







常见中间件ES和RocketMQ的面试题
一. RocketMQ如何防止消息丢失
MQ的消息生成到消费主要经历三个阶段:MQ消息生产、RocketMQ Broker存储消息、消费者消息对应的消息。如下图:
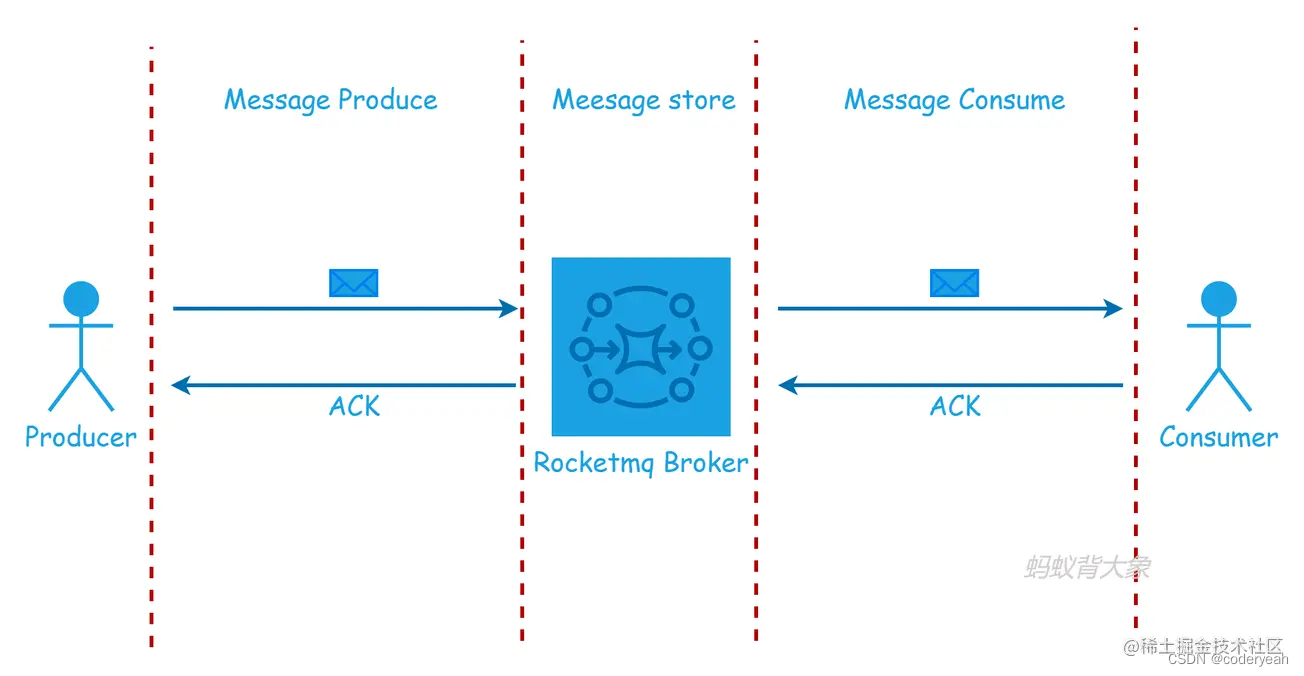
消息丢失情况
-
消息生产者将消息发送到RocketMQ Broker的这个过程可能出现消息丢失。
生产者只要接收到返回的ack,就代表这个阶段的消息未丢失。
生产者通过网络将消息发送到Broker,然后等待Broker响应ack,此时的网络是不可靠的,极有可能导致消息发不出去,或者Broker在ack时网络故障导致生产者收不到ack。
-
RocketMQ Broker接收到生产者发送的消息存储的过程消息可能丢失。
Broker收到消息后是先存储在内存中的,然后再持久化到磁盘,Broker刚收到Producer消息存储在内存中,然后发生宕机,就会导致消息丢失。
RocketMQ的持久化消息有两种方式:同步刷盘:Broker收到消息后会在持久化到磁盘完成后才发送ack
异步刷盘:Broker收到消息存到内存后返回ack,然后Broker定期将一组消息持久化到磁盘
默认是异步刷盘,要保证存储阶段不丢失消息,可以修改为同步刷盘,即确保消息持久化后再ack
-
消费者处理失败,但是将错误进行捕捉,导致消息出现虚假的消费成功。实际上没有消费,但是在MQ看来消费完成了消费。
RocketMQ消息生产方式
- 同步发送消息: 重要的通知(订单状态的更新)、短信系统。
- 异步发送消息: 通常用于响应时间敏感的业务场景。
- One-way: 主要用于对可靠性要求不高的场景,在金融的场景下不适用。一般是用于日志收集。
- one-way 的消息发送模式本身就是不对消息的不丢失无法保证。如果你的系统对消息丢失零容忍不能使用 one-way 的方式发送。
- 同步发送消息和异步发送消息 都可以判断消息的发送状态判断消息是否已经发送到Broker。这里是选择同步发送还是异步发送消息看业务的需要,同步发送比较关心发送后返回的结果对时间的要求不是那么敏感。异步发送对消息返回时间敏感。
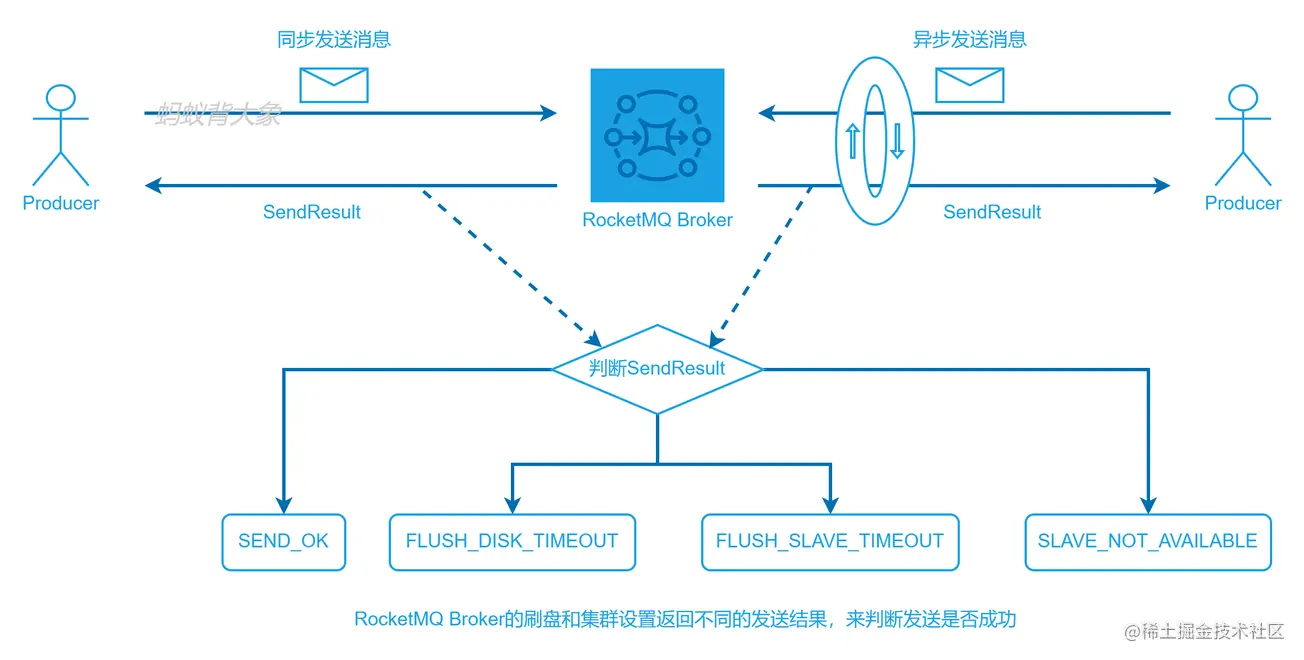
Producer如何保证发送阶段消息可达
失败会自动重试,重试后仍然失败,那么Producer会知道消息没发送成功,这个时候可以进行补偿,或者业务做兜底处理。
Broker是集群部署,高可用,挂了一个节点仍然可以提供服务。
存储阶段
想要在存储阶段保证消息不丢失,可以同步刷盘和主从同步后再发送ack,但是性能肯定会差。
消费阶段
在消费时失败了也会导致消息丢失,这个阶段采用重试也可以解决消息不丢失。
二.RocketMQ如何保证消息有序
**全局有序:**整个 RocketMQ 系统的所有消息严格按照队列先入先出顺序进行消费。
**局部有序:**只保证一部分关键消息的消费顺序。
按照发送的顺序进行消费就是顺序消息,遵循(FIFO), 默认生产者以 Round Robin轮询方式把消息发送到不同的 Queue 分区队列;消费者从多个队列中消费消息,这种情况没法保证顺序。RocketMQ 分为全局有序和部分有序:全局有序是一个 topic 下的所有消息都要保证顺序,如果要保证消息全局顺序消费,就需要保证使用一个队列存放消息,一个消费者从这一个队列消费消息就能保证顺序,即:单线程执行部分顺序消息只要保证某一组消息被顺序消费,即:只需要保证一个队列中的消息有序消费即可。比如:保证同一个订单 ID 的生成、付款、发货消息按照顺序消费即可实现。
三.RocketMQ如何快速处理积压消息
- 如果是机器本⾝的原因,⽐如消费者组有⼏个消费者服务挂掉了,剩下少量消费者消费能⼒不⾜导致的消费积压,那就正常重新启动,然后慢慢再去消费积压的消息。
- 如果是⽣产者端由业务暴增引起的⽣产过快,⽽消费者端消费能⼒不⾜,这个时候就可以采取⽣产者端限流或者进⾏消费者扩容;这个时候要注意,如果⽣产者只是短期暴增或者消息的业务不是很重要可以采⽤限流,如果是长期暴增真正的业务量上涨就必须要进⾏消费者扩
- ⽐如说消费者挂了,然后broker堆积了很多消息,然后可以先把堆积的消息读到别的地⽅⽐如mysql或者es然后去后续进⾏处理,然后把RocketMQ堆积的消息删掉,启动消费者保障消费者正常消费,这⾥要注意的是删除堆积消息之前,需要停⽌mq。
四.RocketMQ延迟消息级别,消费模式
延时消息是指发送到 RocketMQ 后不会马上被消费者拉取到,而是等待固定的时间,才能被消费者拉取到。
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
这里延时级别有 18 个,延迟级别是 3,消息会延迟 10s 后消费者才能拉取。
消费模式
消息到消费分为:拉取式 pull ,和推送是 push
- Pull:拉取式,需要消费者间隔一定时间就去遍历关联的 Queue,实时性差但是便于应用控制消息的拉取
- Push:推送式,封装了 Queue 的遍历,实时性强,但是对系统资源占用比较多。
五.RocketMQ事务消息原理
事务消息解决的就是,事务发送方执行本地事务和事务消息的原子性。
- 首先事务发起方:往 MQ 中发送一个事务消息-half 半消息(准备消息),该消息不可被消费;
- 然后事务发送方执行本地事务,并发送 commit 给 MQ,如果是执行失败就会发送rollback 给 MQ;
- 然后事务发送方执行本地事务,并发送 commit 给 MQ,如果是执行失败就会发送rollback 给 MQ;
- 事务参与者,也就是消费者会消费这个消息,然后执行相关的逻辑处理。如果是Rollback 消息就不会被消费,而是丢弃;
- 如果事务参与方并没有发送 commit 或者 rollback 指令 MQ,MQ 回调用事务发送方的回到方法来检查,我们需要去实现这个本地事务检查接口,通过返回 commit 或者rollback 来告知 MQ 本地事务是否执行成功。
六.为什么要使用es,跟sql模糊查询比如何
查询速度快,传统搜索比如 mysql 的 like 关键字查询,它的搜索方式就是全文扫表,查询性能很低;
ES 是基于 Lucene 的全文检索引擎,它采用的是倒排索引结构,在存储时先对文档进行分词,再做一些标点符号去除,大小写时态转换等优化处理,最后按照字母顺序去重,排序,形成一个倒排索引文档,我们在检索时,就可以通过二分查找的方式找到目标值。
七.es的版本,es的分层结构,index下面是什么
- Index:索引库,包含有一堆相似结构的文档数据,类比 Mysql 中的数据库
- Type:类型,它是 index 中的一个逻辑数据分类,类比 Mysql 中的表
- Document:文档:是 ES 中的最小数据单元,通常用 json 结构标识,类比 Mysql 中的一行数据
- Field:字段:类比 Mysql 中的一个列
- 从 ES7.0 开始,Type 被干掉了,从此库表合一即一个 Index 中只有一个默认的 Type
八.es的keyword和text区别
- keyword:不分词,直接建立索引,支持模糊查询,精确查询,聚合查询;
- text:分词后建立索引,支持模糊查询,精确查询,不支持聚合查询;
- keyword 通常用于通常用于存储年龄,性别,邮编,邮箱号码等等,直接将完整数据保存的场景;
- text 通常存储全文搜索的数据,例如地址,文章内容的保存。
九.es分词器
ES会将text格式的字段按照分词器进行分词,并编排成倒排索引,正是因为如此,es的查询才如此之快。
- standard分词器 —— ES默认分词器,对于中文会按每个字分开处理,会忽略特殊字符;
- ik 分词器 —— 适用于根据词语查询整个内容信息,同样忽略其他特殊字符以及英文字符;
- pinyin 分词器 —— 适用于通过拼音查询到对应字段信息,同时忽略特殊字符。
十.DSL语法
- DSL 是一种以 json 形式标识的,由 ES 提供的一种查询语言,它由两部分组成,DSL查询和 DSL 过滤。
- DSL 过滤类似于模糊查询,DSL 查询类似于精确查询。
十一.es怎么保证并发安全性
ES采取的是乐观锁机制;ES是靠内部维护的一个_version版本号字段进行乐观锁的。
每个索引文档都有一个版本号。默认情况下,使用从 1 开始的内部版本控制,每次更新都会增加,包括删除。版本号可以设置为外部值(例如,如果在数据库中维护)。
十二.Elasticsearch如何保证读写一致?
1、可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
2、另外对于写操作,一致性级别支持 quorum/one/all,默认为 quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络 等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点 上重建。
3、对于读操作,可以设置 replication 为 sync(默认),这使得操作在主分片和副 本分片都完成后才会返回;如果设置 replication 为 async 时,也可以通过设置搜索请求参数_preference 为 primary 来查询主分片,确保文档是最新版本。
十三.ES如何实现高亮
使用 HighlightBuilder 对关键字作高亮处理,由于我们项目使用的是 SpringBoot 整合 ES的 jar 包,结果没有进行高亮处理,我们使用 ElasticsearchTemplate 的 queryForPage 方法来获取结果,再手动进行分页封装返回前台。
十四.ES有哪些聚合查询?
- 指标聚合,比如求和,求最大值,最小值,平均数
- 数量统计聚合,计算满足条件数据的总条数,相当于 sql 中的 count
- Q 去重聚合,它会计算非重复的数据个数,相当于 sql 中的 distinct
- 桶聚合,它会将某个 field 的每个唯一值当成一个桶,并计算每个桶内的文档个数,相当于 sql 中的 group by
- 最高权值聚合,它会匹配每组前 n 条数据,相当于 sql 中的 group by 后取出前 n 条。
十五.es集群,分片机制(了解)
集群
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型[数据集],实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群,集群内的节点的cluster.name相同。
分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。
这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。 当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。















 4248
4248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









