







文章目录
q22 括号生成
题解
这道题我们换一种思路去解决,题目要求用n对括号去排列,我们就从2 * n个括号中去选择括号来从左向右排列。这个时候我们发现,我们已经选择的左括号必须比右括号要多,比如"(((“、”(()“、”(())“这样的情况是允许出现的,但是”())"这样的情况却是不能够出现的。所以在一开始我们就制定了这样的策略:
- 只要左括号一直有,那就可以一直选择左括号
- 只要左括号的数量大于右括号的数量,我们才能选择右括号
- 当括号的数量等于2 * n,表示已经得到了一种排列
func generateParenthesis(n int) []string {
res := []string{}
var dfs func(lBracket int, rBracket int, path string)
dfs = func(lBracket int, rBracket int, path string){
if len(path) >= 2 * n {
res = append(res, path)
return
}
if lBracket > 0 {
dfs(lBracket - 1, rBracket, path + "(")
}
if rBracket > lBracket {
dfs(lBracket, rBracket - 1, path + ")")
}
}
dfs(n, n, "")
return res
}
q39 组合总和
题解
这道题使用dfs来求解,因为每种组合可以有相同的元素,所以不需要去重,也就没有必要先对数组进行排序。我们的递归函数长这样: dfs(target, index),target是每次target被减去以后剩下的那个部分,index则是初始数组的下标。所以递归的终止条件就有两个:当target == 0 或者 index == len - 1的时候。每次递归的时候我们有两种处理方式:跳过当前的元素 -> dfs(target, index + 1) 以及 加上当前的元素 -> dfs(target - candidates[index], index),因为一种组合中的相同元素是可以重复的,所
以dfs的第二个参数依然是index。
func combinationSum(candidates []int, target int) (res [][]int) {
var comb []int
var dfs func(target int, index int)
dfs = func(target int, index int) {
if index == len(candidates) {
return
}
if target == 0 {
res = append(res, append([]int{}, comb...))
/*tmp := make([]int, len(comb))
copy(tmp, comb)
res = append(res, tmp)*/
return
}
// 直接跳过
dfs(target, index + 1)
// 减去当前的元素
if target - candidates[index] >= 0 {
comb = append(comb, candidates[index])
dfs(target - candidates[index], index)
comb = comb[:len(comb) - 1]
}
}
dfs(target, 0)
return
}
q40 组合总和2
题解
这道题的解法与上一道其实差不多,只是需要去重,所以我们要对数组进行排序,方便去重.
然后每次递归的时候加上一个for循环,遍历从index开始到n的每个元素,同时将这些元素与index对应的数进行对比,以便去重.
然后其实在for循环枚举的过程中,跳过当前这次dfs(target, index + 1)已经默认执行过了,所以不用加上这行代码,其次,因为for循环在遍历的时候,下标不会超过n,所以下面的边界条件判断也可以去掉:
if index == len(candidates) {
return
}
最终代码:
func combinationSum2(candidates []int, target int) (res [][]int) {
var comb []int
// 因为不能重复,所以需要去重
sort.Ints(candidates)
var dfs func(target int, index int)
dfs = func(target int, index int) {
if target == 0 {
res = append(res, append([]int{}, comb...))
return
}
// 1. 在循环里面去重
// 2. 在循环里面把dfs(target, index + 1)这一步已经默认执行过了
for i := index; i < len(candidates); i++ {
// 去重
if i != index && candidates[i] == candidates[i - 1] {
continue
}
// 剪枝
if target < candidates[i] {
return
}
comb = append(comb, candidates[i])
dfs(target - candidates[i], i + 1)
comb = comb[:len(comb) - 1]
}
}
dfs(target, 0)
return
}
q46 全排列
题解
这道题使用dfs来求解,判断叶子节点的条件是cur数组的长度与nums的长度一致,这个时候就把cur数组加到res数组中。然后遍历nums数组来选数,以此来创建新分支,在一次循环内部要遍历cur数组,看看选择的数字是否重复,没问题就沿着这条分支继续走。
func permute(nums []int) [][]int {
var res [][]int
dfs(nums, []int{}, &res)
return res
}
func dfs(nums []int, cur []int, res *[][]int) {
if len(nums) == len(cur) {
tmp := make([]int, len(cur))
copy(tmp, cur)
*res = append(*res, tmp)
return
}
for i := 0; i < len(nums); i++ {
exist := false
for j := 0; j < len(cur); j++ {
if nums[i] == cur[j] {
exist = true
break
}
}
if exist == true {
continue
}
dfs(nums, append(cur, nums[i]), res)
}
}
我们也可以使用一个标记数组来记录重复的值:
func permute(nums []int) (res [][]int) {
var cur []int
visited := make([]bool, len(nums))
var dfs func()
dfs = func() {
if len(cur) == len(nums) {
res = append(res, append([]int{}, cur...))
return
}
for i := 0; i < len(nums); i++ {
if visited[i] {
continue
}
visited[i] = true
cur = append(cur, nums[i])
dfs()
visited[i] = false
cur = cur[:len(cur)-1]
}
}
dfs()
return res
}
q77 组合
题解
这道题使用dfs来求解。
func combine(n int, k int) (res [][]int) {
var dfs func(start int, path []int)
dfs = func(start int, path []int) {
// 如果path切片长度到达k,加入结果数组
if len(path) == k {
res = append(res, append([]int{}, path...))
return
}
// 这个for循环用来排列相同位置的不同值
// 比如上一次递归的时候确定了第一个位置的值,这次递归需要确立第二个位置的值
// for循环为第二个位置分别摆放不同的值
for i := start; i <= n; i++ {
// 拼接进path切片
path = append(path, i)
// 向后递归,为切片后面的位置分配数字
dfs(i+1, path)
// 回溯
path = path[:len(path)-1]
}
}
dfs(1, []int{})
return
}
q78 子集
题解
该题可以使用dfs和bfs两种方法来解决。
dfs:
func subsets(nums []int) (res [][]int) {
var dfs func(index int, prefix []int)
dfs = func(index int, prefix []int) {
if index >= len(nums) {
// 将prefix切片插入res切片
res = append(res, append([]int(nil), prefix...))
return
}
// 继续往后递归
// 累加上当前遍历到的元素
dfs(index+1, append(prefix, nums[index]))
// 不累加上当前遍历到的元素
dfs(index+1, prefix)
}
dfs(0, nil)
return
}
bfs:
func subsets1(nums []int) [][]int {
res := make([][]int, 0)
path := make([]int, 0)
var bfs func(int)
bfs = func(start int) {
if start > len(nums) {
return
}
tmp := make([]int, len(path))
copy(tmp, path)
res = append(res, tmp)
for i := start; i < len(nums); i++ {
path = append(path, nums[i])
bfs(i + 1)
path = path[:len(path) - 1]
}
}
bfs(0)
return res
}
q79 单词搜索
题解
这道题可以使用BFS和DFS来求解,很久没有写搜索的题目了,一下子没有写出来,看到官方题解才想起来,是一道标准的搜索题。官方题解用的是BFS + 回溯。
func exist(board [][]byte, word string) bool {
type pair struct {
x, y int
}
direction := []pair{{-1, 0}, {0, 1}, {1, 0}, {0, -1}}
lenX, lenY := len(board), len(board[0])
visit := make([][]bool, lenX)
for i := 0; i < lenX; i++ {
visit[i] = make([]bool, lenY)
}
var check func(i, j, k int) bool
check = func(i, j, k int) bool {
// 剪枝
if board[i][j] != word[k] {
return false
}
// 如果找到了所有word中的字符,直接返回true
if k == len(word) - 1 {
return true
}
// 标记已经走过这条路
visit[i][j] = true
// 回溯
defer func() {
visit[i][j] = false
}()
// 遍历四个方向
for _, dir := range direction {
newX, newY := i + dir.x, j + dir.y
if newX >= 0 && newX < lenX && newY >= 0 && newY < lenY && !visit[newX][newY] {
if check(newX, newY, k + 1) {
return true
}
}
}
return false
}
for i, row := range board {
for j, _ := range row {
if check(i, j, 0) {
return true
}
}
}
return false
}
q240 搜索二维矩阵2
题解
这道题可以使用DFS来求解,由于矩阵是有序的,所以剪枝的办法有两个:
- 下一个要遍历的数是否大于target
- 下一个数是否已经遍历过(建立一个visited二维数组)
func searchMatrix(matrix [][]int, target int) bool {
var find bool
visited := make([][]bool, len(matrix))
for i := 0; i < len(matrix); i++ {
visited[i] = make([]bool, len(matrix[i]))
}
var dfs func(i, j int)
dfs = func(i, j int) {
visited[i][j] = true
// 找到数字
if matrix[i][j] == target {
find = true
return
}
if find == true {
return
}
//fmt.Println("i: ", i, ", j: ", j)
// 未出下边界
if i + 1 < len(matrix) && matrix[i + 1][j] <= target && !visited[i + 1][j] {
dfs(i + 1, j)
}
// 未出下边界
if j + 1 < len(matrix[0]) && matrix[i][j + 1] <= target && !visited[i][j + 1] {
dfs(i, j + 1)
}
}
dfs(0, 0)
return find
}
然后由于是排序过的二维数组,所以可以对每一行进行二分查找,下面是官方题解提供的解法:
func searchMatrix(matrix [][]int, target int) bool {
for _, row := range matrix {
i := sort.SearchInts(row, target)
if i < len(row) && row[i] == target {
return true
}
}
return false
}
q301 删除无效括号
题解
可以参考这篇题解:
func removeInvalidParentheses(s string) []string {
lremove, rremove := 0, 0
for _, i := range s {
if i == '(' {
lremove += 1
} else if i == ')' && lremove == 0 {
rremove += 1
} else if i == ')' && lremove > 0 {
lremove -= 1
}
}
ans := []string{}
dfs(&ans, s, 0, 0, 0, lremove, rremove)
return ans
}
func dfs(ans *[]string, s string, lcount, rcount, start, lremove, rremove int) {
if lremove == 0 && rremove == 0 {
if valid(s) {
*ans = append(*ans, s)
}
return
}
for i := start; i < len(s); i++ {
if s[i] == '(' {
lcount += 1
}
if s[i] == ')' {
rcount += 1
}
if i > start && s[i] == s[i-1] {
continue
}
if s[i] == '(' && lremove > 0 {
dfs(ans, s[:i]+s[i+1:], lcount-1, rcount, i, lremove-1, rremove)
}
if s[i] == ')' && rremove > 0 {
dfs(ans, s[:i]+s[i+1:], lcount, rcount-1, i, lremove, rremove-1)
}
//剪枝优化
if rcount > lcount {
break
}
}
}
func valid(s string) bool {
cnt := 0
for _, v := range s {
if v == '(' {
cnt++
} else if v == ')' {
cnt--
if cnt < 0 {
return false
}
}
}
return cnt == 0
}
q437 路径总和iii
题解
这道题可以使用dfs来求解:
// 统计从当前节点出发,满足的路径数目
func pathFrom(root *TreeNode, sum int) int {
if root == nil {
return 0
}
// 路径数量
cnt := 0
if root.Val == sum {
cnt++
}
// 如果已经找到一条满足的路径,后面可以能会出现正负值相互抵消的情况,从而新增一条更长的路径
cnt += pathFrom(root.Left, sum - root.Val)
cnt += pathFrom(root.Right, sum - root.Val)
return cnt
}
func pathSum(root *TreeNode, sum int) (res int) {
if root == nil {
return 0
}
return pathFrom(root, sum) + pathSum(root.Left, sum) + pathSum(root.Right, sum)
}
但其实我们完全可以使用前缀和把前面的状态给保存起来.
具体做法是使用一个hash表把前面出现过的前缀和给记录下来,然后根据递推公式 pre[i] - pre[j-1] = targetSum判断两个前缀和之间是否有目标值,即[j,i]区间的前缀和差值是否为目标值,进而可以推出寻找pre[j-1] = pre[i] - targetSum,其中pre可以直接使用pre变量进行存储.
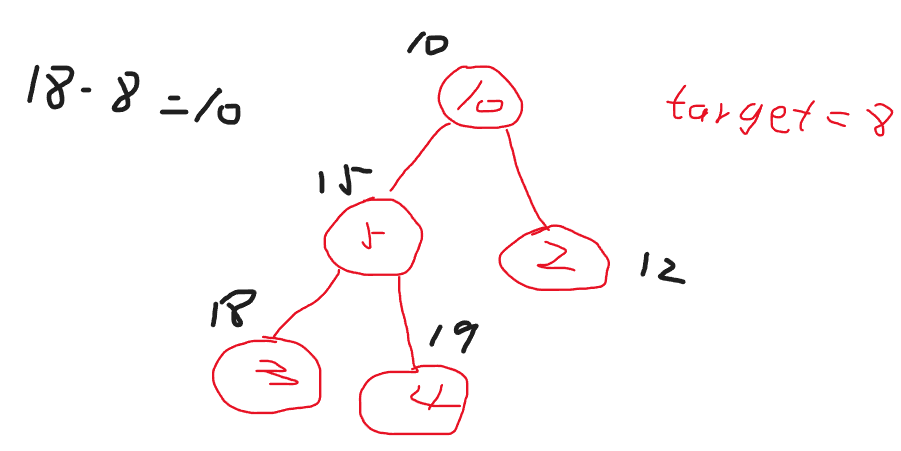
例如下图所示,当我们遍历到18这个节点时,用18减去目标值8,就可以得到之前统计过的前缀和10.所以就存在满足要求的路径.
func pathSum(root *TreeNode, targetSum int) (res int) {
// 前缀和表
mp := make(map[int]int)
var dfs func(root *TreeNode)
pre := 0
// 初始状态
mp[0] = 1
dfs = func(root *TreeNode) {
if root == nil {
return
}
pre += root.Val
// 累加上根节点到当前节点之间刚好和等于目标值的路径
res += mp[pre-targetSum]
// 记录前缀和
mp[pre] += 1
dfs(root.Left)
dfs(root.Right)
// 因为是树形结构,所以要回溯
mp[pre] -= 1
pre -= root.Val
}
dfs(root)
return
}
剑指 Offer 12. 矩阵中的路径
题解
搜索回溯的模板题。
步骤:
- 创建一个表示四个方向的二维数组,定义矩阵的长和宽。
- 创建一个标记数组,用于标记访问过的位置,并初始化。
- 开始创建DFS函数,在函数内部:
- 剪枝、递归出口、标记访问过的位置、回溯,遍历四个方向递归。
- 在外部将二维数组的每个位置都当作起始点进行递归。
func exist(board [][]byte, word string) bool {
// 定义一个对组
type pair struct {
x, y int
}
// 定义四个方向
dir := []pair{{0, 1}, {0, -1}, {1, 0}, {-1, 0}}
// 矩阵的长和宽
lenX, lenY := len(board), len(board[0])
// 创建一个标记数组
visited := make([][]bool, lenX)
for i := 0; i < lenX; i++ {
visited[i] = make([]bool, lenY)
}
// 创建DFS函数
var check func(i, j, k int) bool
check = func(i, j, k int) bool {
// 剪枝
if board[i][j] != word[k] {
return false
}
// 递归出口
if k == len(word)-1 {
return true
}
// 标记当前位置被访问过
visited[i][j] = true
// 回溯
defer func() {
visited[i][j] = false
}()
// 遍历四个方向
for _, d := range dir {
newX, newY := i+d.x, j+d.y
// 判断从当前方向开始递归是否可行
if newX >= 0 && newX < lenX && newY >= 0 && newY < lenY && !visited[newX][newY] {
if check(newX, newY, k+1) {
return true
}
}
}
return false
}
// 将二维数组的每个位置都当作起始点进行递归
for i := 0; i < lenX; i++ {
for j := 0; j < lenY; j++ {
if check(i, j, 0) {
return true
}
}
}
return false
}
剑指 Offer 38. 字符串的排列
题解
这道题就是对字符串进行全排列,但是原来字符串中的字符是可以重复的,比如原来的字符串可能是aab,由于里面含有重复字符,所以它的不重复全排列比不含重复字符的字符串少了几种。
创建一个map用来累加字符串中的个数,然后遍历这个map,同时递归即可。
func permutation(s string) (res []string) {
// 创建一个map用于标记元素的个数
cache := make(map[byte]int)
for _, v := range s {
cache[byte(v)]++
}
// 创建一个临时[]byte用于保存每次遍历的情况
var str []byte
// 创建dfs函数
var dfs func()
dfs = func() {
// 边界条件
if len(str) == len(s) {
res = append(res, string(append([]byte(nil), str...)))
return
}
// 从哪个字符开始遍历
for k, _ := range cache {
if cache[k] != 0 {
str = append(str, k)
cache[k]--
dfs()
cache[k]++
str = str[:len(str)-1]
}
}
}
dfs()
return
}














 880
880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









