 2
输出:2
解释:有两种方法可以爬到楼顶。
1. 1 阶 + 1 阶
2. 2 阶
示例 2:
输入:n = 3
输出:3
解释:有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶
解题方式:动态规划
class Solution {
public int climbStairs(int n) {
/*
标签:动态规划
本问题其实常规解法可以分成多个子问题,爬第n阶楼梯的方法数量,等于 2 部分之和
爬上 n-1n−1 阶楼梯的方法数量。因为再爬1阶就能到第n阶
爬上 n-2n−2 阶楼梯的方法数量,因为再爬2阶就能到第n阶
所以我们得到公式 dp[n] = dp[n-1] + dp[n-2]dp[n]=dp[n−1]+dp[n−2]
同时需要初始化 dp[0]=1dp[0]=1 和 dp[1]=1dp[1]=1
时间复杂度:O(n)O(n)
*/
if (n<=2){
return n;
}
int[] dp = new int[n];
dp[0] = 1;
dp[1] = 2;
for (int i = 2; i < dp.length; i++) {
dp[i] = dp[i-1]+dp[i-2];
}
return dp[n-1];
}
}
力扣:94 二叉树的中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:
输入:root = [1,null,2,3]
输出:[1,3,2]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
解题方式1:递归法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//递归解决
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
ArrayList<Integer> list = new ArrayList<>();
helper(root,list);
return list;
}
//ldr中序遍历,递归的方式
public void helper(TreeNode node,List<Integer> list){
if (node == null){
return;
}
helper(node.left,list);
list.add(node.val);
helper(node.right,list);
}
}
解题方式2:迭代法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//迭代解决
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
ArrayList<Integer> list = new ArrayList<>();
helper2(root,list);
return list;
}
//迭代法
public void helper2(TreeNode node,List<Integer> list){
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = node;
while (cur != null || stack.size() > 0) {
if(cur !=null){
stack.push(cur);
cur = cur.left;
}
else{
cur = stack.pop();
list.add(cur.val);
cur = cur.right;
}
}
}
}
力扣:100 相同的树
给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
示例 1:
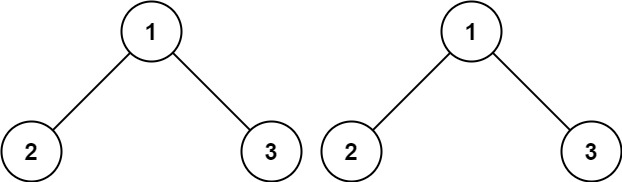
输入:p = [1,2,3], q = [1,2,3]
输出:true
示例 2:
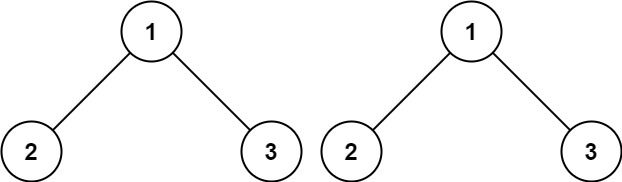
输入:p = [1,2], q = [1,null,2]
输出:false
示例 3:
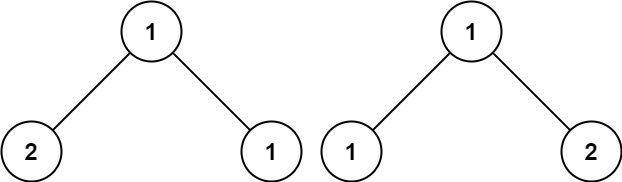
输入:p = [1,2,1], q = [1,1,2]
输出:false
解题方式1:递归法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
if (p == null && q == null){//终止条件
return true;
}
if (p == null || q == null){//终止条件
return false;
}
if (p.val == q.val){//如果两个值相等,则进行递归操作
return isSameTree(p.left,q.left) && isSameTree(p.right,q.right);
}
return false;
}
}
力扣:102 二叉树的层序遍历
给你二叉树的根节点
root,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:
输入:root = [3,9,20,null,null,15,7]
输出:[[3],[9,20],[15,7]]
示例 2:
输入:root = [1]
输出:[[1]]
示例 3:
输入:root = []
输出:[]
解题方式1:BFS
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
if(root == null)
return new ArrayList<>();
List<List<Integer>> res = new ArrayList<>();
//使用队列
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while(!queue.isEmpty()){
int count = queue.size();
List<Integer> list = new ArrayList<>();
while(count > 0){
//出队列
TreeNode node = queue.poll();
list.add(node.val);
if(node.left != null)
queue.add(node.left);
if(node.right != null)
queue.add(node.right);
count--;
}
//一排一排的加入
res.add(list);
}
return res;
}
}
解题方式2:DFS
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
List<List<Integer>> result = new ArrayList<>();
//dfs法
public List<List<Integer>> levelOrder(TreeNode root) {
dfs(0,root);
return result;
}
public void dfs(int n,TreeNode node){
if (node == null){
return;
}
if (result.size()<n+1){
result.add(new ArrayList<>());
}
result.get(n).add(node.val);
dfs(n+1,node.left);
dfs(n+1,node.right);
}
}
力扣:107 二叉树的层序遍历Ⅱ
给你二叉树的根节点 root ,返回其节点值 自底向上的层序遍历 。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
示例 1:
输入:root = [3,9,20,null,null,15,7]
输出:[[15,7],[9,20],[3]]
示例 2:
输入:root = [1]
输出:[[1]]
示例 3:
输入:root = []
输出:[]
解题方式1:DFS
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
List<List<Integer>> result = new ArrayList<>();
public List<List<Integer>> levelOrderBottom(TreeNode root) {
dfs(0,root);
Collections.reverse(result);
return result;
}
public void dfs(int n,TreeNode node){
if (node == null){
return;
}
if (result.size()<n+1){
result.add(new ArrayList<>());
}
result.get(n).add(node.val);
dfs(n+1,node.left);
dfs(n+1,node.right);
}
}
力扣:121 买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
解题方式:迭代法
class Solution {
public int maxProfit(int[] prices) {
int max = 0;
int min = prices[0];
for (int i = 0; i < prices.length; i++) {
min = Math.min(min,prices[i]);
max = Math.max(max,prices[i]-min);
}
return max;
}
}
力扣:144 二叉树的前序遍历
给你二叉树的根节点
root,返回它节点值的 前序 遍历。
示例 1:
输入:root = [1,null,2,3]
输出:[1,2,3]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
示例 4:
输入:root = [1,2]
输出:[1,2]
示例 5:
输入:root = [1,null,2]
输出:[1,2]
解题方式1:递归法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
ArrayList<Integer> list = new ArrayList<>();
back(root,list);
return list;
}
public void back(TreeNode node,List<Integer> list){
if (node == null){
return;
}
list.add(node.val);
back(node.left,list);
back(node.right,list);
}
}
力扣:145 二叉树的后序遍历
给你一棵二叉树的根节点
root,返回其节点值的 后序遍历 。
示例 1:
输入:root = [1,null,2,3]
输出:[3,2,1]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
解题方式1:递归法
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
ArrayList<Integer> list = new ArrayList<>();
back(root,list);
return list;
}
public void back(TreeNode node,List<Integer> list){
if (node == null){
return;
}
back(node.left,list);
back(node.right,list);
list.add(node.val);
}
}
力扣:205 同构字符串
给定两个字符串 s 和 t ,判断它们是否是同构的。
如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。
每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。
示例 1:
输入:s = "egg", t = "add"
输出:true
示例 2:
输入:s = "foo", t = "bar"
输出:false
示例 3:
输入:s = "paper", t = "title"
输出:true
解题方式:迭代法
class Solution {
public boolean isIsomorphic(String s, String t) {
char[] chars1 = s.toCharArray();
char[] chars2 = t.toCharArray();
HashMap<Character, Character> map1 = new HashMap<>();//chars1配对chars2
HashMap<Character, Character> map2 = new HashMap<>();//chars2配对chars1
for (int i = 0; i < chars1.length; i++) {
if (!map1.containsKey(chars1[i]) && !map2.containsKey(chars2[i])){//如果两个数据中没有出现配对过的情况,则将他们进行配对
map1.put(chars1[i],chars2[i]);
map2.put(chars2[i],chars1[i]);
}else{
if (map1.containsKey(chars1[i])){//如果map1中存在
if (chars2[i]!= map1.get(chars1[i])){//判断map1中的值和chars2中的值
return false;
}
}
if (map2.containsKey(chars2[i])){//如果map2中存在
if (chars1[i] != map2.get(chars2[i])){//判断map2中的值和chars1中的值
return false;
}
}
}
}
return true;
}
}
力扣:206 反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:
输入:head = [1,2]
输出:[2,1]
示例 3:
输入:head = []
输出:[]
解题方式:迭代法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
/*
* 1 -> 2 -> 3 -> 4 -> null
* null <- 1 <- 2 <- 3 <- 4
*/
ListNode prev = null; //前指针节点
ListNode curr = head; //当前指针节点
//每次循环,都将当前节点指向它前面的节点,然后当前节点和前节点后移
while (curr != null){
ListNode next = curr.next;//临时节点,暂存当前节点的下一节点,用于后移
curr.next = prev;//将当前节点指向它前面的节点
prev = curr;//前指针后移
curr = next;//当前指针后移
}
return prev;
}
}
解题方式2:递归法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
return reverse(null,head);
}
private static ListNode reverse(ListNode pre,ListNode cur){
if(cur==null) return pre;
ListNode next = cur.next;
cur.next = pre;
return reverse(cur,next);
}
}
力扣:263 丑数
丑数 就是只包含质因数 2、3 和 5 的正整数。
给你一个整数 n ,请你判断 n 是否为 丑数 。如果是,返回 true ;否则,返回 false 。
示例 1:
输入:n = 6
输出:true
解释:6 = 2 × 3
示例 2:
输入:n = 1
输出:true
解释:1 没有质因数,因此它的全部质因数是 {2, 3, 5} 的空集。习惯上将其视作第一个丑数。
示例 3:
输入:n = 14
输出:false
解释:14 不是丑数,因为它包含了另外一个质因数 7 。
解题方式1:因素分解法
//因素分解法
class Solution {
//只要将n一直分解2,3,5,如果最后不得1,那么该数就不为丑数
public boolean isUgly(int n) {
if (n <= 0){
return false;
}
while (n%2 == 0){
n = n>>1;
}
while (n % 3 == 0){
n = n/3;
}
while (n % 5 == 0){
n = n/5;
}
return n == 1;
}
}
力扣:278 第一个错误的版本
你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。
假设你有 n 个版本 [1, 2, …, n],你想找出导致之后所有版本出错的第一个错误的版本。
你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
示例 1:
输入:n = 5, bad = 4
输出:4
解释:
调用 isBadVersion(3) -> false
调用 isBadVersion(5) -> true
调用 isBadVersion(4) -> true
所以,4 是第一个错误的版本。
示例 2:
输入:n = 1, bad = 1
输出:1
解题方式:
/* The isBadVersion API is defined in the parent class VersionControl.
boolean isBadVersion(int version); */
public class Solution extends VersionControl {
public int firstBadVersion(int n) {
int left =1,right=n;
while (left<right){
int mid = left+(right-left)/2;
if (isBadVersion(mid)){
right = mid;
}else{
left = mid+1;
}
}
return left;
}
}
力扣:338 比特位计数
给你一个整数 n ,对于 0 <= i <= n 中的每个 i ,计算其二进制表示中 1 的个数 ,返回一个长度为 n + 1 的数组 ans 作为答案。
示例 1:
输入:n = 2
输出:[0,1,1]
解释:
0 --> 0
1 --> 1
2 --> 10
示例 2:
输入:n = 5
输出:[0,1,1,2,1,2]
解释:
0 --> 0
1 --> 1
2 --> 10
3 --> 11
4 --> 100
5 --> 101
解题方式1:调api
class Solution {
public int[] countBits(int n) {
int[] ans = new int[n+1];
for(int i = 0 ; i <= n ; i++){
ans[i] = Integer.bitCount(i);
}
return ans;
}
}
力扣:392 判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
进阶:
如果有大量输入的 S,称作 S1, S2, … , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
致谢:
特别感谢 @pbrother 添加此问题并且创建所有测试用例。
示例 1:
输入:s = "abc", t = "ahbgdc"
输出:true
示例 2:
输入:s = "axc", t = "ahbgdc"
输出:false
解题方式:迭代法
class Solution {
public boolean isSubsequence(String s, String t) {
if (s.equals("")){
return true;
}
char[] chars1 = s.toCharArray();
char[] chars2 = t.toCharArray();
int left = 0;//chars1的指针
int right = 0;//chars2的指针
while (right < chars2.length){//如果chars2的指针不溢出
if (chars1[left] == chars2[right]){//判断值
left++;
right++;
}else {
right++;
}
if (left == chars1.length){//判断是否是子序列
return true;
}
}
return false;
}
}
力扣:409 最长回文串
给定一个包含大写字母和小写字母的字符串 s ,返回 通过这些字母构造成的 最长的回文串 。
在构造过程中,请注意 区分大小写 。比如 “Aa” 不能当做一个回文字符串。
示例 1:
输入:s = "abccccdd"
输出:7
解释:
我们可以构造的最长的回文串是"dccaccd", 它的长度是 7。
示例 2:
输入:s = "a"
输入:1
解题方式:哈希法
class Solution {
public int longestPalindrome(String s) {
/*
怎么样才能构成回文数呢,回文数中都是成对的,或者中间有一个落单的数,我们根据这个来判断即可
*/
int max = 0;//统计最大长度
HashMap<Character, Integer> map = new HashMap<>();
char[] chars = s.toCharArray();
for (int i = 0; i < chars.length; i++) {
if (!map.containsKey(chars[i])){
map.put(chars[i],1);
}else{
map.put(chars[i],map.get(chars[i])+1);
}
}
boolean flag = false;//判断是否有落单的数
Set<Map.Entry<Character, Integer>> entries = map.entrySet();
for (Map.Entry<Character, Integer> entry : entries) {
if (entry.getValue()%2!=0){
flag = true;
}
max +=(entry.getValue() / 2) * 2;//成对的数
}
return flag?max+1 : max;
}
}
力扣:434 字符串中的单词数
统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。
请注意,你可以假定字符串里不包括任何不可打印的字符。
示例:
输入: "Hello, my name is John"
输出: 5
解释: 这里的单词是指连续的不是空格的字符,所以 "Hello," 算作 1 个单词。
解题方式1:使用java分割api
class Solution {
public int countSegments(String s) {
if (s.equals("")){//如果字符串为""则直接返回0
return 0;
}
String[] s1 = s.trim().split(" ");//去除前后空格后在进行分隔操作
int count = 0;//单词数量
for (int i = 0; i < s1.length; i++) {
if (!s1[i].equals("")){//如果字符串不是“”则为单词
// System.out.println(s1[i]);
count++;
}
}
return count;
}
}
力扣:441 排列硬币
你总共有 n 枚硬币,并计划将它们按阶梯状排列。对于一个由 k 行组成的阶梯,其第 i 行必须正好有 i 枚硬币。阶梯的最后一行 可能 是不完整的。
给你一个数字 n ,计算并返回可形成 完整阶梯行 的总行数。
示例 1:
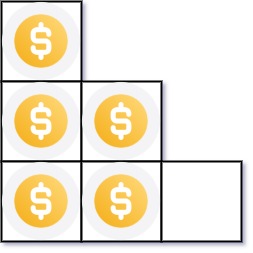
输入:n = 5
输出:2
解释:因为第三行不完整,所以返回 2 。
示例 2:
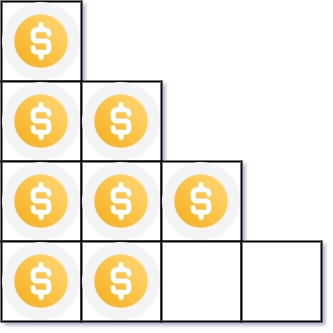
输入:n = 8
输出:3
解释:因为第四行不完整,所以返回 3 。
解题方式1:迭代法
class Solution {
public int arrangeCoins(int n) {
if ( n== 0){
return 0;
}
int i = 1 ;
while (n>=i){
n-=i;
i++;
}
return i - 1;
}
}
力扣:448 找到所有数组中消失的数字
给你一个含 n 个整数的数组 nums ,其中 nums[i] 在区间 [1, n] 内。请你找出所有在 [1, n] 范围内但没有出现在 nums 中的数字,并以数组的形式返回结果。
示例 1:
输入:nums = [4,3,2,7,8,2,3,1]
输出:[5,6]
示例 2:
输入:nums = [1,1]
输出:[2]
解题方式1:哈希法
class Solution {
public List<Integer> findDisappearedNumbers(int[] nums) {
ArrayList<Integer> list = new ArrayList<>();
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 1; i <= nums.length; i++) {
map.put(i,0);
}
for (int i = 0; i < nums.length; i++) {
if (map.containsKey(nums[i])){
map.put(nums[i],map.get(nums[i])+1);
}
}
Set<Integer> keySet = map.keySet();
Iterator<Integer> iterator = keySet.iterator();
while (iterator.hasNext()){
Integer next = iterator.next();
if (map.get(next) == 0){
list.add(next);
}
}
return list;
}
}
力扣:509 斐波那契数
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0,F(1) = 1
F(n) = F(n - 1) + F(n - 2),其中 n > 1
给定 n ,请计算 F(n) 。
示例 1:
输入:n = 2
输出:1
解释:F(2) = F(1) + F(0) = 1 + 0 = 1
示例 2:
输入:n = 3
输出:2
解释:F(3) = F(2) + F(1) = 1 + 1 = 2
示例 3:
输入:n = 4
输出:3
解释:F(4) = F(3) + F(2) = 2 + 1 = 3
解题方式:动态规划法
class Solution {
public int fib(int n) {
if (n<=0){
return 0;
}
if (n==1){
return 1;
}
return fib(n-1)+fib(n-2);
}
}
力扣:704 二分查找
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1
解题方式:
class Solution {
public int search(int[] nums, int target) {
int left = 0;
int right = nums.length-1;
while (left<=right){
int mid = left+(right-left)/2;
if (nums[mid]<target){
left = mid+1;
}else if (nums[mid]>target){
right = mid-1;
}else{
return mid;
}
}
return -1;
}
}
力扣:724 寻找数组的中心下标
给你一个整数数组 nums ,请计算数组的 中心下标 。
数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。
如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回 -1 。
示例 1:
输入:nums = [1, 7, 3, 6, 5, 6]
输出:3
解释:
中心下标是 3 。
左侧数之和 sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11 ,
右侧数之和 sum = nums[4] + nums[5] = 5 + 6 = 11 ,二者相等。
示例 2:
输入:nums = [1, 2, 3]
输出:-1
解释:
数组中不存在满足此条件的中心下标。
示例 3:
输入:nums = [2, 1, -1]
输出:0
解释:
中心下标是 0 。
左侧数之和 sum = 0 ,(下标 0 左侧不存在元素),
右侧数之和 sum = nums[1] + nums[2] = 1 + -1 = 0 。
解题方式1:
class Solution {
public int pivotIndex(int[] nums) {
for (int i = 0; i < nums.length; i++) {
int leftSum = 0;
int rightSum = 0;
for (int j = 0; j < i; j++) {
leftSum+=nums[j];
}
for (int j = i+1; j < nums.length; j++) {
rightSum+=nums[j];
}
if (leftSum == rightSum){
return i;
}
}
return -1;
}
}
力扣:746 使用最小花费爬楼梯
给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。
你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。
请你计算并返回达到楼梯顶部的最低花费。
示例 1:
输入:cost = [10,15,20]
输出:15
解释:你将从下标为 1 的台阶开始。
- 支付 15 ,向上爬两个台阶,到达楼梯顶部。
总花费为 15 。
示例 2:
输入:cost = [1,100,1,1,1,100,1,1,100,1]
输出:6
解释:你将从下标为 0 的台阶开始。
- 支付 1 ,向上爬两个台阶,到达下标为 2 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 4 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 6 的台阶。
- 支付 1 ,向上爬一个台阶,到达下标为 7 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 9 的台阶。
- 支付 1 ,向上爬一个台阶,到达楼梯顶部。
总花费为 6 。
解题方式1:
class Solution {
public int minCostClimbingStairs(int[] cost) {
int[] dp = new int[cost.length];
dp[0] = cost[0];
dp[1] = cost[1];
for (int i = 2; i < cost.length; i++) {
dp[i] = Math.min(dp[i - 1], dp[i - 2]) + cost[i];
}
return Math.min(dp[cost.length - 1], dp[cost.length - 2]);
}
}
力扣:876 链表的中间结点
给定一个头结点为 head 的非空单链表,返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
示例 1:
输入:[1,2,3,4,5]
输出:此列表中的结点 3 (序列化形式:[3,4,5])
返回的结点值为 3 。 (测评系统对该结点序列化表述是 [3,4,5])。
注意,我们返回了一个 ListNode 类型的对象 ans,这样:
ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, 以及 ans.next.next.next = NULL.
示例 2:
输入:[1,2,3,4,5,6]
输出:此列表中的结点 4 (序列化形式:[4,5,6])
由于该列表有两个中间结点,值分别为 3 和 4,我们返回第二个结点。
解题方式1:迭代法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode middleNode(ListNode head) {
ListNode temp = head;
int count =1;
while (temp.next!=null){
count++;
temp = temp.next;
}
int end = 0;
int start = 1;
if (count%2==0){
end=count/2+1;
}else{
end=count/2+1;
}
while (true){
if (start==end){
return head;
}
start++;
head=head.next;
}
}
}
力扣:896 单调数列
如果数组是单调递增或单调递减的,那么它是 单调 的。
如果对于所有 i <= j,nums[i] <= nums[j],那么数组 nums 是单调递增的。 如果对于所有 i <= j,nums[i]> = nums[j],那么数组 nums 是单调递减的。
当给定的数组 nums 是单调数组时返回 true,否则返回 false。
示例 1:
输入:nums = [1,2,2,3]
输出:true
示例 2:
输入:nums = [6,5,4,4]
输出:true
示例 3:
输入:nums = [1,3,2]
输出:false
解题方式1:迭代法
class Solution {
public boolean isMonotonic(int[] nums) {
if (nums.length == 1){
return true;
}
if (nums.length == 0){
return false;
}
boolean flag = true;//true为升序,false为降序
if (nums[0] <= nums[nums.length-1]){
flag = true;
}else {
flag = false;
}
if (flag){//升序
for (int i = 1; i < nums.length; i++) {
if (nums[i] - nums[i-1] < 0){
return false;
}
}
}else{//逆序
for (int i = 1; i < nums.length; i++) {
if (nums[i] - nums[i-1] > 0){
return false;
}
}
}
return true;
}
}
力扣:905 按奇偶排序数组
给你一个整数数组 nums,将 nums 中的的所有偶数元素移动到数组的前面,后跟所有奇数元素。
返回满足此条件的 任一数组 作为答案。
示例 1:
输入:nums = [3,1,2,4]
输出:[2,4,3,1]
解释:[4,2,3,1]、[2,4,1,3] 和 [4,2,1,3] 也会被视作正确答案。
示例 2:
输入:nums = [0]
输出:[0]
解题方式1:迭代法
class Solution {
public int[] sortArrayByParity(int[] nums) {
int index = 0;//当前下标
int count = 0;//奇数个数
while (index< nums.length-count){//遍历未知的数
if (nums[index]%2 == 1){//如果当前下标指向的值是奇数,则交换,
int temp = nums[index];
nums[index] = nums[nums.length-1-count];
nums[nums.length-1-count] = temp;
count++;//奇数数量+1
continue;//检查交换过来的值,是奇数还是偶数
}
//如果当前下标指向是偶数,则下标+1
index++;
}
return nums;
}
}
力扣:922 按奇偶排序数组Ⅱ
给定一个非负整数数组 nums, nums 中一半整数是 奇数 ,一半整数是 偶数 。
对数组进行排序,以便当 nums[i] 为奇数时,i 也是 奇数 ;当 nums[i] 为偶数时, i 也是 偶数 。
你可以返回 任何满足上述条件的数组作为答案 。
示例 1:
输入:nums = [4,2,5,7]
输出:[4,5,2,7]
解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。
示例 2:
输入:nums = [2,3]
输出:[2,3]
解题方式1:迭代法
class Solution {
public int[] sortArrayByParityII(int[] nums) {
if (nums.length == 0){
return nums;
}
int[] nums2 = new int[nums.length];
int temp1 = 0;//偶数
int temp2 = 1;//奇数
for (int i = 0; i < nums.length; i++) {
if (nums[i]%2==0){
nums2[temp1] = nums[i];
temp1+=2;
}else{
nums2[temp2] = nums[i];
temp2+=2;
}
}
return nums2;
}
}
力扣:933 最近的请求次数
写一个 RecentCounter 类来计算特定时间范围内最近的请求。
请你实现 RecentCounter 类:
RecentCounter() 初始化计数器,请求数为 0 。
int ping(int t) 在时间 t 添加一个新请求,其中 t 表示以毫秒为单位的某个时间,并返回过去 3000 毫秒内发生的所有请求数(包括新请求)。确切地说,返回在 [t-3000, t] 内发生的请求数。
保证 每次对 ping 的调用都使用比之前更大的 t 值。
示例 1:
输入:
["RecentCounter", "ping", "ping", "ping", "ping"]
[[], [1], [100], [3001], [3002]]
输出:
[null, 1, 2, 3, 3]
解释:
RecentCounter recentCounter = new RecentCounter();
recentCounter.ping(1); // requests = [1],范围是 [-2999,1],返回 1
recentCounter.ping(100); // requests = [1, 100],范围是 [-2900,100],返回 2
recentCounter.ping(3001); // requests = [1, 100, 3001],范围是 [1,3001],返回 3
recentCounter.ping(3002); // requests = [1, 100, 3001, 3002],范围是 [2,3002],返回 3
解题方式1:
class RecentCounter {
public List<Integer> table = new ArrayList<>();
public RecentCounter() {
table.clear();
}
public int ping(int t) {
table.add(t);
while(table.get(0)+3000 <t){
table.remove(0);
}
return table.size();
}
}
/**
* Your RecentCounter object will be instantiated and called as such:
* RecentCounter obj = new RecentCounter();
* int param_1 = obj.ping(t);
*/
力扣:1317 将整数转换为两个无零整数的和
无零整数」是十进制表示中 不含任何 0 的正整数。
给你一个整数 n,请你返回一个 由两个整数组成的列表 [A, B],满足:
A 和 B 都是无零整数
A + B = n
题目数据保证至少有一个有效的解决方案。如果存在多个有效解决方案,你可以返回其中任意一个。
示例 1:
输入:n = 2
输出:[1,1]
解释:A = 1, B = 1. A + B = n 并且 A 和 B 的十进制表示形式都不包含任何 0 。
示例 2:
输入:n = 11
输出:[2,9]
示例 3:
输入:n = 10000
输出:[1,9999]
示例 4:
输入:n = 69
输出:[1,68]
示例 5:
输入:n = 1010
输出:[11,999]
解题方式1:
class Solution {
public int[] getNoZeroIntegers(int n) {
for (int i = 1; i <= n/2; i++) {
if (String.valueOf(i).indexOf('0') == -1 && String.valueOf(n-i).indexOf('0') == -1 ){
return new int[]{i,n-i};
}
}
return new int[0];
}
}
力扣:1437 是否所有1都至少相隔k个元素
给你一个由若干
0和1组成的数组nums以及整数k。如果所有1都至少相隔k个元素,则返回True;否则,返回False。
示例 1:
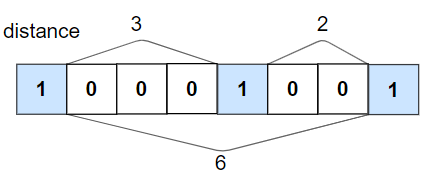
输入:nums = [1,0,0,0,1,0,0,1], k = 2
输出:true
解释:每个 1 都至少相隔 2 个元素。
示例 2:
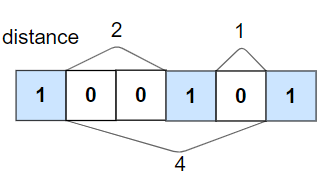
输入:nums = [1,0,0,1,0,1], k = 2
输出:false
解释:第二个 1 和第三个 1 之间只隔了 1 个元素。
示例 3:
输入:nums = [1,1,1,1,1], k = 0
输出:true
示例 4:
输入:nums = [0,1,0,1], k = 1
输出:true
解题方式1:迭代法
class Solution {
public boolean kLengthApart(int[] nums, int k) {
int index1 = 0;//定位1的下标
int index2 = 0;//定位1的下标
boolean flag = false;//是否取到第一个1的下标
for (int i = 0; i < nums.length; i++) {
if (flag == false){//首先要取到第一个1的下标
if (nums[i] == 1){
index1 = i;
flag = true;
}
}else{//取到第一个1的下标后,后面就简单了
if (nums[i] == 1){//判断该值是否为1
index2 = i;//下标赋值给index2
if (index2 -index1-1 < k){//判断距离
return false;
}
index1 = i;//下标赋值给index1
}
}
}
return true;
}
}
力扣:1464 数组中两元素的最大乘积
给你一个整数数组 nums,请你选择数组的两个不同下标 i 和 j,使 (nums[i]-1)*(nums[j]-1) 取得最大值。
请你计算并返回该式的最大值。
示例 1:
输入:nums = [3,4,5,2]
输出:12
解释:如果选择下标 i=1 和 j=2(下标从 0 开始),则可以获得最大值,(nums[1]-1)*(nums[2]-1) = (4-1)*(5-1) = 3*4 = 12 。
示例 2:
输入:nums = [1,5,4,5]
输出:16
解释:选择下标 i=1 和 j=3(下标从 0 开始),则可以获得最大值 (5-1)*(5-1) = 16 。
示例 3:
输入:nums = [3,7]
输出:12
解题方式1:迭代法
class Solution {
public int maxProduct(int[] nums) {
Arrays.sort(nums);
int start = (nums[0]-1)*(nums[1]-1);
int end = (nums[nums.length-1]-1)*(nums[nums.length-2]-1);
return start > end ? start : end;
}
}
力扣:1480 一维数组的动态和
给你一个数组 nums 。数组「动态和」的计算公式为:runningSum[i] = sum(nums[0]…nums[i]) 。
请返回 nums 的动态和。
示例 1:
输入:nums = [1,2,3,4]
输出:[1,3,6,10]
解释:动态和计算过程为 [1, 1+2, 1+2+3, 1+2+3+4] 。
示例 2:
输入:nums = [1,1,1,1,1]
输出:[1,2,3,4,5]
解释:动态和计算过程为 [1, 1+1, 1+1+1, 1+1+1+1, 1+1+1+1+1] 。
示例 3:
输入:nums = [3,1,2,10,1]
输出:[3,4,6,16,17]
解题方式1:
class Solution {
public int[] runningSum(int[] nums) {
ArrayList<Integer> list = new ArrayList<Integer>();
int sum = 0;
for(int i=0;i<nums.length;i++){
sum+=nums[i];
list.add(sum);
}
int[] ints = new int[list.size()];
for (int i = 0; i < ints.length; i++) {
ints[i]= list.get(i);
}
return ints;
}
}
力扣:1518 换水问题
超市正在促销,你可以用 numExchange 个空水瓶从超市兑换一瓶水。最开始,你一共购入了 numBottles 瓶水。
如果喝掉了水瓶中的水,那么水瓶就会变成空的。
给你两个整数 numBottles 和 numExchange ,返回你 最多 可以喝到多少瓶水。
示例 1:
输入:numBottles = 9, numExchange = 3
输出:13
解释:你可以用 3 个空瓶兑换 1 瓶水。
所以最多能喝到 9 + 3 + 1 = 13 瓶水。
示例 2:
输入:numBottles = 15, numExchange = 4
输出:19
解释:你可以用 4 个空瓶兑换 1 瓶水。
所以最多能喝到 15 + 3 + 1 = 19 瓶水。
解题方式1:
class Solution {
public int numWaterBottles(int numBottles, int numExchange) {
int sum = numBottles;//最多的数量
int over = 0;//每次还完后剩余的数量
while(numBottles/numExchange!=0){
over = numBottles % numExchange;
numBottles = numBottles / numExchange;
sum+=numBottles;
numBottles+=over;
}
return sum;
}
}
力扣:1556 千位分隔数
给你一个整数 n,请你每隔三位添加点(即 “.” 符号)作为千位分隔符,并将结果以字符串格式返回。
示例 1:
输入:n = 987
输出:"987"
示例 2:
输入:n = 1234
输出:"1.234"
示例 3:
输入:n = 123456789
输出:"123.456.789"
示例 4:
输入:n = 0
输出:"0"
解题方式1:字符串类型格式化
class Solution {
public String thousandSeparator(int n) {
String format = String.format("%,d", n).replace(',','.');
return format;
}
}
解题方式2:
class Solution {
public String thousandSeparator(int n) {
StringBuilder sb = new StringBuilder(String.valueOf(n));
for (int i = sb.length()-3; i >0 ; i-=3) {
sb.insert(i,".");
}
return sb.toString();
}
}
力扣:1736 替换隐藏数字得到的最晚时间
给你一个字符串 time ,格式为 hh:mm(小时:分钟),其中某几位数字被隐藏(用 ? 表示)。
有效的时间为 00:00 到 23:59 之间的所有时间,包括 00:00 和 23:59 。
替换 time 中隐藏的数字,返回你可以得到的最晚有效时间。
示例 1:
输入:time = "2?:?0"
输出:"23:50"
解释:以数字 '2' 开头的最晚一小时是 23 ,以 '0' 结尾的最晚一分钟是 50 。
示例 2:
输入:time = "0?:3?"
输出:"09:39"
示例 3:
输入:time = "1?:22"
输出:"19:22"
解题方式1:枚举法
class Solution {
public String maximumTime(String time) {
char[] chars = time.toCharArray();
for (int i = 0; i < chars.length; i++) {
if (chars[i] == '?'){//判断是否是?
if (i == 0){//判断下标为0是?时的情况
if(chars[i+1] == '?'){//如果下标为1的值是?
chars[i] = '2';
}else if (chars[i+1] >= '4'){
chars[i] = '1';
}else{
chars[i] = '2';
}
}else if (i == 1){//判断下标为1是?的情况
switch (chars[i-1]){
case '0':
chars[i] = '9';
break;
case '1':
chars[i] = '9';
break;
case '2':
chars[i] = '3';
break;
}
}else if (i == 3){//判断下标为3是?的情况
chars[i] = '5';
}else if (i == 4){//判断下标为4是?的情况
chars[i] = '9';
}
}
}
return new String(chars);
}
}
力扣:1822 数组元素积的符号
已知函数 signFunc(x) 将会根据 x 的正负返回特定值:
如果 x 是正数,返回 1 。
如果 x 是负数,返回 -1 。
如果 x 是等于 0 ,返回 0 。
给你一个整数数组 nums 。令 product 为数组 nums 中所有元素值的乘积。返回 signFunc(product) 。
示例 1:
输入:nums = [-1,-2,-3,-4,3,2,1]
输出:1
解释:数组中所有值的乘积是 144 ,且 signFunc(144) = 1
示例 2:
输入:nums = [1,5,0,2,-3]
输出:0
解释:数组中所有值的乘积是 0 ,且 signFunc(0) = 0
示例 3:
输入:nums = [-1,1,-1,1,-1]
输出:-1
解释:数组中所有值的乘积是 -1 ,且 signFunc(-1) = -1
解题方式1:迭代法
class Solution {
public int arraySign(int[] nums) {
int negativeCount = 0;//负数数量
int positiveCount = 0;//正数数量
for (int i = 0; i < nums.length; i++) {
if (nums[i] < 0){
negativeCount++;
}else if(nums[i] > 0){
positiveCount++;
}else {
return 0;
}
}
return negativeCount%2==0 ? 1 :-1;
}
}
力扣:2335 装满杯子需要的最短总时长
现有一台饮水机,可以制备冷水、温水和热水。每秒钟,可以装满 2 杯 不同 类型的水或者 1 杯任意类型的水。
给你一个下标从 0 开始、长度为 3 的整数数组 amount ,其中 amount[0]、amount[1] 和 amount[2] 分别表示需要装满冷水、温水和热水的杯子数量。返回装满所有杯子所需的 最少 秒数。
示例 1:
输入:amount = [1,4,2]
输出:4
解释:下面给出一种方案:
第 1 秒:装满一杯冷水和一杯温水。
第 2 秒:装满一杯温水和一杯热水。
第 3 秒:装满一杯温水和一杯热水。
第 4 秒:装满一杯温水。
可以证明最少需要 4 秒才能装满所有杯子。
示例 2:
输入:amount = [5,4,4]
输出:7
解释:下面给出一种方案:
第 1 秒:装满一杯冷水和一杯热水。
第 2 秒:装满一杯冷水和一杯温水。
第 3 秒:装满一杯冷水和一杯温水。
第 4 秒:装满一杯温水和一杯热水。
第 5 秒:装满一杯冷水和一杯热水。
第 6 秒:装满一杯冷水和一杯温水。
第 7 秒:装满一杯热水。
示例 3:
输入:amount = [5,0,0]
输出:5
解释:每秒装满一杯冷水。
解题方式1:迭代法
class Solution {
public int fillCups(int[] amount) {
int count = 0;
//在装两种不同类型的水时,需要将最大的类型的水均摊到第一小和第二小的类型的水中
//每次对着最大的两个数字进行计算即可
while (amount[0]>0 || amount[1]>0 || amount[2] >0){//一直循环
//使用插入排序法降序排序
for (int i = 1; i < amount.length; i++) {
int index = i;//当前元素下标
int temp = amount[i];//待插入的元素
while (index-1 >=0){
if (temp > amount[index - 1]){//如果比插入的数大
amount[index] = amount[index -1];
index--;
}
else {
break;
}
}
amount[index] = temp;
}
if (amount[0]>0 && amount[1]>0){//比较大的前两个值
amount[0]--;
amount[1]--;
} else {//如果另外两个都为0,则只有最大的数减
amount[0]--;
}
count++;
}
return count;
}
}
中等
力扣:2 两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。

解题方式一:迭代法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
int total=0;//和
int nextl=0;//取进位值
ListNode result = new ListNode();
ListNode cur=result;//定义结果链表指针
while (l1!=null && l2!=null){//如果两个链表都没遍历完
total= l1.val+ l2.val+nextl;//
cur.next=new ListNode(total%10);
nextl=total/10;
l1=l1.next;//l1指向下一个节点的值
l2=l2.next;//l2指向下一个节点的值
cur=cur.next;
}
while (l1!=null){//如果l1没有遍历完
total=l1.val+nextl;
cur.next=new ListNode(total%10);
nextl=total/10;
l1=l1.next;
cur=cur.next;
}
while (l2!=null){//如果l2没有遍历完
total=l2.val+nextl;
cur.next=new ListNode(total%10);
nextl=total/10;
l2=l2.next;
cur=cur.next;
}
if (nextl!=0){//如果进位值不为0
cur.next=new ListNode(nextl);
}
//返回result.next,因为cur只是result的指针,而且存的值是总result.next开始的
return result.next;
}
}
解题方式二:递归法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
int total=l1.val+l2.val;//计算和
int nextl=total/10;//计算进位值
ListNode res = new ListNode(total % 10);//将其取模加入链表
if(l1.next!=null||l2.next!=null||nextl!=0){
if(l1.next!=null){//如果l1链表还存在值
l1=l1.next;
}else {
l1=new ListNode(0);
}
if(l2.next!=null){
l2=l2.next;
}else {
l2=new ListNode(0);
}
//l1的值加上这次进位的值,然后传给下一个调用
l1.val= l1.val+nextl;
//下一个节点,递归调用自身
res.next=addTwoNumbers(l1, l2);
}
return res;
}
}
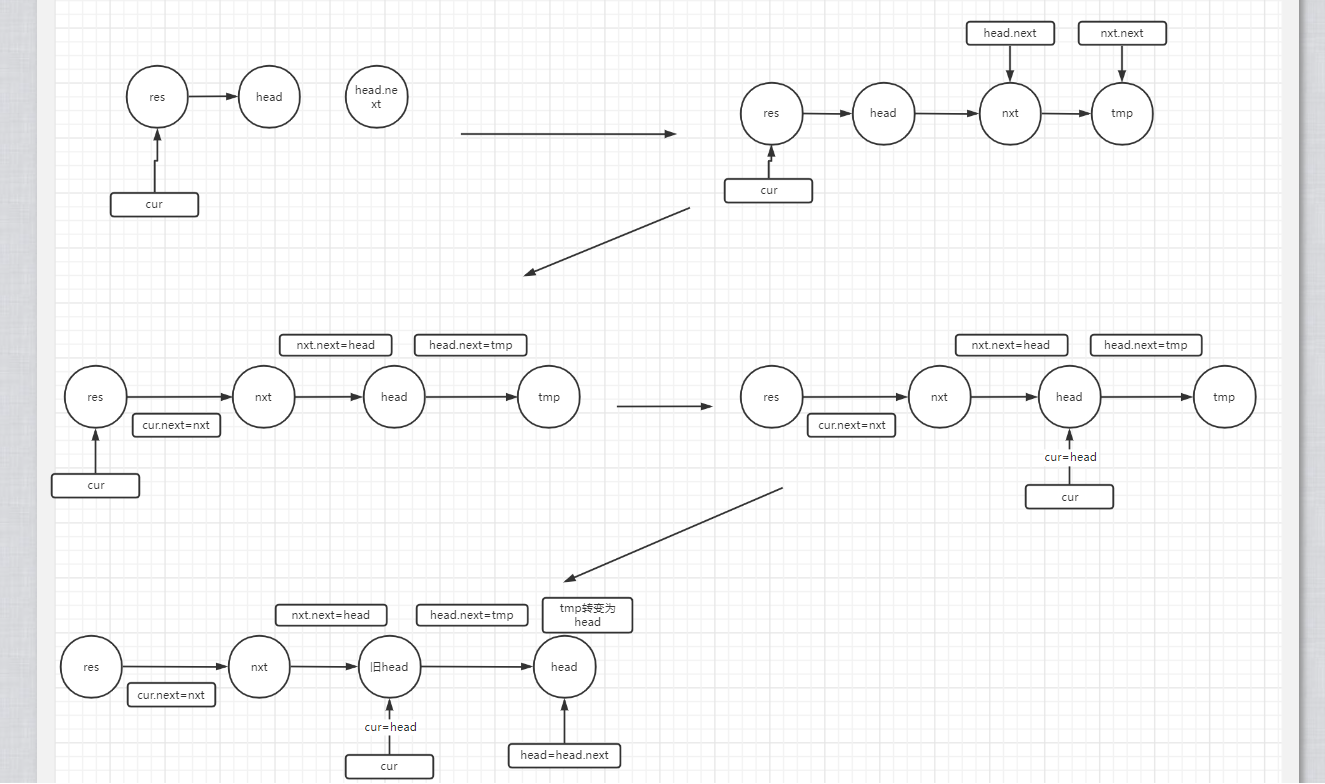
力扣:24 两两交换链表中的值
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)
示例 1:

输入:head = [1,2,3,4]
输出:[2,1,4,3]
示例 2:
输入:head = []
输出:[]
示例 3:
输入:head = [1]
输出:[1]
解题方式1:迭代法
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode swapPairs(ListNode head) {
if(head==null||head.next==null){
return head;
}
//创建一个新节点
ListNode res = new ListNode();
//该节点的下一个节点指向head
res.next=head;
//定义cur为res的指针
ListNode cur=res;
while (cur.next!=null&&cur.next.next!=null){
//nxt节点为head节点的next节点
ListNode nxt=head.next;
//tmp节点为head节点的next节点的next节点
ListNode tmp=nxt.next;
//res节点的下一个节点指向nxt节点
cur.next=nxt;
//nxt节点的下一个节点指向head节点
nxt.next=head;
//head节点的下一个节点指向tmp节点
head.next=tmp;
//cur节点指向head节点,作为指针
cur=head;
//将head节点更换好head节点的下一个节点上
head=head.next;
//这个时候cur指针与head节点的相对位置依旧与初次进入循环一致
//继续循环
}
//
return res.next;
}
}
解题方式二:递归法
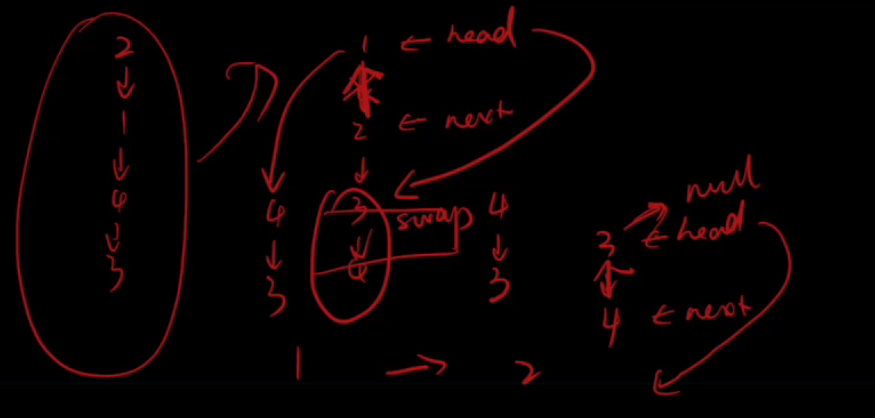
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode swapPairs(ListNode head) {
if(head==null||head.next==null){
return head;
}
//定义nxt节点等于head节点的next节点
ListNode nxt=head.next;
//定义head节点的next节点为head节点的next节点的next节点
head.next=swapPairs(head.next.next);
//定义nxt节点的下一个节点为head
nxt.next=head;
return nxt;
}
}
力扣:39 组合总数
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
示例 1:
输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。
示例 2:
输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
示例 3:
输入: candidates = [2], target = 1
输出: []
解题方式1:回溯法
class Solution {
List<List<Integer>> res = new ArrayList<>();
public List<List<Integer>> combinationSum(int[] candidates, int target) {
ArrayList<Integer> list = new ArrayList<>();
Arrays.sort(candidates);
helper(candidates,target,list,0);
return res;
}
/*
回溯法
*/
public void helper(int[] candidates,int target,List<Integer> list,int i){
if (target<0){
return;
}
if (target == 0 ){
res.add(new ArrayList<>(list));
return;
}
for (int j = i; j < candidates.length; j++) {
list.add(candidates[j]);
//为了实现可以遍历重复的元素,所以设置传递j
helper(candidates,target-candidates[j],list,j);
list.remove(list.size()-1);
}
}
}
力扣:40 组合总和Ⅱ
给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用 一次 。
注意:解集不能包含重复的组合。
示例 1:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
示例 2:
输入: candidates = [2,5,2,1,2], target = 5,
输出:
[
[1,2,2],
[5]
]
解题方式1:回溯法
class Solution {
List<List<Integer>> res = new ArrayList<>();
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates);
ArrayList<Integer> list = new ArrayList<>();
helper(candidates,0,target,list);
// res.forEach(re ->{
// Collections.sort(re, new Comparator<Integer>() {
// @Override
// public int compare(Integer o1, Integer o2) {
// return o1-o2;
// }
// });
// });
// HashSet<List<Integer>> set = new HashSet<>(new ArrayList<>(res));
// ArrayList<List<Integer>> lists1 = new ArrayList<>(set);
return res;
}
public void helper(int[] candidates,int n,int target,List<Integer> list){
if (target == 0){
res.add(new ArrayList<>(list));
return;
}else if(target < 0){
return;
}
for (int i = n; i < candidates.length; i++) {
// 要对同一树层使用过的元素进行跳过
if (i > n && candidates[i] == candidates[i - 1]) {
continue;
}
list.add(candidates[i]);
helper(candidates,i+1,target-candidates[i],list);
list.remove(list.size()-1);
}
}
}
力扣:46 全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例 3:
输入:nums = [1]
输出:[[1]]
解题方式:回溯法
class Solution {
List<List<Integer>> res = new ArrayList<>();//定义全局变量存储数据
public List<List<Integer>> permute(int[] nums) {
List<Integer> path = new ArrayList<>();//存储每次排列的结果
back(nums,path);
return res;
}
public void back(int[] nums,List<Integer> path){
if (path.size() == nums.length){//如果排列的数量和传进来的数组数量相等了,则将其添加到res中
res.add(new ArrayList(path));//确保不会修改之前传入的值
}else{
for (int i = 0; i < nums.length; i++) {//循环遍历
if (path.contains(nums[i])){//集合中存在该值,则跳过本次遍历
continue;
}
path.add(nums[i]);//否则加入集合中
back(nums,path);//继续全排列判断
path.remove(path.size()-1);//全排列完毕后会后退,此时需要将刚刚加入的值去除
}
}
}
}
力扣:49 字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
示例 1:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
示例 2:
输入: strs = [""]
输出: [[""]]
示例 3:
输入: strs = ["a"]
输出: [["a"]]
解题方式1:排序法
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String, ArrayList<String>> map = new HashMap<>();
for (int i = 0; i < strs.length; i++) {
char[] chars = strs[i].toCharArray();
Arrays.sort(chars);
String key = new String(chars);
if (!map.containsKey(key)){
map.put(key,new ArrayList<String>());
}
map.get(key).add(strs[i]);
}
return new ArrayList<>(map.values());
}
}
解题方式2:哈希法
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String, ArrayList<String>> map = new HashMap<>();
for (String s : strs) {
int[] count_table = new int[26];
for (char c : s.toCharArray()) {
count_table[c-'a']++;
}
StringBuilder stringBuilder = new StringBuilder();
for (int count : count_table) {
stringBuilder.append("#");
stringBuilder.append(count);
}
String key = stringBuilder.toString();
if (!map.containsKey(key)){
map.put(key,new ArrayList<String>());
}
map.get(key).add(s);
}
return new ArrayList<>(map.values());
}
}
力扣:53 最大子数组和
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组 是数组中的一个连续部分。
示例 1:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
输出:6
解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
示例 2:
输入:nums = [1]
输出:1
示例 3:
输入:nums = [5,4,-1,7,8]
输出:23
解题方式1:动态规划
public static int maxSubArray(int[] nums) {
if (nums.length == 1){//如果数组长度为1则直接返回
return nums[0];
}
int max = nums[0]; //最大值
int sum = 0; //总值
for (int i = 0; i < nums.length; i++) {
if (sum<0){//如果sum小于0,则sum更换为本次遍历的值
sum = nums[i];
}else{//否则添加
sum = sum+nums[i];
}
max = Math.max(max,sum);//赋值给max
}
return max;
}
解题方式2:暴力法
class Solution {
public int maxSubArray(int[] nums) {
if (nums.length == 1){
return nums[0];
}
int max = nums[0];
for (int i = 0; i < nums.length; i++) {
int temp = nums[i];
if (temp>max){
max=temp;
}
for (int j = i+1; j < nums.length; j++) {
temp = temp+nums[j];
if (temp>max){
max=temp;
}
}
}
return max;
}
}
力扣:56 合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
解题方式1:暴力排序法
public static int[][] merge(int[][] intervals) {
if (intervals.length == 1){
return intervals;
}
int[][] ints = new int[intervals.length][2];
//for (int i = 0; i < intervals.length - 1; i++) {//数组排序
// for (int j = i+1; j < intervals.length; j++) {
//
// if (intervals[i][0] > intervals[j][0]){
// int[] temp = intervals[i];
// intervals[i] = intervals[j];
// intervals[j] = temp;
// }
//
// }
//}
//按照前区间升序排序
Arrays.sort(intervals, new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
//return o1[0]-o2[0];
return o1[0]-o2[0];
}
});
int count = 0;
for (int i = 0; i < intervals.length -1; i++) {
if (intervals[i][1] >= intervals[i+1][0]){//如果前一个区间的后区间>=后一个区间的前区间,则进行合并
//判断区间条件
if (intervals[i][1] <= intervals[i+1][1] && intervals[i][0] <= intervals[i+1][0]){
ints[count][0]=intervals[i][0];
ints[count][1]=intervals[i+1][1];
}else if (intervals[i][1] >= intervals[i+1][1] && intervals[i][0] <= intervals[i+1][0]){
ints[count][0]=intervals[i][0];
ints[count][1]=intervals[i][1];
}else if (intervals[i][1] <= intervals[i+1][1] && intervals[i][0] >= intervals[i+1][0]){
ints[count][0]=intervals[i+1][0];
ints[count][1]=intervals[i][1];
}else if (intervals[i][1] >= intervals[i+1][1] && intervals[i][0] >= intervals[i+1][0]){
ints[count][0]=intervals[i+1][0];
ints[count][1]=intervals[i][1];
}
intervals[i+1] = ints[count];//将合并后的区间重新赋值到原数组进行比较
}else{
ints[count][0]=intervals[i][0];
ints[count][1]=intervals[i][1];
count++;
if (i == intervals.length-2){ //最后一个值也需要写入
ints[count][0]=intervals[i+1][0];
ints[count][1]=intervals[i+1][1];
}
}
}
return Arrays.copyOf(ints,count+1);
}
力扣:57 插入区间
给你一个 无重叠的 ,按照区间起始端点排序的区间列表。
在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。
示例 1:
输入:intervals = [[1,3],[6,9]], newInterval = [2,5]
输出:[[1,5],[6,9]]
示例 2:
输入:intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8]
输出:[[1,2],[3,10],[12,16]]
解释:这是因为新的区间 [4,8] 与 [3,5],[6,7],[8,10] 重叠。
示例 3:
输入:intervals = [], newInterval = [5,7]
输出:[[5,7]]
示例 4:
输入:intervals = [[1,5]], newInterval = [2,3]
输出:[[1,5]]
示例 5:
输入:intervals = [[1,5]], newInterval = [2,7]
输出:[[1,7]]
解题方式1:排序法
/*
* 与力扣56有异曲同工之妙,只是先将要插入的数组和原数组重组成一个新数组
*/
class Solution {
public int[][] insert(int[][] intervals, int[] newInterval) {
//将新插入的区间与原区间形成一个新数组
int[][] arr = new int[intervals.length+1][2];
for (int i = 0; i < intervals.length; i++) {
arr[i] = intervals[i];
}
arr[intervals.length] = newInterval;
//如果新数组长度为1则直接返回
if (arr.length == 1){
return arr;
}
//创建一个数组存储正确的区间值
int[][] ints = new int[arr.length][2];
//将区间数组按照前区间进行升序排序
Arrays.sort(arr, new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
//return o1[0]-o2[0];
return o1[0]-o2[0];
}
});
//区间数量
int count = 0;
for (int i = 0; i < arr.length -1; i++) {
if (arr[i][1] >= arr[i+1][0]){//如果前一个区间的后区间>=后一个区间的前区间,则进行合并
//判断区间条件
if (arr[i][1] <= arr[i+1][1] && arr[i][0] <= arr[i+1][0]){
ints[count][0]=arr[i][0];
ints[count][1]=arr[i+1][1];
}else if (arr[i][1] >= arr[i+1][1] && arr[i][0] <= arr[i+1][0]){
ints[count][0]=arr[i][0];
ints[count][1]=arr[i][1];
}else if (arr[i][1] <= arr[i+1][1] && arr[i][0] >= arr[i+1][0]){
ints[count][0]=arr[i+1][0];
ints[count][1]=arr[i][1];
}else if (arr[i][1] >= arr[i+1][1] && arr[i][0] >= arr[i+1][0]){
ints[count][0]=arr[i+1][0];
ints[count][1]=arr[i][1];
}
arr[i+1] = ints[count];//将合并后的区间重新赋值到原数组,然后下一个区间与该合并后的区间进行比较
}else{
//如果不区间不重合,则赋值
ints[count][0]=arr[i][0];
ints[count][1]=arr[i][1];
count++;
if (i == arr.length-2){ //最后一个值也需要写入
ints[count][0]=arr[i+1][0];
ints[count][1]=arr[i+1][1];
}
}
}
//返回ints对应长度的数组,后面的空值不需要
return Arrays.copyOf(ints,count+1);
}
}
力扣:77 组合
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
示例 2:
输入:n = 1, k = 1
输出:[[1]]
解题方式:回溯法
//回溯法
class Solution {
List<List<Integer>> result = new ArrayList<>();//返回的结果
public List<List<Integer>> combine(int n, int k) {
if (n == 0){
return result;
}
ArrayList<Integer> list = new ArrayList<>();//符合条件的数据
back(1,n,k,list);
return result;
}
/**
* 回溯方法
* @param i 当前执行到的数字
* @param n [1-n]的区间
* @param k k个数的组合
* @param list 符合条件的数据
*/
public void back(int i,int n,int k,List<Integer> list){
if (list.size() == k){//如果符合条件的数据达到k个,则加入
result.add(new ArrayList<>(list));//这里必须新建集合,否则之前的值会被修改
return;
}
for (int j = i; j <= n; j++) {
list.add(i);
back(i+1,n,k,list);
i++;
list.remove(list.size()-1);//执行完成后需要删掉加入的这个值,回溯
}
}
}
力扣:78 子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
解题方式1:回溯法
class Solution {
List<List<Integer>> res = new ArrayList<>();
public List<List<Integer>> subsets(int[] nums) {
List<Integer> list = new ArrayList<>();
back(nums,0,list);
return res;
}
public void back(int[] nums,int temp,List<Integer> list){
if (nums.length == temp){
res.add(new ArrayList<>(list));
return;
}
//将子集加入到总集合中
back(nums,temp+1,list);
//放入现有的子集中
list.add(nums[temp]);
back(nums,temp+1,list);
//移除该元素
list.remove(list.size() -1);
}
}
解题方式2:动态规划
class Solution {
public List<List<Integer>> subsets(int[] nums) {
List<List<Integer>> lists = new ArrayList<>(); // 解集
lists.add(new ArrayList<Integer>()); // 首先将空集加入解集中
for(int i = 0; i < nums.length; i++){
int size = lists.size(); // 当前子集数
for(int j = 0; j < size; j++){
List<Integer> newList = new ArrayList<>(lists.get(j));// 拷贝所有子集
newList.add(nums[i]); // 向拷贝的子集中加入当前数形成新的子集
lists.add(newList); // 向lists中加入新子集
}
}
return lists;
}
}
力扣:80 删除有序数组中的重复项Ⅱ
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [1,1,1,2,2,3]
输出:5, nums = [1,1,2,2,3]
解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3 。 不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,1,2,3,3]
输出:7, nums = [0,0,1,1,2,3,3]
解释:函数应返回新长度 length = 7, 并且原数组的前五个元素被修改为 0, 0, 1, 1, 2, 3, 3 。 不需要考虑数组中超出新长度后面的元素。
解题方式1:迭代法
class Solution {
public int removeDuplicates(int[] nums) {
int temp = 0;//记录数量
/*
foreach遍历数组
num一直在变,temp根据元素数量去变,nums[temp]及其之前的数组都是出现次数不超过两次的元素
*/
for (int num : nums) {
/*
如果循环次数小于2,数组中直接更新
如果num<nums[temp - 2],则说明nums[temp - 2]是和num相等的,这里取反
*/
if (temp < 2 || num > nums[temp - 2]){
nums[temp++] = num;
}
}
return temp;
}
}
力扣:90 子集Ⅱ
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例 1:
输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
解题方式1:回溯法
class Solution {
List<List<Integer>> res = new ArrayList<>();
public List<List<Integer>> subsetsWithDup(int[] nums) {
List<Integer> list = new ArrayList<>();
back(nums,0,list);
//将返回的集合进行排序
res.forEach(re ->{
re.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1-o2;
}
});
});
//将结果集转为set,去重
Set<List<Integer>> hashSet = new HashSet<>(res);
//再将set转为list
List<List<Integer>> lists = new ArrayList<>(hashSet);
return lists;//返回去重后的list
}
public void back(int[] nums,int temp,List<Integer> list){
if (nums.length == temp){
res.add(new ArrayList<>(list));
return;
}
//将子集加入到总集合中
back(nums,temp+1,list);
//放入现有的子集中
list.add(nums[temp]);
back(nums,temp+1,list);
//移除该元素
list.remove(list.size() -1);
}
}
力扣:137 只出现一次的数字
给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法且不使用额外空间来解决此问题。
示例 1:
输入:nums = [2,2,3,2]
输出:3
示例 2:
输入:nums = [0,1,0,1,0,1,99]
输出:99
解题方式1:迭代法
class Solution {
public int singleNumber(int[] nums) {
Arrays.sort(nums);//排序
if (nums.length == 1){
return nums[0];
}
for (int i = 0; i < nums.length; i=i+3) {
if (nums[i] != nums[i+2]){//如果相隔两个下标的值不相等,则返回nums[i]
return nums[i];
}
if (i+3 >=nums.length -1){//如果下一个循环的下标>=数组的下标,则返回下一个下标
return nums[i+3];
}
}
return 0;
}
}
力扣:142 环形链表 II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:

输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
解题方式:哈希法
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode detectCycle(ListNode head) {
//哈希法,存储每次遍历的ListNode对象及其下标
HashMap<ListNode, Integer> map = new HashMap<>();
int index = 0;
while (head!=null){
if (map.containsKey(head)){//如果这个节点之前遍历过,则该节点是环的头结点
return head;
}
map.put(head,index);
index++;
head=head.next;
}
return null;
}
}
力扣:560 和为 K 的子数组
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的连续子数组的个数 。
示例 1:
输入:nums = [1,1,1], k = 2
输出:2
示例 2:
输入:nums = [1,2,3], k = 3
输出:2
解题方式1:迭代法
class Solution {
public int subarraySum(int[] nums, int k) {
int count = 0;//数量
int sum = 0;//和
int temp = 0;//当前指针
while (temp<nums.length){
for (int i = temp; i < nums.length; i++) {//遍历相加
sum+=nums[i];
if (sum==k){//如果相等则数量+1
count++;
}
}
sum = 0;//重置sum
temp++;//指针指向下一个
}
return count;
}
}
解题方式2:哈希表法
class Solution {
public int subarraySum(int[] nums, int k) {
/**
扫描一遍数组, 使用map记录出现同样的和的次数, 对每个i计算累计和sum并判断map内是否有sum-k
**/
Map<Integer, Integer> map = new HashMap<>();
map.put(0, 1);
int sum = 0, ret = 0;
for(int i = 0; i < nums.length; ++i) {
sum += nums[i];
if(map.containsKey(sum-k))
ret += map.get(sum-k);
map.put(sum, map.getOrDefault(sum, 0)+1);
}
return ret;
}
}
困难
LCP
简单
LCP:18 早餐组合
小扣在秋日市集选择了一家早餐摊位,一维整型数组 staple 中记录了每种主食的价格,一维整型数组 drinks 中记录了每种饮料的价格。小扣的计划选择一份主食和一款饮料,且花费不超过 x 元。请返回小扣共有多少种购买方案。
注意:答案需要以 1e9 + 7 (1000000007) 为底取模,如:计算初始结果为:1000000008,请返回 1
示例 1:
输入:staple = [10,20,5], drinks = [5,5,2], x = 15
输出:6
解释:小扣有 6 种购买方案,所选主食与所选饮料在数组中对应的下标分别是:
第 1 种方案:staple[0] + drinks[0] = 10 + 5 = 15;
第 2 种方案:staple[0] + drinks[1] = 10 + 5 = 15;
第 3 种方案:staple[0] + drinks[2] = 10 + 2 = 12;
第 4 种方案:staple[2] + drinks[0] = 5 + 5 = 10;
第 5 种方案:staple[2] + drinks[1] = 5 + 5 = 10;
第 6 种方案:staple[2] + drinks[2] = 5 + 2 = 7。
示例 2:
输入:staple = [2,1,1], drinks = [8,9,5,1], x = 9
输出:8
解释:小扣有 8 种购买方案,所选主食与所选饮料在数组中对应的下标分别是:
第 1 种方案:staple[0] + drinks[2] = 2 + 5 = 7;
第 2 种方案:staple[0] + drinks[3] = 2 + 1 = 3;
第 3 种方案:staple[1] + drinks[0] = 1 + 8 = 9;
第 4 种方案:staple[1] + drinks[2] = 1 + 5 = 6;
第 5 种方案:staple[1] + drinks[3] = 1 + 1 = 2;
第 6 种方案:staple[2] + drinks[0] = 1 + 8 = 9;
第 7 种方案:staple[2] + drinks[2] = 1 + 5 = 6;
第 8 种方案:staple[2] + drinks[3] = 1 + 1 = 2;
解题方式1:二分法
class Solution {
public int breakfastNumber(int[] staple, int[] drinks, int x) {
int sum = 0;
//Arrays.sort(staple);
Arrays.sort(drinks);
for (int val : staple) {
int cur = x - val;//cur为早餐不超过的价格
if (cur > 0){
sum += find(drinks,cur);
sum%= 1000000007;
}
}
return sum%1000000007;
}
//二分
public static int find(int[] drinks ,int cur){
int l = 0;
int r = drinks.length - 1;
while (l <= r){//结束条件
int mid = l + (r-l)/2;//中间下标
if (drinks[mid] <= cur){//如果中间下标的值小于或等于cur
l = mid + 1;
}else if(drinks[mid] > cur){
r = mid -1;
}
}
return l;
}
}
中等
困难
剑指offer
简单
剑指offer:09 用两个栈实现队列
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
看不懂题目?下面给你讲解
简单明了,带你直接看懂题目和例子。 输入: ["CQueue","appendTail","deleteHead","deleteHead"] 这里是要执行的方法,从左到右执行 [[],[3],[],[]]对应上面的方法,是上面方法的参数。CQueue和deleteHead方法不需要指定数字,只有添加才需要指定数字 1.创建队列,返回值为null 2.将3压入栈,返回值为null 3.将栈底的元素删除,也就是消息队列中先进来的元素,所以是deleteHead,返回该元素的数值,所以为3 4.继续删除栈底的元素,但是没有元素了,所以返回-1 所以就有了下面的输出 输出:[null,null,3,-1] 示例 2: 输入: ["CQueue","deleteHead","appendTail","appendTail","deleteHead","deleteHead"] [[],[],[5],[2],[],[]] 1.创建队列,返回值为null 2.删除栈底的元素,但是没有元素,所以返回-1 3.把5压入栈,返回null 4.把2压入栈,返回null 5.删除栈底的一个元素,也就是消息队列中先进来的元素,所以是deleteHead,就是最先进来的5,返回值为5, 6.删除栈底的一个元素,就是后进来的2,返回值为2, 所以就有了下面的输出 输出:[null,-1,null,null,5,2] 有没有发现先进来的数字,首先显示出来了,但是题目中说要使用栈,栈是先进后出的,使用栈来实现先进先出,在这里使用两个栈就好了,从一个进来再到另一个栈,这样顺序就是先进先出了。题目的主旨写在第一句,就是,使用两个栈实现一个队列。
示例 1:
输入:
["CQueue","appendTail","deleteHead","deleteHead","deleteHead"]
[[],[3],[],[],[]]
输出:[null,null,3,-1,-1]
示例 2:
输入:
["CQueue","deleteHead","appendTail","appendTail","deleteHead","deleteHead"]
[[],[],[5],[2],[],[]]
输出:[null,-1,null,null,5,2]
解题方式:
class CQueue {
Stack<Integer> stack1;
Stack<Integer> stack2;
public CQueue() {
stack1 = new Stack<>();
stack2 = new Stack<>();
}
public void appendTail(int value) {
stack1.add(value);
}
public int deleteHead() {
if (stack2.isEmpty()) {
if (stack1.isEmpty()) return -1;
while (!stack1.isEmpty()) {
stack2.add(stack1.pop());
}
return stack2.pop();
}
else return stack2.pop();
}
}
/**
* Your CQueue object will be instantiated and called as such:
* CQueue obj = new CQueue();
* obj.appendTail(value);
* int param_2 = obj.deleteHead();
*/
剑指offer:30 包含min函数的栈
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。
示例:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.min(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.min(); --> 返回 -2.
解题方式:
class MinStack {
Stack<Integer> stack;
ArrayList<Integer> list;
/** initialize your data structure here. */
public MinStack() {
stack = new Stack<Integer>();
list = new ArrayList<Integer>();
}
public void push(int x) {
stack.push(x);
list.add(x);
}
public void pop() {
int i = stack.pop();
list.remove(Integer.valueOf(i));
}
public int top() {
return stack.peek();
}
public int min() {
Collections.sort(list);
return list.get(0);
}
}
/**
* Your MinStack object will be instantiated and called as such:
* MinStack obj = new MinStack();
* obj.push(x);
* obj.pop();
* int param_3 = obj.top();
* int param_4 = obj.min();
*/
中等
困难
数据库
简单
力扣:175 组合两个表
表: Person
±------------±--------+
| 列名 | 类型 |
±------------±--------+
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
±------------±--------+
personId 是该表的主键列。
该表包含一些人的 ID 和他们的姓和名的信息。表: Address
±------------±--------+
| 列名 | 类型 |
±------------±--------+
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
±------------±--------+
addressId 是该表的主键列。
该表的每一行都包含一个 ID = PersonId 的人的城市和州的信息。编写一个SQL查询来报告 Person 表中每个人的姓、名、城市和州。如果 personId 的地址不在 Address 表中,则报告为空 null 。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入:
Person表:
+----------+----------+-----------+
| personId | lastName | firstName |
+----------+----------+-----------+
| 1 | Wang | Allen |
| 2 | Alice | Bob |
+----------+----------+-----------+
Address表:
+-----------+----------+---------------+------------+
| addressId | personId | city | state |
+-----------+----------+---------------+------------+
| 1 | 2 | New York City | New York |
| 2 | 3 | Leetcode | California |
+-----------+----------+---------------+------------+
输出:
+-----------+----------+---------------+----------+
| firstName | lastName | city | state |
+-----------+----------+---------------+----------+
| Allen | Wang | Null | Null |
| Bob | Alice | New York City | New York |
+-----------+----------+---------------+----------+
解释:
地址表中没有 personId = 1 的地址,所以它们的城市和州返回 null。
addressId = 1 包含了 personId = 2 的地址信息。
解题方式:
# Write your MySQL query statement below
select p.firstName,p.lastName,d.city,d.state
from Person p
left join Address d
on p.personId = d.personId
力扣:182 查找重复的电子邮箱
编写一个 SQL 查询,查找 Person 表中所有重复的电子邮箱。
示例:
+----+---------+
| Id | Email |
+----+---------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
+----+---------+
根据以上输入,你的查询应返回以下结果:
+---------+
| Email |
+---------+
| a@b.com |
+---------+
解题方式:
# Write your MySQL query statement below
select Email
from Person
group by Email
having count(Id)>1
力扣:183 从不订购的客户
某网站包含两个表,Customers 表和 Orders 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。
Customers 表:
+----+-------+
| Id | Name |
+----+-------+
| 1 | Joe |
| 2 | Henry |
| 3 | Sam |
| 4 | Max |
+----+-------+
Orders 表:
+----+------------+
| Id | CustomerId |
+----+------------+
| 1 | 3 |
| 2 | 1 |
+----+------------+
例如给定上述表格,你的查询应返回:
+-----------+
| Customers |
+-----------+
| Henry |
| Max |
+-----------+
解题方式:
select Name as Customers
from Customers
where Customers.Id not in (select CustomerId from Orders)
力扣:196 删除重复的电子邮箱
表: Person
±------------±--------+
| Column Name | Type |
±------------±--------+
| id | int |
| email | varchar |
±------------±--------+
id是该表的主键列。
该表的每一行包含一封电子邮件。电子邮件将不包含大写字母。编写一个 SQL 删除语句来 删除 所有重复的电子邮件,只保留一个id最小的唯一电子邮件。
以 任意顺序 返回结果表。 (注意: 仅需要写删除语句,将自动对剩余结果进行查询)
查询结果格式如下所示。
示例 1:
输入:
Person 表:
+----+------------------+
| id | email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
| 3 | john@example.com |
+----+------------------+
输出:
+----+------------------+
| id | email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
+----+------------------+
解释: john@example.com重复两次。我们保留最小的Id = 1。
解题方式:
# 删除表中id不为单个或最小的
# 通过分组email来进行查询单id
delete from Person
Where id not in (
select id
from(
select min(id) as id
from Person
group by email
) t
)
力扣:197 上升的温度
表: Weather
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| id | int |
| recordDate | date |
| temperature | int |
±--------------±--------+
id 是这个表的主键
该表包含特定日期的温度信息编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 不要求顺序 。
查询结果格式如下例。
示例 1:
输入:
Weather 表:
+----+------------+-------------+
| id | recordDate | Temperature |
+----+------------+-------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+----+------------+-------------+
输出:
+----+
| id |
+----+
| 2 |
| 4 |
+----+
解释:
2015-01-02 的温度比前一天高(10 -> 25)
2015-01-04 的温度比前一天高(20 -> 30)
解题方式:
# Write your MySQL query statement below
select b.id
from Weather a,Weather b
where a.temperature < b.temperature and datediff(b.recordDate,a.recordDate)=1
力扣:511 游戏玩法分析 I
活动表 Activity:
±-------------±--------+
| Column Name | Type |
±-------------±--------+
| player_id | int |
| device_id | int |
| event_date | date |
| games_played | int |
±-------------±--------+
表的主键是 (player_id, event_date)。
这张表展示了一些游戏玩家在游戏平台上的行为活动。
每行数据记录了一名玩家在退出平台之前,当天使用同一台设备登录平台后打开的游戏的数目(可能是 0 个)。写一条 SQL 查询语句获取每位玩家 第一次登陆平台的日期。
查询结果的格式如下所示:
Activity 表:
+-----------+-----------+------------+--------------+
| player_id | device_id | event_date | games_played |
+-----------+-----------+------------+--------------+
| 1 | 2 | 2016-03-01 | 5 |
| 1 | 2 | 2016-05-02 | 6 |
| 2 | 3 | 2017-06-25 | 1 |
| 3 | 1 | 2016-03-02 | 0 |
| 3 | 4 | 2018-07-03 | 5 |
+-----------+-----------+------------+--------------+
Result 表:
+-----------+-------------+
| player_id | first_login |
+-----------+-------------+
| 1 | 2016-03-01 |
| 2 | 2017-06-25 |
| 3 | 2016-03-02 |
+-----------+-------------+
解题方式:
# Write your MySQL query statement below
select player_id ,min(event_date) first_login
from Activity
group by player_id
力扣:595 大的国家
World 表:
±------------±--------+
| Column Name | Type |
±------------±--------+
| name | varchar |
| continent | varchar |
| area | int |
| population | int |
| gdp | int |
±------------±--------+
name 是这张表的主键。
这张表的每一行提供:国家名称、所属大陆、面积、人口和 GDP 值。如果一个国家满足下述两个条件之一,则认为该国是 大国 :
面积至少为 300 万平方公里(即,3000000 km2),或者
人口至少为 2500 万(即 25000000)
编写一个 SQL 查询以报告 大国 的国家名称、人口和面积。按 任意顺序 返回结果表。
查询结果格式如下例所示。
示例:
输入:
World 表:
+-------------+-----------+---------+------------+--------------+
| name | continent | area | population | gdp |
+-------------+-----------+---------+------------+--------------+
| Afghanistan | Asia | 652230 | 25500100 | 20343000000 |
| Albania | Europe | 28748 | 2831741 | 12960000000 |
| Algeria | Africa | 2381741 | 37100000 | 188681000000 |
| Andorra | Europe | 468 | 78115 | 3712000000 |
| Angola | Africa | 1246700 | 20609294 | 100990000000 |
+-------------+-----------+---------+------------+--------------+
输出:
+-------------+------------+---------+
| name | population | area |
+-------------+------------+---------+
| Afghanistan | 25500100 | 652230 |
| Algeria | 37100000 | 2381741 |
+-------------+------------+---------+
解题方式:
select name name,population population,area `area`
from World
where population>=25000000 or area>=3000000
力扣:584 寻找用户推荐人
给定表 customer ,里面保存了所有客户信息和他们的推荐人。
±-----±-----±----------+
| id | name | referee_id|
±-----±-----±----------+
| 1 | Will | NULL |
| 2 | Jane | NULL |
| 3 | Alex | 2 |
| 4 | Bill | NULL |
| 5 | Zack | 1 |
| 6 | Mark | 2 |
±-----±-----±----------+
写一个查询语句,返回一个客户列表,列表中客户的推荐人的编号都 不是 2。对于上面的示例数据,结果为:
±-----+
| name |
±-----+
| Will |
| Jane |
| Bill |
| Zack |
±-----+
解题方式:
select name
from customer
where referee_id!=2 or referee_id is null
力扣:586 订单最多的客户
表: Orders
±----------------±---------+
| Column Name | Type |
±----------------±---------+
| order_number | int |
| customer_number | int |
±----------------±---------+
Order_number是该表的主键。
此表包含关于订单ID和客户ID的信息。编写一个SQL查询,为下了 最多订单 的客户查找 customer_number 。
测试用例生成后, 恰好有一个客户 比任何其他客户下了更多的订单。
查询结果格式如下所示。
示例 1:
输入:
Orders 表:
+--------------+-----------------+
| order_number | customer_number |
+--------------+-----------------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 3 |
+--------------+-----------------+
输出:
+-----------------+
| customer_number |
+-----------------+
| 3 |
+-----------------+
解释:
customer_number 为 '3' 的顾客有两个订单,比顾客 '1' 或者 '2' 都要多,因为他们只有一个订单。
所以结果是该顾客的 customer_number ,也就是 3 。
解题方式:
# Write your MySQL query statement below
select customer_number
from Orders
group by customer_number
order by count(customer_number) desc
limit 0,1
力扣:596 超过5名学生的课
表: Courses
±------------±--------+
| Column Name | Type |
±------------±--------+
| student | varchar |
| class | varchar |
±------------±--------+
(student, class)是该表的主键列。
该表的每一行表示学生的名字和他们注册的班级。编写一个SQL查询来报告 至少有5个学生 的所有班级。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入:
Courses table:
+---------+----------+
| student | class |
+---------+----------+
| A | Math |
| B | English |
| C | Math |
| D | Biology |
| E | Math |
| F | Computer |
| G | Math |
| H | Math |
| I | Math |
+---------+----------+
输出:
+---------+
| class |
+---------+
| Math |
+---------+
解释:
-数学课有6个学生,所以我们包括它。
-英语课有1名学生,所以我们不包括它。
-生物课有1名学生,所以我们不包括它。
-计算机课有1个学生,所以我们不包括它。
解题方式:
select class
from Courses
group by class
having count(student)>=5
力扣:607 销售员
表: SalesPerson
±----------------±--------+
| Column Name | Type |
±----------------±--------+
| sales_id | int |
| name | varchar |
| salary | int |
| commission_rate | int |
| hire_date | date |
±----------------±--------+
sales_id 是该表的主键列。
该表的每一行都显示了销售人员的姓名和 ID ,以及他们的工资、佣金率和雇佣日期。表: Company
±------------±--------+
| Column Name | Type |
±------------±--------+
| com_id | int |
| name | varchar |
| city | varchar |
±------------±--------+
com_id 是该表的主键列。
该表的每一行都表示公司的名称和 ID ,以及公司所在的城市。表: Orders
±------------±-----+
| Column Name | Type |
±------------±-----+
| order_id | int |
| order_date | date |
| com_id | int |
| sales_id | int |
| amount | int |
±------------±-----+
order_id 是该表的主键列。
com_id 是 Company 表中 com_id 的外键。
sales_id 是来自销售员表 sales_id 的外键。
该表的每一行包含一个订单的信息。这包括公司的 ID 、销售人员的 ID 、订单日期和支付的金额。编写一个SQL查询,报告没有任何与名为 “RED” 的公司相关的订单的所有销售人员的姓名。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例:
输入:
SalesPerson 表:
+----------+------+--------+-----------------+------------+
| sales_id | name | salary | commission_rate | hire_date |
+----------+------+--------+-----------------+------------+
| 1 | John | 100000 | 6 | 4/1/2006 |
| 2 | Amy | 12000 | 5 | 5/1/2010 |
| 3 | Mark | 65000 | 12 | 12/25/2008 |
| 4 | Pam | 25000 | 25 | 1/1/2005 |
| 5 | Alex | 5000 | 10 | 2/3/2007 |
+----------+------+--------+-----------------+------------+
Company 表:
+--------+--------+----------+
| com_id | name | city |
+--------+--------+----------+
| 1 | RED | Boston |
| 2 | ORANGE | New York |
| 3 | YELLOW | Boston |
| 4 | GREEN | Austin |
+--------+--------+----------+
Orders 表:
+----------+------------+--------+----------+--------+
| order_id | order_date | com_id | sales_id | amount |
+----------+------------+--------+----------+--------+
| 1 | 1/1/2014 | 3 | 4 | 10000 |
| 2 | 2/1/2014 | 4 | 5 | 5000 |
| 3 | 3/1/2014 | 1 | 1 | 50000 |
| 4 | 4/1/2014 | 1 | 4 | 25000 |
+----------+------------+--------+----------+--------+
输出:
+------+
| name |
+------+
| Amy |
| Mark |
| Alex |
+------+
解释:
根据表 orders 中的订单 '3' 和 '4' ,容易看出只有 'John' 和 'Pam' 两个销售员曾经向公司 'RED' 销售过。
所以我们需要输出表 salesperson 中所有其他人的名字。
解题方式:
# Write your MySQL query statement below
select name
from SalesPerson
where sales_id not in(
#查找出与“RED”公司订单有关的销售人员姓名
select distinct(o.sales_id)
from Company c,Orders o
where c.name = "RED" and c.com_id = o.com_id
)
力扣:627 变更性别
Salary 表:
±------------±---------+
| Column Name | Type |
±------------±---------+
| id | int |
| name | varchar |
| sex | ENUM |
| salary | int |
±------------±---------+
id 是这个表的主键。
sex 这一列的值是 ENUM 类型,只能从 (‘m’, ‘f’) 中取。
本表包含公司雇员的信息。请你编写一个 SQL 查询来交换所有的 ‘f’ 和 ‘m’ (即,将所有 ‘f’ 变为 ‘m’ ,反之亦然),仅使用 单个 update 语句 ,且不产生中间临时表。
注意,你必须仅使用一条 update 语句,且 不能 使用 select 语句。
查询结果如下例所示。
示例 1:
输入:
Salary 表:
+----+------+-----+--------+
| id | name | sex | salary |
+----+------+-----+--------+
| 1 | A | m | 2500 |
| 2 | B | f | 1500 |
| 3 | C | m | 5500 |
| 4 | D | f | 500 |
+----+------+-----+--------+
输出:
+----+------+-----+--------+
| id | name | sex | salary |
+----+------+-----+--------+
| 1 | A | f | 2500 |
| 2 | B | m | 1500 |
| 3 | C | f | 5500 |
| 4 | D | m | 500 |
+----+------+-----+--------+
解释:
(1, A) 和 (3, C) 从 'm' 变为 'f' 。
(2, B) 和 (4, D) 从 'f' 变为 'm' 。
解题方式:
update Salary
set sex = if(sex='m','f','m') #类似于java中的三元运算
力扣:1050 合作过至少三次的演员和导演
ActorDirector 表:
±------------±--------+
| Column Name | Type |
±------------±--------+
| actor_id | int |
| director_id | int |
| timestamp | int |
±------------±--------+
timestamp 是这张表的主键.写一条SQL查询语句获取合作过至少三次的演员和导演的 id 对 (actor_id, director_id)
示例:
ActorDirector 表:
+-------------+-------------+-------------+
| actor_id | director_id | timestamp |
+-------------+-------------+-------------+
| 1 | 1 | 0 |
| 1 | 1 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 1 | 2 | 4 |
| 2 | 1 | 5 |
| 2 | 1 | 6 |
+-------------+-------------+-------------+
Result 表:
+-------------+-------------+
| actor_id | director_id |
+-------------+-------------+
| 1 | 1 |
+-------------+-------------+
唯一的 id 对是 (1, 1),他们恰好合作了 3 次。
解题方式:
# Write your MySQL query statement below
select actor_id,director_id
from ActorDirector
group by actor_id,director_id
having count(director_id)>=3
力扣:1084 销售分析III
Table: Product
±-------------±--------+
| Column Name | Type |
±-------------±--------+
| product_id | int |
| product_name | varchar |
| unit_price | int |
±-------------±--------+
Product_id是该表的主键。
该表的每一行显示每个产品的名称和价格。
Table: Sales±------------±--------+
| Column Name | Type |
±------------±--------+
| seller_id | int |
| product_id | int |
| buyer_id | int |
| sale_date | date |
| quantity | int |
| price | int |
±----- ------±--------+
这个表没有主键,它可以有重复的行。
product_id 是 Product 表的外键。
该表的每一行包含关于一个销售的一些信息。编写一个SQL查询,报告2019年春季才售出的产品。即仅在2019-01-01至2019-03-31(含)之间出售的商品。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入:
Product table:
+------------+--------------+------------+
| product_id | product_name | unit_price |
+------------+--------------+------------+
| 1 | S8 | 1000 |
| 2 | G4 | 800 |
| 3 | iPhone | 1400 |
+------------+--------------+------------+
Sales table:
+-----------+------------+----------+------------+----------+-------+
| seller_id | product_id | buyer_id | sale_date | quantity | price |
+-----------+------------+----------+------------+----------+-------+
| 1 | 1 | 1 | 2019-01-21 | 2 | 2000 |
| 1 | 2 | 2 | 2019-02-17 | 1 | 800 |
| 2 | 2 | 3 | 2019-06-02 | 1 | 800 |
| 3 | 3 | 4 | 2019-05-13 | 2 | 2800 |
+-----------+------------+----------+------------+----------+-------+
输出:
+-------------+--------------+
| product_id | product_name |
+-------------+--------------+
| 1 | S8 |
+-------------+--------------+
解释:
id为1的产品仅在2019年春季销售。
id为2的产品在2019年春季销售,但也在2019年春季之后销售。
id 3的产品在2019年春季之后销售。
我们只退回产品1,因为它是2019年春季才销售的产品。
解题方式:
# Write your MySQL query statement below
select p.product_id ,product_name
from Product p,Sales s
where p.product_id = s.product_id
and sale_date between '2019-01-01 00:00:00' and '2019-03-31 23:59:59'
and p.product_id not in (
select product_id
from Sales
where sale_date not between '2019-01-01 00:00:00' and '2019-03-31 23:59:59')
group by p.product_id
力扣:1141 查询近30天活跃用户数
活动记录表:Activity
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| user_id | int |
| session_id | int |
| activity_date | date |
| activity_type | enum |
±--------------±--------+
该表是用户在社交网站的活动记录。
该表没有主键,可能包含重复数据。
activity_type 字段为以下四种值 (‘open_session’, ‘end_session’, ‘scroll_down’, ‘send_message’)。
每个 session_id 只属于一个用户。请写SQL查询出截至 2019-07-27(包含2019-07-27),近 30 天的每日活跃用户数(当天只要有一条活动记录,即为活跃用户)。
以 任意顺序 返回结果表。
查询结果示例如下。
示例 1:
输入:
Activity table:
+---------+------------+---------------+---------------+
| user_id | session_id | activity_date | activity_type |
+---------+------------+---------------+---------------+
| 1 | 1 | 2019-07-20 | open_session |
| 1 | 1 | 2019-07-20 | scroll_down |
| 1 | 1 | 2019-07-20 | end_session |
| 2 | 4 | 2019-07-20 | open_session |
| 2 | 4 | 2019-07-21 | send_message |
| 2 | 4 | 2019-07-21 | end_session |
| 3 | 2 | 2019-07-21 | open_session |
| 3 | 2 | 2019-07-21 | send_message |
| 3 | 2 | 2019-07-21 | end_session |
| 4 | 3 | 2019-06-25 | open_session |
| 4 | 3 | 2019-06-25 | end_session |
+---------+------------+---------------+---------------+
输出:
+------------+--------------+
| day | active_users |
+------------+--------------+
| 2019-07-20 | 2 |
| 2019-07-21 | 2 |
+------------+--------------+
解释:注意非活跃用户的记录不需要展示。
解题方式:
# Write your MySQL query statement below
select activity_date day,count(distinct user_id) active_users
from activity
where activity_date between '2019-06-28' and '2019-07-27'
group by activity_date
力扣:1148 文章浏览 I
表:
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| article_id | int |
| author_id | int |
| viewer_id | int |
| view_date | date |
±--------------±--------+
此表无主键,因此可能会存在重复行。
此表的每一行都表示某人在某天浏览了某位作者的某篇文章。
请注意,同一人的 author_id 和 viewer_id 是相同的。请编写一条 SQL 查询以找出所有浏览过自己文章的作者,结果按照 id 升序排列。
查询结果的格式如下所示:
Views 表:
+------------+-----------+-----------+------------+
| article_id | author_id | viewer_id | view_date |
+------------+-----------+-----------+------------+
| 1 | 3 | 5 | 2019-08-01 |
| 1 | 3 | 6 | 2019-08-02 |
| 2 | 7 | 7 | 2019-08-01 |
| 2 | 7 | 6 | 2019-08-02 |
| 4 | 7 | 1 | 2019-07-22 |
| 3 | 4 | 4 | 2019-07-21 |
| 3 | 4 | 4 | 2019-07-21 |
+------------+-----------+-----------+------------+
结果表:
+------+
| id |
+------+
| 4 |
| 7 |
+------+
解题方式:
# Write your MySQL query statement below
select distinct(author_id) as id
from Views
where author_id = viewer_id
order by author_id
力扣:1407 排名靠前的旅行者
表:Users
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| id | int |
| name | varchar |
±--------------±--------+
id 是该表单主键。
name 是用户名字。表:Rides
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| id | int |
| user_id | int |
| distance | int |
±--------------±--------+
id 是该表单主键。
user_id 是本次行程的用户的 id, 而该用户此次行程距离为 distance 。写一段 SQL , 报告每个用户的旅行距离。
返回的结果表单,以 travelled_distance 降序排列 ,如果有两个或者更多的用户旅行了相同的距离, 那么再以 name 升序排列 。
查询结果格式如下例所示。
Users 表:
+------+-----------+
| id | name |
+------+-----------+
| 1 | Alice |
| 2 | Bob |
| 3 | Alex |
| 4 | Donald |
| 7 | Lee |
| 13 | Jonathan |
| 19 | Elvis |
+------+-----------+
Rides 表:
+------+----------+----------+
| id | user_id | distance |
+------+----------+----------+
| 1 | 1 | 120 |
| 2 | 2 | 317 |
| 3 | 3 | 222 |
| 4 | 7 | 100 |
| 5 | 13 | 312 |
| 6 | 19 | 50 |
| 7 | 7 | 120 |
| 8 | 19 | 400 |
| 9 | 7 | 230 |
+------+----------+----------+
Result 表:
+----------+--------------------+
| name | travelled_distance |
+----------+--------------------+
| Elvis | 450 |
| Lee | 450 |
| Bob | 317 |
| Jonathan | 312 |
| Alex | 222 |
| Alice | 120 |
| Donald | 0 |
+----------+--------------------+
Elvis 和 Lee 旅行了 450 英里,Elvis 是排名靠前的旅行者,因为他的名字在字母表上的排序比 Lee 更小。
Bob, Jonathan, Alex 和 Alice 只有一次行程,我们只按此次行程的全部距离对他们排序。
Donald 没有任何行程, 他的旅行距离为 0。
解题方式:
# Write your MySQL query statement below
select name,ifnull(sum(distance),0) travelled_distance
from Users
left join Rides on Users.id = Rides.user_id
group by Users.id
order by travelled_distance desc,name asc
力扣:1471查找每个员工花费的总时间
表: Employees
±------------±-----+
| Column Name | Type |
±------------±-----+
| emp_id | int |
| event_day | date |
| in_time | int |
| out_time | int |
±------------±-----+
(emp_id, event_day, in_time) 是这个表的主键。
该表显示了员工在办公室的出入情况。
event_day 是此事件发生的日期,in_time 是员工进入办公室的时间,而 out_time 是他们离开办公室的时间。
in_time 和 out_time 的取值在1到1440之间。
题目保证同一天没有两个事件在时间上是相交的,并且保证 in_time 小于 out_time。编写一个SQL查询以计算每位员工每天在办公室花费的总时间(以分钟为单位)。 请注意,在一天之内,同一员工是可以多次进入和离开办公室的。 在办公室里一次进出所花费的时间为out_time 减去 in_time。
返回结果表单的顺序无要求。
查询结果的格式如下:
Employees table:
+--------+------------+---------+----------+
| emp_id | event_day | in_time | out_time |
+--------+------------+---------+----------+
| 1 | 2020-11-28 | 4 | 32 |
| 1 | 2020-11-28 | 55 | 200 |
| 1 | 2020-12-03 | 1 | 42 |
| 2 | 2020-11-28 | 3 | 33 |
| 2 | 2020-12-09 | 47 | 74 |
+--------+------------+---------+----------+
Result table:
+------------+--------+------------+
| day | emp_id | total_time |
+------------+--------+------------+
| 2020-11-28 | 1 | 173 |
| 2020-11-28 | 2 | 30 |
| 2020-12-03 | 1 | 41 |
| 2020-12-09 | 2 | 27 |
+------------+--------+------------+
雇员 1 有三次进出: 有两次发生在 2020-11-28 花费的时间为 (32 - 4) + (200 - 55) = 173, 有一次发生在 2020-12-03 花费的时间为 (42 - 1) = 41。
雇员 2 有两次进出: 有一次发生在 2020-11-28 花费的时间为 (33 - 3) = 30, 有一次发生在 2020-12-09 花费的时间为 (74 - 47) = 27。
解题方式:
# Write your MySQL query statement below
select event_day day,emp_id,sum(out_time-in_time) as total_time
from employees
group by event_day,emp_id
力扣:1484 按日期分组销售产品
表 Activities:
±------------±--------+
| 列名 | 类型 |
±------------±--------+
| sell_date | date |
| product | varchar |
±------------±--------+
此表没有主键,它可能包含重复项。
此表的每一行都包含产品名称和在市场上销售的日期。编写一个 SQL 查询来查找每个日期、销售的不同产品的数量及其名称。
每个日期的销售产品名称应按词典序排列。
返回按 sell_date 排序的结果表。
查询结果格式如下例所示。
示例 1:
输入:
Activities 表:
+------------+-------------+
| sell_date | product |
+------------+-------------+
| 2020-05-30 | Headphone |
| 2020-06-01 | Pencil |
| 2020-06-02 | Mask |
| 2020-05-30 | Basketball |
| 2020-06-01 | Bible |
| 2020-06-02 | Mask |
| 2020-05-30 | T-Shirt |
+------------+-------------+
输出:
+------------+----------+------------------------------+
| sell_date | num_sold | products |
+------------+----------+------------------------------+
| 2020-05-30 | 3 | Basketball,Headphone,T-shirt |
| 2020-06-01 | 2 | Bible,Pencil |
| 2020-06-02 | 1 | Mask |
+------------+----------+------------------------------+
解释:
对于2020-05-30,出售的物品是 (Headphone, Basketball, T-shirt),按词典序排列,并用逗号 ',' 分隔。
对于2020-06-01,出售的物品是 (Pencil, Bible),按词典序排列,并用逗号分隔。
对于2020-06-02,出售的物品是 (Mask),只需返回该物品名。
解题方式:
#使用group_concat
select sell_date,count(distinct product) num_sold,group_concat(distinct product order by product separator ',') products
from Activities
group by sell_date
力扣:1527 患某种疾病的患者
患者信息表: Patients
±-------------±--------+
| Column Name | Type |
±-------------±--------+
| patient_id | int |
| patient_name | varchar |
| conditions | varchar |
±-------------±--------+
patient_id (患者 ID)是该表的主键。
‘conditions’ (疾病)包含 0 个或以上的疾病代码,以空格分隔。
这个表包含医院中患者的信息。写一条 SQL 语句,查询患有 I 类糖尿病的患者 ID (patient_id)、患者姓名(patient_name)以及其患有的所有疾病代码(conditions)。I 类糖尿病的代码总是包含前缀 DIAB1 。
按 任意顺序 返回结果表。
查询结果格式如下示例所示。
示例 1:
输入:
Patients表:
+------------+--------------+--------------+
| patient_id | patient_name | conditions |
+------------+--------------+--------------+
| 1 | Daniel | YFEV COUGH |
| 2 | Alice | |
| 3 | Bob | DIAB100 MYOP |
| 4 | George | ACNE DIAB100 |
| 5 | Alain | DIAB201 |
+------------+--------------+--------------+
输出:
+------------+--------------+--------------+
| patient_id | patient_name | conditions |
+------------+--------------+--------------+
| 3 | Bob | DIAB100 MYOP |
| 4 | George | ACNE DIAB100 |
+------------+--------------+--------------+
解释:Bob 和 George 都患有代码以 DIAB1 开头的疾病。
解题方式:
select patient_id,patient_name,conditions
from Patients
where conditions like 'DIAB1%' or conditions like '% DIAB1%'
力扣:1581 进店却未进行过交易的顾客
表:Visits
±------------±--------+
| Column Name | Type |
±------------±--------+
| visit_id | int |
| customer_id | int |
±------------±--------+
visit_id 是该表的主键。
该表包含有关光临过购物中心的顾客的信息。表:Transactions
±---------------±--------+
| Column Name | Type |
±---------------±--------+
| transaction_id | int |
| visit_id | int |
| amount | int |
±---------------±--------+
transaction_id 是此表的主键。
此表包含 visit_id 期间进行的交易的信息。有一些顾客可能光顾了购物中心但没有进行交易。请你编写一个 SQL 查询,来查找这些顾客的 ID ,以及他们只光顾不交易的次数。
返回以 任何顺序 排序的结果表。
查询结果格式如下例所示。
示例 1:
输入:
Visits
+----------+-------------+
| visit_id | customer_id |
+----------+-------------+
| 1 | 23 |
| 2 | 9 |
| 4 | 30 |
| 5 | 54 |
| 6 | 96 |
| 7 | 54 |
| 8 | 54 |
+----------+-------------+
Transactions
+----------------+----------+--------+
| transaction_id | visit_id | amount |
+----------------+----------+--------+
| 2 | 5 | 310 |
| 3 | 5 | 300 |
| 9 | 5 | 200 |
| 12 | 1 | 910 |
| 13 | 2 | 970 |
+----------------+----------+--------+
输出:
+-------------+----------------+
| customer_id | count_no_trans |
+-------------+----------------+
| 54 | 2 |
| 30 | 1 |
| 96 | 1 |
+-------------+----------------+
解释:
ID = 23 的顾客曾经逛过一次购物中心,并在 ID = 12 的访问期间进行了一笔交易。
ID = 9 的顾客曾经逛过一次购物中心,并在 ID = 13 的访问期间进行了一笔交易。
ID = 30 的顾客曾经去过购物中心,并且没有进行任何交易。
ID = 54 的顾客三度造访了购物中心。在 2 次访问中,他们没有进行任何交易,在 1 次访问中,他们进行了 3 次交易。
ID = 96 的顾客曾经去过购物中心,并且没有进行任何交易。
如我们所见,ID 为 30 和 96 的顾客一次没有进行任何交易就去了购物中心。顾客 54 也两次访问了购物中心并且没有进行任何交易。
解题方式:
# Write your MySQL query statement below
#先查询出进商场后没有消费过的用户id(进一次算一次),再根据用户id去查询没消费的次数
select customer_id,count(customer_id) as count_no_trans
from Visits
where Visits.visit_id not in (
select distinct(v.visit_id)
from Visits v,Transactions t
where v.visit_id = t.visit_id
)
group by customer_id
力扣:1587 银行账户概要 II
表: Users
±-------------±--------+
| Column Name | Type |
±-------------±--------+
| account | int |
| name | varchar |
±-------------±--------+
account 是该表的主键.
表中的每一行包含银行里中每一个用户的账号.表: Transactions
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| trans_id | int |
| account | int |
| amount | int |
| transacted_on | date |
±--------------±--------+
trans_id 是该表主键.
该表的每一行包含了所有账户的交易改变情况.
如果用户收到了钱, 那么金额是正的; 如果用户转了钱, 那么金额是负的.
所有账户的起始余额为 0.写一个 SQL, 报告余额高于 10000 的所有用户的名字和余额. 账户的余额等于包含该账户的所有交易的总和.
返回结果表单没有顺序要求.
查询结果格式如下例所示.
Users table:
+------------+--------------+
| account | name |
+------------+--------------+
| 900001 | Alice |
| 900002 | Bob |
| 900003 | Charlie |
+------------+--------------+
Transactions table:
+------------+------------+------------+---------------+
| trans_id | account | amount | transacted_on |
+------------+------------+------------+---------------+
| 1 | 900001 | 7000 | 2020-08-01 |
| 2 | 900001 | 7000 | 2020-09-01 |
| 3 | 900001 | -3000 | 2020-09-02 |
| 4 | 900002 | 1000 | 2020-09-12 |
| 5 | 900003 | 6000 | 2020-08-07 |
| 6 | 900003 | 6000 | 2020-09-07 |
| 7 | 900003 | -4000 | 2020-09-11 |
+------------+------------+------------+---------------+
Result table:
+------------+------------+
| name | balance |
+------------+------------+
| Alice | 11000 |
+------------+------------+
Alice 的余额为(7000 + 7000 - 3000) = 11000.
Bob 的余额为1000.
Charlie 的余额为(6000 + 6000 - 4000) = 8000.
解题方式:
# Write your MySQL query statement below
select name,sum(amount) balance
from Users u,Transactions t
where u.account = t.account
group by u.account
having balance>10000
力扣:1667 修复表中的名字
表: Users
±---------------±--------+
| Column Name | Type |
±---------------±--------+
| user_id | int |
| name | varchar |
±---------------±--------+
user_id 是该表的主键。
该表包含用户的 ID 和名字。名字仅由小写和大写字符组成。编写一个 SQL 查询来修复名字,使得只有第一个字符是大写的,其余都是小写的。
返回按 user_id 排序的结果表。
查询结果格式示例如下。
示例 1:
输入:
Users table:
+---------+-------+
| user_id | name |
+---------+-------+
| 1 | aLice |
| 2 | bOB |
+---------+-------+
输出:
+---------+-------+
| user_id | name |
+---------+-------+
| 1 | Alice |
| 2 | Bob |
+---------+-------+
解题方式:
select user_id,concat(upper(left(name,1)),lower(right(name,length(name) -1))) name
from Users
order by user_id
力扣:1693 每天的领导和合伙人
表:DailySales
±------------±--------+
| Column Name | Type |
±------------±--------+
| date_id | date |
| make_name | varchar |
| lead_id | int |
| partner_id | int |
±------------±--------+
该表没有主键。
该表包含日期、产品的名称,以及售给的领导和合伙人的编号。
名称只包含小写英文字母。写一条 SQL 语句,使得对于每一个 date_id 和 make_name,返回不同的 lead_id 以及不同的 partner_id 的数量。
按 任意顺序 返回结果表。
查询结果格式如下示例所示。
示例 1:
输入:
DailySales 表:
+-----------+-----------+---------+------------+
| date_id | make_name | lead_id | partner_id |
+-----------+-----------+---------+------------+
| 2020-12-8 | toyota | 0 | 1 |
| 2020-12-8 | toyota | 1 | 0 |
| 2020-12-8 | toyota | 1 | 2 |
| 2020-12-7 | toyota | 0 | 2 |
| 2020-12-7 | toyota | 0 | 1 |
| 2020-12-8 | honda | 1 | 2 |
| 2020-12-8 | honda | 2 | 1 |
| 2020-12-7 | honda | 0 | 1 |
| 2020-12-7 | honda | 1 | 2 |
| 2020-12-7 | honda | 2 | 1 |
+-----------+-----------+---------+------------+
输出:
+-----------+-----------+--------------+-----------------+
| date_id | make_name | unique_leads | unique_partners |
+-----------+-----------+--------------+-----------------+
| 2020-12-8 | toyota | 2 | 3 |
| 2020-12-7 | toyota | 1 | 2 |
| 2020-12-8 | honda | 2 | 2 |
| 2020-12-7 | honda | 3 | 2 |
+-----------+-----------+--------------+-----------------+
解释:
在 2020-12-8,丰田(toyota)有领导者 = [0, 1] 和合伙人 = [0, 1, 2] ,同时本田(honda)有领导者 = [1, 2] 和合伙人 = [1, 2]。
在 2020-12-7,丰田(toyota)有领导者 = [0] 和合伙人 = [1, 2] ,同时本田(honda)有领导者 = [0, 1, 2] 和合伙人 = [1, 2]。
解题方式:
# Write your MySQL query statement below
select date_id,make_name,count(distinct(lead_id)) unique_leads,count(distinct(partner_id)) unique_partners
from DailySales
group by make_name,date_id
力扣:1729 求关注者的数量
表: Followers
±------------±-----+
| Column Name | Type |
±------------±-----+
| user_id | int |
| follower_id | int |
±------------±-----+
(user_id, follower_id) 是这个表的主键。
该表包含一个关注关系中关注者和用户的编号,其中关注者关注用户。写出 SQL 语句,对于每一个用户,返回该用户的关注者数量。
按 user_id 的顺序返回结果表。
查询结果的格式如下示例所示。
示例 1:
输入:
Followers 表:
+---------+-------------+
| user_id | follower_id |
+---------+-------------+
| 0 | 1 |
| 1 | 0 |
| 2 | 0 |
| 2 | 1 |
+---------+-------------+
输出:
+---------+----------------+
| user_id | followers_count|
+---------+----------------+
| 0 | 1 |
| 1 | 1 |
| 2 | 2 |
+---------+----------------+
解释:
0 的关注者有 {1}
1 的关注者有 {0}
2 的关注者有 {0,1}
解题方式:
# Write your MySQL query statement below
select user_id,count(follower_id) followers_count
from Followers
group by user_id
order by user_id
力扣:1757 可回收且低脂的产品
表:Products
±------------±--------+
| Column Name | Type |
±------------±--------+
| product_id | int |
| low_fats | enum |
| recyclable | enum |
±------------±--------+
product_id 是这个表的主键。
low_fats 是枚举类型,取值为以下两种 (‘Y’, ‘N’),其中 ‘Y’ 表示该产品是低脂产品,‘N’ 表示不是低脂产品。
recyclable 是枚举类型,取值为以下两种 (‘Y’, ‘N’),其中 ‘Y’ 表示该产品可回收,而 ‘N’ 表示不可回收。写出 SQL 语句,查找既是低脂又是可回收的产品编号。
返回结果 无顺序要求 。
查询结果格式如下例所示:
Products 表:
+-------------+----------+------------+
| product_id | low_fats | recyclable |
+-------------+----------+------------+
| 0 | Y | N |
| 1 | Y | Y |
| 2 | N | Y |
| 3 | Y | Y |
| 4 | N | N |
+-------------+----------+------------+
Result 表:
+-------------+
| product_id |
+-------------+
| 1 |
| 3 |
+-------------+
只有产品 id 为 1 和 3 的产品,既是低脂又是可回收的产品。
解题方式:
select product_id
from Products
where low_fats = 'Y' and recyclable = 'Y'
力扣:1795 每个产品在不同商店的价格
表:Products
±------------±--------+
| Column Name | Type |
±------------±--------+
| product_id | int |
| store1 | int |
| store2 | int |
| store3 | int |
±------------±--------+
这张表的主键是product_id(产品Id)。
每行存储了这一产品在不同商店store1, store2, store3的价格。
如果这一产品在商店里没有出售,则值将为null。请你重构 Products 表,查询每个产品在不同商店的价格,使得输出的格式变为(product_id, store, price) 。如果这一产品在商店里没有出售,则不输出这一行。
输出结果表中的 顺序不作要求 。
查询输出格式请参考下面示例。
示例 1:
输入:
Products table:
+------------+--------+--------+--------+
| product_id | store1 | store2 | store3 |
+------------+--------+--------+--------+
| 0 | 95 | 100 | 105 |
| 1 | 70 | null | 80 |
+------------+--------+--------+--------+
输出:
+------------+--------+-------+
| product_id | store | price |
+------------+--------+-------+
| 0 | store1 | 95 |
| 0 | store2 | 100 |
| 0 | store3 | 105 |
| 1 | store1 | 70 |
| 1 | store3 | 80 |
+------------+--------+-------+
解释:
产品0在store1,store2,store3的价格分别为95,100,105。
产品1在store1,store3的价格分别为70,80。在store2无法买到。
解题方式:
# Write your MySQL query statement below
#列转行union all, 行转列 case when
select product_id, 'store1' as store, store1 as price
from products
where store1 is not null
union all
select product_id, 'store2' as store, store2 as price
from products
where store2 is not null
union all
select product_id, 'store3' as store, store3 as price
from products
where store3 is not null
力扣:1837 计算特殊奖金
表: Employees
±------------±--------+
| 列名 | 类型 |
±------------±--------+
| employee_id | int |
| name | varchar |
| salary | int |
±------------±--------+
employee_id 是这个表的主键。
此表的每一行给出了雇员id ,名字和薪水。写出一个SQL 查询语句,计算每个雇员的奖金。如果一个雇员的id是奇数并且他的名字不是以’M’开头,那么他的奖金是他工资的100%,否则奖金为0。
Return the result table ordered by employee_id.
返回的结果集请按照employee_id排序。
查询结果格式如下面的例子所示。
示例 1:
输入:
Employees 表:
+-------------+---------+--------+
| employee_id | name | salary |
+-------------+---------+--------+
| 2 | Meir | 3000 |
| 3 | Michael | 3800 |
| 7 | Addilyn | 7400 |
| 8 | Juan | 6100 |
| 9 | Kannon | 7700 |
+-------------+---------+--------+
输出:
+-------------+-------+
| employee_id | bonus |
+-------------+-------+
| 2 | 0 |
| 3 | 0 |
| 7 | 7400 |
| 8 | 0 |
| 9 | 7700 |
+-------------+-------+
解释:
因为雇员id是偶数,所以雇员id 是2和8的两个雇员得到的奖金是0。
雇员id为3的因为他的名字以'M'开头,所以,奖金是0。
其他的雇员得到了百分之百的奖金。
解题方式:
select employee_id,salary*(employee_id%2) bonus
from Employees
where name not like 'M%'
union
select employee_id,salary*0 bonus
from Employees
where name like 'M%'
order by employee_id
力扣:1890 2020年最后一次登录
表: Logins
±---------------±---------+
| 列名 | 类型 |
±---------------±---------+
| user_id | int |
| time_stamp | datetime |
±---------------±---------+
(user_id, time_stamp) 是这个表的主键。
每一行包含的信息是user_id 这个用户的登录时间。编写一个 SQL 查询,该查询可以获取在 2020 年登录过的所有用户的本年度 最后一次 登录时间。结果集 不 包含 2020 年没有登录过的用户。
返回的结果集可以按 任意顺序 排列。
查询结果格式如下例。
示例 1:
输入:
Logins 表:
+---------+---------------------+
| user_id | time_stamp |
+---------+---------------------+
| 6 | 2020-06-30 15:06:07 |
| 6 | 2021-04-21 14:06:06 |
| 6 | 2019-03-07 00:18:15 |
| 8 | 2020-02-01 05:10:53 |
| 8 | 2020-12-30 00:46:50 |
| 2 | 2020-01-16 02:49:50 |
| 2 | 2019-08-25 07:59:08 |
| 14 | 2019-07-14 09:00:00 |
| 14 | 2021-01-06 11:59:59 |
+---------+---------------------+
输出:
+---------+---------------------+
| user_id | last_stamp |
+---------+---------------------+
| 6 | 2020-06-30 15:06:07 |
| 8 | 2020-12-30 00:46:50 |
| 2 | 2020-01-16 02:49:50 |
+---------+---------------------+
解释:
6号用户登录了3次,但是在2020年仅有一次,所以结果集应包含此次登录。
8号用户在2020年登录了2次,一次在2月,一次在12月,所以,结果集应该包含12月的这次登录。
2号用户登录了2次,但是在2020年仅有一次,所以结果集应包含此次登录。
14号用户在2020年没有登录,所以结果集不应包含。
解题方式:
# Write your MySQL query statement below
select user_id ,max(time_stamp) last_stamp
from Logins
where time_stamp between '2020-1-1 00:00:00' and '2020-12-31 23:59:59'
group by user_id
力扣:1965 丢失信息的雇员
表: Employees
±------------±--------+
| Column Name | Type |
±------------±--------+
| employee_id | int |
| name | varchar |
±------------±--------+
employee_id 是这个表的主键。
每一行表示雇员的id 和他的姓名。
表: Salaries±------------±--------+
| Column Name | Type |
±------------±--------+
| employee_id | int |
| salary | int |
±------------±--------+
employee_id is 这个表的主键。
每一行表示雇员的id 和他的薪水。写出一个查询语句,找到所有 丢失信息 的雇员id。当满足下面一个条件时,就被认为是雇员的信息丢失:
雇员的 姓名 丢失了,或者
雇员的 薪水信息 丢失了,或者
返回这些雇员的id employee_id , 从小到大排序 。
查询结果格式如下面的例子所示。
示例 1:
输入:
Employees table:
+-------------+----------+
| employee_id | name |
+-------------+----------+
| 2 | Crew |
| 4 | Haven |
| 5 | Kristian |
+-------------+----------+
Salaries table:
+-------------+--------+
| employee_id | salary |
+-------------+--------+
| 5 | 76071 |
| 1 | 22517 |
| 4 | 63539 |
+-------------+--------+
输出:
+-------------+
| employee_id |
+-------------+
| 1 |
| 2 |
+-------------+
解释:
雇员1,2,4,5 都工作在这个公司。
1号雇员的姓名丢失了。
2号雇员的薪水信息丢失了。
解题方式:
# Write your MySQL query statement below
select distinct(t.employee_id)
from
(
select employee_id from Employees
union
select employee_id from Salaries
) as t
left join
(select Employees.employee_id,Salaries.salary
from Employees,Salaries
where Employees.employee_id = Salaries.employee_id
) as s
on t.employee_id=s.employee_id
where s.salary is null
order by t.employee_id
中等
力扣:176 第二高的薪水
Employee 表:
±------------±-----+
| Column Name | Type |
±------------±-----+
| id | int |
| salary | int |
±------------±-----+
id 是这个表的主键。
表的每一行包含员工的工资信息。编写一个 SQL 查询,获取并返回 Employee 表中第二高的薪水 。如果不存在第二高的薪水,查询应该返回 null 。
查询结果如下例所示。
示例 1:
输入:
Employee 表:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
输出:
+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+
示例 2:
输入:
Employee 表:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
+----+--------+
输出:
+---------------------+
| SecondHighestSalary |
+---------------------+
| null |
+---------------------+
解题方式:
# Write your MySQL query statement below
select ifNULL((
select distinct(salary) as SecondHighestSalary
from Employee
order by salary desc
limit 1,1),null) as SecondHighestSalary
力扣:608 树节点
给定一个表 tree,id 是树节点的编号, p_id 是它父节点的 id 。
±—±-----+
| id | p_id |
±—±-----+
| 1 | null |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
±—±-----+
树中每个节点属于以下三种类型之一:叶子:如果这个节点没有任何孩子节点。
根:如果这个节点是整棵树的根,即没有父节点。
内部节点:如果这个节点既不是叶子节点也不是根节点。
写一个查询语句,输出所有节点的编号和节点的类型,并将结果按照节点编号排序。上面样例的结果为:
±—±-----+
| id | Type |
±—±-----+
| 1 | Root |
| 2 | Inner|
| 3 | Leaf |
| 4 | Leaf |
| 5 | Leaf |
±—±-----+
解释
节点 ‘1’ 是根节点,因为它的父节点是 NULL ,同时它有孩子节点 ‘2’ 和 ‘3’ 。
节点 ‘2’ 是内部节点,因为它有父节点 ‘1’ ,也有孩子节点 ‘4’ 和 ‘5’ 。
节点 ‘3’, ‘4’ 和 ‘5’ 都是叶子节点,因为它们都有父节点同时没有孩子节点。
样例中树的形态如下:
1
/ \
2 3
/ \
4 5
解题方式:
# Write your MySQL query statement below
select id,
case
when p_id is null then "Root"
when id in (select p_id from tree) then "Inner"
else "Leaf"
end as Type
from tree
力扣:1158 市场分析 I
Table: Users
±---------------±--------+
| Column Name | Type |
±---------------±--------+
| user_id | int |
| join_date | date |
| favorite_brand | varchar |
±---------------±--------+
此表主键是 user_id。
表中描述了购物网站的用户信息,用户可以在此网站上进行商品买卖。Table: Orders
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| order_id | int |
| order_date | date |
| item_id | int |
| buyer_id | int |
| seller_id | int |
±--------------±--------+
此表主键是 order_id。
外键是 item_id 和(buyer_id,seller_id)。Table: Items
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| item_id | int |
| item_brand | varchar |
±--------------±--------+
此表主键是 item_id。请写出一条SQL语句以查询每个用户的注册日期和在 2019 年作为买家的订单总数。
以 任意顺序 返回结果表。
查询结果格式如下。
示例 1:
输入:
Users 表:
+---------+------------+----------------+
| user_id | join_date | favorite_brand |
+---------+------------+----------------+
| 1 | 2018-01-01 | Lenovo |
| 2 | 2018-02-09 | Samsung |
| 3 | 2018-01-19 | LG |
| 4 | 2018-05-21 | HP |
+---------+------------+----------------+
Orders 表:
+----------+------------+---------+----------+-----------+
| order_id | order_date | item_id | buyer_id | seller_id |
+----------+------------+---------+----------+-----------+
| 1 | 2019-08-01 | 4 | 1 | 2 |
| 2 | 2018-08-02 | 2 | 1 | 3 |
| 3 | 2019-08-03 | 3 | 2 | 3 |
| 4 | 2018-08-04 | 1 | 4 | 2 |
| 5 | 2018-08-04 | 1 | 3 | 4 |
| 6 | 2019-08-05 | 2 | 2 | 4 |
+----------+------------+---------+----------+-----------+
Items 表:
+---------+------------+
| item_id | item_brand |
+---------+------------+
| 1 | Samsung |
| 2 | Lenovo |
| 3 | LG |
| 4 | HP |
+---------+------------+
输出:
+-----------+------------+----------------+
| buyer_id | join_date | orders_in_2019 |
+-----------+------------+----------------+
| 1 | 2018-01-01 | 1 |
| 2 | 2018-02-09 | 2 |
| 3 | 2018-01-19 | 0 |
| 4 | 2018-05-21 | 0 |
+-----------+------------+----------------+
解题方式:
# Write your MySQL query statement below
select user_id buyer_id, join_date,count(order_id) orders_in_2019
from Users u
left join Orders o
on o.buyer_id = u.user_id and o.order_date between '2019-1-1 00:00:00' and '2019-12-31 23:59:59'
group by u.user_id
order by u.user_id asc
力扣:1893 股票的资本损益
Stocks 表:
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| stock_name | varchar |
| operation | enum |
| operation_day | int |
| price | int |
±--------------±--------+
(stock_name, day) 是这张表的主键
operation 列使用的是一种枚举类型,包括:(‘Sell’,‘Buy’)
此表的每一行代表了名为 stock_name 的某支股票在 operation_day 这一天的操作价格。
保证股票的每次’Sell’操作前,都有相应的’Buy’操作。编写一个SQL查询来报告每支股票的资本损益。
股票的资本损益是一次或多次买卖股票后的全部收益或损失。
以任意顺序返回结果即可。
SQL查询结果的格式如下例所示:
Stocks 表:
+---------------+-----------+---------------+--------+
| stock_name | operation | operation_day | price |
+---------------+-----------+---------------+--------+
| Leetcode | Buy | 1 | 1000 |
| Corona Masks | Buy | 2 | 10 |
| Leetcode | Sell | 5 | 9000 |
| Handbags | Buy | 17 | 30000 |
| Corona Masks | Sell | 3 | 1010 |
| Corona Masks | Buy | 4 | 1000 |
| Corona Masks | Sell | 5 | 500 |
| Corona Masks | Buy | 6 | 1000 |
| Handbags | Sell | 29 | 7000 |
| Corona Masks | Sell | 10 | 10000 |
+---------------+-----------+---------------+--------+
Result 表:
+---------------+-------------------+
| stock_name | capital_gain_loss |
+---------------+-------------------+
| Corona Masks | 9500 |
| Leetcode | 8000 |
| Handbags | -23000 |
+---------------+-------------------+
Leetcode 股票在第一天以1000美元的价格买入,在第五天以9000美元的价格卖出。资本收益=9000-1000=8000美元。
Handbags 股票在第17天以30000美元的价格买入,在第29天以7000美元的价格卖出。资本损失=7000-30000=-23000美元。
Corona Masks 股票在第1天以10美元的价格买入,在第3天以1010美元的价格卖出。在第4天以1000美元的价格再次购买,在第5天以500美元的价格出售。最后,它在第6天以1000美元的价格被买走,在第10天以10000美元的价格被卖掉。资本损益是每次(’Buy'->'Sell')操作资本收益或损失的和=(1010-10)+(500-1000)+(10000-1000)=1000-500+9000=9500美元。
解题方式:
# Write your MySQL query statement below
select stock_name,sum(if(operation="Buy",-price,price)) capital_gain_loss
from stocks
group by stock_name
















 3903
3903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











