






一、前提声明
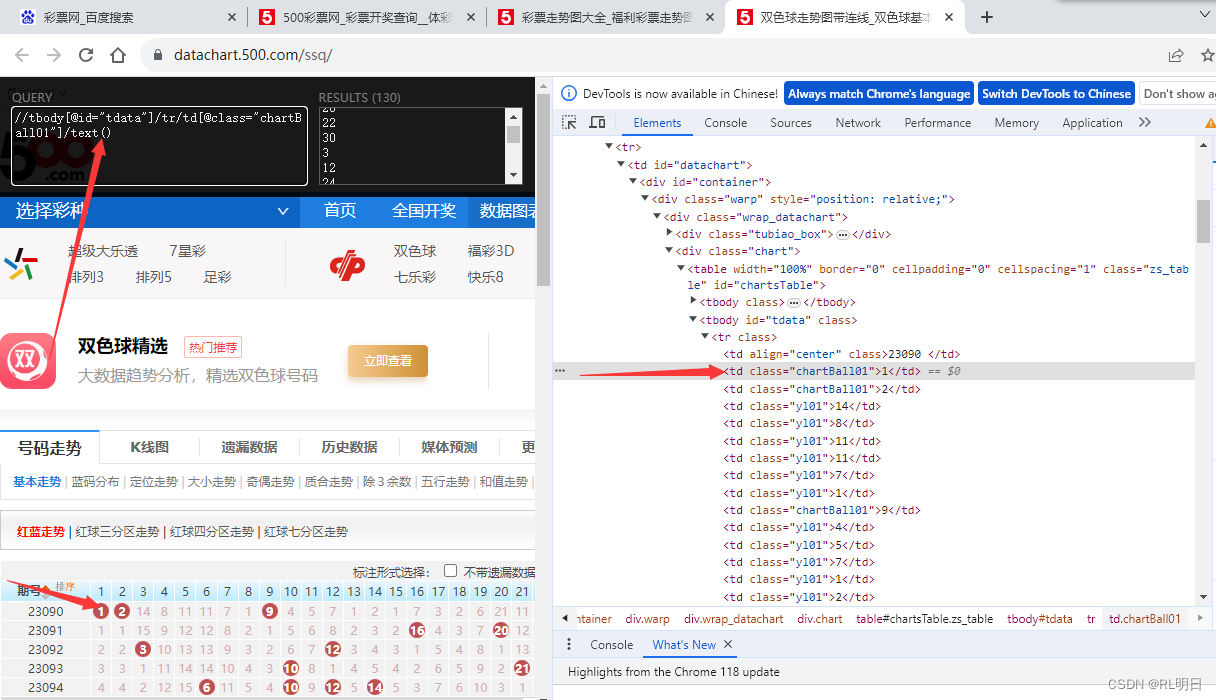
1、高亮显示的双色球xpath路径
//tbody[@id="tdata"]/tr/td[contains(@class,'chartBall01')]/text() = //tbody[@id="tdata"]/tr/td[@class="chartBall01"]/text()
<> text <> :<><>两者之间是文本信息,加上/text()没有问题
2、数据解析

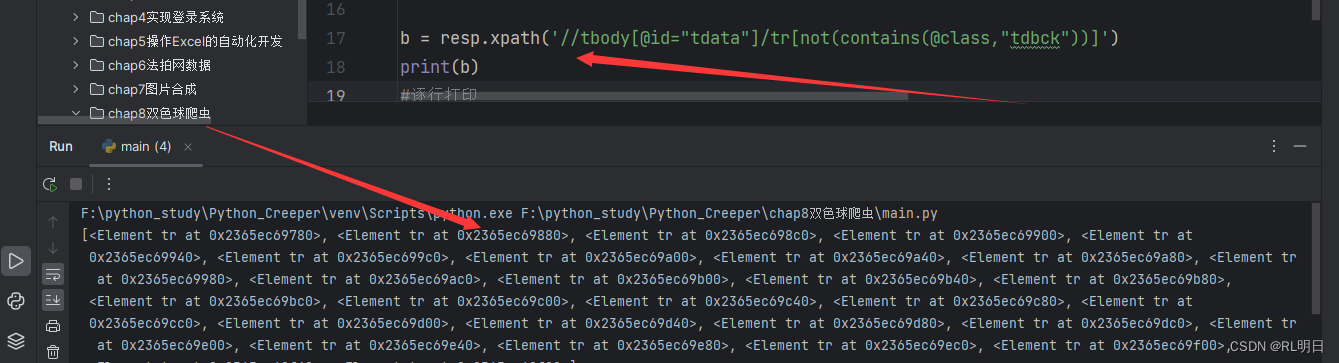
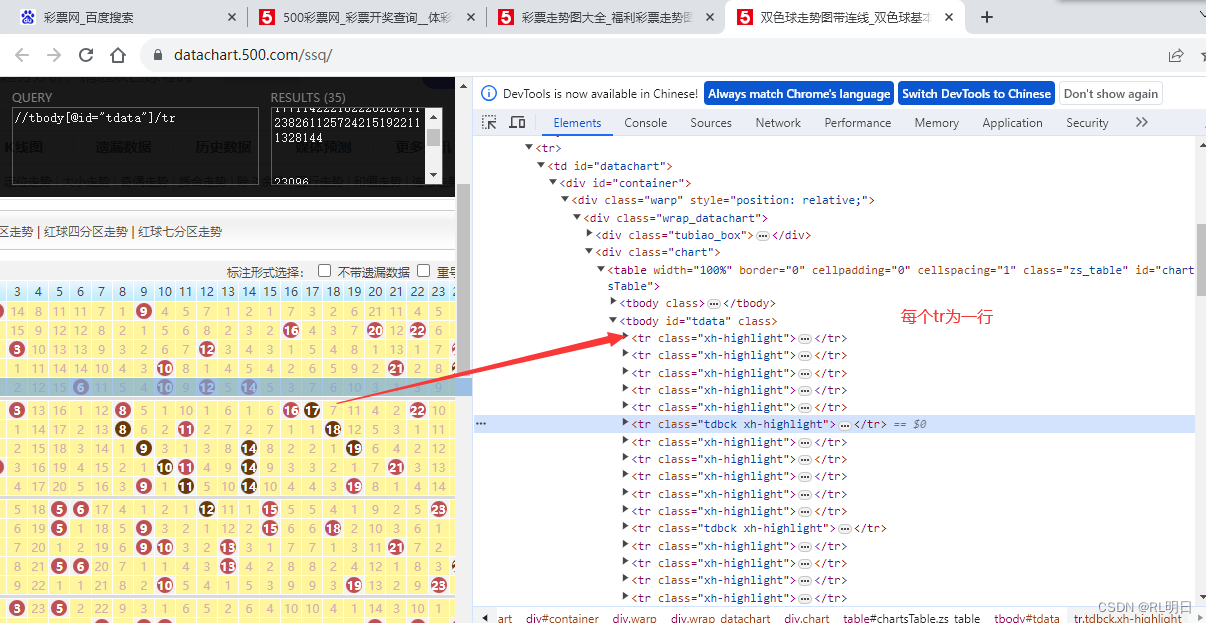
for tr in resp.xpath('//tbody[@id="tdata"]/tr[not(contains(@class,"tdbck"))]')
每个tr为一行:输出为:
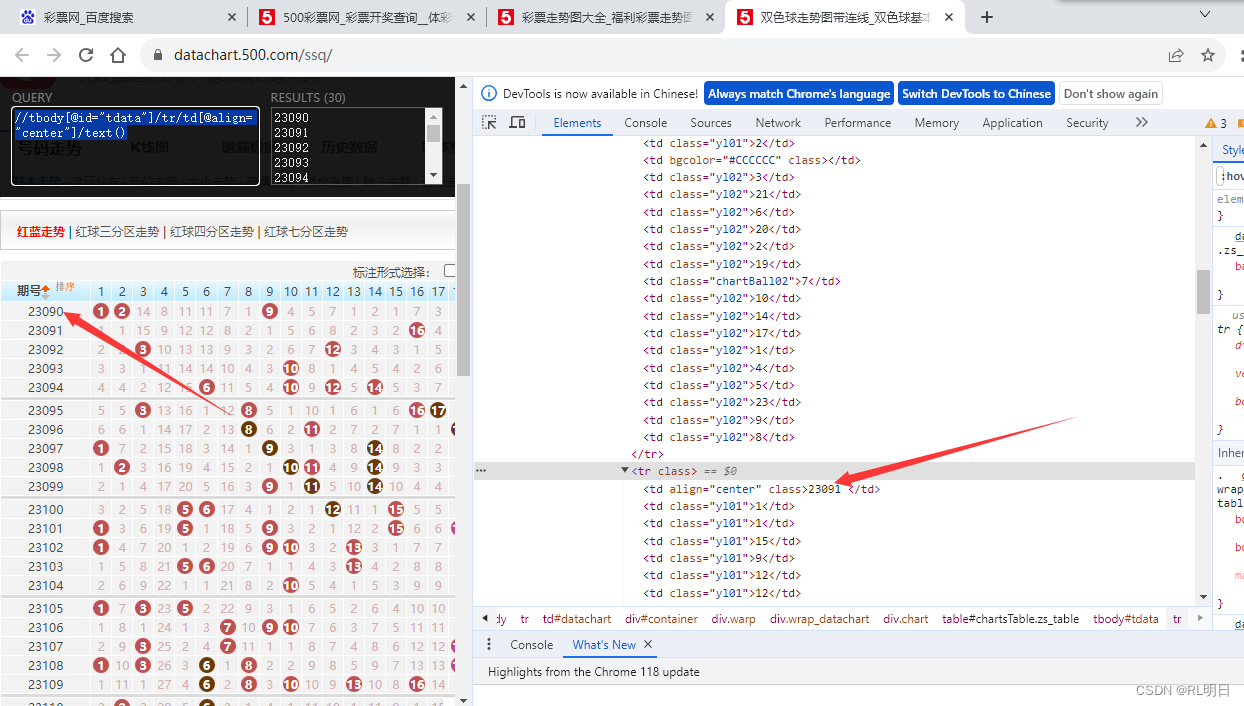
期数xpath路径
二、完整代码及运行结果
1、代码
import requests
from lxml import etree
#发送请求
url = 'https://datachart.500.com/ssq/'
heardes = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}
#获取结果
respond = requests.get(url,headers=heardes)
respond.encoding = 'gbk'
resp = etree.HTML(respond.text)
a = resp.xpath('//tbody[@id="tdata"]/tr/td[@class="chartBall01"]/text()')
b = resp.xpath('//tbody[@id="tdata"]/tr[not(contains(@class,"tdbck"))]')
print(b)
#逐行打印
reds = [tr.xpath('./td[contains(@class,"chartBall01")]/text()') for tr in resp.xpath('//tbody[@id="tdata"]/tr[not(contains(@class,"tdbck"))]')] #数据过滤以及提取
"""
列表推导式,相当于
for tr in resp.xpath('//tbody[@id="tdata"]/tr[not(contains(@class,"tdbck"))]'):
print(tr.xpath('./td[contains(@class,"chartBall01")]/text()')
"""
blues = resp.xpath('//tbody[@id="tdata"]/tr/td[@class="chartBall02"]/text()')
title = resp.xpath('//tbody[@id="tdata"]/tr/td[@align="center"]/text()')
for t,r,b in zip(title,reds,blues):
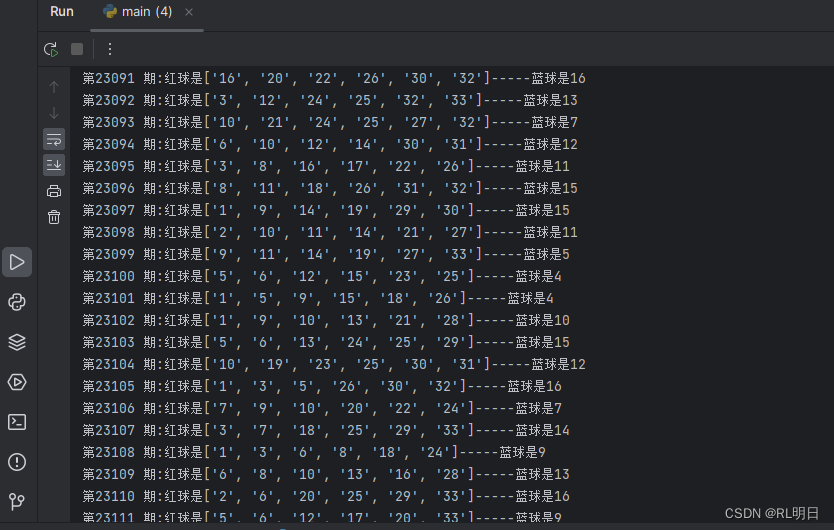
print(f'第{t}期:红球是{r}-----蓝球是{b}')
#处理结果2、运行结果

















 5624
5624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









