







一.hadoop简介
(一)Hadoop起源于Google的三大论文
GFS:Google的分布式文件系统Google File System
MapReduce:Google的MapReduce开源分布式并行计算框架
BigTable:一个大型的分布式数据库
(二)演变关系
GFS—->HDFS
Google MapReduce—->Hadoop MapReduce
BigTable—->HBase
Hadoop名字不是一个缩写,是Hadoop之父Doug Cutting儿子毛绒玩具象命名的
(三)hadoop主流版本:
Apache基金会hadoop,后面的实验用的是这个3.2.1版本的
Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)
Hortonworks版本(Hortonworks Data Platform,简称“HDP”)

(四)Hadoop的框架最核心的设计就是:HDFS和MapReduce。
HDFS为海量的数据提供了存储。
MapReduce为海量的数据提供了计算。
(五)Hadoop框架包括以下四个模块:
Hadoop Common: 这些是其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的Java文件和脚本。
Hadoop YARN: 这是一个用于作业调度和集群资源管理的框架。
Hadoop Distributed File System (HDFS): 分布式文件系统,提供对应用程序数据的高吞吐量访问。
Hadoop MapReduce:这是基于YARN的用于并行处理大数据集的系统
(六)hadoop应用场景:
在线旅游 移动数据 电子商务 能源开采与节能 基础架构管理 图像处理 诈骗检测 IT安全 医疗保健

二.HDFS简介
运维的话,资源管理层及下面的,特别是hdfs分布式文件系统,是整个大数据体系的基石.
1.HDFS属于Master与Slave结构。一个集群中只有一个NameNode,可以有多个DataNode。
2.HDFS存储机制保存了多个副本,当写入1T文件时,我们需要3T的存储,3T的网络流量带宽;系统提供容错机制,副本丢失或宕机可自动恢复,保证系统高可用性。
3.HDFS默认会将文件分割成block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,会导致内存的负担很重。
4.HDFS采用的是一次写入多次读取的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能
5.HDFS存储理念是以最少的钱买最烂的机器并实现最安全、难度高的分布式文件系统(高容错性低成本),HDFS认为机器故障是种常态,所以在设计时充分考虑到单个机器故障,单个磁盘故障,单个文件丢失等情况。
6.HDFS容错机制:
节点失败监测机制:DN每隔3秒向NN发送心跳信号,10分钟收不到,认为DN宕机。
通信故障监测机制:只要发送了数据,接收方就会返回确认码。
数据错误监测机制:在传输数据时,同时会发送总和校验码
三.hdfs部署
官网部署参考
必须安装Java;必须安装ssh并且必须运行sshd才能使用管理远程Hadoop守护程序的Hadoop脚本
server1
get hadoop-3.2.1.tar.gz jdk-8u181-linux-x64.tar.gz
useradd -u 1001 hadoop
mv * /home/hadoop/
su - hadoop
tar zxf hadoop-3.2.1.tar.gz
tar zxf jdk-8u181-linux-x64.tar.gz
ln -s jdk1.8.0_181/ java
ln -s hadoop-3.2.1 hadoop
cd hadoop/etc/hadoop/
vim hadoop-env.sh
54 export JAVA_HOME=/home/hadoop/java #设置为Java安装的根目录
58 export HADOOP_HOME=/home/hadoop/hadoop
(一)本地独立运行
server1
cd /home/hadoop/hadoop
mkdir input
cp etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
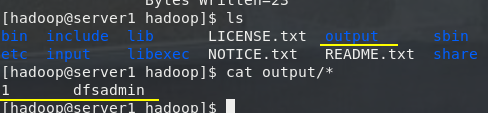
(二)伪分布式操作
Hadoop也可以以伪分布式模式在单节点上运行,其中每个Hadoop守护程序都在单独的Java进程中运行
echo westos | passwd --stdin hadoop
su - hadoop
cd /home/hadoop/hadoop/etc/hadoop
vim core-site.xml
19 <configuration>
20 <property>
21 <name>fs.defaultFS</name>
22 <value>hdfs://localhost:9000</value> #nodename
23 </property>
24 </configuration>
vim hdfs-site.xml
19 <configuration>
20 <property>
21 <name>dfs.replication</name>
22 <value>1</value> #副本数
23 </property>
24 </configuration>
[hadoop@server1 hadoop]$ cat workers #数据节点
localhost
ssh-keygen
ssh-copy-id localhost
vim ~/.bash_profile #/home/hadoop/hadoop/bin格式化脚本,写入环境变量
source ~/.bash_profile
hdfs namenode -format #格式化文件系统
ll /tmp #数据目录

vim ~/.bash_profile #/home/hadoop/hadoop/sbin 运行脚本
source ~/.bash_profile
start-dfs.sh #启动NameNode守护程序和DataNode守护程序

vim ~/.bash_profile #/home/hadoop/java/bin, java脚本
source ~/.bash_profile
jps
hdfs dfsadmin -report
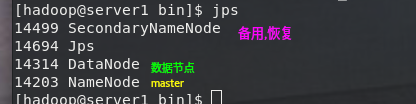

[hadoop@server1 ~]$ hdfs dfs -mkdir -p /user/hadoop #设置执行MapReduce作业所需的HDFS目录,hadoop=<用户名>
cd /home/hadoop/hadoop
hdfs dfs -put input #将输入文件复制到分布式文件系统中
hdfs dfs -ls
hdfs dfs -ls input #查看
hdfs dfs -get input #下载


172.25.2.1:9870


[hadoop@server1 hadoop]$ hdfs dfs -rm -r input
Deleted input
stop-dfs.sh #停止服务
(三)全分布式运行
[root@server1 ~]#yum install nfs-utils -y
vim /etc/exports
/home/hadoop/ *(rw,anonuid=1001,anonuid=1001)
systemctl start nfs
server2 3
useradd -u 1001 hadoop
yum install nfs-utils -y
showmount -e 172.25.2.1
mount 172.25.2.1:/home/hadoop/ /home/hadoop/
server1
su - hadoop
cd /home/hadoop/hadoop/etc/hadoop
vim core-site.xml
19 <configuration>
20 <property>
21 <name>fs.defaultFS</name>
22 <value>hdfs://server1:9000</value> #nodename
23 </property>
24 </configuration>
vim hdfs-site.xml
19 <configuration>
20 <property>
21 <name>dfs.replication</name>
22 <value>2</value> #两个副本
23 </property>
24 </configuration>
vim workers #数据节点
server2
server3
hdfs namenode -format
cd /home/hadoop/hadoop/sbin
./start-dfs.sh
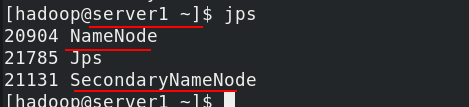
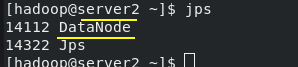

server1
hdfs dfs -mkdir -p /user/hadoop
hdfs dfs -mkdir input
cd /home/hadoop/hadoop/etc/hadoop
hdfs dfs -put * input


1.数据节点的热添加
server4
yum install nfs-utils -y
useradd -u 1001 hadoop
mount 172.25.2.1:/home/hodoop/ /home/hadoop/
su - hadoop
ssh server4
cd /home/hadoop/hadoop/etc/hadoop/
vim workers
server2
server3
server4
hdfs --daemon start datanode

[hadoop@server4 ~]$ hdfs dfs -put jdk-8u181-linux-x64.tar.gz


2.数据节点的热删除
server1
cd /home/hadoop/hadoop/sbin
./stop-dfs.sh
cd /home/hadoop/hadoop/etc/hadoop
vim hdfs-site.xml
19 <configuration>
20 <property>
21 <name>dfs.replication</name>
22 <value>2</value>
23 </property>
24 <property>
25 <name>dfs.hosts.exclude</name>
26 <value>/home/hadoop/hadoop/etc/hadoop/exclude</value>
27 </property>
28 </configuration>
vim exclude
server3
cd /home/hadoop/hadoop/sbin
./start-dfs.sh
hdfs dfsadmin -refreshNodes
hdfs dfsadmin -report

[root@server3 ~]# hdfs --daemon stop datanode

hadoop原理漫画
接下来也可以做一下hdfs的高可用和yarn的高可用















 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









