







JDK中优先级队列就是基于堆的实现,所以率先学习堆。
文章目录
1️⃣堆(基于二叉树)
1.概念和特点
堆有很多种实现形式,二叉树只是其中一种。
二叉堆有两个特点:
- 在结构上是一颗完全二叉树
- 结点间的关系:
在最大堆/大根堆中,根结点的值 >= 子树中结点的值;
在最小堆/小根堆中,根结点的值 <= 子树中结点的值.
注意:
在一个大根堆中,结点值的大小和结点所在层数无关,例如:

2.存储结构
完全二叉树/满二叉树可以也建议使用顺序表进行存储,但是其他的二叉树不建议使用顺序表。
因为在完全二叉树中,按照层序遍历二叉树的结果中不存在只有右子树而没有左子树的情况,不用存储空结点,所以使用顺序表存储完全二叉树没有空间浪费。
使用顺序表存储二叉树,结点的索引和结点的关系:
- 根结点从
0开始编号 - 给定一个编号为
k的结点,判断该结点是否有子树依据:2 * k + 1 < 数组长度
其左子树的索引:k * 2 + 1;右子树的索引:k * 2 + 2. - 给定一个编号为
k的结点,父节点为:(k - 1) / 2,判断是否存在父节点:(k - 1) / 2 > 0
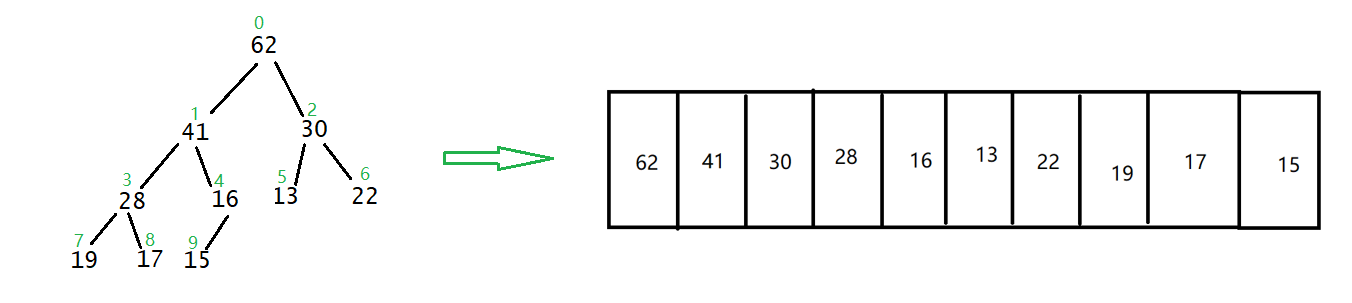
普通二叉树不推荐使用顺序表进行存储,是因为要存储空结点(为了区分左右子树),会浪费大量的空间

3.代码实现
以最大堆为例
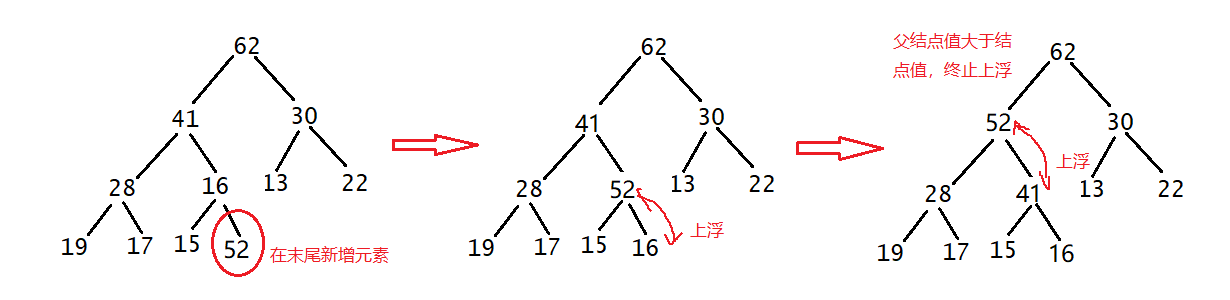
添加元素(元素上浮)
- 直接在数组的末尾新增元素(结构上保证添加了元素后,这颗二叉树仍然是完全二叉树)
- 添加了元素后,调整元素的位置,使得这颗完全二叉树仍满足最大堆的性质。
这里需要将末尾的元素进行上浮操作,使之满足最大堆。
终止条件为:走到根结点 || 父结点值 >= 该结点的值
例如:
插入一个值为52的结点,上浮操作:
代码
public void add(int val){
data.add(val);
siftUp(data.size() - 1);
}
private void siftUp(int k) {
//终止条件:已经走到根结点 || 父节点的值 >= 结点的值
while(k > 0 && data.get(parent(k)) < data.get(k)){
//交换当前结点和父节点的值
swap(parent(k),k);
//更新坐标
k = parent(k);
}
}
private void swap(int i, int j) {
int tmp = data.get(i);
data.set(i,data.get(j));
data.set(j,tmp);
}
取出元素(元素下沉)
堆顶元素就是这个堆元素的最值,对于最大堆来说,取出的就是最大值。
- 从数组中取出最大值,也就是堆顶
- 删除堆顶元素,将数组末尾的元素放到堆顶并进行下沉操作
下沉操作的终止条件:到达了叶子叶子结点( 2 * k + 1 > size)|| 当前结点值 >= 左右子树的最大值
例如:
取出堆顶元素62后的下沉操作:

代码
public int extractMax() {
//判空
if(data.size() == 0){
throw new NoSuchElementException("The heap is empty!");
}
//取出堆顶
int out = data.get(0);
//将末尾顶到堆顶
data.set(0,data.get(data.size() - 1));
//删除末尾
data.remove(data.size() - 1);
//下沉
siftDown(0);
return out;
}
private void siftDown(int k) {
//判断是否还存在子树
while(leftChild(k) < data.size()){
int child = leftChild(k);
//存在右子树并且右子树大于左子树,将较大的结点保存
if(child + 1< data.size() && data.get(child) < data.get(child + 1)){
child += 1;
}
//判断子树的是否小于结点
if(data.get(child) < data.get(k)){
break;
}
//交换最大的孩子和父节点的值
swap(k,child);
//更新父节点,继续下沉
k = child;
}
}
private int leftChild(int k){
return 2 * k + 1;
}
private void swap(int i, int j) {
int tmp = data.get(i);
data.set(i,data.get(j));
data.set(j,tmp);
}
将任意数组堆化
之前存储完全二叉树就是用数组存储的,所以任意数组都可以看作为一颗完全二叉树。
方法一:
将数组中的元素逐个用add()方法插入一个新堆中,就可以得到一个最大堆了。
这个方法是可行的,但是它的时间复杂度为O(N * logN),其实可以用时间复杂度为O(N)的建堆方法。
方法二
从这个完全二叉树的最后一个非叶子结点进行元素的下沉操作即可。
那么应该如何找到最后一个非叶子结点呢?
其实就是最后一个结点的父结点就是,即(data.size() - 1) / 2,找到了该结点就可以建堆了。
代码:
public MaxHeap(int[] arr) {
data = new ArrayList<>(data.size());
//将数组中的值拷贝进二叉树中
for(int i:arr){
data.add(i);
}
//从最后一个结点开始下沉
for (int i = (data.size() - 1) >> 1; i >= 0; i--) {
siftDown(i);
}
}
2️⃣优先级队列
1.概念
优先级队列看起来是个队列,底层是基于堆实现的。
普通队列:FIFO
元素先进先出,按照入队的顺序进行逐个出队操作。
基于链表的时间复杂度:入队(O(1));出队(O(N)),最坏情况,比如出最大值。
优先级队列:
按照元素间的优先级的大小动态顺序,处理的元素个数是动态变化的,有进有出,不像排序处理的集合元素个数是固定的。
基于堆的时间复杂度:入队(O(logN)),元素上浮;出队(O(logN)),元素下沉
举个栗子:
医生给患者做手术。此时等待做手术的患者有十个人,其中会按照患者的病情安排做手术的顺序,情况越严重的患者“优先”进行手术,病情差不多的患者依次按照先后顺序进行手术。
2.基本类型的使用
JDK中的优先级队列默认是最小堆的。
//基本类型
int[] arr = new int[]{3,5,7,9,1,5,7,2,4};
Queue<Integer> queue1 = new PriorityQueue<>();
for(int tmp : arr){
queue1.offer(tmp);
}
int[] ret = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
ret[i] = queue1.poll();
}
System.out.println(Arrays.toString(ret));
//输出结果:
[1, 2, 3, 4, 5, 5, 7, 7, 9]
那如果优先级队列保存的不是基本类型,而是自定义类型,还能直接使用吗?
3.自定义类型的使用
如果定义一个Student类,并且在优先级队列中直接使用该类会怎样:

我们可以看到此时报错了,是因为自定义类的对象之间无法比较大小,想要使其能够比较大小,有以下两种方法:
(1)Comparable接口
java.lang.Comparable
一旦一个类实现了Comparable接口,就表示该类具备了可比较大小的能力
@Override
public int compareTo(Student o) {
return 0;
}
重写compareTo方法,根据其返回值就可以对其进行比较,返回值是自己决定的。
内部会返回值的大小进行比较,具体规则:
返回值 > 0,表示当前对象 > 传入对象
返回值 = 0,表示当前对象 = 传入对象
返回值 < 0,表示当前对象 < 传入对象
代码
public class PriorityQueueTest {
public static void main(String[] args) {
Queue<Student> queue = new PriorityQueue<>();
Student stu1 = new Student("师傅",40);
Student stu2 = new Student("哥哥",20);
Student stu3 = new Student("姐姐",30);
Student stu4 = new Student("老师",35);
//排序
System.out.println("排序:");
Student[] students = {stu1,stu2,stu3,stu4};
Arrays.sort(students);
System.out.println(Arrays.toString(students));
//优先级队列
System.out.println("优先级队列:");
queue.offer(stu1);
queue.offer(stu2);
queue.offer(stu3);
queue.offer(stu4);
System.out.println(queue);
}
}
class Student implements Comparable<Student>{
private String name;
private int age;
public Student(String name,int age){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
//实现Comparable接口实现自定义类型可比较
public int compareTo(Student o) {
return this.age - o.age;
}
}

其中默认的排序是升序的,优先级队列默认是小堆。
如果想要改变排序顺序和堆结构要怎么呢?
我们可以修改compareTo方法的返回值改变结果:
@Override
//实现Comparable接口实现自定义类型可比较
public int compareTo(Student o) {
return o.age - this.age;
}
但是如果需要根据需求变换排序结果时,就又得要修改compareTo方法。
根据不同场景需求频繁改动代码是大忌!
所以引出第二种方法:
(2)实现Comparator接口
java.util.Comparator比较器
此时需要比较的类不需要实现此接口,而是有一个专门的类来实现此接口,这个类就是专门用于比较的!
代码
//使用Comparator比较器,实现无侵入编程
//实现小堆比较的类
class StudentCom implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
return o1.getAge() - o2.getAge();
}
}
//实现大堆比较的类
class StudentComDesc implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
return o2.getAge() - o1.getAge();
}
}
Comparator相较于Comparable来说更加灵活,无须修改自定义类代码,根据不同的需求配置不同的比较器,实现无侵入编程。
//在定义队列的时候就传入比较器
//小堆
Queue<Student> queue1 = new PriorityQueue<>(new StudentCom());
//大堆
Queue<Student> queue2 = new PriorityQueue<>(new StudentComDesc());
或者使用匿名内部类的方式:
//匿名内部类
Queue<Student> queue = new PriorityQueue<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge() - o2.getAge();
}
});
在或者使用Lanbda表达式,函数式编程:
//函数式编程,Lambda表达式
Queue<Student> queue = new PriorityQueue<>((o1,o2) -> o1.getAge() - o2.getAge());
往期文章:
















 2002
2002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











