






八、序列:
python序列的概念:就是指按照一定顺序排列的数据
python里常用的序列共有5种:列表、元组、字典、集合、字符串
序列中元素的位置,叫做索引 (**索引值从0开始**)
**二进制**
11
**八进制**
111
**十六进制**
#二进制
number1=0b111
print(number1) #1X2^2+1X2^1+1X2^0=7
#八进制
number2=0o171
print(number2) #1X8^2+7X8^1+1X8^0=121
#十六进制
number3=0xA1
print(number3) #10X16^1+1X16^0=161
九、字符串:
定义:由一系列字符组成的不可变序列容器,存储的是字符的编码值。
#字符串数据不可变(数据一旦创建之后,不能再次修改,如果修改,会破坏其他数据的内存空间.所以要修改数据时,会创建新数据,替换变量所记录的内存地址)
name="猴子"
name='孙猴子'
name="花果山孙猴子"
print(name) #花果山孙猴子
相关概念
字节byte:计算机最小存储单位,等于8位bit 1B=8bit
#字--》数
number = ord("B")
print(number) #66
#数--》字
message=chr(65)
print(message) #A
练习1、循环录入编码值打印文字,直到输入空字符串停止(while循环)
while True:
str2=input()
if str2=="":
break
number=int(str2)
print(chr(number))
练习2、终端中输入一个内容,循环打印每个字符串对应的数字
str1=input(str())
for i in str1:
print(ord(i))
字符串写法:
1.双引号(大多数语言只支持这个)
date01="学习python"
2.单引号
date02='学习java'
3.三引号(可见即所得)
date03=" " "学
习go" " "
date03=' ' '学
习js' ' '
注意:引号冲突
print('我要好好"学习"天天向上')
print("我要好好'学习'天天向上")
print("""我要'好'好"学习"python""")
4.转义字符:改变原始含义特殊字符
\" \' \\ 字符串前面加r
print('我要好好"学习"天天向上')
print("我要好好'学习'天天向上")
print("""我要'好'好"学习"python""")
print("我要'好'好\"学习\"python")
print("我要'好'好\'学习\'python")
print(r"我要'好'好\"学习\"python")
print("我要\\好好\\学习python")
\n(换行)
5.格式化字符串:将字符串按照某个格式显示
语法:
占位符: ”....格式....“%(变量) %s是保留原来变量 %f是对小数处理(点几位就是保留几位) %d是取整数(小于2位是前面加0)
name="李四"
age=20
score=100
print(name+"的年龄是"+str(age)+",期末成绩是"+str(score))
print("%s的年龄是%s,期末成绩是%s"%(name,age,score))
练习:根据下列文字,提取变量。使用字符串格式化打印信息
医院现有确诊人数89525人,治愈了79542人,治愈率是0.98
70秒是01分零10秒
definite=89525
heal=79542
CureRate=heal/definite
print("医院现有确诊人数%s人,治愈了%s人,治愈率是%0.2f" % (definite,heal,CureRate))
# 70秒是01分零10秒
seconds=70
minute=1
second=10
print("%s秒是%0.2d分零%s秒" % (seconds,minute,second))
通用操作符:
数学运算符: +元素的拼接
print("我喜欢" +"pyhton") # 我喜欢python
*元素重复
print("不会"*2) #不会不会
比较运算符:== != > < (依次比较两个容器中的元素,一但不同则返回比较结果)
print("悟空">"八戒") #True
成员运算符: in not in
print("悟空" in "齐天大圣孙悟空") #True
print("八戒" not in "七天大圣孙悟空") #True
print("大孙" in "七天大圣孙悟空") #False
练习:在终端中获取一个整数,作为边长,打印下过如图所示
$$$KaTeX parse error: Can't use function '$' in math mode at position 2: $̲ $ $ …$$$
number=int(input())
print("$" * number)
for i in range(number-2):
print("$%s$"%(" "*(number-2)))
print("$" * number)
上面答案优化方案如下:
number=int(input())
for i in range(number):
#写好开头和结尾
if i==0 or i==number-1:
print("$" * number)
else:#中间
print("$%s$"%(" "*(number-2)))
索引 (定位单个元素)
容器名[整数]
```python
msg="adsf花果山水帘洞齐天大圣孙悟空"
print(msg[1]) #定位第二个元素
print(len(msg))
#print(msg[100]) #IndexError: string index out of range索引超过范围
print(msg[-1]) #定位最后一个元素
print(msg[len(msg)-1]) #定位最后一个元素
切片 (定位多个元素)
容器名[开始:结束:间隔]
容器名[开始:结束]
容器名[:结束]
注意:不包含结束的那个元素
间隔默认为1
开始默认为0
结束默认为末尾
msg="花果山水帘洞齐天大圣孙悟空"
print(msg[0:3:1]) #花果山
print(msg[0:3]) #花果山
print(msg[:3]) #花果山
print(msg[:100]) #花果山水帘洞齐天大圣孙悟空
print(msg[::-1]) #空悟孙圣大天齐洞帘水山果花
1.打印第一个字符、打印最后一个字符、打印中间字符
2.打印前三个字符,打印后三个字符
3.广东在content中
4.广州不在content中
5.通过切片打印"广东省广州市"
6.通过切片打印"我是广州仔"
7.通过切片打印仔靓的市
8.倒序打印字符
content="我是广东省广州市的靓仔哦"
print(content[0])
print(content[-1])
print(content[(len(content) // 2)])
print(content[:3])
print(content[-3:])
if "广东" in content[:]:
print(True)
else:
print(False)
if "广州" not in content[-5:]:
print(True)
else:
print(False)
print(content[2:8])
print(content[:2] + content[5:-5] + content[-2])
print(content[-2:-6:-1])
print(content[::-1])
十、列表
定义:由一系列变量组成的可变序列容器
用于存储单一维度的数据
1.创建 --根据元素
list_names=["屌毛","靓仔","扑盖仔"]
list_age=[22,23,25]
list_sexs=["男","女","女"]
--根据可迭代对象(将不可变数据改为可变数据)
list_sek=list("孙行者")
print(list_sek) #['孙', '行', '者']
2.添加
--追加
list_names.append("锁黑")
print(list_names) #['屌毛', '靓仔', '扑盖仔', '锁黑']
--插入
list_names.insert(1,"唐新")
print(list_names) #['屌毛', '唐新', '靓仔', '扑盖仔', '锁黑']
练习:1.创建地区列表、新增列表、现有列表,至少存储3行信息
地区 新增 现有 累计 治愈 死亡
西藏 1 172 175 1 1
云南 10 45 60 2 3
甘肃 5 12 30 5 8
广东 15 198 225 1 11
台湾 20 560 610 30 0
美国 1000 1000 150000 0 148000
2.向以上三个列表追加数据第4行数据,在第1个位置插入第5行数据
list_region=["西藏","云南","甘肃"]
list_add=[1,10,5]
list_current=[172,45,12]
list_region.append("广东")
list_add.append(15)
list_current.append(198)
print(list_region,list_add,list_current) #['西藏', '云南', '甘肃', '广东'] [1, 10, 5, 15] [172, 45, 12, 198]
list_region.insert(0,"美国")
list_add.insert(0,1000)
list_current.insert(0,1000)
print(list_region,list_add,list_current) #['美国', '西藏', '云南', '甘肃', '广东'] [1000, 1, 10, 5, 15] [1000, 172, 45, 12, 198]
3.定位
----索引
list_names=["屌毛","靓仔","扑盖仔"]
print(list_names[0])
list_names[1]="唐新"
print(list_names)
----切片(注意:通过切片读取数据,会创建新列表存储结果)
print(list_names[1:])
通过切片修改数据,将右侧可迭代对象数据依次存入左侧
list_names[1:]=["朝巴","勾八","大大","小小"]
print(list_names)
list_names[2:2]=["齐天大圣孙悟空"]
print(list_names)
4.遍历 ---从头到位获取所有元素
for i in list_names:
#打印列表中第一个字和最后一个字相同的人名
if i [0] == i [-1]:
print(i)
倒序查找数据
len(list_names)-1表示从总数减1开始
-1表示不包含负一,包含0
-1表示:倒序
for i in range(len(list_names)-1,-1,-1):
print(list_names[i])
#练习:
“”"
1.打印美国疫情信息(XX地区新增XX人现存XX人)
2.将地区列表后2个元素修改为[“GH”,“usc”]
3.打印地区列表元素(一行一个)
4.倒序打印新增列表元素(一行一个)
“”"
list_region=["西藏","云南","甘肃"]
list_add=[1,10,5]
list_current=[172,45,12]
list_region.append("广东")
list_add.append(15)
list_current.append(198)
print(list_region,list_add,list_current)
list_region.insert(0,"美国")
list_add.insert(0,1000)
list_current.insert(0,1000)
print(list_region,list_add,list_current)
print("%s地区新增%s人现存%s人"%(list_region[0],list_add[0],list_current[0]))
list_region[-1:-3:-1]="GH","usc"
print(list_region)
#顺序获取地区列表
for item in list_region:
print(item)
#倒序获取地区列表
for item in range(len(list_region)-1,-1,-1):
print(list_region[item])
自学新版占位符 f -string
5.删除
list_names=["屌毛","靓仔","扑盖仔"]
#---根据元素删除
if "吊毛" in list_names:
list_names.remove("吊毛") #如果不存在则报错
print(list_names)
#---根据定位删除
del list_names[0],list_names[1]
print(list_names)
del list_names[0:]
print(list_names)
练习
1.删除地区列表中的云南
2.删除现有列表中的前2个元素
list_region=["西藏","云南","甘肃","美国"]
list_add=[1,10,5,100]
list_current=[172,45,12,1000]
list_region.remove("云南")
del list_region[:2],list_add[:2],list_current[:2]
print(list_region,list_add,list_current)
#八大行星:水星,金星,地球,火星,木星,土星,天王星,海王星
“”"
1.创建列表存储4个行星:水星,金星,火星,木星
2.插入地球,追加土星,天王星,海王星
3.打印距离最近、最远的行星
4.打印太阳到地球之间的行星
5.删除海王星
6.倒序打印所有行星
“”"
list_planet=["水星","金星","火星","木星"]
list_planet.insert(2,"地球")
list_planet.append("土星")
list_planet.append("天王星")
list_planet.append("海王星")
#list_planet +=["土星","天王星","海王星"]
print(list_planet)
print(list_planet[0], list_planet[-1])
print(list_planet[:2])
list_planet.remove("海王星")
print(list_planet)
for i in range(len(list_planet)-1,-1,-1):
print(list_planet[i])
深拷贝:所有层数据拷贝
优点:绝对互不影响 缺点:占用内存较多 适用性:当深层数据需要被修改时
import copy
list01=[10,[20,30,50]]
list02=copy.deepcopy(list01)
list02[0]=100
list02[1][0]=200
print(list01) #[10, [20, 30, 50]]
print(list02) #[100, [200, 30, 50]]
浅拷贝:只复制第一层数据,共享深层数据
优点:占用内存小 缺点:深层数据被修改,互相影响 适用性:优先
list01=[20,[25,35,45]]
list02=list01
list03=list01[:] #第一层两份,深层一份
list03[0]=100 #修改第一层,互不影响
list03[1][0]=250 #修改深层,互相影响
print(list01) #[20,[250,35,45]]
print(list02) #[20,[250,35,45]]
print(list03) #[100,[250,35,45]]
深浅拷贝练习:
import copy
list01=["北京",["上海","深圳"]]
list02=list01
list03=list01[:]
list04=copy.deepcopy(list01)
list04[0]="广州"
list04[1][1]="苏州"
print(list01) #["北京",["上海","深圳"]]
list03[0]="南京"
list03[1][1]="杭州"
print(list01) #["北京",["上海","杭州"]]
list02[0]="天津"
list02[1][1]="无锡"
print(list01) #["天津",["上海","无锡"]]
print(list03) #["南京",["上海","无锡"]]
列表字符串的转换
列表转字符串
#list -->str(列表中元素必须是字符串)
list01=["a","b","c"]
#语法: 字符串 = "连接符".join(列表)
result=" ".join(list01)
print(result) #a b c
应用:
需求:根据某些逻辑循环拼接字符串
缺点:每次循环产生一个新字符串,存储当前,销毁之前
result2=""
for number1 in range(10):
result2+=str(number1)
print(result2)
解决:用可变数据代替不可变数据
result1=[]
for number in range(10):
result1.append(str(number))
#列表(可变)——》字符串(不可变)
result1="".join(result1)
print(result1)
练习
“”“在终端中,循环录入字符串,如果录入空则停止,停止录入后打印所有内容(一个字符串)
效果:
请输入内容:XXX
请输入内容:XXX
请输入内容:XXX
请输入内容:
XXX_XXX_XXX
“””
list01=[]
while True :
str01 = str(input("请输入内容:"))
if str01 == "":
break
list01.append(str01)
list02="_".join(list01)
print("结果是:"+list02)
字符串转列表
#str ---> list
#使用一个字符串存储多个信息
list_result="宋江,武松,李逵".split(",")
print(list_result) #['宋江,武松,李逵']
练习
“”"
将下列英文语句按照单词进行翻转
转换前:To Have A Government That Is Of People
转换后:People Of Is That Government A Have To
“”"
str1="To Have A Government That Is Of People"
list01=str1.split(" ")
# list02=[] 使用for循环倒序创建新列表
# for i in range(len(list01)-1,-1,-1):
# list02.append(list01[i])
list02=list01[-1: :-1]
str2=" ".join(list02)
print("转换后:"+str2)
列表推导式(根据可迭代对象,简单的构建新列表)
新列表 = [变量 for 变量 in 可迭代对象 if 条件]
练习:
“”"
生成10——100之间能被3或者5整除的数字
“”"
# for number in range(10,50):
# if number %3 == 0 and number %5 == 0:
# print(number)
list=[number for number in range(10,100) if number %3 == 0 and number %5 == 0 ]
print(list)
“”"
生成10-25之间的数字平方
“”"
list01=[number**2 for number in range(10,26) ]
print(list01)
作业
2. 根据列表中的数字,重复生成*.
list01 = [1, 2, 3, 4, 5, 4, 3, 2, 1]
效果:
*
**
***
****
*****
****
***
**
*
list01=[1, 2, 3, 4, 5, 4, 3, 2, 1]
#第一种
for i in list01:
print(i*"*")
#第二种
for i in range(len(list01)):
print("*"* list01[i])
- 将列表中的数字累乘
list02 = [5, 1, 4, 6, 7, 4, 6, 8, 5]
结果:806400
list02 = [5, 1, 4, 6, 7, 4, 6, 8, 5]
result=1
for item in list02:
result*=item
print(result)
- 将列表中整数的个位不是5和3的数字存入另外一个列表
list03 = [25, 63, 27, 75, 70, 83, 27]
结果:[27, 70, 27]
list03 = [25, 63, 27, 75, 70, 83, 27]
list04=[]
for item in list03:
unit=item %10
if unit in [5,3]:
continue
#判断各位是不是3或者5
#if not (i%10==5 or i%10==3):
list04.append(item)
print(list04)
- 计算列表中字符串⻓度⼤于2,并且第⼀个和最后⼀个字符相同的字符串个数
字符串列表:words =[“qtx”,“看一看”,“想啊想”,“练练”]
结果:2
words =["qtx","看一看","想啊想","练练","123361","啊啊啊","啥玩意","a","钱"]
str2=0
for i in words:
if len(i)>2 and i[0]==i[len(i)-1] :
str2+=1
print(str2)
- 在终端中录入疫情地区名称,如果输入空字符串,则停止。
最后倒序打印所有地区名称(一行一个)
要求:录入的名称已经存在不要再次添加.
提示: in
list01=[]
while True:
#循环输入
str1=str(input("请输入地区:"))
#判断是否为空
if str1=="" :
break
if str1 in list01:
print("该地区已输入,请重新输入")
else:
list01.append(str1)
#倒序打印
for i in range(len(list01)-1,-1,-1):
print(list01[i])
- 在终端中录入5个疫情省份的确诊人数
最后打印最大值、最小值、平均值.
(使用内建函数实现)
list1=[]
for i in range(1,6):
str1=int(input("确诊人数:"))
list1.append(str1)
#使用列表推导式
list1=[ int(input("确诊人数:")) for i in range(1,6)]
print("最大值为:"+"%s"%(max(list1)))
print("最小值为:"+"%s"%(min(list1)))
print("平均值为:"+"%s"%(sum(list1)//len(list1)))
十一、元组touple:
元组:由一系列变量组成的不可变序列容器(不可变是指一旦创建,不可再添加/删除/修改元素)
列表:由一系列变量组成的可变序列容器
1.创建: ---根据可迭代对象
tuple01=(10,20,'啊')
print(tuple01)
---根据可迭代对象
list02=["a","b","c"] #存储计算过程中的数据
tuple02=tuple(list02) #储计算结果
print(tuple02)
2.定位(只读)
# ---索引
print(tuple02[1])
# ---切片
print(tuple02[:2])
print(tuple02[-2:])
3.遍历
for item in tuple02:
print(item)
for i in range(len(tuple02)-1,-1,-1):
print(tuple02[i])
4.拼接
tuple10 = (10,20)
tuple10 += (40,50)
print(tuple10) #(10, 20, 40, 50)
#注意一:构建元组的小括号可以省略
tuple03="a",4,10,"啊"
#注意二:如果元组中只有一个元素,必须添加逗号
tuple04=("b",)
print(type(tuple04))
#注意三:序列拆包
tuple=(1,2,3)
a,b,c=tuple01
#a,b = b,a
print(a)
print(b)
print(c)
练习:
name="岳不群"
names=["令狐冲","风清扬","林平之"]
tuple05=("华山派",name,names)
name="岳掌门"
tuple05[2][0]="令掌门"
print(tuple05) #("华山派","岳不群",["令掌门","风清扬","林平之"])
根据月日,计算是这一年的第几天。
公式:前几个月总天数+当月天数
tuple_day=(31,28,31,30,31,30,31,31,30,31,30,31)
#输入不合理是重新输入
while True:
str1=int(input())
if str1 not in (tuple(item for item in range(1,13))):
print("您输入的月份错误!请重新输入")
break
str2 = int(input())
if str2 not in (i for i in range(1,32)):
print("输入的天数有误!请重新输入")
break
day=sum(tuple_day[:(str1-1)])+int(str2)
print(str(day)+"天")
break
十二、字典dict:
字典:由一系列键值对组成的可变散列容器(利用空间(内存)换取(cpu定位)时间)
定位单个元素最快
散列:对键进行哈希运算,缺点在内存中的存储位置,每条数据存储无先后顺序
键必须唯一且不可变(字符串/数字/元组),值没有限制
列表:由一系列变量组成的可变序列容器
#创建
#---列表存储单一维度数据
#---字典存储多个维度数据
#---根据键值对创建
dict01={"name":"宋江","age":"55","sex":"男"}
dict02={"name":"武松","age":"50","sex":"男"}
dict03={"name":"扈三娘","age":"45","sex":"女"}
#---根据可迭代对象
#注意:可迭代对象元素的格式要求:能够一分为二
list_name=[("孙","行者"),["猪","八戒"],"唐僧"]
print(dict(list_name))
#2.添加 字典["键"]=值
if "money" not in dict01:
dict01["money"]=10000
print(dict01)
# #3.修改(定位) 字典[键]
if "age" in dict01:
dict01["age"]=26
print(dict01)
#4.读取
if "age" in dict01:
print(dict01["name"])
#练习
“”"
创建字典存储香港信息、云南信息、广东信息
地区 新增 现有 累计 治愈 死亡
香港 7 171 11531 11155 205
云南 2 68 301 231 2
广东 1 40 2290 2242 8
上海 2 37 1904 1860 7
“”"
dict_XG={
"region":"香港",
"新增":7,
"现有":171,
"累计":11531
}
dict_YN={
"region":"云南",
"新增":2,
"现有":68,
"累计":301
}
dict_GD={
"region":"广东",
"新增":1,
"现有":40,
"累计":2290
}
print(dict_XG)
print(dict_GD)
print(dict_YN)
#在终端中打印香港的现有人数,
#在终端中打印云南的新增和现有人数,
#广东新增人数加1
print(dict_XG["现有"])
print(dict_YN["新增"],dict_YN["现有"])
dict_GD["新增"] +=1
print(dict_GD)
#5.删除
dict_XG={"region":"香港","新增":7,"现有":171,"累计":11531}
del dict_XG["现有"]
print(dict_XG)
#6.遍历(获取所有键)
dict_YN={ "region":"云南", "新增":2, "现有":68,"累计":301}
for key in dict_YN:
print(key)
#获取所有值
for value in dict_YN.values():
print(value)
#获取所有键值
for item in dict_YN.items():
#结果为元组
print(item) #('region', '云南') ('新增', 2) ('现有', 68) ('累计', 301)
for key,value in dict_YN.items():
print(key,value)
#字典——》列表
print(list(dict_YN)) #只有键
print(list(dict_YN.values())) #只有值
print(list(dict_YN.items()))
del dict_XG["累计"]
print(dict_XG)
del dict_GD["新增"]
print(dict_GD)
del dict_YN["新增"],dict_YN["现有"]
print(dict_YN)
for key in dict_XG:
print(key)
for value in dict_YN.values():
print(value)
for k,v in dict_GD.items():
print(k,v)
#香港根据值7找到对应的键
for k,v in dict_XG.items():
#如果值为7则打印对应的键
if v==7:
print(k)
number= int(input("请输入数字:"))
dict_learn={
1:"python语言核心编程",
2:"python高级软件技术",
3:"web 全栈",
4:"项目实战",
5:"数据分析",
6:"人工智能",
7:"爬虫"
}
if number in dict_learn:
print(dict_learn[number])
else:
print("输入的数字未检索到。请重新输入")
6.字典推导式
{键:值 for 变量 in 可迭代对象 条件}
#练习
“”"
1、将2个列表合并为一个字典
姓名[“孙行者”,“猪悟能”,“唐僧”]
房间号[99,95,56]
2、颠倒练习1的字典键值
“”"
list01=["孙行者","猪悟能","唐僧"]
list02=[99,95,56]
dict1={}
i=0
while i<len(list01):
key=list01[i]
value=list02[i]
dict1[value]=key
i +=1
for i in range(len(list01)):
key=list01[i]
value=list02[i]
dict1[value]=key
print(dict1)
dict2={list01[i]:list02[i] for i in range(len(list01))}
print(dict2)
# dict3={}
# for k,v in dict2.items():
# dict3[v]=k
# print(dict3)
dict3={v:k for k,v in dict2.items()}
print(dict3)
十三、集合set:
集合:由一系列不重复的(不可变类型变量(元组/数/字符串)键)组成的可变散列容器
应用:去重、数学运算
字典:由一系列键值对组成的可变散列容器(利用空间(内存)换取(cpu定位)时间)
#创建
list_name=["经理","开发","测试"]
dict_JL={"name":"经理","money":"1000000","sex":"少妇"}
#----根据元素
set_name={"经理","经理","经理","经理","开发","测试"}
print(set_name)
#----根据可迭代对象创建(字符串、列表、元组、)
list111=["经理","经理","经理","经理","开发","测试"]
set_names=set(list111)
print(set_names)
#注意创建空集合
set01=set()
print(type(set01))
#添加
set_names.add("人")
set_names.add("人")
print(set_names)
#定位(读取/修改)(集合不具备定位)
#删除
set_names.remove("人")
print(set_names)
#遍历
for item in set_names:
print(set_names)
练习
“”"
在终端中循环录入多个省份名称
如果输入空字符串则停止
最后打印每个省份名称
要求:省份不能重复
“”"
set01=set()
while True:
str1 = str(input("请输入省份:"))
if str1 == "":
break
set01.add(str1)
print(set01)
#应用2:数学运算(交集、并集,补集)
s1={1,2,3}
s2={2,3,5}
#交集
print(s1 & s2) #{2, 3}
#并集
print(s1 | s2 ) #{1, 2, 3, 5}
#补集
print(s1 ^ s2) #{1, 5}
print(s1 - s2) #{1}
print(s2 - s1) #{5}
“”"
经理:曹操,关羽,张飞
开发:曹操,司马懿,孙权,关羽,张飞
1、定义数据结构,存储以上信息
2、是经理也是开发的都有谁?
3、是经理不是技术的都有谁?
4、不是经理是技术的都有谁?
5、身兼-职的都有谁?
6、公司总共多少人?
“”"
dict1={"经理":{"曹操","关羽","张飞"},"开发":{"曹操","司马懿","孙权","关羽"}}
print(type(dict1))
# set1=dict1["经理"]
# set2=dict1["开发"]
print(dict1["经理"] & dict1["开发"])
print(dict1["经理"]-dict1["开发"])
print(dict1["开发"]-dict1["经理"])
print(dict1["经理"] ^ dict1["开发"])
print(len(dict1["经理"] | dict1["开发"]))
“”"
2. 在终端中获取颜色(RGBA),打印描述信息,否则提示颜色不存在
“R” -> “红色”
“G” -> “绿色”
“B” -> “蓝色”
“A” -> “透明度”
“”"
dict001={"R":"红色","G":"绿色","B":"蓝色","A":"透明度"}
while True:
str1=input("请输入信息:")
if str1 in dict001:
print(dict001[str1])
else:
print("对应的颜色不存在")
break
“”"
3. 将列表中的数字累减
list02 = [5, 1, 4, 6, 7, 4, 6, 8, 5]
“”"
list02 = [5, 1, 4, 6, 7, 4, 6, 8, 5]
number=0
#方法1
for i in range(len(list02)):
number -= list02[i]
#方法2
# for item in list02:
# number -=item
print(number)
“”"
4. 在数字列表中查找最大的数字(自定义算法)
算法:
[170 , 160 , 180 , 165]
假设第一个就是最大值
使用假设的和第二个进行比较, 发现更大的就替换假设的
使用假设的和第三个进行比较, 发现更大的就替换假设的
使用假设的和第四个进行比较, 发现更大的就替换假设的
最后,假设的就是最大的.
“”"
list001=[170 , 160 , 180 , 165, 200, 1000]
max_number=list001[0]
for i in range(1,len(list001)):
if max_number<list001[i]:
max_number=list001[i]
print(max_number)
“”"
5. (选做)彩票:双色球
红色:6个 1–33之间的整数 不能重复
蓝色:1个 1–16之间的整数
1) 随机产生一注彩票(列表(前六个是红色,最后一个蓝色))
2) 在终端中录入一支彩票
要求:满足彩票的规则.
“”"
import random
list_ticket = []
# 前六个红球
while len(list_ticket) < 6:
number = random.randint(1, 33)
if number not in list_ticket:
list_ticket.append(number)
# 第七个蓝球
list_ticket.append(random.randint(1, 16))
print(list_ticket)
ls1=[]
while len(ls1)<6:
str1 = input("请输入您要买的红球号:")
if str1 in ls1:
print("该号码已经存在")
elif int(str1) not in range(1,34) :
print("输入的号码有误")
else:
ls1.append(str1)
while len(ls1)<7:
str1 = input("请输入您要买的蓝球号:")
if int(str1) not in range(1,17):
print("输入的号码有误")
else:
ls1.append(str1)
print(ls1)
十四、小结-容器
1.种类与特性
字符串:存储字符编码,不可变,序列
列表:存储变量,可变,序列
元组:存储变量,不可变,序列
字典:存储键值对,可变,散列
键唯一且不可变(数值/字符串/元组)
集合:存储键,可变,散列
2.可变性
可变:预留空间+自动扩容
优点:操作方便(增删改)
缺点:占用内存空间较多
不可变:按需分配
优点:占用内存空间较少
缺点:操作不方便(不能增删改)
适用性:优先
3.序列与散列
序列:有顺序,内存,定位灵活(支持索引切片),空间占用较少
散列:无顺序,定位单个元素最快,空间占用较多
4.基础操作
#创建
#添加
#定位
list01=[10,20,30]
list02=["啊","w",0]
#将右侧元素依次取出,存入左侧定位的区域
list01[:]=["a","b","c"]
#变量list01存储了新列表,取消与就列表的关联
list01=["a","b","c"]
#将list02浅拷贝出新列表赋值给变量list01
list01=list02[:]
#将list02存储的列表地址赋值给变量list01
list01=list02
#右侧浅拷贝出新列表,依次取出元素给左侧列表元素
list[:]=list02[:]
#遍历
#删除
"""
for-for
"""
#外层循环执行1次,内存循环执行多次
#控制行 控制列
for row in range(2):
for colum in range(5):
print("*",end=" ")
print() #换行
练习
"""
$
$$
$$$
$$$$
"""
for r in range(4): #0 1 2 3
for c in range(r+1): #0 01 012 0123
print("$", end="")
print() #换行
"""
二维列表
定位:列表名[行索引][列索引]
"""
#练习
"""
list01=[
[1,2,3,4,5],
[6,7,8,9,10],
[11,12,13,14,15]
]
1.将第一行从左到右逐行打印
2.将第二行从右到左逐行打印
3.将第三列从上到下逐列打印
4.将列表list01按照行列打印
"""
#1.将第一行从左到右逐行打印
for r in range(len(list01[0])):
print(list01[0][r],end=" ")
print()
#2.将第二行从右到左逐行打印
for r in range(len(list01[1])-1,-1,-1):
print(list01[1][r],end=" ")
print()
#3.将第三列从上到下逐列打印
for c in range(len(list01)):
print(list01[c][2],end=" ")
print()
#4.将列表list01按照行列打印
for r in range(len(list01)): #0 1 2
for c in range(len(list01[0])): #01234 01234 01234
print(list01[r][c],end="\t") #\t相当于键盘的tab键
print()
“”"
dict_hobbies={
“成龙”:[“抽烟”,“喝酒”,“打麻将”]
“洪金宝”:[“说”,“斗”,“学”,“唱”]
}
“”"
#1.打印成龙的所有爱好(一行一个)
for item in dict_hobbies["成龙"]:
print(item)
#2.计算洪金宝的所有爱好数量
i=0
for item in dict_hobbies["洪金宝"]:
i +=1
print(i)
#3.打印所有人(一行一个)
for key in dict_hobbies:
print(key)
#4.打印所有爱好(一行一个)
for values in dict_hobbies.values():
for i in values:
print(i)
dict_travel_info={
"北京":{
"景区":["故宫","天坛","天安门"],
"美食":["烤鸭","豆汁儿","炸酱面"]
},
"四川":{
"景区": ["太古里","九寨沟","峨眉山"],
"美食": ["火锅","麻辣烫"]
}
}
#1.打印北京的第一个景区
print(dict_travel_info["北京"]["景区"][0])
#2.打印四川的第二个美食
print(dict_travel_info["四川"]["美食"][1])
#3.所有城市(一行一个)
for k in dict_travel_info:
print(k)
#4.北京所有美食(一行一个)
for i in dict_travel_info["北京"]["美食"]:
print(i)
#5.打印所有城市的所有美食(一行一个)
for V in dict_travel_info.values():
for x in V["美食"]:
print(x)
#6.把北京改成北京市
dict_travel_info["北京市"]=dict_travel_info["北京"]
del dict_travel_info["北京"]
print(dict_travel_info)
十五、小结 -算法
1.循环计数
开始
for/while...
间隔
结束
2.交换
a,b = b,a
3.最值
list001=[5,65,70,88,89,14]
max_value=list001[0] 设置第一个值为最大值
for i in range(1,len(list001)):
if max_value<list001[i]: 第一个值依次和后面的值做比较
max_value=list001[i]
print(max_value)
4.自定义排序算法
list001 = [5, 65, 70, 88, 89, 14]
for x in range( len(list001)-1):
#作比较
for i in range(x+1,len(list001)):
#找更大
if list001[x] < list001[i]:
#做交换
list001[x],list001[i]=list001[i],list001[x]
print(list001)
练习
list001 = [5, 65, 70, 88, 89, 14]
for i in range(1, len(list001)):
if list001[0] < list001[i]:
list001[0],list001[i]=list001[i],list001[0]
print(list001)
for i in range(2, len(list001)):
if list001[1] < list001[i]:
list001[1],list001[i]=list001[i],list001[1]
print(list001)
for i in range(3, len(list001)):
if list001[2] < list001[i]:
list001[2],list001[i]=list001[i],list001[2]
print(list001)
#取数据
for x in range( len(list001)-1):
#作比较
for i in range(x+1,len(list001)):
#找更大
if list001[x] < list001[i]:
#做交换
list001[x],list001[i]=list001[i],list001[x]
print(list001)
#练习(升序排列)
list002 = [5, 65, 70, 88, 89, 1, 99, 85, 3, 56]
for i in range(1,len(list002)):
if list002[0]>list002[i]:
list002[0],list002[i]=list002[i],list002[0]
print(list002)
for i in range(2,len(list002)):
if list002[1]>list002[i]:
list002[1],list002[i]=list002[i],list002[1]
print(list002)
for i in range(3,len(list002)):
if list002[2]>list002[i]:
list002[2],list002[i]=list002[i],list002[2]
print(list002)
for y in range(len(list002)):
for i in range(1+y, len(list002)):
if list002[y] > list002[i]:
list002[y], list002[i] = list002[i], list002[y]
print(list002)
#商品信息
dict_commodity={
101:{"name":"阿波菲斯魔剑","price":"10000"}
102:{"name":"无影艾诺克","price":"6000"}
103:{"name":"计算机","price":"2000000"}
104:{"name":"杯子","price":"600"}
105:{"name":"避孕套","price":"50"}
}
#订单列表
list_orders=[
{"cid":"101","count":"3"}
{"cid":"102","count":"1"}
{"cid":"103","count":"2"}
]
#1.打印所有商品的信息(格式:商品编号XX,商品名称XX,商品单价XX)
for k,v in dict_commodity.items():
print("商品编号%d,商品名称%s,商品单价%s" % (k,v["name"],v["price"]))
#2.打印所有订单中的信息(格式:商品编号XX,购买数量XX)
for item in list_orders:
print("商品编号%s,购买数量%s" % (item["cid"],item["count"]))
#3.打印所有订单中商品信息(格式:商品名称XX,商品单价XX,数量XX)
for item in list_orders: #101
cid=item["cid"]
info1=dict_commodity[cid]
print("商品名称%s,商品单价%s,数量%s" % (info1["name"],info1["price"],item["count"]))
#4.查找数量最多的订单(使用自定义算法,不使用内置函数)
max_count=list_orders[0]["count"]
for i in range(1,len(list_orders)):
if max_count<list_orders[i]["count"]:
max_count=list_orders[i]["count"]
print(max_count)
#5.根据购买数量对订单列表降序(大>小)排序
for i in range(len(list_orders)-1): #3 1 2
for c in range(i+1,len(list_orders)): #12 2
if list_orders[i]["count"] < list_orders[c]["count"]:
list_orders[i]["count"], list_orders[c]["count"]= list_orders[c]["count"],list_orders[i]["count"]
print(list_orders)
“”"
列表推导式嵌套
“”"
list00001=["香蕉","苹果","哈密瓜","葡萄"]
list00002=["可乐","牛奶","果汁","啤酒"]
list00003=[]
for r in list00001:
for c in list00002:
list00003.append((r, c))
print(list00003)
list0004=[(r, c) for r in list00001 for c in list00002 ]
print(list0004)
#请排列出2个筛子的所有组合
list_shaizi=[]
for x in range(1,7):
for y in range(1,7):
list_shaizi.append((x,y))
print(list_shaizi)
list_shaizi2=[(x,y) for x in range(1,7) for y in range(1,7) ]
print(list_shaizi2)
list_shaizi3=[(a,b,c) for a in range(1,7) for b in range(1,7) for c in range(1,7) ]
print(list_shaizi3)
2. 画出下列代码内存图
data01 = "悟空"
data02 = data01
data01 = "孙悟空"
print(data02) # ? 悟空

data03 = {“name”:“悟空”}
data04 = data03
data03[“name”] = “孙悟空”
print(data04[“name”]) # ? 孙悟空

data05 = [{"name": "悟空"}]
data06 = data05[:]
data05[0]["name"] = "孙悟空"
print(data06) # ? 孙悟空

-
容器综合训练
员工字典(员工编号 部门编号 姓名 工资) dict_employees = { 1001: {"did": 9002, "name": "师父", "money": 60000}, 1002: {"did": 9001, "name": "孙悟空", "money": 50000}, 1003: {"did": 9002, "name": "猪八戒", "money": 20000}, 1004: {"did": 9001, "name": "沙僧", "money": 30000}, 1005: {"did": 9001, "name": "小白龙", "money": 15000}, } 部门列表 list_departments = [ {"did": 9002, "title": "销售部"}, #9002 #9001 {"did": 9001, "title": "教学部"}, #9001 9003 #9003 {"did": 9003, "title": "品保部"}, ]
#--1. 打印所有员工信息,
#格式:xx的员工编号是xx,部门编号是xx,月薪xx元.
for k,v in dict_employees.items():
print("%s的员工编号是%s,部门编号是%s,月薪%s元."%(v["name"],k,v["did"],v["money"]))
#--2. 打印所有月薪大于2w的员工信息,
#格式:xx的员工编号是xx,部门编号是xx,月薪xx元.
for k,v in dict_employees.items():
if v["money"]>20000:
print("%s的员工编号是%s,部门编号是%s,月薪%s元."%(v["name"],k,v["did"],v["money"]))
#--3. 在部门列表中查找编号最小的部门
min_did=list_departments[0]
for i in range(len(list_departments)):
if min_did["did"]>list_departments[i]["did"]:
min_did["did"]=list_departments[i]["did"]
print(min_did["did"])
#--4. 根据部门编号对部门列表升序排列
for i in range(len(list_departments)-1):
for c in range(i+1,len(list_departments)):
if list_departments[c]["did"]<list_departments[i]["did"]:
list_departments[c]["did"],list_departments[i]["did"]=list_departments[i]["did"],list_departments[c]["did"]
print(list_departments)
"""
4. (选做)在列表中删除所有偶数
list01 = [10,20,33,40,51,60,70,80]
提示:倒序删除
"""
list1 = [10,20,33,40,51,60,70,80]
for i in range(len(list1)-1,-1,-1):
if list1[i]%2==0:
del list1[i]
print(list1)
十六、列表 list:
列表中可以存放任意数据类型
写法:中括号
#注意:通常使用列表都是存放同一数据类型
#说明:列表就是一个小型数据库,所以对于列表中元素的操作,就是:增删改查
列表中可以存放任意数据类型:整数、浮点数、字符串、布尔值、其他列表(即嵌套列表)、元组、字典、集合以及自定义的对象等
1.查询列表中的元素:中括号(注意索引值的概念)

2.增删改列表中的元素:

列表中常用的方法:(函数)
len():返回对象(如列表、元组、字符串等)的长度或项目数
max():返回可迭代对象中的最大值。如果传入多个参数,则返回这些参数中的最大值
min():返回可迭代对象中的最小值。如果传入多个参数,则返回这些参数中的最小值
sum():返回可迭代对象中所有元素的和。如果传入多个参数,则返回这些参数的和。
index(x): 返回列表中第一个出现的元素x的索引。
extend(L): 将列表L中的所有元素添加到当前列表的末尾。
insert(index, x): 在指定索引位置插入元素x。append()默认在末尾插入
pop([index]): 移除并返回列表中指定索引的元素,如果不提供索引,则默认移除并返回最后一个元素。
count(x): 返回列表中元素x出现的次数。
sort(key=None, reverse=False): 对列表进行排序。key参数用于指定排序规则,reverse参数用于指定是否降序排序。
reverse(): 反转列表中的元素顺序。
copy(): 返回列表的一个浅拷贝。
清空列表:列表名.clear( ) 注意:元组不可清空
删除列表元素:列表名.remove( )

列表进阶:
1.创建空列表:空列表是False

2.创建数值列表:借助两个函数list()和range()

3.列表切片:

4.列表相加:

5.列表相乘:
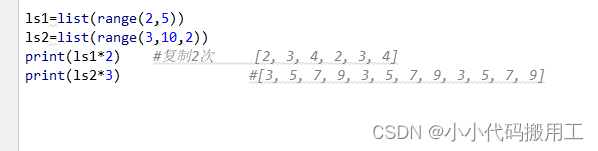
6.检测列表中元素是否存在:in/not in

7.二维列表:
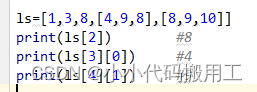
8.遍历列表:把列表中所有的元素依次取出来

9.列表推导式:目的就是快速生成列表

练习题:
1.将列表ls = ['hello','123','456123','Bbbbbbb','sssss','789','BAC','b','ZZZ']中的纯字符串抽取并排序

2.冒泡算法:;将1到1000的随机数按从大到小的顺序排列
十七、元组 tuple:
元组就是一个不可变的列表(列表是可变的:增删改)
元组用( ) 列表用[ ]
写法:

注意:当元组中,只有一个元素时,需要用逗号分隔开,目的是和分字符串区分!

元组进阶:
1.创建空元组:False

2.创建数值元组:同列表 tuple()与range()

3.元组的加法乘法:同列表
4.元组的删除:(列表是删除列表中的元素,元组的删除是删除整个元组)

5.元组常用的方法:
count() 获取元素出现的次数
index() 返回元素首次出现的索引位置
len() 返回元素个数
max()
min()
sum()

6.元组切片:同列表

7.元组推导式:

8.元素和列表的区别:
列表可变,元组不可变
①练习题:将列表与元组合并(一维),返回新的列表
②练习题:制作由元组组成的列表,并以列表形式输出所有元组中出现频率最高的元素
要求:元组个数随机,元组中元素数值随机,元素个数随机
面试题:
判断列表元素是否存在?
简述列表切片的写法?
如何快速创建数值列表?
说一下列表的增删改查?
python序列有哪五种?
获取列表的元素个数?获取列表中的最小值?
元组和列表的区别?
十八.字典 dict: (dictionary 字典)
1.字典与列表类似,都是可变序列,但字典是无序的(列表和元组都是有序的)
2.有序:意味着有索引值的概念
3.字典保存的内容是:键值对形式
键值对理解:类似新华字典中的拼音和汉字 拼音就是 key,汉字就是 value
键值对特点:键是唯一的,而值可以重复
写法:
总结:
列表用中括号[ ]
元组用小括号( )
字典用花括号{ }
创建空字典:False

通过映射函数zip()来创建字典:映射函数 列表元组都可以映射

通过关键字参数创建字典:dict()函数

清空字典:

访问字典:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









