







java基础笔记
面向对象(OOP,Object Oriented Programing)
面向对象是相对于面向过程来说的:面向过程就是利用数据以及操作这些数据的方法按照一定的顺序组合来完成一件事情的编程思想,例如C语言;面向对象是将数据和方法抽象成一个整体---对象,使用对象的方法来完成一件事情的编程思想,例如java/C++,优点是:隐藏实现细节更安全、代码低耦合更加灵活、易于维护 …
1、抽象类与接口
抽象方法:如果父类的方法本身不需要实现任何功能,仅仅是为了定义方法签名,目的就是让子类去覆盖它(比如动物类的叫声方法,在"动物"本身这个类去实现没有任何意义,它的存在就是为了子类去重写,因为每个子类叫声并不相同,不能通过父类去统一实现),那么就可以把父类的这个方法定义为抽象方法。
[权限修饰符] abstract [返回值类型] 方法名(); //没有方法体
一个普通类里面不能定义抽象方法,因为抽象方法本身无法执行,如果普通类包含抽象方法就导致无法实例化,编译器会报错无法编译这个普通类。
抽象类:如果一个类中有抽象方法,那么这个类是抽象类(abstract class),使用abstract修饰的类。如果一个类没有足够的信息来描述一个具体的对象,这样的类就是抽象类。抽象类除了不能实例化对象之外,类的其它功能依然存在,成员变量、成员方法和构造方法的访问方式和普通类一样。由于抽象类不能实例化对象,所以抽象类必须被继承,才能被使用。
接口:是一种约束形式,其中只包括成员定义,不包含成员具体的实现,是抽象方法的集合。目的是为了不相关的类提供通用的处理服务。(如各种数据的驱动实现)
接口中的方法在jdk1.8以后除了抽象方法外还可以有default定义的默认方法和static静态方法,接口中的成员变量默认是public static final类型。接口中的方法默认是public abstract类型。
2、抽象类和接口的区别
1. 抽象类中的方法可以有方法体,就是能实现方法的具体功能,但是接口中的方法不行。
2. 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 public static final 类型的。
3. 接口中不能含有静态代码块以及静态方法(用 static 修饰的方法),而抽象类是可以有静态代码块
和静态方法。
4. 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
5. 接口没有构造方法,而抽象类有构造方法。
3、函数式编程
面向对象编程:做一件事情,创建一个能解决这件事的对象,通过调用对象的方法实现这件事。
函数式编程:是一种通过应用和组合函数来构建程序的编程思想。
函数式接口:一个接口中的抽象方法只有一个,那么这个接口就是一个函数式接口。
通过@FunctionalInterface注解检测一个接口是否是函数式接口。
使用函数式接口编写计算两个数运算的方法,以加减为例;
@FunctionalInterface
public interface Calculate {
int calculate(int a,int b);
}
class Test{
public static Calculate operator(String opr){
Calculate result = null;
switch(opr){
case "+":
result = new Calculate() {
@Override
public int calculate(int a, int b) {
return a+b;
}
};
break;
case "-":
result = new Calculate() {
@Override
public int calculate(int a, int b) {
return a-b;
}
};
break;
}
return result;
}
public static void main(String[] args) {
Calculate f1 = operator("+");
Calculate f2 = operator("-");
System.out.println("加操作"+f1.calculate(10,20));
System.out.println("减操作"+f2.calculate(10,20));
}
}
虽然上面用匿名内部类实现了函数式接口开发,但还是代码略显繁琐,下面使用Lambda表达式
Lambda表达式是什么
Lambda 表达式也称为闭包,是Java 8 发布的新特性
Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)
为什么要使用Lambda表达式
避免匿名内部类定义过多,可以让代码简洁紧凑,留下核心的逻辑
使用Lambda表达式前提是:接口是函数式接口
Lambda表达式语法
(参数列表) ->{重写接口的方法的方法体}
特征
- 可省略类型声明:不需要声明形式参数类型
- 可省略参数括号:一个参数无需定义括号,但多个参数需要定义括号
- 可省略花括号:如果主体只包含了一个语句就不需要使用花括号
- 可省略返回关键字:如果主体只包含了一个返回值语句则会自动返回
比如对于上述的Calculate接口,其Lambda表达式使用如下:

根据省略的规则可以进一步简化:
case "+":
result = (a,b) -> a+b;
break;
例:Runnable创建线程:
new Thread(new Runnable(){
@override
public void run(){
System.out.println("这是一个个创建的线程");
}
}).start();
Lambda表达式用法:
new Thread(()->System.out.println("这是一个个创建的线程")).start();
4.Lambda的::双帽号使用
“::”就是java中的方法引用关键字。
java8中我们可以使用::关键字来访问类的构造方法,成员方法,静态方法。
获取到这些方法以后就能直接绑定到接口上不需要继承和重写了,摆脱了类的负担。
参数的个数类型顺序返回值必须一致,虽然返回值可以不一致但是会影响到方法的使用最终结果。
方法引用格式:类名::方法名

@FunctionalInterface
public interface Calculate {
int plus(int a,int b);
}
class Test{
public static void main(String[] args) {
//Calculate c=(a,b)->Integer.sum(a,b);
Calculate c= Integer::sum;
System.out.println(c.plus(23,45));
}
}
5.java中提供的函数式接口
1.Supplier<T>生产型接口
//源码
@FunctionalInterface
public interface Supplier<T> {
T get();
}
可以看出来就是一个无参数带返回值的一个get抽象方法
也就意味着这个接口主要的作用是对外提供数据的,等同于封装中的Get()用法
比如冒泡排序返回排好序的数组
public static void main(String[] args) {
int[] arr={20,18,33,28,16,8,4,12,9};
Supplier<int[]> supplier=()->{
int len=arr.length;
for (int i=1;i<len;i++){
boolean isSort=true;
for (int j=0;j<len-i;j++){
if (arr[j]>arr[j+1]){
arr[j]=arr[j]^arr[j+1];
arr[j+1]=arr[j]^arr[j+1];
arr[j]=arr[j]^arr[j+1];
isSort=false;
}
}
if (isSort)
break;
}
return arr;
};
System.out.printf("冒泡排序后的数组元素为:%s",
Arrays.toString(supplier.get()));
}
2.Consumer<T>消费接口
//源码
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after); //判断对象是否为空,如果是空,报异常
return (T t) -> { accept(t); after.accept(t); };
//可以发现这段代码就是调用当前的方法和调用传递进来的接口内的方法,
//然后返回一个接口用于再次拼接
}
}
通过源码我们可以发现 accept 是一个 只有一个参数无返回值的抽象方法
那么 很好理解了就是将传进来的数据进行处理,等同于封装中的Set()用法
public static void stringReverse(String name,Consumer<String> consumer){
consumer.accept(name);
}
public static void main(String[] args) {
//将传进去的字符串进行反转在打印
stringReverse("case",name->System.out.println(new StringBuilder(name).reverse()));
ArrayList<String> list = new ArrayList<>();
}
3.Function计算转换接口

4.Predicate判断接口

6、Stream流操作
java8的Stream使用的是函数式编程模式,如同它的名字一样,它可以用来对集合或数组进行链状流式的操作。可以方便的让我们对集合操作。
获取Stream流对象,只有获取流对象后才能使用Stream中的方法,所有Collection接口包括子接口都有默认的stream默认的方法获取流;stream流必须要有终结操作(如forEach)才会执行。
//把单列集合 转换为Stream流
List<String> list=new ArrayList<>();
Stream<String> stream = list.stream();
Set<String> set=new HashSet<>();
Stream<String> stream1 = set.stream();
//把双列集合 转换为Stream流
Map<String,String> map=new HashMap<>();
//将所有的key 都转换为 Stream流
Stream<String> stream2 = map.keySet().stream();
//把所有的value 都转换为 Stream流
Stream<String> stream3 = map.values().stream();
//我们还可以 通过Entry 来转换为Stream流
// 顺便 介绍下用法
map.put("a","A");
map.put("b","B");
Stream<Map.Entry<String, String>> stream4 = map.entrySet().stream();
stream4.forEach(entry-> System.out.println(entry.getKey()));
使用函数式接口,对下列书籍进行过滤并排序;
public class StreamTest {
public static void main(String[] args) {
List<Book> books=new ArrayList<Book>();
books.add(new Book("名侦探柯南",200.0,"青山刚仓"));
books.add(new Book("大侦探霍桑",30.6,"程小青"));
books.add(new Book("夏洛克.福尔摩斯",700.0,"柯南.道尔"));
books.add(new Book("三国演义",300.5,"罗贯中"));
books.add(new Book("红楼梦",20.5,"曹雪芹"));
books.add(new Book("水浒传",290.5,"施耐庵"));
books.add(new Book("西游记",10.5,"吴承恩"));
books.stream().filter(new Predicate<Book>() {
@Override
public boolean test(Book book) {
return book.getPrice()<60;
}
}).sorted(new Comparator<Book>() {
@Override
public int compare(Book o1, Book o2) {
return (int) (o1.getPrice()-o2.getPrice());
}
}) .forEach(new Consumer<Book>() {
@Override
public void accept(Book book) {
System.out.println(book.getName()+"---"+book.getPrice()+"---"+
book.getAuthor());
}
});
}
}
class Book{
private String name;
private Double price;
private String author; //省略了无参有参构造及setter,getter方法
}
使用lambda表达式以后:
books.stream().filter(book -> book.getPrice()<60)
.sorted((o1, o2) -> (int) (o1.getPrice()-o2.getPrice()))
.forEach(System.out::println);
7、Stream流的一些中间操作
7.1 filter过滤
filter可以对流中的元素进行条件过滤,符合过滤条件的元素才能继续留在流中。
eg: 对于上述的书籍,打印出作者姓名长度大于3的书籍信息;
books.stream().filter((book)->book.getAuthor().length()>3)
.forEach(System.out::println);
7.2 map元素映射
map可以对流中元素进行计算和转换
eg: 现在书店打5折折扣,重新计算所有书籍价格;
books.stream().map(book -> {
book.setPrice(book.getPrice()*0.5);
return book;
}).forEach(System.out::println);
7.3 distinct元素去重
distinct对于元素的重复是按照Object的equals方法来判断的(使用==来比较应用存储地址),如果是自定义类型,需要重写equals方法。
books.stream().distinct().forEach(System.out::println);
7.4 sorted元素排序
sorted排序有两种重载方法,一种是无参的不过需要类实现Comparable接口,重写compareTo方法使其对象可以比较;另一种需要输入Comparator接口传入参数进行比较。
books.stream().sorted(new Comparator<Book>() {
@Override
public int compare(Book o1, Book o2) {
return (int) (o1.getPrice()-o2.getPrice());
}
})
7.4 limit限制流长度
limit限制流的长度,超出部分将会被抛弃,可以获取指定元素个数; 接收参数为long类型的整数,表示流的最大长度。
eg: 获取书店中价格最贵的书籍信息;
books.stream().distinct()
.sorted((o1,o2)-> (int)(o2.getPrice()-o1.getPrice()))
.limit(1)
.forEach(System.out::println);
7.5 skip跳过元素
skip(long n) 跳过前n个元素,返回剩下的元素
eg: 打印除了价格最大的书籍信息
books.stream().distinct()
.sorted((o1,o2)-> (int)(o2.getPrice()-o1.getPrice()))
.skip(1)
.forEach(System.out::println);
7.6 flatMap扁平化映射
先将元素扁平化处理(将一个数据分割成多个数据),在对每个元素映射
map只能把一个对象转换成另一个对象作为流中的元素,flatMap可以把一个对象转换为多个对象作为流中的元素。stream流是将集合中的元素展开一次,flatMap则相当于展开两次
eg1: 将author集合中的每个作者的书籍信息打印(一个作家可能有多个Book所以用flatMap)
class Author{
private String name;
private List<Book> books;
}
authors.stream().flatMap(new Function<Author, Stream<Book>>() {
@Override
public Stream<Book> apply(Author author) {
return author.getBooks().stream();
}
}).forEach(System.out::println);
--------
authors.stream().flatMap(author -> author.getBooks().stream())
.forEach(System.out::println);
eg2: 现在Book里面有个分类,比如“爱情”,比如“爱情,哲学”;需要把书籍所有分类打印出来,但不能出现“爱情,哲学”这种形式,需要分割开来展示
ArrayList<Author> authors = new ArrayList<>();
ArrayList<Book> book1 = new ArrayList<>();
book1.add(new Book("a1",23.2,"张三","爱情"));
book1.add(new Book("a2",13.2,"张三","爱情,讽刺文学"));
ArrayList<Book> book2 = new ArrayList<>();
book2.add(new Book("b1",1123.2,"李四","探案,恐怖"));
book2.add(new Book("b2",21113.2,"李四","历险"));
authors.add(new Author(("张三"),book1));
authors.add(new Author(("李四"),book2));
authors.stream().flatMap(author -> author.getBooks().stream())
.flatMap(book -> {
String category = book.getCategory();
return Arrays.stream(category.split(","));
}).forEach(System.out::println);
8、Stream的终结操作(只有终结操作才会开启整个流式计算)
8.1 forEach遍历
对流中的元素进行遍历操作,我们通过传入的参数去指定对遍历的元素进行什么具体操作。
eg: 输出所有作家的名字
authors.stream().forEach(author -> {
System.out.println(author.getName());
});
8.2 count计数
可以用来获取流中元素个数。
eg: 打印所有作家的书籍总数;
long count = authors.stream()
.flatMap(author -> author.getBooks().stream())
.distinct()
.count();
8.3 min&max
获取流中元素的最大最小值,接收Comparator接口实现比较器
eg: 打印书籍价格的最大、最小值
Optional<Book> min =
authors.stream().flatMap(author -> author.getBooks().stream())
.min((o1, o2) -> (int) (o1.getPrice() - o2.getPrice()));
System.out.println(min.get());
//max类似
8.4 reduce聚合
对流中的数据按照你指定好的计算方式计算出一个结果。
reduce的作用是把Stream中的元素组合起来,我们可以传入一个初始值,他会按照我们的计算方式依次获取流中元素在和初始值的基础上进行计算,计算结果在和后面元素计算。
reduce()方法传入的对象是BinaryOperator接口,它定义了一个apply()方法,负责把上次累加的结果和本次的元素进行运算,并返回累加的结果
//1.求集合中元素总和
ArrayList<Integer> list = new ArrayList<>();
for (int i=1;i<11;i++){
list.add(i);
}
Integer sum = list.stream().reduce(0, Integer::sum);
//这里reduce第一个参数是初始值
System.out.println(sum);
---------------------------
//2.用reduce求元素中最大值
Integer max = list.stream()
.reduce(list.get(0),result, element) -> result<element?element:result);
System.out.println(max);
如果去掉初始值,我们会得到一个Optional:
Optional opt = stream.reduce((result, element) -> result+element);
if (opt.isPresent()) {
System.out.println(opt.get());
}
这是因为Stream的元素没有了初始值有可能是0个元素,这样就没法调用reduce()的聚合函数了,因此返回Optional对象,需要进一步判断结果是否存在。
8.5 collect收集
把当前流中的元素转换为集合类型
eg: 对于上面获取所有书名的集合;
List<String> list = authors.stream()
.flatMap(author -> author.getBooks().stream())
.map(Book::getName)
.collect(Collectors.toList()); //转换为Set-->Collector.toSet();
list.forEach(System.out::println);
eg: 将author,Book存到HashMap<String,List<Book>>集合中:
Map<String, List<Book>> map = authors.stream()
.collect(Collectors.toMap(Author::getName, Author::getBooks));
8.6 anyMatch匹配
判断是否有符合匹配条件的元素,结果为boolean类型。只要有任意一个符合的结果就为true
eg: 是否有价格>500的书籍;
boolean b = authors.stream().flatMap(author -> author.getBooks().stream())
.anyMatch(book -> book.getPrice() > 500);
8.7 allMatch匹配
如果流中所有的元素都匹配成功,返回true,否则返回false
eg: 判断所有的书籍否都是由张三编写的;
boolean b = authors.stream().flatMap(author -> author.getBooks().stream())
.allMatch(book -> book.getName().equals("张三"));
8.8 noneMatch匹配
如果流中所有的元素都匹配不成功,返回true,否则返回false
eg: 判断书籍价格是否都没有超过100元;
boolean b = authors.stream().flatMap(author -> author.getBooks().stream())
.noneMatch(book -> book.getPrice() < 100);
8.9 findAny查找
获取流中的任意一个元素,该方法没有办法保证获取到的一定是流中的第一个元素。
eg: 获取一个书籍价格<100的书籍;
Optional<Book> books = authors.stream()
.flatMap(author -> author.getBooks().stream())
.filter(book -> book.getPrice() < 100)
.findAny();
books.ifPresent(System.out::println); //如果find成功就消费数据
8.10 findFirst查找
查找符合条件流中第一个元素。
eg: 查找书籍价格最低的书;
authors.stream().flatMap(author -> author.getBooks().stream())
.sorted((o1, o2) -> (int) (o1.getPrice() - o2.getPrice()))
.findFirst().ifPresent(System.out::println);
使用Stream流注意事项
- 惰性求值;如果没有终结操作,中间操作是不会执行的
- 流是一次性的;一旦一个流对象经过一次终结操作以后,这个流就不能在使用
- 流的操作不会影响原数据
9 Optional
我们在编写代码的时候出现最多的就是空指针异常,所以在很多情况下我们需要做各种非空的判断。而过多的非空判断就会让我们的代码显得非常臃肿,所以在jdk8中引入了Optional,养成Optional的习惯后可以写出更优雅的非空判断来避免空指针异常。
一般用法:
Object A=getObejct(); //通过一个方法获取对象很容易产生空指针异常
System.out.println(A.getXXX()); //这里先要做非空判断
------
Object A=getObejct();
if (A!=null){ //比较安全的写法
System.out.println(A.getXXX());
}
Optional就像是包装类,可以把我们的具体数据封装到Optional对象的属性中,然后去使用Optional封装好的方法操作这个数据进行非空判断。
创建Optional对象
一般使用Optional的静态方法ofNullable来把数据封装成一个Optional对象。
Optional<Object> A=Optional.ofNullable(getObject());
A.ifPresent(Consumer消费数据); ifPersent()判断对象是否存在
在确定对象不为空时可以用Optional.of(Object)静态方法封装成Optional对象,
该静态方法不能输入null。
安全消费值
获取到一个Optional对象以后肯定要对其中的数据进行使用,可以使用其ifPersent()方法对其中的值进行消费,其内部会对数据进行非空判断,空则不执行。
也可以用boolean类型的 isPersent()方法判断是否为空在操作,但是没必要可以直接使用if判空。
安全获取值
如果我们期望安全的获取值,不推荐使用OptionalObject.get()方法,因为Optional内部数据为空时会报异常。应当使用Optional提供的以下方法:
orElseGet、orElse
获取数据并且设置数据为空时的默认值。如果数据不为空就能获取到该数据,如果为空,则返回设置的默认值。不过orEsle函数接收的是同类型的对象,orElseGet是Supplier<? extends 传入的对象类型>的函数式接口。
Optional<Object> A=Optional.ofNullable(getObject());
A.orElseGet(Object::new); //如果Optional有就返回,没有就使用默认值
另:
A.orElse(new Object());
orElseThrow
获取数据,如果数据不为空就能获取到值,如果为空,则根据传入的参数来抛出异常。
public static void main(String[] args){
Optional<A> a = Optional.ofNullable(getA());
try {
a.orElseThrow(() -> new RuntimeException("数据为null"));
} catch (Throwable throwable) {
System.out.println("你好");
throwable.printStackTrace();
}
}
public static A getA(){
return null;
}
filter过滤和map类型转换
我们也可以对Optional对象进行过滤操作,使用根stream流类似,map同理;
Optional<Author> A=Optional.ofNullable(getAuthor());
Object a=A.orElseGet(Object::new);
Optional<Author> b=a.filter(author->author.getAge<30);
10、Stream流基本数据类型优化
Stream的很多方法涉及到的参数和返回值类型都是引用类型,如果使用stream操作基本数据类型,会导致进行大量的装箱、拆箱这个过程肯定会消耗时间。所以为了优化这部分时间,stream流提供了专门针对基本数据类型的方法。例如:
maptoInt, maptoLong, maptoDouble, flatMaptoInt, flatMaptoDouble等
eg: 计算上述书店书籍的平均价格:
DoubleStream doubleStream = authors.stream()
.flatMap(author -> author.getBooks().stream())
.mapToDouble(Book::getPrice); //内部只实行了一次拆箱
System.out.println(doubleStream.average().orElse(0));
11、并行流
之前流操作都是串行计算,当流中有大量元素时,我们可以使用并行流提高执行效率。并行流就是把任务分配给多个线程去执行。
调用parallel()方法使用并行流并行计算。
Stream<Integer> s = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer result = s.filter(num -> num > 5)
.parallel()
.reduce(Integer::sum)
.orElse(0);
System.out.println(result);
这里因为数据量少,并行化执行比串行执行慢,因为并行化还需要创建线程有消耗的时间,当数据量非常大时,多个线程执行肯定比一个线程执行更快。
12、反射(Reflection)
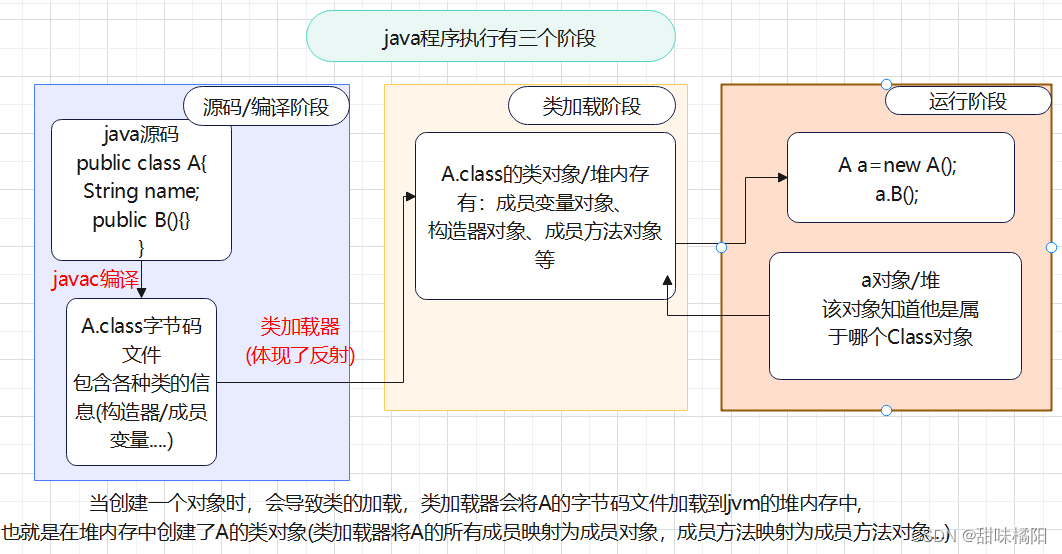
认识反射、获取类
在运行过程中,可以动态获取类的属性(比如idea中创建了一个类a,然后用访问修饰符 a.xxx 点操作,idea会自动弹出提示其对应的属性和方法)。加载类,并允许以编程的方式解析类中的各种成员(成员变量、方法、构造器等)。主要学习如何获取类的信息并操作他们。 主要做作用于框架中。
步骤:
- 1、加载类,获取字节码Class对象
- 2、获取类的构造器对象:Constructor对象
- 3、获取类的成员变量对象:Field对象
- 4、获取类的成员方法对象:Method对象
Class类
- Class类是一个特殊类,它用于表示JVM运行时类或接口的信息。
- Class类提供很多方法用于获取类的各种信息,比如获取类名、判断该类是否是一个接口还是普通类等等。
- Class类是通过类加载器的loadClass()方法创建的,是系统创建的,不是new创建的。
- 一个类在类加载时只加载一次,在内存中只有一份。(不管是new创建时加载还是反射时加载)
- 每个对象实例都会知道本身是属于哪个Class对象。(对象实例.class获取Class对象)
- Class对象是存放在对内存中的。
- 类的字节码二进制数据(元数据:包括方法代码,变量名,方法名,访问权限等)是存放在方法区中的。
- 通过Class对象可以获取类的所有结构信息。
获取Class对象的方式
- Class c1=类名.class
- 调用 Class.forName(全类名); 方法
- Object提供的方法:Class c1=对象.getClass()
public static void main(String[] args) {
Student s1 = new Student("jxh", 1);
Class<? extends Student> s1Class = s1.getClass();
System.out.println(Arrays.toString(s1Class.getMethods()));
Class<Student> studentClass = Student.class;
//System.out.println(studentClass.getName());//简名 全类名
// System.out.println(Arrays.toString(studentClass.getFields()));
//类的class对象只有一个,所以无论以何种方式获取都是同一个对象
System.out.println(s1Class==studentClass); //true
}
//获取构造器
Class<Student> studentClass = Student.class;
System.out.println(Arrays.toString(studentClass.getConstructors()));
for (Constructor<?> c:studentClass.getConstructors()) {
//只能获取public修饰的构造器
System.out.println("构造器名称:"+c.getName()+"\n参数个数:"+c.getParameterCount());
}
//获取全部的构造器无论是否是public修饰 class对象.getDeclaredConstructors();
//获取某一个构造器(也可以用getDeclaredConstructor())
System.out.println(studentClass.getConstructor()); //获取无参构造器
System.out.println(studentClass.getConstructor(String.class,Integer.class)); //获取有参构造器
获取类构造器的作用:将初始化对象返回
Student student = studentConstructor.newInstance(); //通过newInstance()返回初始化对象
System.out.println(student);
将类的构造器修饰符修改为private,则会报一个私有权限的异常;可以设置:
studentConstructor.setAccessible(true); //表示禁止检查访问控制
所以可以得出:反射是可以破坏类的封装性。
//获取成员变量
Field[] fields = studentClass.getDeclaredFields();
// 或者调用studentClass.getFields();
for (Field f:fields){
System.out.println(f.getName()+":"+f.getType());
}
//通过名字定位某个成员变量
Field name = studentClass.getDeclaredField("name");
System.out.println(name+":"+name.getType());
反射获取成员变量的作用:赋值、取值
Field f_name = studentClass.getDeclaredField("name");
System.out.println(f_name+":"+f_name.getType());
Student s1 = new Student("jxh", 1);
f_name.setAccessible(true); //因为name属性是私有的
f_name.set(s1,"你好"); //将s1的name修改为你好
System.out.println(s1);
System.out.println(f_name.get(s1));//获取s1对象的name
//获取所有方法
Method[] methods = studentClass.getDeclaredMethods();
for (Method m:methods){
System.out.println(m.getName()+":"+m.getParameterCount()+":"+m.getReturnType());
}
//获取某个方法对象(通过名字+参数定位)
Method setId = studentClass.getDeclaredMethod("setId", Integer.class);
System.out.println(setId.getReturnType() +":"+ setId.getName());
//通过反射获取方法的作用依然是执行
Student s2 = new Student("jxh", 2);
setId.invoke(s2,111); //触发方法执行
System.out.println(s2);
反射最重要的用途是:适合做java的框架,基本上,主流的框架都会基于反射设计出一些通用的功能。
使用反射做一个简易版的框架
需求:对于任意一个对象,该框架都可以将其所有字段名和值组装成JSON对象,保存到文件中去。
public class saveObjectFrame {
//目标:保存任意对象的字段的对象到文件中去
public static void saveObject(Object o) throws Exception {
PrintStream ps=new PrintStream(new FileOutputStream("G:\\data.txt",true));
Class<?> c = o.getClass();
//从类中提取全部成员变量
Field[] fields = c.getDeclaredFields();
ps.println("---------"+c.getSimpleName()+"-----------");
for (Field field : fields) {
//先获取成员变量的名字
String f_name = field.getName();
field.setAccessible(true);
//获取成员变量的值
String value = field.get(o)+"";
ps.println(f_name+"="+value);
}
ps.close();
}
}
反射的优点缺点
优点:可以动态的创建和使用对象(也是框架底层核心),使用灵活;没有反射机制框架技术就失去了底层支撑。
缺点:使用反射基本是解释执行,对执行速度有影响;也会破坏封装性。
动态加载、静态加载
反射机制是java实现动态语言的关键、也就是通过反射实现类动态加载。
静态加载:编译时加载相关的类,如果没有则报错,依赖性很强(通过new创建对象、调用静态成员、子类被加载时父类也加载等都是静态加载)。
动态加载:在运行时加载相关的类,如果运行时不用该类,即使不存在该类也不报错,降低了依赖性(反射是动态加载),懒人模式–用到了才加载。
13、注解(Annotation)
注解:是java代码中的一些特殊标记,比如@Override、@Test等;
作用是:让其他程序根据注解信息来决定怎么执行该程序。
自定义注解:
public @interface 注解名称{
public 属性类型 属性名() default 默认值;
}
特殊属性名:如果注解中有value属性且只有一个时,使用注解时,value名称可以不用写。
public @interface MyAnnotation {
public String hello() default "你好";
public boolean isRight();
public String[] arr();
}
@MyAnnotation(isRight = true,arr = {"html","java"})//数组赋值 {}
class test{
public static void main(String[] args) {
}
}
运行后将class文件反编译,可以得出:
- 注解的本质就是一个接口,继承了Annotation接口,其所有属性是该接口各个抽象方法。
- 使用时:@注解(…) 其实就是一个实现类对象,实现了该注解以及Annotation接口。
元注解:修饰注解的注解。
常用的有:@Target、@Retention两个元注解
@Target
用来声明被修饰的注解只能在那些地方使用。
@Target(value=ElemenetType.TYPE)
这个value值就表示当前被修饰的注解能用在哪里。
- TYPE: 类/接口
- FIELD:成员变量
- METHTOD:成员方法
- PARAMETER:方法参数中
- CONSTRUCTOR: 构造器中
- LOCAL_VARIABLE: 局部变量
import java.lang.annotation.ElementType;
import java.lang.annotation.Target;
/*
* 元注解的使用:Target
* */
@Target(value = ElementType.TYPE)
//表明当前修饰的注解只能作用在类/接口上
public @interface A1 {
public String name() default "jxh";
}
@A1
class Test{} //可以使用
---------
@A1
interface Test{} //也可以使用
使用在成员变量上时报错
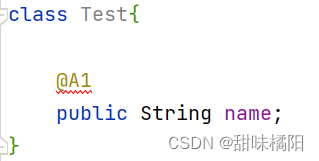
设置注解@A1可以在类/成员方法上使用:
@Target(value = {ElementType.TYPE,ElementType.METHOD})
//表明当前修饰的注解只能作用在类/接口上
public @interface A1 {
public String name() default "jxh";
}
@Retention
用来声明注解的保留周期。
@Retention(RetentionPolicy.RUNTIME)
- SOURCE: 只作用在源码阶段,字节码文件中不存在。
- CLASS (默认值): 保留到字节码文件阶段,运行阶段不存在。
- RUNTIME (开发常用): 一直保留到运行阶段。
/*
* 元注解的使用:Target、Retention
* */
@Target(value = {ElementType.TYPE,ElementType.METHOD})
//表明当前修饰的注解只能作用在类/接口上
@Retention(value = RetentionPolicy.RUNTIME)
//控制A1注解一直保留到运行阶段
public @interface A1 {
public String name() default "jxh";
}
14、注解的解析
就是判断类上、方法上、成员变量上是否存在注解,并把注解里的内容给解析出来。
- 如何解析注解:要解析谁上面的注解,就先拿到谁。
- 比如要解析类上面的注解就应该先获取该类的Class对象,在通过Class对象解析其上面的注解。
- 比如要解析成员方法上面的注解时应该获取该成员方法的Method对象, 在通过Method对象解析其上面的注解。其他类似…
- Class、Method、Field、Constructor都实现了AnnotatedElement接口,拥有解析注解的能力。
- AnnotatedElement接口解析注解的方法有:
getDeclaredAnnotations()获取当前对象上面的注解;getDeclaredAnnotation()获取指定的注解对象;isAnnotationPresent()判断你是否存在某个注解。

@Target(value = {ElementType.TYPE,ElementType.METHOD})
@Retention(value = RetentionPolicy.RUNTIME)
public @interface MyTest4 {
public String value();
public double aaa() default 100;
public String[] bbb();
}
----------
@MyTest4(value = "蜘蛛精",aaa = 99.5,bbb = {"你好","黑马"})
class Demo{
@MyTest4(value = "孙悟空",aaa = 199.9,bbb = {"ltt","解析注解"})
public void test1(){
}
}
//解析注解
class Test{
public static void main(String[] args) {
//获取要解析的类
Class<Demo> c = Demo.class;
//解析类上面的注解
//判断类上是否存在某个注解
if (c.isAnnotationPresent(MyTest4.class)){
System.out.println("yes");
MyTest4 myTest4 = c.getDeclaredAnnotation(MyTest4.class);
System.out.println(myTest4.value());
System.out.println(myTest4.aaa());
System.out.println(Arrays.toString(myTest4.bbb()));
}else System.out.println("no annotation");
}
}
注解的应用场景
一般是结合反射实现某个框架的功能。
模拟Junit测试框架
需求:定义若干个方法,只要加了@MyTest注解,就会触发该方法执行。
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import java.lang.reflect.Method;
@Target(value= ElementType.METHOD)
@Retention(value= RetentionPolicy.RUNTIME)
public @interface MyTest {
}
class Demo2{
@MyTest
public void t1(){
System.out.println("t1执行...");
}
public void t2(){
System.out.println("t2执行...");
}
@MyTest
public void t3(){
System.out.println("t3执行...");
}
public static void main(String[] args) throws Exception {
Class<Demo2> aClass = Demo2.class;
Demo2 demo2 = new Demo2();
Method[] methods = aClass.getDeclaredMethods();
for (Method m:methods){
if (m.isAnnotationPresent(MyTest.class)){
m.invoke(demo2);
}
}
}
}
//t3和t1执行
动态代理
程序为什么需要代理?代理长什么样?
比如:一个大明星,能唱歌会跳舞,在程序中也就是这个对象有唱歌和跳舞这两个方法,但是在唱歌之前需要准备话筒、收钱等,在跳舞之前要准备场地、收钱等。
但是这个明星显然不能去做准备话筒、准备场地这些工作,所以需要一个中间代理来负责这部分事情,明星只专注于唱歌、跳舞。
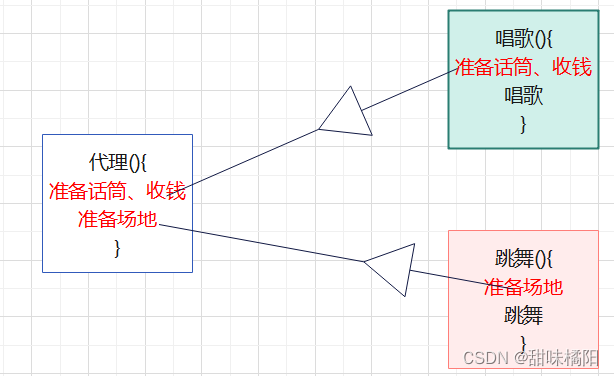
代理:Proxy,是一种设计模式,*提供了对目标对象另外的访问方式;即通过代理对象访问目标对象*.这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能
对象如果嫌身上做的事太多的话,可以通过代理来转移部分职责。
/**
* @author brett
* @date 2022-12-19 13:32:12
* @describe 明星类,该目标对象的核心功能
*/
public class BigStar implements Star{
private String name;
public BigStar(String name){
this.name=name;
}
public String sing(String sing_name){
System.out.println(this.name+"正在唱"+sing_name);
return "谢谢大家!";
}
public void dance(){
System.out.println(this.name+"正在优美的跳舞...");
}
}
通过接口的形式告诉代理对象要代理哪些方法
public interface Star {
public String sing(String name);
public void dance();
}
代理类对象:
public class ProxyUtil {
public static Star createProxy(BigStar star){
return (Star) Proxy.newProxyInstance(ProxyUtil.class.getClassLoader(),
new Class[]{Star.class}, new InvocationHandler() {
@Override //invoke是一个回调方法
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//代理对象要做的事情
if (method.getName().equals("sing")) {
System.out.println("准备话筒,收钱20W");
} else if (method.getName().equals("dance")) {
System.out.println("准备场地,收钱1000W");
}
return method.invoke(star, args);
}
});
}
}
测试:
public class Test {
public static void main(String[] args) {
BigStar star = new BigStar("杨超越");
Star starProxy = ProxyUtil.createProxy(star);
System.out.println(starProxy.sing("好日子"));
starProxy.dance();
}
}

动态代理应用
//获取所有用户
public List<Star> getAllUsers(){
long start_time = System.currentTimeMillis();
List<Star> re= UserService.getAllUsers();
long end_time = System.currentTimeMillis();
System.out.println("花费时间:"+(end_time-start_time)/1000.0+"s");
return re;
}
//删除所有用户
public void deleteAllUsers(){
long start_time = System.currentTimeMillis();
UserService.deleteAllUsers();
long end_time = System.currentTimeMillis();
System.out.println("花费时间:"+(end_time-start_time)/1000.0+"s");
}
从上述代码中可以看出统计耗时的功能与两个方法核心功能没有太大关系,所以可以使用代理方式将共同的方法分离出来,解耦合。
public interface UserService {
public void getAllUsers();
public void deleteAllUsers();
}
class ProxyUtil2 {
public static UserService createProxy(UserService userService){
return (UserService) Proxy.newProxyInstance(ProxyUtil2.class.getClassLoader(),
new Class[]{UserService.class},
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//实现需要代理的方法
if ("getAllUsers".equals(method.getName())||"deleteAllUsers".equals(method.getName())){
long start = System.currentTimeMillis();
method.invoke(userService,args);
Thread.sleep(300);
long end = System.currentTimeMillis();
System.out.println("花费时间:"+(end-start)/1000.0+"s");
System.out.println("==================================");
}else {
method.invoke(userService,args);
}
return null;
}
});
}
}
java IO流
流:java中所有数据都是使用流读写的。流是一组有序的数据序列,将数据从一端传输到另一端。根据数据流向的不同,可以分为输入流和输出流。
输入就是将数据从各种输入设备(文件、键盘等)中读取到内存中,输出则刚好相反 ,是将数据写入到各种输出设备(文件、显示器、磁盘等)。
例如键盘就是一个标准的输入设备,而显示器就是一个标准的输出设备,但是文件既可以作为输入设备,又可以作为输出设备。
数据流是java进行IO操作的对象,它按照不同的标准可以分为不同的类别。
- 按照流的方向主要分为输入流、输出流。
- 按照数据单位不同分为字节流、字符流。
- 按照功能可以分为节点流、处理流。
File类
文件:是以磁盘为载体保存在计算机中的信息集合;保存数据的地方。比如word文档,txt文本文档,excel文件…
常用的文件操作:
- 创建文件对象构造器和方法
- new File(String pathname) 根据路径创建一个File对象
- new File(File parent, String child) 根据父目录文件+子路径构建
- new File(String parent, String child) 根据父目录文件+子路径构建
- File对象.createNewFile() 创建新文件
demo1:在E盘下创建a.txt文件
public class FileTest {
public static void main(String[] args) {
// create1();
create2();
}
public static void create1(){
File file = new File("E:\\a.txt");
try {
boolean newFile = file.createNewFile();
if (newFile){
System.out.println("创建文件成功!");
}else System.out.println("创建文件失败!");
} catch (IOException e) {
e.printStackTrace();
}
}
public static void create2(){
File parent_file = new File("E:\\");
File aa = new File(parent_file, "aa.txt");
try {
if (aa.createNewFile()) {
System.out.println("创建成功!!");
}else System.out.println("创建失败!!");
} catch (IOException e) {
e.printStackTrace();
}
}
}
File对象获取文件信息的操作:
- getName() 获取文件名
- getAbsolutePath() 获取文件绝对路径
- getParent() 获取父级目录
- length() 文件大小(有多少字节)
- exists() 判断改文件/目录是否存在
- isFile() 判断是否s是文件
- isDirectory() 判断是否是目录
- delete() 删除文件
















 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









