







 本文提出了一种基于多智能体强化学习的框架,模拟欺诈者对抗基于图神经网络的假新闻检测器。研究了挑战与限制,定义了GNN节点更新和损失函数,并探讨了不同智能体(机器人、半机器人和众包工作者)的攻击策略及其效果。结果显示,多智能体方法在攻击成功率上优于单智能体,且攻击效果受新闻类型和连接度影响。
本文提出了一种基于多智能体强化学习的框架,模拟欺诈者对抗基于图神经网络的假新闻检测器。研究了挑战与限制,定义了GNN节点更新和损失函数,并探讨了不同智能体(机器人、半机器人和众包工作者)的攻击策略及其效果。结果显示,多智能体方法在攻击成功率上优于单智能体,且攻击效果受新闻类型和连接度影响。
本文介绍了一个新的针对基于图神经网络(GNN)的假新闻检测器的对抗性攻击框架,我们利用多智能体强化学习(MARL)框架来模拟社交媒体上欺诈者的对抗行为。
专业名词解释:
MARL:多智能体强化学习,多个智能体(agents)同时存在,并且它们的决策会相互影响,因为它们共享一个环境并可能有共同的目标。
模拟欺诈者的对抗行为来攻击基于GNN的错误信息检测器有三个挑战:
- 现实中社交媒体推广假新闻,恶意行为者只能操纵受控制的用户账户来分享不同的社交帖子。然而,以往的大多数GNN对抗性攻击工作都假设所有节点和边缘都可以被扰动。
- 许多已部署的基于gnn的假新闻检测器是灰盒模型。具有针对异构用户帖子图定制的各种模型架构。因此,不能基于梯度的优化方法来设计攻击。
- 不同类型的恶意行为者具有不同的能力、预算和风险偏好。例如,关键意见领袖的影响力比社交机器人更大,但培养成本更高。
专业名词解释:
灰盒模型:
- 攻击者可能知道一些关于系统的信息,比如算法的类型、输入输出的格式或者一些系统的特性。
- 但是,他们不知道系统的具体参数和训练数据等详细信息。
- 这种情况在实际中非常常见,因为通常系统的一些信息(比如它是基于哪种已知算法)是公开的,但更具体的信息(比如系统是如何被训练的)不为外人所知
基于梯度的优化方法:基于梯度的攻击通常涉及计算模型预测相对于其输入的微小变化(即梯度),然后根据这些梯度来调整输入以欺骗模型。但是,当模型是为特定类型的图——在这里是异构图——定制的时候,直接计算和应用梯度变得复杂,因为模型的预测可能依赖于图中多个相互关联的节点和边。
为了克服上述挑战,本论文首先定义了基于gnn的假新闻检测以及对抗攻击,然后提出的MARL框架,其中基于gnn的假新闻检测提出了
GNN节点更新:
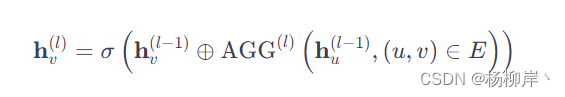
公式解释:

GNN损失函数:
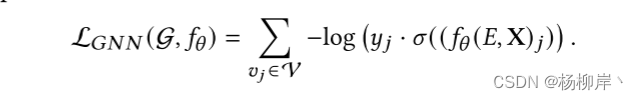
公式解释:

基于gnn的假新闻检测器的对抗性攻击:
定义了一种针对基于GNN的假新闻检测系统的攻击策略。这种策略考虑了真实世界中可能存在的限制,比如攻击者不能删除已有的帖子,只能通过分享新帖子来影响社交网络的结构。
目标是使GNN错误地将某些特定的社交帖子分类(例如,将真实新闻错误分类为假新闻,或相反)。为了实现这一点,攻击者利用一组受控用户(Uc)和他们可以创建的新边(Ea),试图改变GNN对特定新闻帖子集合(VT)的分类结果。
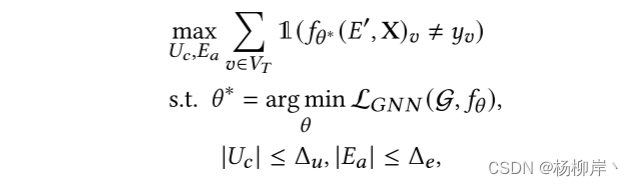
公式解释:

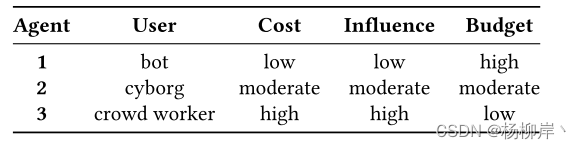
MARL由三个智能体组成,分别为bot, cyborg, and crowd worker agents,三者有不同的的成本、可用预算和影响。
专业名词解释:
机器人(bot):自动化程序或机器人,它们通过预定义的规则、程序或算法执行任务。这些代理通常不具备学习能力,它们的行为是通过编程来确定的,而不是通过学习或适应。
成本:低。机器人通常由自动程序控制,不需要人工操作,因此成本较低。
影响力:低。机器人账户通常没有真实社交网络中的信任和广泛的影响力。
预算:高。由于成本低,机器人可以执行更多的操作,比如自动发布和分享大量帖子。
半机器人用户(cyborg):半机械或半人工智能的实体。在多智能体系统中,它可能指的是一种混合了自动化程序和人工智能元素的实体,具有一些自主决策的能力,同时还能与人工智能系统进行交互。
成本:中等。半机器人是由人类注册并控制的账户,但某些活动可能由自动程序执行,成本适中。
影响力:中等。这些账户可能在人类和自动化之间切换,使它们在社交网络上有一定的可信度和影响力。
预算:中等。半机器人用户的预算适中,意味着它们在行动次数上既不多也不少。
众包工作者(crowd worker):通过在线平台(如众包平台)参与任务的个人。这些个体通常是真实的人类,而不是程序或机器人。他们执行各种任务,从简单的数据标注到复杂的认知任务,作为多智能体系统中的代理,与其他智能体协同工作。
成本:高。众包工作者是通过支付金钱来进行特定活动的真人,因此成本较高。
影响力:高。作为真实的用户,他们能够以更自然和更有信服力的方式进行社交媒体互动。
预算:低。因为成本高,众包工作者的操作次数相对较少。
工作原理图:
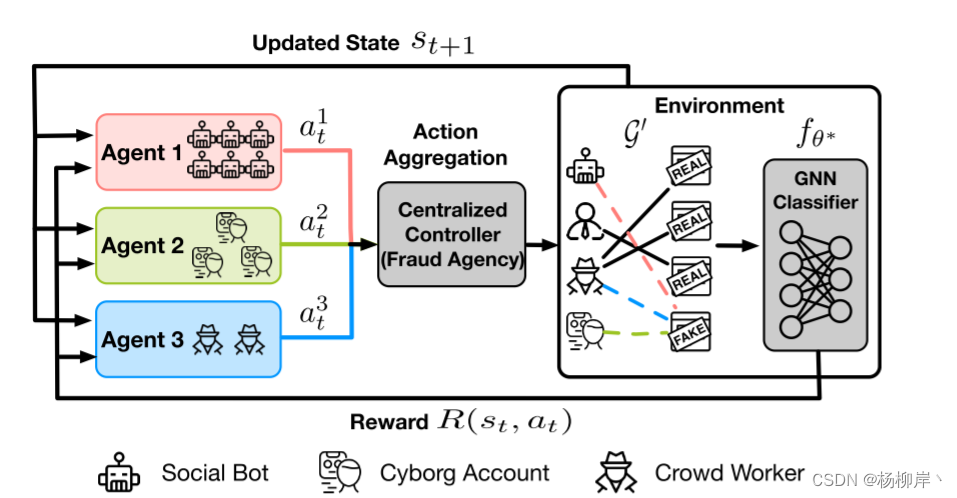
每个智能体都会做出一些行动(分享一个新闻帖子)。这些行动首先被一个中心控制器收集起来。然后,这些行动会被“应用”到社交网络这个环境中,这个环境由用户、帖子和假新闻检测系统构成。最后,根据玩家的行动对环境产生的影响,假新闻检测系统会反馈一些结果,告诉每个智能体的行动是成功了(比如成功让假新闻看起来像真的)还是失败了。每个智能体会根据这些反馈来调整他们下一轮的行动策略。这个过程不断重复,每个智能体都在学习和试图找到最好的方法来使他们控制的假新闻在社交媒体上传播得更远、更广。
MARL框架是一个马尔可夫博弈加深度Q学习,其中马尔可夫博弈由元组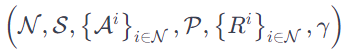 定义,
定义,
公式解释:
专业名词解释:


马尔可夫奖励函数:
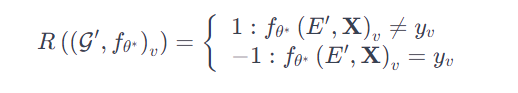
公式解释:
智能体的目标是让分类器错误地将假新闻判定为真新闻。如果它成功了,它就得到正的奖励(+1);如果没成功,就得到负的奖励(-1)。这个奖励会告诉智能体它的行动是好是坏,帮助它在下一轮游戏中做出更好的决策。
马尔可夫结束条件:
当Δu和Δe都消耗空结束。
专业名词解释:

深度Q学习主要采用了下述三个公式的思想来进行的:
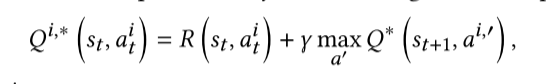
公式解释:这个公式是智能体如何决定最好的行动的计算方法

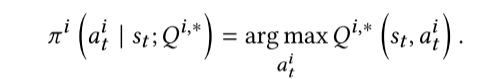
公式解释:这个公式描述了智能体如何选择最佳行动

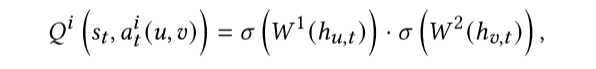
公式解释:这个公式用于计算特定行动的分数
这个公式的意思是,智能体会根据用户和帖子的重要性来计算一个行动的分数。如果一个用户很有影响力,或者一个帖子非常关键,那么相应的行动(如分享这个帖子)可能会得到高分。
实验:
实验设置:
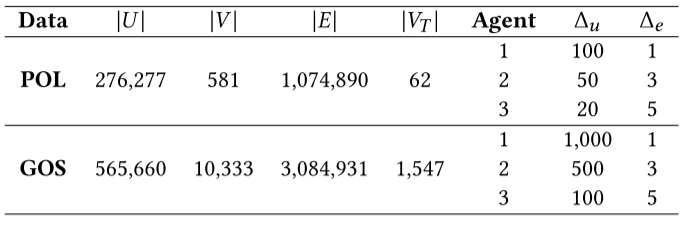
1.数据来源:
数据集是从FakeNewsNet数据库提取的Politifact和Gossipcop
2.特征表示:
用户特征(将用户的历史推文转换为特征表示)和新闻内容特征采用(新闻内容的文本信息也被转化为数字形式)Glove 300D嵌入表示
3.替代模型(无法直接访问或使用原始模型(比如因为隐私、安全性或其他限制)时,替代模型是原始模型的一个近似或模拟,用来进行测试和分析):
为了模拟基于GNN的假新闻检测器,研究者选择了三种经典的GNN模型作为替代模型M。具体来说,这些模型包括图卷积网络(Graph Convolution Network)、图注意力网络(Graph Attention Network)和GraphSAGE。
4.基准测试攻击:
随机边攻击:随便选一些账号和新闻,然后创建连接,就像在社交网络上随机点赞或转发帖子一样,直到用完他们的操作预算。
具体实现:
我们根据智能体节点的度来连接抽样攻击智能体和新闻目标之间的边。具体来说,我们随机连接机器人智能体与1个新闻目标,半机器人智能体与3个新闻目标,众包工作者智能体与5个新闻目标。
随机节点攻击:在网络中创建一些新的账号,并让它们与目标新闻建立联系,有点像制造一些虚假账号并让它们开始进行社交活动。
具体实现:
我们为三种智能体类型各添加了5个用户节点。我们通过随机抽样每种类型的智能体的20个节点,并取它们的嵌入的平均值作为注入节点的新嵌入。我们以随机边方法同样的方式将生成的用户节点与目标新闻节点连接。
单一智能体强化学习攻击:为了显示多智能体方法的优越性,他们还测试了只使用一种类型账号(机器人、半机器人或众包工作者)的攻击效果。
针对以下四个问题设置实验
-
RQ1: 多智能体强化学习的性能与基线相比如何?
-
RQ2: 什么因素影响多智能体强化学习的性能?
-
RQ3: 直接攻击与间接攻击相比如何?
-
RQ4: 针对攻击有哪些对策?
RQ1: 多智能体强化学习的性能与基线相比如何?

结论:
- 假新闻攻击成功率:MARL在提高假新闻攻击成功率方面表现优秀,尤其是在Gossipcop数据集上,攻击成功率的提高非常显著。
- 真新闻攻击性能:MARL在攻击Politifact中的真新闻时并没有显示出优势,尤其是对GCN和GraphSAGE模型。这可能是因为实验中设置的智能体对真新闻的影响不如假新闻显著。
- GCN的敏感性:GCN模型对于图中边的扰动非常敏感,即使只添加少量的边,也能在攻击假新闻时取得较高的成功率。这表明GCN的结构可能使其在面对图结构变化时更加脆弱。
RQ2: 什么因素影响多智能体强化学习的性能?
1.智能体类型:
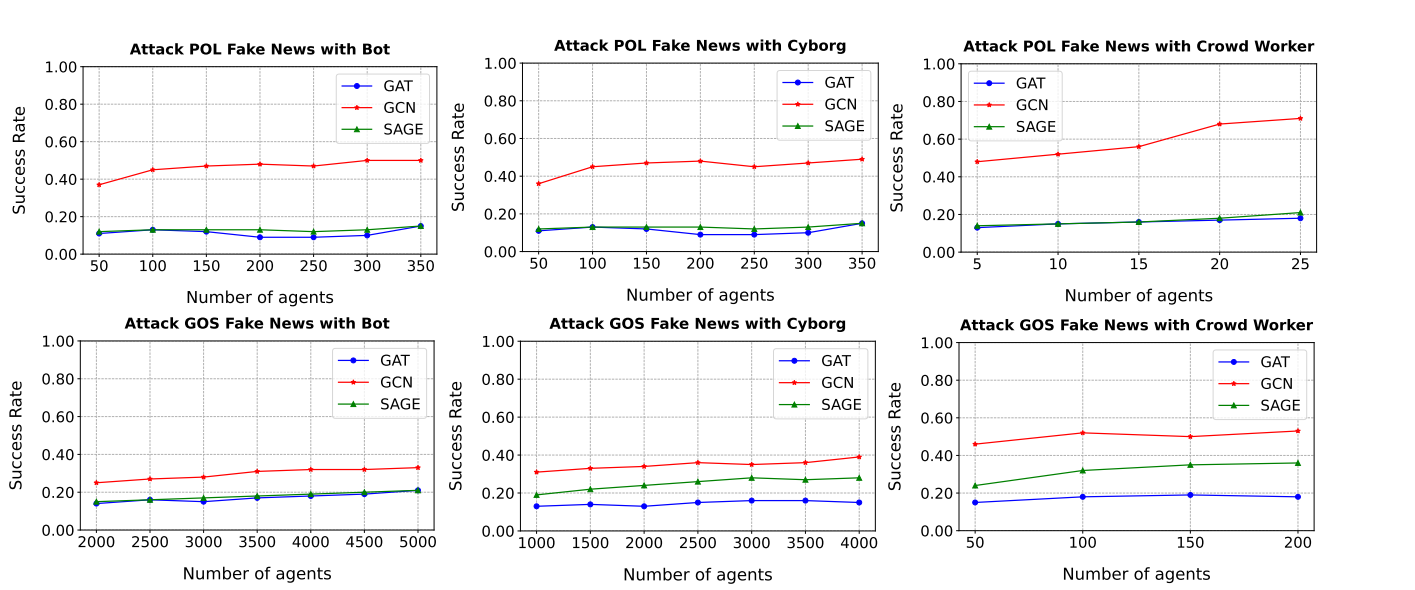
2.新闻类型:
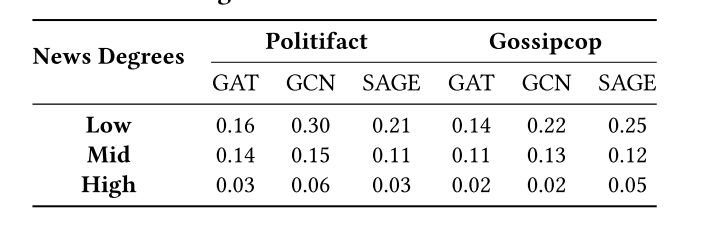
low:度为10以下的节点
mid:度为10-100的节点
high:度为100以上的节点
结论:
- 随着攻击预算的逐步增加,所有三种类型的智能体的整体攻击性能都有所提高。
- 性能增益在达到某个阈值后增长放缓。因此,攻击者需要选择最优数量的智能体来执行间接攻击。
- 在给定相同攻击预算的情况下,众包工作者智能体在所有三个GNN上的表现优于机器人和半机器人智能体。因为众包工作者智能体具有更强的影响力,它们的社交帖子与真实新闻相连,因此它们对假新闻的影响更大。
- 新闻的连接度影响:当攻击连接度低于10的假新闻时,攻击的成功率显著高于攻击连接度超过100的假新闻。这表明,较少被分享的新闻更容易受到攻击,可能是因为它们的信息不够充分,或者不够社交网络中的算法“注意”到。
- 不同GNN模型的鲁棒性:当新闻的连接度从小于10增加到小于100时,GAT的性能下降较少。这可能是因为GAT中的注意力机制使其对连接度的变化不那么敏感。注意力机制能够让GAT更关注重要的连接,而不是仅仅由连接的数量决定。
RQ3: 直接攻击与间接攻击相比如何?
专业名词解释:
直接攻击: 在直接攻击中,受控用户分享的是目标新闻帖子本身Vt,并且这个帖子并不在原始图的邻居中(u, v)。这种方式的目的是通过直接将受控用户的分享与目标新闻帖子相关联,以干扰GNN对目标帖子的分类结果。
间接攻击: 在间接攻击中,受控用户分享的是不与目标新闻帖子直接相关的其他帖子,但受控用户与目标帖子有一条边(u, v)。这种方式利用了GNN的邻居聚合机制,通过改变目标帖子的邻域,影响GNN对目标帖子的分类结果。在实际中,这种攻击方式相对较隐蔽,因为它不直接修改与目标新闻帖子之间的边。
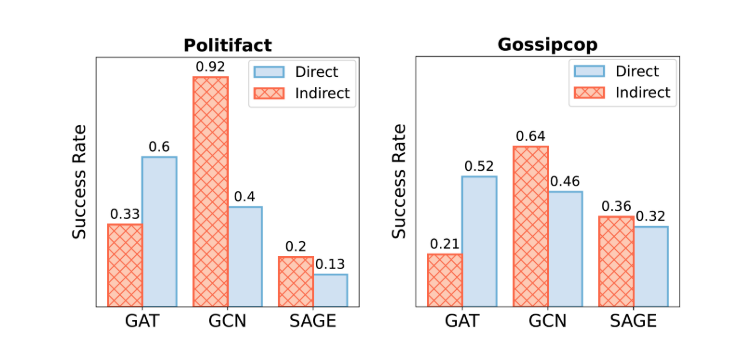
直接攻击和间接攻击Politifact和Gossipcop数据集对比:
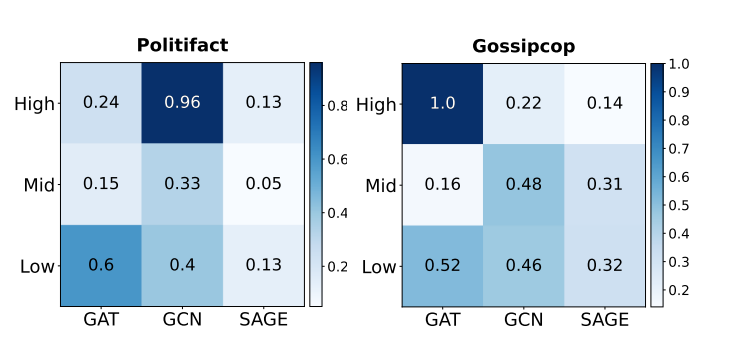
直接攻击不同连接度的新闻的对比:
结论:
- 直接攻击在两个数据集上分别提高了GAT的性能。然而,我们在两个数据集上的GCN和GraphSAGE检测器上看到性能下降。尤其是在Politifact数据集的GCN检测器上。
- 直接攻击在低和中等连接度的新闻上对GAT和GCN检测器有效,而在高连接度的新闻上对GraphSAGE效果不佳。
RQ4: 针对攻击有哪些对策?
结论:
- 从机器学习安全的角度来看,有很多关于防御图对抗攻击的研究工作。可以利用对抗训练、异常检测、和鲁棒的GNN模型等方法来抵御这些攻击。
- 从实际角度来看,社交媒体平台应同样关注“机器人”和看似“良好”的用户。正如实验所展示的,攻击者可以利用用户的良好发布历史来成功地对假新闻进行有针对性的攻击,从而混淆基于GNN的检测器。
- 由于间接攻击对许多GNN检测器都是有效的,这表明平台应该监控与目标新闻互动的帐户的更多参与活动,而不仅仅是目标新闻本身。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









