







 本文介绍了微软的DeepSpeed框架中的ZeRO内存优化技术,通过切片减少模型训练时的内存占用,适用于多GPU环境。作者以ChatGLM2-6B模型为例,演示了如何在实际项目中应用ZeRO-1、ZeRO-2和ZeRO-3,以及如何调整配置以优化空间和速度。
本文介绍了微软的DeepSpeed框架中的ZeRO内存优化技术,通过切片减少模型训练时的内存占用,适用于多GPU环境。作者以ChatGLM2-6B模型为例,演示了如何在实际项目中应用ZeRO-1、ZeRO-2和ZeRO-3,以及如何调整配置以优化空间和速度。
大家好,i am chickenfans。
今天给大家写的文章是微软deepspeed的ZeRO的理解。详细原理可以去看其他文章。
其实几句话就可以概括:
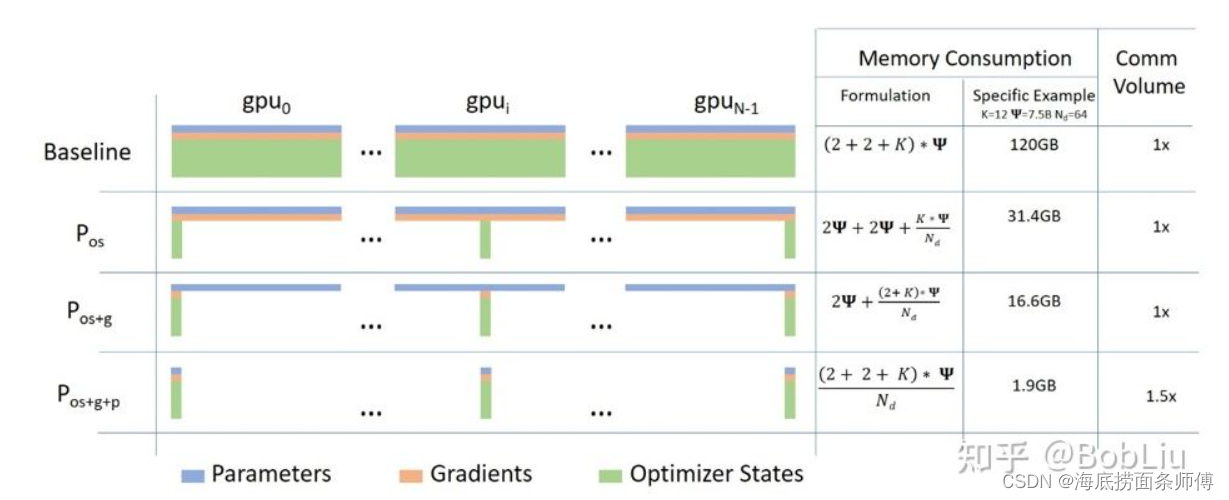
1、模型在训练的时候,会有很多内存的冗余,分布是模型权重W,梯度以及优化器状态,就因为这三个玩意再加上最后的参数,把内存给占满了。
这三玩意有多大,比如6B模型,fp16训练,一个fp16的数字2个字节,那么模型的参数就有2*6B约等于12GB,权重也是12GB,梯度也是12GB,优化器因为要存fp32的数字所以是24GB,这还不包括数据,还有其他缓存。
2、how to 解决?
答案:切片。以时间换空间
假如我有4张显卡,对于梯度,把梯度像年糕一样切成等份的四份,第一份放第一张显卡上,第二份放第二张显卡上,同理第三第四份放到第三、四张显卡上,假如显卡1上要使用梯度,那就进行一次通信,把其他三台机器上的梯度拿过来就好啦,是不是很简单。
同理优化器、权重也都是这么切片的。
ZeRO-1是将优化器分片,ZeRO-2是在ZeRO-1的基础上将梯度分片,ZeRO-3是在ZeRO-2的基础上将权重分配,所以理论上来说,显卡越多,那么显存占用就会越少。
ok,什么,你ZeRO-3都使用了,发现还是存在显存溢出,怎么办?
都别玩了,切什么切,直接ZeRO-affload,将刚刚经过ZeRO切片的梯度、权重、优化器直接丢到内存就好了,为什么?内存便宜啊,显存80g都很奢侈了,内存1000多随便80g。
速度?
都说了牺牲时间换空间,所以,谁占的空间小,谁的速度慢,按快慢分,1>2>3>offload。
看别人都配了图,我也要配图,直接截。Pos代表ZeRO-1,Pos+g代表ZeRO-2,Pos+g+p是ZeRO-3
原理讲完了,直接谈实战:
实战我选择的是大名鼎鼎的chatglm2-6BGitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型,在两张V100上跑全量微调!!单机多(2)卡
什么?没有V100的卡?
租赁服务器链接:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
AutoDL看到了麻烦给一下广告费
第一步:下载拷贝到本地仓库
git clone https://github.com/THUDM/ChatGLM2-6Bcd ChatGLM2-6B
第二步:配置环境
https://www.heywhale.com/mw/project/64984a7b72ebe240516ae79c
基础环境:Python3.9 Cuda11.6 Torch1.12.1
pip install -r requirements.txt
pip install rouge_chinese nltk jieba datasets -i https://mirror.sjtu.edu.cn/pypi/web/simple
得注释requirements.txt文件夹底下的torch,不然使用不了gpu哦第三步
修改ptuning文件夹下的ds_train_finetune.sh文件。
LR=1e-4
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --num_gpus=4 #多少张卡写多少--master_port $MASTER_PORT main.py \
--deepspeed deepspeed.json \
--do_train \
--train_file AdvertiseGen/train.json \ #训练数据的路径
--test_file AdvertiseGen/dev.json \ #测试数据的路径
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm2-6b \ #默认模型的路径,不指定回去huggingface下载然后放到缓存里
--output_dir ./output/adgen-chatglm2-6b-ft-$LR \ #模型输出路径
--overwrite_output_dir \
--max_source_length 64 \ #输入序列长度
--max_target_length 64 \ #输出序列长度
--per_device_train_batch_size 4 \ #每张卡的batch_size
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \ #梯度累计次数
--predict_with_generate \
--max_steps 5000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--fp16 #fp16精度训练
第四步修改 deepspeed.json
{
"train_micro_batch_size_per_gpu": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2, #就改这一部分,具体的参数意义可以看我上篇文章"offload_optimizer": {
"device": "cpu"
},
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": false,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients" : true
}
}
第五步:运行ds_train_finetune.sh文件



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









