






 文章讲述了如何使用Python脚本遍历文件夹,检测.xlsx文件,读取数据并合并,以及使用Linux命令进行文件移动和合并的方法,以实现对xlsx文件中的数据进行统计并保存到单个文件中。
文章讲述了如何使用Python脚本遍历文件夹,检测.xlsx文件,读取数据并合并,以及使用Linux命令进行文件移动和合并的方法,以实现对xlsx文件中的数据进行统计并保存到单个文件中。
此工具来源来自于一道比赛题目,题目描述大致如下:
现在有一个文件夹下面包含若干子文件夹,某个子文件夹下面可能有一个xlsx文件,要求把所有xlsx中的数据进行统计,得到的数据行数为答案
文件深度大概如下

可见还是相当麻烦,还是比较多
Python脚本
import os
import shutil
# 指定源目录和目标目录
src_dir = 'file'
dst_dir = 'out'
# 确保目标目录存在,如果不存在则创建
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
# 遍历源目录及其所有子目录
for root, dirs, files in os.walk(src_dir):
for file in files:
# 判断文件是否为xlsx格式
if file.endswith('.xlsx'):
# 构建完整源文件路径和目标文件路径
src_file = os.path.join(root, file)
dst_file = os.path.join(dst_dir, file)
# 复制文件到目标目录
shutil.copy2(src_file, dst_file)
print("所有xlsx文件已成功复制到out目录下。")分拣加合并代码
import os
import shutil
from pathlib import Path
import pandas as pd
# 指定源目录和目标目录
src_dir = 'file'
dst_dir = 'out'
# 确保目标目录存在,如果不存在则创建
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
# 用于存储所有.xlsx文件的数据帧
all_xlsx_data = []
# 遍历源目录及其所有子目录
for root, dirs, files in os.walk(src_dir):
for file in files:
# 构建完整源文件路径和目标文件路径
src_file = os.path.join(root, file)
dst_file = os.path.join(dst_dir, file)
# 复制文件到目标目录
shutil.copy2(src_file, dst_file)
print(f"{file} 已成功复制到 {dst_dir} 目录下。")
# 判断文件是否为.xlsx格式
if file.endswith('.xlsx'):
# 读取 Excel 文件并存储到列表中
df = pd.read_excel(src_file)
all_xlsx_data.append(df)
# 将所有.xlsx文件合并为一个数据帧
merged_df = pd.concat(all_xlsx_data, ignore_index=True)
# 将合并后的数据帧写入到out.xlsx文件中
output_file = os.path.join(dst_dir, 'out.xlsx')
merged_df.to_excel(output_file, index=False)
print(f"所有.xlsx文件已成功合并到 {output_file} 文件中。")
当然也可以使用linux一条命令进行
find -type f -name "*.xlsx" -exec mv {} out \;\n合并可以使用wps进行合并
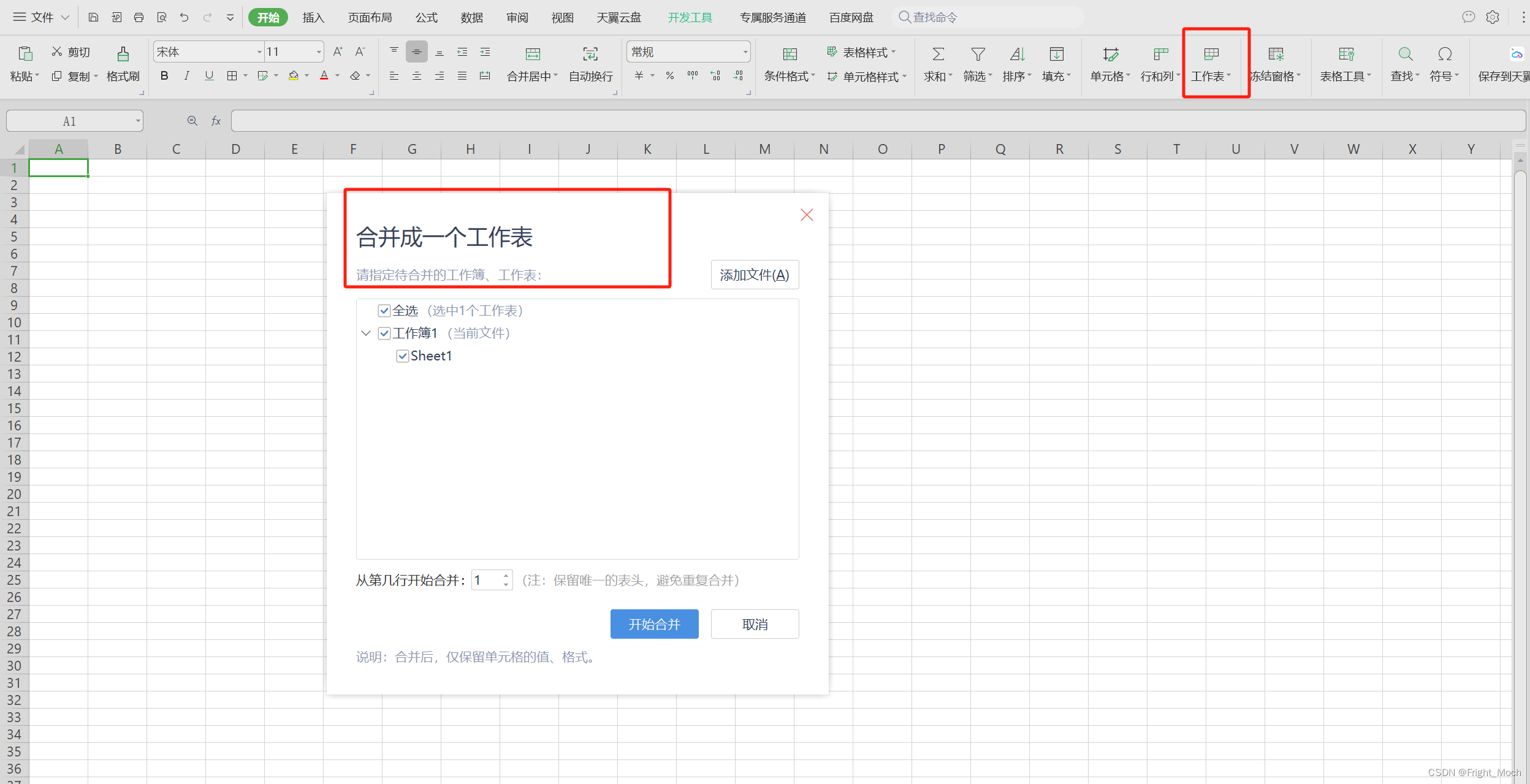 也可以达到效果,无论采用那种方式都可以达到相同的效果,只要目的达到了就行了,大佬勿喷!!题目文件资源已经绑定,各位大佬可以试一下~
也可以达到效果,无论采用那种方式都可以达到相同的效果,只要目的达到了就行了,大佬勿喷!!题目文件资源已经绑定,各位大佬可以试一下~















 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









