







GCR: GRADIENT CORESET BASED REPLAY BUFFER SELECTION FOR CONTINUAL LEARNING
Abstract
continual learning旨在用一个模型有效解决增量任务的学习,这篇工作可以看做是基于重演的对抗知识遗忘的方法,提出了一个 Gradient Coreset Replay (GCR)策略来重演被选择的缓存,其中本文选择一个Coreset(核心集),这个核心集尽力近似所有见过的数据的模型的梯度。
1 Introduction
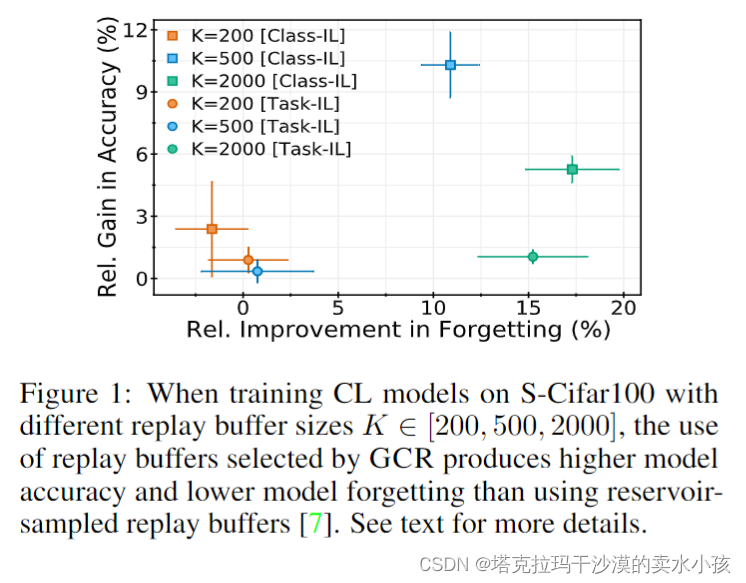
CL任务主要要解决的是灾难遗忘的问题,目前的方法有对loss函数,网络结构,训练过程和数据增广做改进。重演的方法就是把之前见过的数据的一小部分maintain下来,如果使用随机采样, 保存1%的原先数据就能对灾难遗忘问题产生很好的效果。和其他基于重演的方法相比,GCR更注重如何选择coreset。
2 Related Work
本文把CL的方法分为三类,正则和结构调整的方法就不展开介绍了,主要谈一下重演的方法。有些方法加入蒸馏损失(限制参数变化)或使用memory;Meta-Experience Replay (MER)在meta learning方法中在task之间加入惩罚项;Maximally Interfered Retrieval (MIR)通过预测模型更新参数对memory进行检索,然后选择最有利于模型更新的样本重演。
Coreset Selection: 核心集是一个权重数据子集,其近似原始数据的特定属性(loss,grandients,logits),本文关注Coreset的选取问题。
Coresets for Replay-based CL: 和先前的方法相比,本文使用了一个和replay的损失函数直接相关的优化准则;另外用了一个带有权重的核心集选取策略,这个权重是由核心集优化准则决定的。
3 Preliminaries
3.1 Notation
对于本文符号的说明:
T
T
T: tasks的数量
t
∈
{
1
,
2
,
…
,
T
}
t\in\{1, 2, \dots, T\}
t∈{1,2,…,T}: task
D
t
D_t
Dt: task
t
t
t的数据集
{
(
x
i
t
,
y
i
t
)
i
=
1
∣
D
t
∣
}
\{(x_{it}, y_{it})^{|D_t|}_{i=1}\}
{(xit,yit)i=1∣Dt∣}: 每个数据点,
i
i
i指第
i
i
i个样本
y
t
=
y
t
1
,
y
t
2
,
…
,
y
t
n
y_t=y_{t1}, y_{t2}, \dots, y_{tn}
yt=yt1,yt2,…,ytn: 每个task都有n个相关的类别,且每个task之间的类别没有重合
Ω
θ
(
x
)
\Omega_\theta(x)
Ωθ(x): 特征层输出
h
θ
(
x
)
h_\theta(x)
hθ(x): logits输出
f
θ
(
x
)
=
S
O
F
T
M
A
X
(
h
θ
(
x
)
)
f_\theta(x)=SOFTMAX(h_\theta(x))
fθ(x)=SOFTMAX(hθ(x))
X
\mathcal{X}
X: 先前task用于重演的data buffer
L
r
e
p
(
θ
,
X
)
\mathcal{L}_{rep}(\theta, \mathcal X)
Lrep(θ,X): replay-buffer loss
3.2 Continual Learning
CL问题的目标和挑战,这里不重复翻译了。
3.3 Replay-based Continual Learning
基于重演方法的训练可以归结为以下公式:
arg min
θ
∑
(
x
,
y
)
∈
D
t
l
(
y
,
f
θ
(
x
)
)
+
λ
L
r
e
p
(
θ
,
X
)
\argmin_{\theta}\sum_{(x,y)\in{D_t}}l(y, f_{\theta}(x))+\lambda\mathcal L_{rep}(\theta, \mathcal X)
θargmin(x,y)∈Dt∑l(y,fθ(x))+λLrep(θ,X)
有些工作会存储与数据点相关的logits(z):
L
r
e
p
(
θ
,
X
)
=
∑
(
x
,
y
)
∈
X
(
α
∣
∣
z
−
f
θ
(
x
)
∣
∣
2
+
β
l
(
y
,
f
θ
(
x
)
)
)
\mathcal L_{rep}(\theta, \mathcal X)=\sum_{(x,y)\in \mathcal X}(\alpha||z-f_{\theta}(x)||^2+\beta l(y,f_{\theta}(x)))
Lrep(θ,X)=(x,y)∈X∑(α∣∣z−fθ(x)∣∣2+βl(y,fθ(x)))
4 GCR: Methods
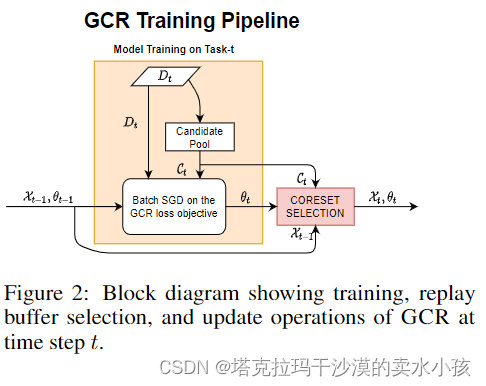
Fig 2就是GCR的overview。本文先构成先前的重演buffer X t − 1 \mathcal X_{t-1} Xt−1和当前数据形成的候选池 C t \mathcal C_t Ct中。之后的操作都在候选池中操作而不是在当前数据流 D t D_t Dt中进行。本文的主要贡献是把选取重演buffer视为基于近似梯度的优化问题
4.1 GradApprox for Replay Buffer Selection

从论文中这一段可以看到,作者这个loss的组成是对梯度做L2损失,加一个关于权重的正则项。L2损失中前一项是整个数据集,后一项是数据集中挑选出来的子集。
也就是说GradApprox挑选出来的数据子集的加权梯度近似等于整个数据集的梯度。
上面这个式子可以看出是很难把这个优化过程模块化的,因此作者采用近似算法——正交匹配追踪来选取子集和权重。最终选择的buffer中的类别应该是相等的,以保证类别平衡。
4.2 GCR Loss objective
重演buffer和候选池中的数据由(x, y, z)组成,损失函数如下:

第一项:预测值和当前任务真值的损失;
第二项和第三项:buffer和候选池中真值和logits的损失;
第四项:监督对比损失,促进embedding space中同类距离拉近,异类距离拉远
下面给出伪代码:


4.3 The GCR algorithm
这一段大概解读了一下上面流程的几个小细节,比如如何采样啊之类的,最后强调了一下算法1需要知道数据边界,在实际使用时可以通过流边界和数据规则间隔来设置边界。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









