









从浏览器地址栏输入 url 到请求返回发生了什么
先阅读篇文章:从输入 URL 开始建立前端知识体系。
DNS 域名解析。(字节面试 DNS原理 )
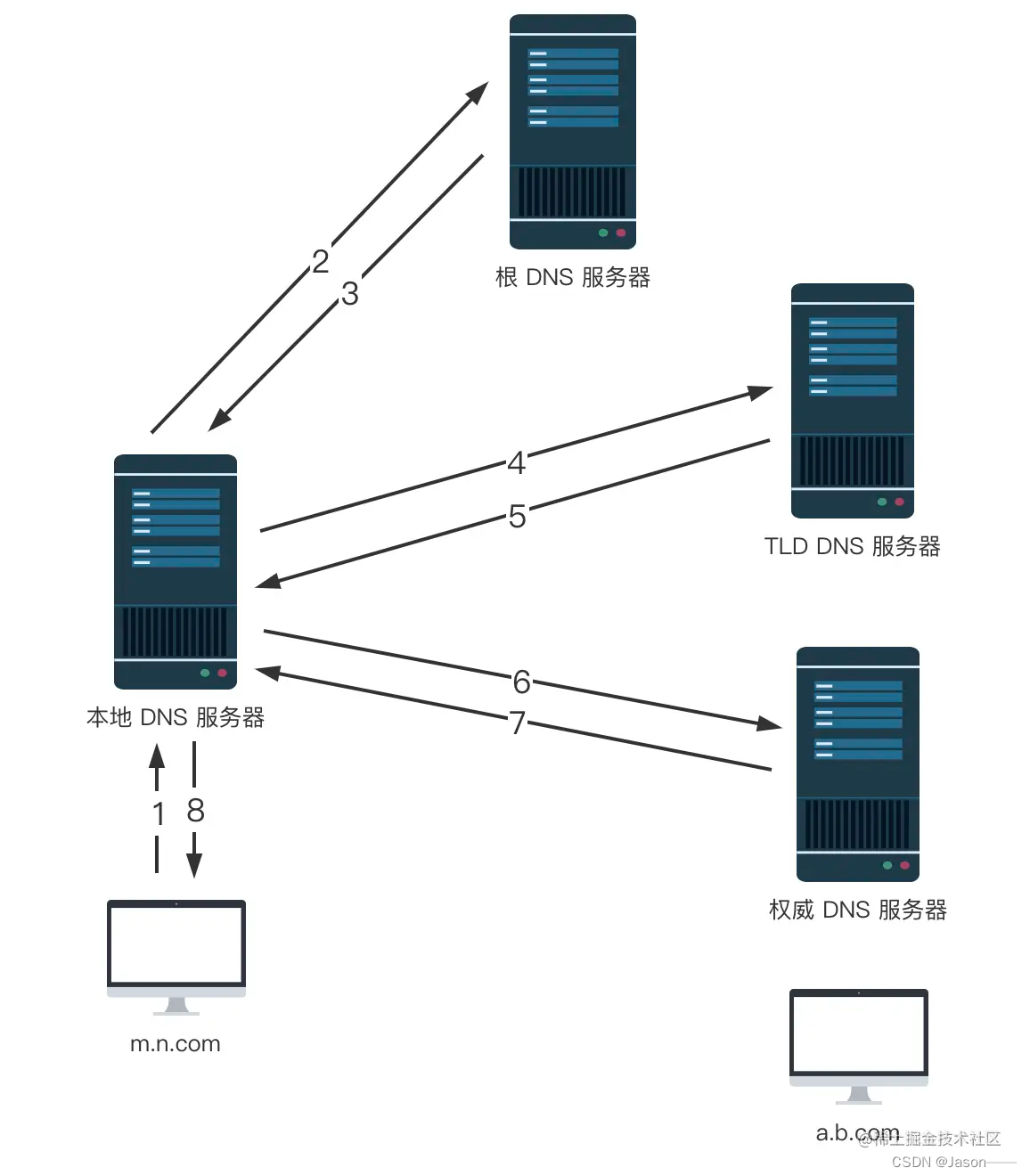
DNS解析说白就是问DNS服务器询问IP是多少,以下为查询流程:
主机 m.n.com 想要获取主机 a.b.com 的 IP 地址,会经过以下几个步骤(递归查询与迭代查询):
● 首先,主机 m.n.com 向它的本地 DNS 服务器发送一个 DNS 查询报文,其中包含期待被转换的主机名 a.b.com;
● 本地 DNS 服务器将该报文转发到根 DNS 服务器;
● 该根 DNS 服务器注意到 com 前缀,便向本地 DNS 服务器返回 com 对应的顶级域 DNS 服务器(TLD)的 IP 地址列表。意思就是,我不知道 a.b.com 的 IP,不过这些 TLD 服务器可能知道,你去问他们吧;
● 本地 DNS 服务器则向其中一台 TLD 服务器发送查询报文;
● 该 TLD 服务器注意到 b.com 前缀,便向本地 DNS 服务器返回权威 DNS 服务器的 IP 地址。意思就是,我不知道 a.b.com 的 IP,不过这些权威服务器可能知道,你去问他们吧;
● 本地 DNS 服务器又向其中一台权威服务器发送查询报文;
● 终于,该权威服务器返回了 a.b.com 的 IP 地址;
● 本地 DNS 服务器将 a.b.com 跟 IP 地址的映射返回给主机 m.n.com,m.n.com 就可以用该 IP 向 a.b.com 发送请求啦。
DNS解析重点
总结,TLD一定知道DNS服务器的IP吗?
不一定,有些时候TLD只知道中间的某个DNS服务器,再由中间DNS服务器去找权威DNS服务器。这时候, 整个查询过程就需要更多DNS报文。
DNS缓存
为了能让我们尽快拿到ip,DNS广泛使用了缓存技术。原理就是在查询过程中,当一台DNS服务器接受到一
个DNS应答时,它就能够将映射缓存到本地,但是缓存不是永久的,每一条映射记录都有对应生存时间,所
以有了缓存,大多数DNS查询都绕过了跟服务器。
TCP链接
TCP 连接。总是要问:为什么需要三次握手,两次不行吗?其实这是由 TCP 的自身特点可靠传输决定的。客户端和服务端要进行可靠传输,那么就需要确认双方的接收和发送能力。第一次握手可以确认客服端的发送能力,第二次握手,确认了服务端的发送能力和接收能力,所以第三次握手才可以确认客户端的接收能力。不然容易出现丢包的现象。
http 请求。
服务器处理请求并返回 HTTP 报文。
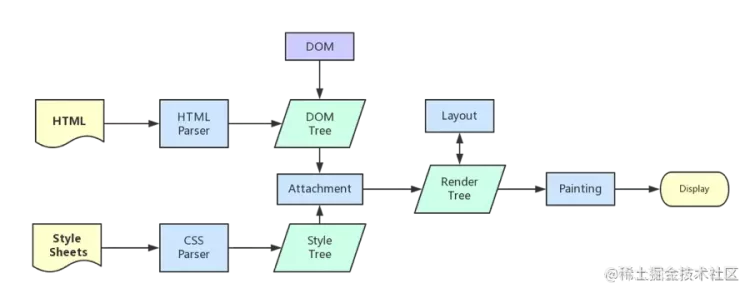
浏览器渲染页面。
- 解析HTML,构建DOM树
- 解析CSS,生成CSS规则树
- 合并DOM树和CSS规则,生成render树
- 布局render树(Layout/reflow),负责各元素尺寸、位置的计算
- 绘制render树(paint),绘制页面像素信息
断开 TCP 连接。
TCP四次挥手
浏览器的垃圾回收机制
这里看这篇文章即可:「硬核 JS」你真的了解垃圾回收机制吗。
有两种垃圾回收策略
● 标记清除:标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁。
● 引用计数:它把对象是否不再需要简化定义为对象有没有其他对象引用到它。如果没有引用指向该对象(引用计数为 0),对象将被垃圾回收机制回收。
标记清除的缺点:
● 内存碎片化,空闲内存块是不连续的,容易出现很多空闲内存块,还可能会出现分配所需内存过大的对象时找不到合适的块。
● 分配速度慢,因为即便是使用 First-fit 策略,其操作仍是一个 O(n) 的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢。
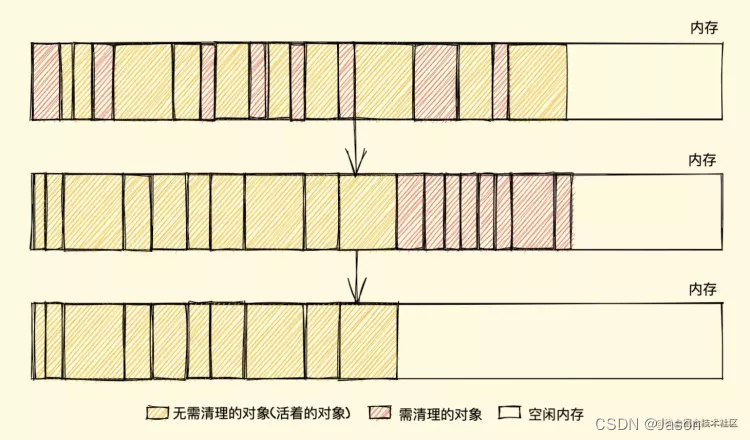
解决以上的缺点可以使用 **标记整理(Mark-Compact)算法 **,标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存(如下图)
引用计数的缺点
● 需要一个计数器,所占内存空间大,因为我们也不知道被引用数量的上限。
● 解决不了循环引用导致的无法回收问题。
V8 的垃圾回收机制也是基于标记清除算法,不过对其做了一些优化
● 针对新生区采用并行回收。
● 针对老生区采用增量标记与惰性回收。
HTTP
状态码分类
● 1xx - 服务器收到请求。
● 2xx - 请求成功,如 200。
● 3xx - 重定向,如 302。
● 4xx - 客户端错误,如 404。
● 5xx - 服务端错误,如 500。
常见状态码
● 200 - 成功。
● 301 - 永久重定向(配合 location,浏览器自动处理)。
● 302 - 临时重定向(配合 location,浏览器自动处理)。
● 304 - 资源未被修改。
● 403 - 没权限。
● 404 - 资源未找到。
● 500 - 服务器错误。
● 504 - 网关超时。
HTTP缓存

关于缓存
什么是缓存? 把一些不需要重新获取的内容再重新获取一次
为什么需要缓存? 网络请求相比于 CPU 的计算和页面渲染是非常非常慢的。
哪些资源可以被缓存? 静态资源,比如 js css img。
三种刷新操作对 http 缓存的影响
● 正常操作:地址栏输入 url,跳转链接,前进后退等。
● 手动刷新:f5,点击刷新按钮,右键菜单刷新。
● 强制刷新:ctrl + f5,shift+command+r。
正常操作:强制缓存有效,协商缓存有效。手动刷新:强制缓存失效,协商缓存有效。强制刷新:强制缓存失效,协商缓存失效。
更多问题推荐:
HTTP 灵魂之问,巩固你的 HTTP 知识体系。
HTTPS 底层原理,面试官直接下跪,唱征服!
JS
原型链?原型?
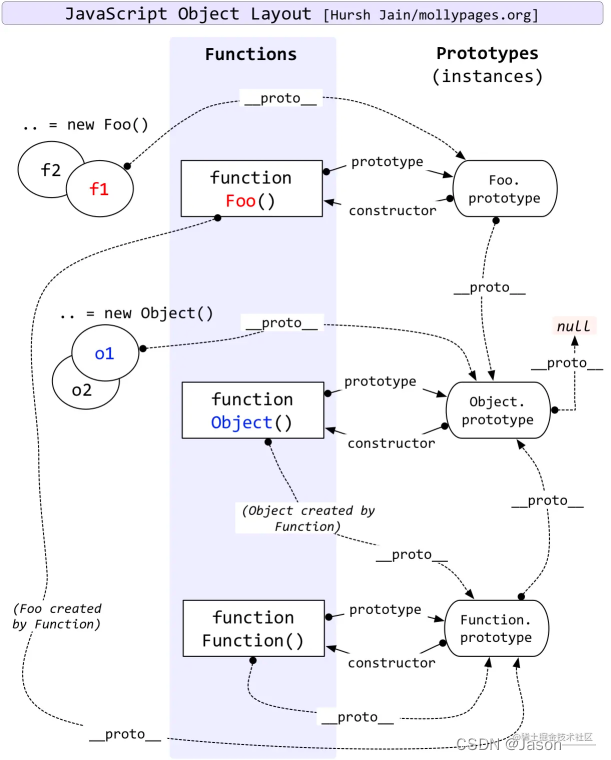
所有的函数都用一个prototype属性,所有的引用类型都有一个__proto__属性,__proto__属性指向它的原型对象上的prototype属性。当我们查找一个属性的时候,在本身没有找到该属性,就会去找它的__proto__属性,也就是它的构造函数的prototype属性,就这样一直向上查找,直到找到该属性;如果查找到Object依旧没有找到,就返回null。
推荐阅读:js深入之从原型到原型链
事件循环机制eventLoop
js是单线程执行的,异步的代码js是怎么处理
- js中执行任务分为微任务与宏任务,这两个队伍分别维护一个队伍,均采用先进先出的策略进行执行!
- 宏任务主要有script(整体代码)、setTimeout、setInterval、I/O、UI 交互事件、postMessage、MessageChannel、setImmediate(Node.js 环境)。
- 微任务主要有:Promise.then、 MutationObserver、 process.nextTick(Node.js 环境)。
任务执行原理顺序
4. 先取第一个宏任务进行执行;
5. 在执行中遇到微任务将其添加到微任务队列;
6. 宏任务执行完毕后,微任务的队列是否存在任务,若存在,在自上而下执行,直到执行完毕;
7. GUI渲染;
8. 回到第一个宏任务,直到执行宏任务完毕;
JS数据类型
8中数据类型: undefined、Null、Boolean、Number、String、Object、Symbol、BigInt;
Es6新增数据类型:
Symbol 代表独一无二的值,一般用于定义对象唯一的属性名;
BigInt 可以表示任意大小的整数;
手写深拷贝
/**
* 深拷贝
* @param {Object} obj 要拷贝的对象
* @param {Map} map 用于存储循环引用对象的地址
*/
function deepClone(obj = {}, map = new Map()) {
if (typeof obj !== "object") {
return obj;
}
if (map.get(obj)) {
return map.get(obj);
}
let result = {};
// 初始化返回结果
if (
obj instanceof Array ||
// 加 || 的原因是为了防止 Array 的 prototype 被重写,Array.isArray 也是如此
Object.prototype.toString(obj) === "[object Array]"
) {
result = [];
}
// 防止循环引用
map.set(obj, result);
for (const key in obj) {
// 保证 key 不是原型属性
if (obj.hasOwnProperty(key)) {
// 递归调用
result[key] = deepClone(obj[key], map);
}
}
// 返回结果
return result;
}
*克隆函数
1.我们可以通过prototype来区分下箭头函数和普通函数,因为箭头函数没有prototype;
2.箭头函数我们可以直接用 evel 生成一个箭头函数,但不实用普通函数;
3.处理普通函数分别使用正则取出函数体和函数参数,然后使用new Function ([arg1[, arg2[, ...argN]],]
functionBody)构造函数重新构造一个新的函数;
//eval函数用法
var jsonStr='{j:1, s:2, o:3, n:4}';
console.log(jsonStr.j); //undefined
var jsonObj=eval("("+jsonStr+")");//转换为json对象
console.log(jsonObj.j); //1
//案例
function cloneFunction(func) {
const bodyReg = /(?<={)(.|\n)+(?=})/m;
const paramReg = /(?<=\().+(?=\)\s+{)/;
const funcString = func.toString();
if (func.prototype) {
console.log('普通函数');
const param = paramReg.exec(funcString);
const body = bodyReg.exec(funcString);
if (body) {
console.log('匹配到函数体:', body[0]);
if (param) {
const paramArr = param[0].split(',');
console.log('匹配到参数:', paramArr);
return new Function(...paramArr, body[0]);
} else {
return new Function(body[0]);
}
} else {
return null;
}
} else {
return eval(funcString);
}
}
Promise深入分析
Promise深入面试题从小白到大神:要就来45道Promise面试题一次爽到底 🌟🌟🌟
● Promise的状态一经改变就不能再改变。
● .then和.catch都会返回一个新的Promise。
● catch不管被连接到哪里,都能捕获上层未捕捉过的错误。
● 在Promise中,返回任意一个非 promise 的值都会被包裹成 promise 对象,例如return 2会被包装为return Promise.resolve(2)。
● Promise 的 .then 或者 .catch 可以被调用多次, 但如果Promise内部的状态一经改变,并且有了一个值,那么后续每次调用.then或者.catch的时候都会直接拿到该值。
● .then 或者 .catch 中 return 一个 error 对象并不会抛出错误,所以不会被后续的 .catch 捕获。
● .then 或 .catch 返回的值不能是 promise 本身,否则会造成死循环。
● .then 或者 .catch 的参数期望是函数,传入非函数则会发生值透传。
● .then方法是能接收两个参数的,第一个是处理成功的函数,第二个是处理失败的函数,再某些时候你可以认为catch是.then第二个参数的简便写法。
● .finally方法也是返回一个Promise,他在Promise结束的时候,无论结果为resolved还是rejected,都会执行里面的回调函数
Promise中的all和race
● Promise.all()的作用是接收一组异步任务,然后并行执行异步任务,并且在所有异步操作执行完后才执行回调。
● .race()的作用也是接收一组异步任务,然后并行执行异步任务,只保留取第一个执行完成的异步操作的结果,其他的方法仍在执行,不过执行结果会被抛弃。
● Promise.all().then()结果中数组的顺序和Promise.all()接收到的数组顺序一致。
● all和race传入的数组中如果有会抛出异常的异步任务,那么只有最先抛出的错误会被捕获,并且是被then的第二个参数或者后面的catch捕获;但并不会影响数组中其它的异步任务的执行
await和promise区别
- await会阻塞后面代码执行;
- promise不会阻塞后面的同步代码;
//大厂面试题
//串行执行每一秒执行一次
const arr = [1, 2, 3]
arr.reduce((p, x) => {
return p.then(() => {
return new Promise(r => {
setTimeout(() => r(console.log(x)), 1000)
})
})
}, Promise.resolve())
防抖实现
//防抖
const debounce = (fn, delay) => {
let timer;
return (...args) => {
if (timer) {
// 取消上一次的定时器
clearTimeout(timer);
}
timer = setTimeout(() => {
fn.apply(this, args)
}, delay);
};
}
节流实现
//节流
const throttle = (fn, interval) => {
let timer;
return function (...args) {
if (!timer) {
timer = setTimeout(() => {
fn.apply(this, args);
timer = null;
}, interval)
}
}
}
闭包
三大特点
- 函数嵌套函数;
- 外部函数可以访问内部函数的变量;
- 参数和变量不会被垃圾回收机制回收;
闭包优缺点
优点
- 可以将一个变量长期存储在内存中,用于缓存
- 可以避免全局变量的污染
- 加强封装性,实现了对变量的隐藏和封装
缺点
- 因为函数执行上下文AO执行完后不被释放,所以会导致内存消耗很大,增加了内存消耗量,影响网页性能出现问题;
- 而且过度的使用闭包可能会导致内存泄露,或程序加载运行过慢卡顿等问题出现。
总结:在退出函数之前,将不再使用的局部变量进行删除;
跨域原理及解决办法
● 跨域是由浏览器的同源策略造成的,所谓同源,即域名、协议、端口均相同。
● CORS(跨来源资源共享),通过添加HTTP头信息,使浏览器判断是否可以发起跨域访问。
● 浏览器将跨域请求分为两类:简单请求和非简单请求。简单请求采取先请求后判断的方式,非简单请求采取预检请求的方式判断是否允许跨域访问。
● 解决跨域通常采用服务端代理转发和配置CORS两种方式
推荐:聊聊跨域的原理
React
函数式编程的理解
React.useCallback() 和 React.useMemo() 的区别
useCallback 可缓存函数,其实就是避免每次重新渲染后都去重新执行一个新的函数。
useMemo 可缓存值。
有很多时候,我们在 useEffect 中使用某个定义的外部函数,是要添加到 deps 数组中的,如果不用 useCallback 缓存,这个函数在每次重新渲染时都是一个完全新的函数,也就是引用地址发生了变化,这就会导致 useEffect 总会无意义的执行。
React dom diff 算法
让虚拟 DOM 和 DOM-diff 不再成为你的绊脚石。
React 性能优化手段
推荐文章:React 性能优化的 8 种方式了解一下?
● 使用 React.memo 来缓存组件。
● 使用 React.useMemo 缓存大量的计算。
● 避免使用匿名函数。
● 利用 React.lazy 和 React.Suspense 延迟加载不是立即需要的组件。
● 尽量使用 CSS 而不是强制加载和卸载组件。
● 使用 React.Fragment 避免添加额外的 DOM。
React Redux
Redux 包教包会(一):介绍 Redux 三大核心概念
Webpack
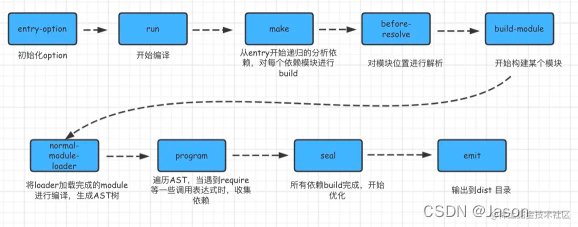
webpack理解
webpack是一个模块化打包工具,可以使用它管理项目中模块的依赖关系,并编译输出模块所需的静态文件。
它可一很好的管理、打包开发中所用到的html、css、js和静态文件等,让开发更高效。对于不同类型的依赖,webpack有对应模块的加载器,最会合并生成优化的静态资源。
webpack的基本功能和工作原理?
● 代码转换:TypeScript 编译成 JavaScript、SCSS 编译成 CSS 等等
● 文件优化:压缩 JavaScript、CSS、HTML 代码,压缩合并图片等
● 代码分割:提取多个页面的公共代码、提取首屏不需要执行部分的代码让其异步加载
● 模块合并:在采用模块化的项目有很多模块和文件,需要构建功能把模块分类合并成一个
文件
● 自动刷新:监听本地源代码的变化,自动构建,刷新浏览器
● 代码校验:在代码被提交到仓库前需要检测代码是否符合规范,以及单元测试是否通过
● 自动发布:更新完代码后,自动构建出线上发布代码并传输给发布系统。
webpack构建过程
● 从entry里配置的module开始递归解析entry依赖的所有module
● 每找到一个module,就会根据配置的loader去找对应的转换规则
● 对module进行转换后,再解析出当前module依赖的module
● 这些模块会以entry为单位分组,一个entry和其所有依赖的module被分到一个组Chunk
● 最后webpack会把所有Chunk转换成文件输出
● 在整个流程中webpack会在恰当的时机执行plugin里定义的逻辑
webpack打包原理
将所有依赖打包成一个bundle.js,通过代码分割成单元片段按需加载
什么是entry,output?
● entry 入口,告诉webpack要使用哪个模块作为构建项目的起点,默认为./src/index.js
● output 出口,告诉webpack在哪里输出它打包好的代码以及如何命名,默认为./dist
什么是loader,plugins?
● loader是用来告诉webpack如何转换某一类型的文件,并且引入到打包出的文件中。
● plugins(插件)作用更大,可以打包优化,资源管理和注入环境变量
loader
● babel-loader: 将ES6+转移成ES5-
● css-loader,style-loader:解析css文件,能够解释@import url()等
● file-loader:直接输出文件,把构建后的文件路径返回,可以处理很多类型的文件
● url-loader:打包图片
plugins
● html-webpack-plugin: 压缩html
● clean-webpack-plugin: 打包器清理源目录文件,在webpack打包器清理dist目录
什么是bundle,chunk,module?
bundle是webpack打包出来的文件,chunk是webpack在进行模块的依赖分析的时候,代码分割出来的代码块。module是开发中的单个模块
什么是Tree-shaking?CSS可以Tree-shaking?
Tree-shaking是指在打包中取出那些引入了但在代码中没有被用到的死代码。webpack中通过uglifysPlugin来Tree-shaking JS。CSS需要使用purify-CSS
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









