







文章目录
- 文章目录
- 前言
- 准备
- 主要架构展示
- 程序项目架构
- EPUB文件架构
- 正文部分
- tool.py
- 导入所需模块
- 1.random_num(length)
- 2.random_chara(length)
- 3.create_book_id()
- 4.create_dir(path)
- 5.create_dirs(path)
- 6.get_filename(path)
- 7.unzip_file(zip_path, extract_path)
- 8.del_dir()
- 9.get_img_files(directory)
- 10.convert_to_jpg(input_path, output_path, trans=False)
- 11.copy_jpg(input_list, output_list, new_list)
- 12.create_time()
- 13.trans_filename(filelist, creator)
- 14.create_on_dict(new_list, filelist)
- 15.zip_files(input_path, output_path)
- 16.trans_img_format(img_path, num=2520)
- 17.create_mobi(epub_path, label="-c2")
- 18.create_path(path)
- pubtools.py
- 导入所需模块
- 1.create_mimetype(epub)
- 2.create_container(epub)
- 3.create_content(epub, fn, b_id, co_tor, cr_tor, c_time, manifest, spine)
- 5.create_toc(epub, filename, filelist, creator)
- 6.create_style(epub)
- 7.create_text(epub, filename, new_list, img_list)
- 8.write_images(epub, filelist, new_list)
- 9.trans_new_filepath(new_list)
- 10.create_manifest(new_list)
- 11.create_spine(new_list)
- doc_create.py
- main.py
- 关于Kindlegen
- kindle简要说明
- kindlegen的全部cmd参数(Options)
- kindlegen常用参数:
- kindlegen.exe 的基本用法
前言
写本文的初衷是记录我的Python学习历程,同时能让我的kindle用着更加趁手(~ ̄▽ ̄)~,为了便于调试和讲解已经将函数打包,本文含有详细说明,代码含有详细中文注释。
主要讲解使用python生成电子书(epub漫画格式)和使用Python调用cmd生成mobi格式文件。目前已测试可用的输入压缩包内图片格式有.jpg和.webp,理论上.png同样可用。
同时为了方便各位喜欢用kindle的小伙伴,可以自己生成电子漫画,甚至可以修改元数据(可能不全,
这里只是根据KCC生成的电子漫画.epub格式进行拆解),许多参数都借鉴于该软件生成的EPUB漫画。为了方便大家理解本文我写的的小程序版本是我早期完成的版本,不含有报错和详细交互界面。
EPUB文件结构:epub 文件拆解_epub解包_wasdjkluioqwer的博客-CSDN博客
本文仅供学习交流,转载请注明出处( •̀ ω •́ )✧。
准备
用到的第三方软件:kindlegen
用到的第三方库:PIL
使用的编译器:PyCharm Community Edition 2.23.2.1
主要架构展示
程序项目架构
- main.py
- Temp(临时文件夹)
- images(压缩包解压出的支持图片格式文件)
- images_ori(与images内图片相同分辨率的JPG图片)
- images_trans(经过等比例缩放大小的JPG图片,高为1680)
- output(程序输出文件夹)
- 文件名(解压转化后的图片,从images_ori文件夹转移而来)
- 文件名.zip(含纯JPG图片的ZIP压缩包)
- 文件名.pdf
- 文件名.epub
- 文件名.mobi
- tools(这是一个包)
- _init_.py
- kindlegen.exe
- tool.py(该模块下主要为一些工具类函数)
- random_num(length)
- random_chara(length)
- create_book_id()
- create_dir(path)
- create_dirs(path)
- get_filename(path)
- unzip_file(zip_path, extract_path)
- del_dir()
- get_img_files(directory)
- convert_to_jpg(input_path, output_path, trans=False)
- copy_jpg(input_list, output_list, new_list)
- create_time()
- trans_filename(filelist, creator)
- create_on_dict(new_list, filelist)
- zip_files(input_path, output_path)
- trans_img_format(img_path, num=2520)
- create_mobi(epub_path, label="-c2")
- create_path(path)
- pubtools.py(该模块下主要为EPUB文件生成有关的函数)
- create_mimetype(epub)
- create_container(epub)
- create_content(epub, fn, b_id, co_tor, cr_tor, c_time, manifest, spine)
- create_nav(epub, filename, filelist, creator)
- create_toc(epub, filename, filelist, creator)
- create_style(epub)
- create_text(epub, filename, new_list, img_list)
- write_images(epub, filelist, new_list)
- trans_new_filepath(new_list)
- create_manifest(new_list)
- create_spine(new_list)
- doc_create.py(该模块专门用于生成PDF文件)
- images_to_pdf(img_paths, pdf_path)
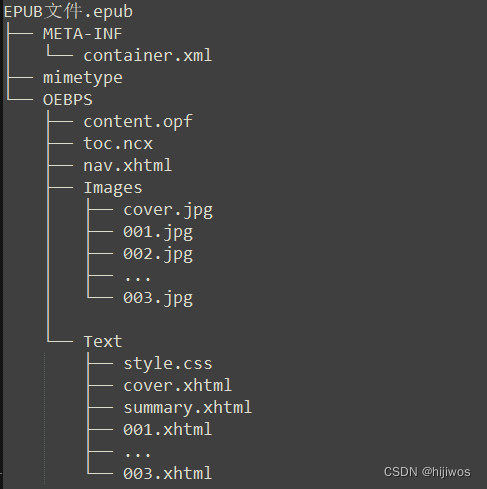
EPUB文件架构
(EPUB文件实质是ZIP压缩文件)
- EPUB文件名.epub
- META-INF
- container.xml
- OEBPS
- Images
- 图片1.jpg
- 图片2.jpg
- ......
- 图片n.jpg
- Text
- style.css
- 图片1.xhtml
- 图片2.xhtml
- ......
- 图片n.xhtml
- content.opf
- nav.xhtml
- toc.ncx
- Images
- mimetype
- META-INF
正文部分
这里先介绍下本程序主要使用的三个自定义模块文件(tool.py, pubtools.py, ),方便对主程序进行讲解
tool.py
导入所需模块
用Lowercase存储所有小写字母供 2.random_chara(length) 使用
# -*- coding: utf-8 -*-
import os
import zipfile
import shutil
from PIL import Image
import time
import string
import random
import subprocess
# 全部小写字母
Lowercase = string.ascii_lowercase
1.random_num(length)
生成一段由指定长度纯数字组成的随机数,用于create_book_id()生成书籍ID
# 生成指定长度(length)随机数
def random_num(length):
"""
生成指定长度(length)随机数
:param length: 要生成的随机数长度,至少为1
:return: 返回生成的随机数 temp_create
"""
temp_create = ""
for i in range(0, length):
temp = str(random.randint(0, 9))
temp_create += temp
return temp_create2.random_chara(length)
生成一段由指定长度纯x小写字母组成的随机字符串,用于create_book_id()生成书籍ID
# 生成指定长度(length)小写字母
def random_chara(length):
"""
生成指定长度(length)小写字母
:param length: 要生成的小写字母字符串长度,至少为1
:return: 返回生成的小写字母字符串 temp_create
"""
temp_create = ""
for i in range(0, length):
temp = random.choice(Lowercase)
temp_create += temp
return temp_create3.create_book_id()
生成EPUB文档的通用唯一识别码
这里使用了固定的格式
- 通用唯一识别码:书的唯一识别码,一串字母与数字组合的字符串,长度为 8-4-4-4-12,例:05e3fb80-8845-44e7-b9e4-05a808a9f0ca
# 生成BookID
def create_book_id():
"""
生成BookID
格式:05e3fb80-8845-44e7-b9e4-05a808a9f0ca
:return: 返回生成的BookID:
"""
temp_create = ""
temp_create += random_num(2)
temp_create += random_chara(1)
temp_create += random_num(1)
temp_create += random_chara(2)
temp_create += random_num(2)
temp_create += "-"
temp_create += random_num(4)
temp_create += "-"
temp_create += random_num(2)
temp_create += random_chara(1)
temp_create += random_num(1)
temp_create += "-"
temp_create += random_chara(1)
temp_create += random_num(1)
temp_create += random_chara(1)
temp_create += random_num(1)
temp_create += "-"
temp_create += random_num(2)
temp_create += random_chara(1)
temp_create += random_num(3)
temp_create += random_chara(1)
temp_create += random_num(1)
temp_create += random_chara(1)
temp_create += random_num(1)
temp_create += random_chara(2)
return temp_create4.create_dir(path)
生成单个文件目录,不支持多级目录
# 检测目录是否存在并生成单层目录
def create_dir(path):
"""
检测目录是否存在并生成目录
:param path: 要生成的目录
:return:无返回值
"""
if os.path.exists(path):
pass
else:
os.mkdir(path)5.create_dirs(path)
生成多级文件目录
# 检测目录是否存在并生成多层目录
def create_dirs(path):
"""
检测目录是否存在并生成目录
:param path: 要生成的目录
:return:无返回值
"""
if os.path.exists(path):
pass
else:
os.makedirs(path)6.get_filename(path)
获取文件名
- 例:“EPUB文档.zip” 的文件名为 “EPUB文档”
# 提取并返回文件名
def get_filename(path):
"""
提取并返回文件名
:param path: 文件路径(带后缀民)
:return: 返回文件名
"""
return os.path.basename(os.path.splitext(path)[0])7.unzip_file(zip_path, extract_path)
解压ZIP文件
# 实现对.zip文件的解压
def unzip_file(zip_path, extract_path):
"""
实现对.zip文件的解压
:param zip_path: 要解压的zip文件
:param extract_path: 解压的输出路径
:return: 无返回值
"""
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
zip_ref.extractall(extract_path)
print("解压缩完成!")8.del_dir()
删除目录,可删除多级目录(包括含有文件的目录),用于清除Temp文件夹
# 删除目录
def del_dir(directory):
"""
删除目录
:param directory: 要删除的目录路径
:return:无返回值
"""
try:
shutil.rmtree(directory)
print("%s 目录删除成功" % directory)
except OSError as e:
print(f"%s 删除目录失败: {e}" % directory)9.get_img_files(directory)
获取输入路径下所有".jpg"、".png"和".webp"图片格式的文件
# 读取输入文件夹路径下所有图片文件路径
def get_img_files(directory):
"""
读取输入路径下所有图片文件路径
:param directory: 待读取的包含图片文件的文件夹路径
:return: 返回读取到的所有图片文件路径列表
"""
images_files = []
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith((".jpg", ".png", ".webp")):
images_files.append(os.path.join(root, file))
# 输出读取到的图片文件路径并返回一个列表
return images_files10.convert_to_jpg(input_path, output_path, trans=False)
将图片文件转换为JPG格式,存储到指定路径,若为JPG格式则直接复制到指定路径
函数参数 "trans" 为True时进行图片大小转换,根据高1680进行等比例缩放,这一步用于生成EPUB文件中用到的图片大小
# 将图片转换为.jpg或复制到指定目录格式
def convert_to_jpg(input_path, output_path, trans=False):
"""
将图片转换为.jpg或复制.jpg到指定目录格式
pic_new = pic_org.resize((224, 224), Image.ANTIALIAS)
pic_new.save(pic_new_path) # 将修改后的图像存储到新的路径中
:param input_path: 原图片路径
:param output_path: 输出图片路径
:param trans: 布尔值,默认为Flase,True时启用图片等比例转换
:return: 无返回值
"""
if input_path.strip("\"\'").endswith(".jpg"):
if trans is False:
shutil.copy(input_path, output_path)
elif trans is True:
print("获取的图片文件路径:", input_path)
output_path = r"{}\{}.jpg".format(output_path, get_filename(input_path))
print("输出的图片文件路径", output_path)
tw = int(trans_img_format(input_path, 1680)[2])
image = Image.open(input_path)
image_new = image.resize((tw, 1680))
image_new.save(output_path)
elif input_path.strip("\"\'").endswith(".webp"):
# 尝试转化.webp文件为.jpg
# 此处路径格式的引用需要使用双斜杠,要不无法访问到目标路径
if trans is True:
print("获取的图片文件路径:", input_path)
output_path = r"{}\{}.jpg".format(output_path, get_filename(input_path))
print("输出的图片文件路径", output_path)
tw = int(trans_img_format(input_path, 1680)[2])
image = Image.open(input_path)
image_new = image.resize((tw, 1680))
image_new.save(output_path)
elif trans is False:
print("获取的图片文件路径:", input_path)
output_path = r"{}\{}.jpg".format(output_path, get_filename(input_path))
print("输出的图片文件路径", output_path)
image = Image.open(input_path)
image.save(output_path)
else:
print("获取的图片文件路径:", input_path)
output_path = r"{}\{}.jpg".format(output_path, get_filename(input_path))
print("输出的图片文件路径", output_path)
image = Image.open(input_path)
image.save(output_path)
"""
# 原来的代码,供修改用
img = Image.open(input_path)
img.save(output_path, 'JPG')
"""11.copy_jpg(input_list, output_list, new_list)
备选函数,未进行引用,原为convert_to_jpg
# 将图片转换为.jpg或复制.jpg到指定目录格式,并改为新文件名
def copy_jpg(input_list, output_list, new_list):
"""
将图片转换为.jpg或复制.jpg到指定目录格式,并改为新文件名
:param input_list: 原图片路径列表
:param output_list: 输出图片路径列表
:param new_list: 新文件名列表
:return: 无返回值
"""
dic = dict(zip(input_list, output_list))
for input_path, output_path in dic.items():
if input_path.strip("\"\'").endswith(".jpg"):
shutil.copy(input_path, output_path)
else:
img = Image.open(input_path)
for each in new_list:
img.save("%s\\%s.jpg" % (output_path, each), 'JPG')12.create_time()
获取当前文件创建时间
- 格式:年-月-日 h:m:s
# 返回当前时间
def create_time():
"""
返回当前时间
格式化成2020-06-25 11:18:29 形式
:return: 当前时间
"""
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())13.trans_filename(filelist, creator)
生成EPUB文件内文件名 0000-author
# 生成zip内文件名(带0000)
def trans_filename(filelist: list, creator: str) -> list:
"""
生成zip内文件名(带0000)
三种格式:
print("{:0>4d}".format(Id))
print("{:04d}".format(Id))
print('%04d' % Id)
:param filelist: 文件名列表
:param creator: 创建人
:return: 转换后的zip内文件名列表
"""
new_list = []
for i in range(1, len(filelist) + 1):
new_name = "%s-%s" % ("{:0>4d}".format(i), creator)
new_list.append(new_name)
return new_list14.create_on_dict(new_list, filelist)
生成一个新旧文件路径字典,用于for in对文件的处理
# 生成一个新旧文件路径对照字典
def create_on_dict(new_list: list, filelist: list):
"""
生成一个新旧文件路径对照字典
:param filelist: 原路径
:param new_list: 新路径
:return: 返回一个 新:旧 字典
"""
return dict(zip(new_list, filelist))15.zip_files(input_path, output_path)
将文件压缩为.zip后缀的ZIP文件
# 将文件夹或文件压缩为.zip文件
def zip_files(input_path, output_path):
with zipfile.ZipFile(output_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
if zipfile.is_zipfile(input_path):
print("输入的文件是已经是ZIP文件了。")
else:
if os.path.isdir(input_path):
# 压缩文件夹
for root, dirs, files in os.walk(input_path):
for file in files:
file_path = os.path.join(root, file)
zipf.write(file_path, os.path.relpath(file_path, input_path))
else:
# 压缩单个文件
zipf.write(input_path, os.path.basename(input_path))
print(f"成功创建ZIP文件: {output_path}")16.trans_img_format(img_path, num=2520)
等比例缩放图片文件大小,根据高2520\1680进行等比例转换
# 实现长宽识别与转换
def trans_img_format(img_path, num=2520):
"""
实现长宽识别与转换
根据高为num:2520/1680等比例转换宽
:param img_path: .jpg图片路径
:param num: 高为num:2520/1680,默认2520
:return: 返回[宽,高,转换后的宽]列表
"""
img = Image.open(img_path)
w = img.width # 图片的宽
h = img.height # 图片的高
# 根据高为2520等比例转换后的宽
trans_w = "%d" % ((num*w)/h)
info_list = [w, h, trans_w]
return info_list17.create_mobi(epub_path, label="-c2")
调用cmd运行tool\kindlegen.exe转换EPUB为MOBI
# 调用命令行转化.epub为.mobi
def create_mobi(epub_path, label="-c2"):
"""
调用命令行转化.epub为.mobi
:param epub_path: epub文件路径
:param label:转化用标签
:return: 反返回命令行返回值
"""
current_path = os.path.join(os.path.dirname(os.path.abspath("kindlegen.exe")), r"tools\kindlegen.exe")
kindle_gen = create_path(current_path)
epub_path = os.path.join(os.path.dirname(os.path.abspath("kindlegen.exe")), epub_path)
cmd = r"{k_path} {pub_path} {label}".format(k_path=kindle_gen, pub_path=create_path(epub_path), label=label)
print(cmd)
ret = subprocess.run(cmd, shell=True, capture_output=True, encoding='utf-8')
print(ret.stdout)
return ret18.create_path(path)
将输入的不带引号的路径两侧添加路径,用于传入cmd
# 在路径的两侧添加英文引号
def create_path(path):
"""
在路径的两侧添加英文引号
:param path: 输入的路径
:return: 加过引号的路径
"""
path = "\"" + path + "\""
return pathpubtools.py
导入所需模块
# -*- coding: utf-8 -*-
from .tool import *
import zipfile
import os这里导入了同一个包下的另一个模块(tool.py)
使用了包内相对导入使PyCharm产生了警告,但是并不影响代码运行,注意两个包内函数名不能相同。
![]()
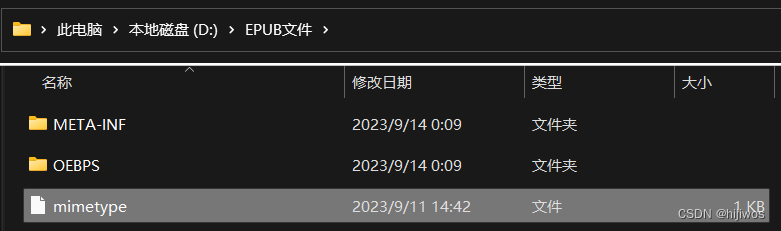
1.create_mimetype(epub)
生成文件位置:EPUB文件\mimetype
# 生成mimetype
def create_mimetype(epub):
"""
生成mimetype
:param epub: zip文件对象
:return:无返回值
"""
epub.writestr('mimetype', 'application/epub+zip', compress_type=zipfile.ZIP_STORED)2.create_container(epub)
生成文件位置:EPUB文件\META-IN\container.xml

# 生成META-INF/container.xml
def create_container(epub):
"""
生成META-INF/container.xml
:param epub: zip文件对象
:return: 无返回值
"""
container_info = '''
<?xml version="1.0"?>
<container version="1.0" xmlns="urn:oasis:names:tc:opendocument:xmlns:container">
<rootfiles>
<rootfile full-path="OEBPS/content.opf" media-type="application/oebps-package+xml"/>
</rootfiles>
</container>
'''
epub.writestr('META-INF/container.xml', container_info.strip("\n"), compress_type=zipfile.ZIP_STORED)3.create_content(epub, fn, b_id, co_tor, cr_tor, c_time, manifest, spine)
生成文件位置:EPUB文件\OEBPS\content.opf
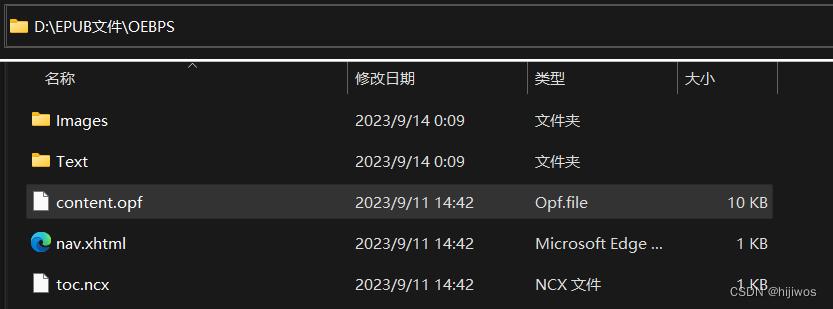
文件内容(删去大部分头部信息和重复的manifest、spine标签内的内容)
# 生成OEBPS/content.opf
def create_content(epub, fn, b_id, co_tor, cr_tor, c_time, manifest, spine):
"""
生成OEBPS/content.opf
:param epub: zip文件对象
:param fn: filename
:param b_id: book_id
:param co_tor: contributor
:param cr_tor: creator
:param c_time: 文档修改时间
:param manifest: manifest
:param spine: spine
:return: 无返回值
"""
temp = """
<?xml version="1.0" encoding="UTF-8"?>
<package version="3.0" unique-identifier="BookID" xmlns="http://www.idpf.org/2007/opf">
<metadata xmlns:opf="http://www.idpf.org/2007/opf" xmlns:dc="http://purl.org/dc/elements/1.1/">
<dc:title>{fn}</dc:title>
<dc:language>en-US</dc:language>
<dc:identifier id="BookID">urn:uuid:{b_id}</dc:identifier>
<dc:contributor id="contributor">{co_tor}</dc:contributor>
<dc:creator>{cr_tor}</dc:creator>
<meta property="dcterms:modified">{time}</meta>
<meta name="cover" content="cover"/>
<meta name="fixed-layout" content="true"/>
<meta name="original-resolution" content="1264x1680"/>
<meta name="book-type" content="comic"/>
<meta name="primary-writing-mode" content="horizontal-lr"/>
<meta name="zero-gutter" content="true"/>
<meta name="zero-margin" content="true"/>
<meta name="ke-border-color" content="#FFFFFF"/>
<meta name="ke-border-width" content="0"/>
<meta name="orientation-lock" content="portrait"/>
<meta name="region-mag" content="true"/>
</metadata>
<manifest>
<item id="ncx" href="toc.ncx" media-type="application/x-dtbncx+xml"/>
<item id="nav" href="nav.xhtml" properties="nav" media-type="application/xhtml+xml"/>
<item id="cover" href="Images/cover.jpg" media-type="image/jpeg" properties="cover-image"/>
{mf}
<item id="css" href="Text/style.css" media-type="text/css"/>
</manifest>
<spine page-progression-direction="ltr" toc="ncx">
{sn}
</spine>
</package>
"""
content_info = temp.format(fn=fn, b_id=b_id, co_tor=co_tor, cr_tor=cr_tor, time=c_time, mf=manifest, sn=spine)
epub.writestr('OEBPS/content.opf', content_info.lstrip("\""), compress_type=zipfile.ZIP_STORED)4.create_nav(epub, filename, filelist, creator)
生成文件位置:EPUB文件\OEBPS\nav.xhtml
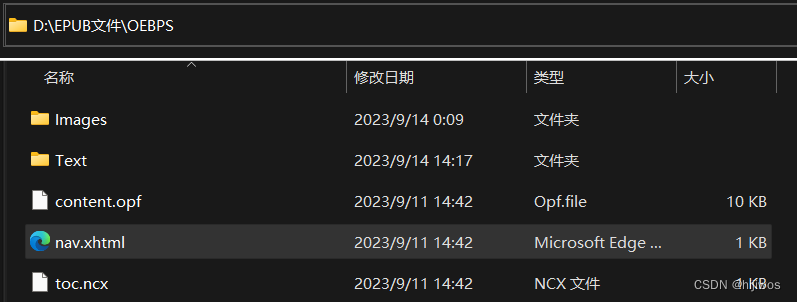
# 生成OEBPS/nav.xhtml
def create_nav(epub, filename, filelist, creator):
"""
生成OEBPS/nav.xhtml
:param epub: zip文件对象
:param filename: 文件名
:param filelist: 图片文件路径列表
:param creator: 创建人
:return: 无返回值
"""
temp = """
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:epub="http://www.idpf.org/2007/ops">
<head>
<title>{filename}</title>
<meta charset="utf-8"/>
</head>
<body>
<nav xmlns:epub="http://www.idpf.org/2007/ops" epub:type="toc" id="toc">
<ol>
<li><a href="Text/{first_filename}.xhtml">{filename}</a></li>
</ol>
</nav>
<nav epub:type="page-list">
<ol>
<li><a href="Text/{first_filename}.xhtml">{filename}</a></li>
</ol>
</nav>
</body>
</html>
"""
nav_info = temp.format(first_filename=trans_filename(filelist, creator)[0], filename=filename)
epub.writestr('OEBPS/nav.xhtml', nav_info.lstrip("\n"), compress_type=zipfile.ZIP_STORED)5.create_toc(epub, filename, filelist, creator)
生成文件位置:EPUB文件\OEBPS\toc.ncx
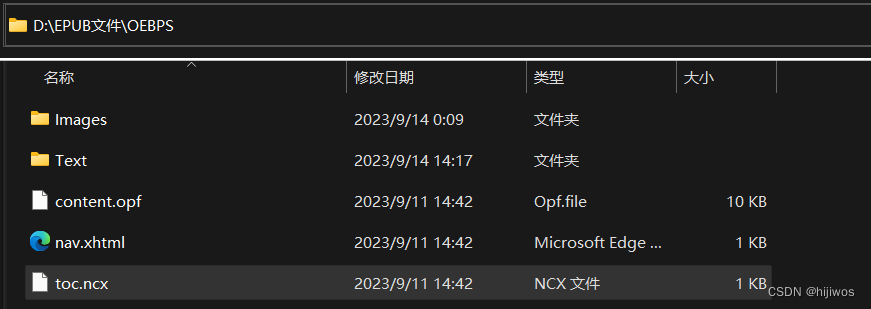
# 生成OEBPS/toc.ncx
def create_toc(epub, filename, filelist, creator):
"""
生成OEBPS/toc.ncx
:param epub: zip文件对象
:param filename: 文件名
:param filelist: 原图片文件路径
:param creator: 创建人
:return: 无返回值
"""
temp = """
<?xml version="1.0" encoding="UTF-8"?>
<ncx version="2005-1" xml:lang="en-US" xmlns="http://www.daisy.org/z3986/2005/ncx/">
<head>
<meta name="dtb:uid" content="urn:uuid:%(b_id)s"/>
<meta name="dtb:depth" content="1"/>
<meta name="dtb:totalPageCount" content="0"/>
<meta name="dtb:maxPageNumber" content="0"/>
<meta name="generated" content="true"/>
</head>
<docTitle><text>{filename}</text></docTitle>
<navMap>
<navPoint id="Text">
<navLabel>
<text>{filename}</text>
</navLabel>
<content src="Text/%(first_filename)s.xhtml"/>
</navPoint>
</navMap>
</ncx>
"""
toc_info = temp.format(first_filename=trans_filename(filelist, creator)[0], filename=filename)
epub.writestr('OEBPS/toc.ncx', toc_info.lstrip("\n"), compress_type=zipfile.ZIP_STORED)6.create_style(epub)
生成文件位置:EPUB文件\OEBPS\Text\style.css
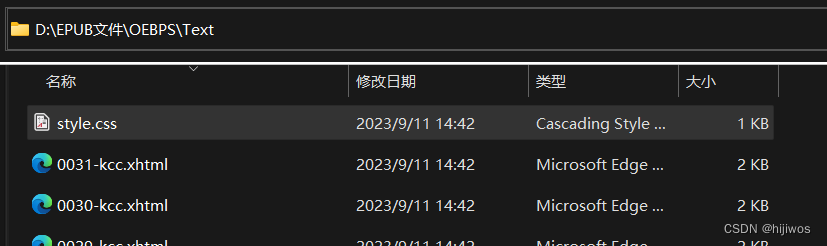
# 生成OEBPS/Text/style.css
def create_style(epub):
"""
生成OEBPS/Text/style.css
生成电子书样式
:param epub: zip文件对象
:return: 无返回值
"""
style_info = """
@page {
margin: 0;
}
body {
display: block;
margin: 0;
padding: 0;
}
#PV {
position: absolute;
width: 100%;
height: 100%;
top: 0;
left: 0;
}
#PV-T {
top: 0;
width: 100%;
height: 50%;
}
#PV-B {
bottom: 0;
width: 100%;
height: 50%;
}
#PV-L {
left: 0;
width: 49.5%;
height: 100%;
float: left;
}
#PV-R {
right: 0;
width: 49.5%;
height: 100%;
float: right;
}
#PV-TL {
top: 0;
left: 0;
width: 49.5%;
height: 50%;
float: left;
}
#PV-TR {
top: 0;
right: 0;
width: 49.5%;
height: 50%;
float: right;
}
#PV-BL {
bottom: 0;
left: 0;
width: 49.5%;
height: 50%;
float: left;
}
#PV-BR {
bottom: 0;
right: 0;
width: 49.5%;
height: 50%;
float: right;
}
.PV-P {
width: 100%;
height: 100%;
top: 0;
position: absolute;
display: none;
}
"""
epub.writestr('OEBPS/Text/style.css', style_info.lstrip("\n"), compress_type=zipfile.ZIP_STORED)7.create_text(epub, filename, new_list, img_list)
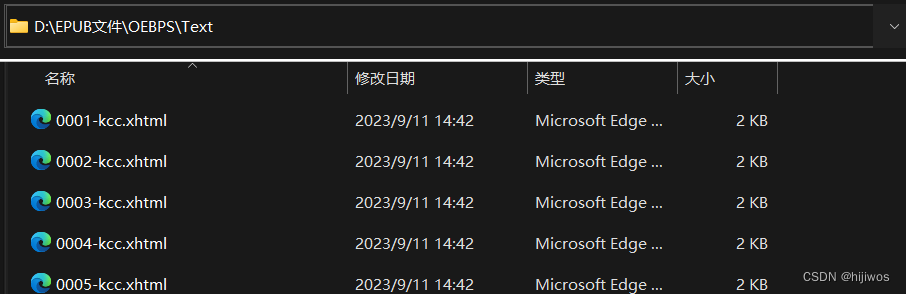
# 生成OEBPS/Text/图片.xhtml
def create_text(epub, filename, new_list, img_list):
"""
生成OEBPS/Text/图片.xhtml
:param epub: zip文件对象
:param filename: 文件名
:param new_list: 新文件路径列表
:param img_list: 图片文件路径列表
:return: 无返回值
"""
temp = """
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:epub="http://www.idpf.org/2007/ops">
<head>
<title>{filename}</title>
<link href="style.css" type="text/css" rel="stylesheet"/>
<meta name="viewport" content="width="{w}", height="{h}"/>
</head>
<body style="">
<div style="text-align:center;top:0.0%;">
<img width="{w}" height="{h}" src="../Images/{n_filename}.jpg"/>
</div>
<div id="PV">
<div id="PV-TL">
<a style="display:inline-block;width:100%;height:100%;" {special_string}TL-P", "ordinal":1{foo}
</div>
<div id="PV-TR">
<a style="display:inline-block;width:100%;height:100%;" {special_string}TR-P", "ordinal":2{foo}
</div>
<div id="PV-BL">
<a style="display:inline-block;width:100%;height:100%;" {special_string}BL-P", "ordinal":3{foo}
</div>
<div id="PV-BR">
<a style="display:inline-block;width:100%;height:100%;" {special_string}BR-P", "ordinal":4{foo}
</div>
</div>
<div class="PV-P" id="PV-TL-P" style="">
<img style="position:absolute;left:0;top:0;" src="../Images/{n_filename}.jpg" width="{tw}" height="2520"/>
</div>
<div class="PV-P" id="PV-TR-P" style="">
<img style="position:absolute;right:0;top:0;" src="../Images/{n_filename}.jpg" width="{tw}" height="2520"/>
</div>
<div class="PV-P" id="PV-BL-P" style="">
<img style="position:absolute;left:0;bottom:0;" src="../Images/{n_filename}.jpg" width="{tw}" height="2520"/>
</div>
<div class="PV-P" id="PV-BR-P" style="">
<img style="position:absolute;right:0;bottom:0;" src="../Images/{n_filename}.jpg" width="{tw}" height="2520"/>
</div>
</body>
</html>
"""
s_c = """class="app-amzn-magnify" data-app-amzn-magnify='{"targetId":"PV-"""
foo = "}'></a>"
new_path_list = trans_new_filepath(img_list)
print(new_path_list)
dic = dict(zip(new_list, new_path_list))
for n_filename, img_path in dic.items():
print(img_path)
info_list = trans_img_format(img_path)
w = info_list[0]
h = info_list[1]
tw = info_list[2]
print(w, h, tw)
text_info = temp.format(filename=filename, n_filename=n_filename, special_string=s_c, foo=foo, w=w, h=h, tw=tw)
epub.writestr('OEBPS/Text/%s.xhtml' % n_filename, text_info.lstrip("\n"), compress_type=zipfile.ZIP_STORED)8.write_images(epub, filelist, new_list)
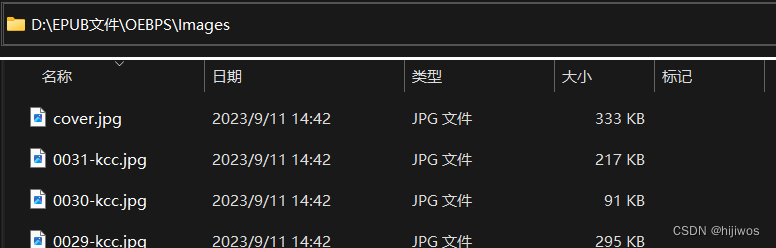
# 写入图片文件,并根据第一张图片创建cover.jpg
def write_images(epub, filelist: list, new_list: list):
"""
写入图片文件,并根据第一张图片创建cover.jpg
:param epub: zip文件对象
:param filelist: 原文件路径列表
:param new_list: 新文件路径列表
:return: 无返回值
"""
dic = create_on_dict(new_list, filelist)
for new_filename, old_filename in dic.items():
# write(file_i, arcname=(n := os.path.basename(file_i)))
epub.write(old_filename, 'OEBPS/Images/%s.jpg' % new_filename, compress_type=zipfile.ZIP_STORED)
epub.write(dic["%s" % new_list[0]], 'OEBPS/Images/cover.jpg', compress_type=zipfile.ZIP_STORED)9.trans_new_filepath(new_list)
用于将要制作EPUB文档的JPG文件名转化为0000-author.jpg的格式
# 生成新文件路径列表
def trans_new_filepath(new_list):
"""
生成新文件路径列表
:param new_list: 新文件名列表
:return: 返回新文件路径列表
"""
new_filepath = []
for new_filename in new_list:
new_filepath.append('%s.jpg' % os.path.splitext(new_filename)[0])
return new_filepath10.create_manifest(new_list)
content.opf的manifest标签内容(省略了部分):

# 生成写入content的manifest
def create_manifest(new_list):
"""
生成写入content的manifest
例:
<item id="page_Images_test0001-kcc" href="Text/test0001-kcc.xhtml" media-type="application/xhtml+xml"/>
<item id="img_Images_test0001-kcc" href="Images/test0001-kcc.jpg" media-type="image/jpeg"/>
:param new_list: 新文件名列表
:return: 返回写入content的manifest,类型为str
"""
manifest_info = ""
temp = """
<item id="page_Images_{new_file_name}" href="Text/{new_file_name}.xhtml" media-type="application/xhtml+xml"/>
<item id="img_Images_{new_file_name}" href="Images/{new_file_name}.jpg" media-type="image/jpeg"/>
"""
for n_f_name in new_list:
temp_info = temp.format(new_file_name=n_f_name).rstrip("\n ")
manifest_info += temp_info
return manifest_info.lstrip("\n")11.create_spine(new_list)
content.opf的spine标签内容(省略了部分):
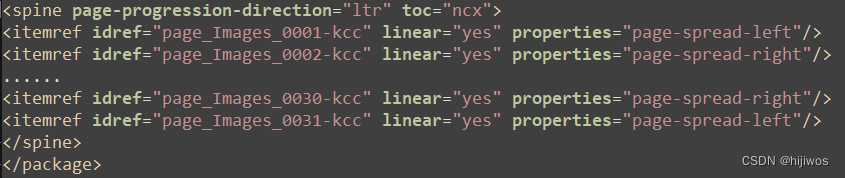
# 生成写入content的spine
def create_spine(new_list):
"""
生成写入content的spine
例:
<itemref idref="page_Images_test0001-kcc" linear="yes" properties="page-spread-left"/>
<itemref idref="page_Images_test0002-kcc" linear="yes" properties="page-spread-right"/>
:param new_list: 新文件路径列表
:return: 返回写入content的spine
"""
i = 1
spine_info = ""
temp = """
<itemref idref="page_Images_{new_filename}" linear="yes" properties="page-spread-{ps}"/>
"""
for each in new_list:
if i % 2 == 1:
spine_info += temp.format(new_filename=each, ps='left').rstrip("\n ")
else:
spine_info += temp.format(new_filename=each, ps='right').rstrip("\n ")
i += 1
return spine_info.lstrip("\n")doc_create.py
将Temp文件夹(images_ori)中的原大小JPG图片转化为PDF文档
# -*- coding: utf-8 -*-
# 导入所需的库
from PIL import Image
# 定义一个函数,用于将多个图片文件转化为PDF文档,并返回PDF文件的路径
def images_to_pdf(img_paths: list, pdf_path: str) -> str:
"""
将多个图片文件转化为PDF文档,并返回PDF文件的路径
:param img_paths: 图片文件路径列表
:param pdf_path: PDF文件输出路径
:return: PDF文件输出路径
"""
# 判断图片文件列表是否为空
if not img_paths:
# 空列表,返回None
return 'None'
# 读取第一个图片文件,并转换为RGB模式
first_img = Image.open(img_paths[0]).convert("RGB")
# 创建一个空的图片列表,用于存储除第一个图片外的其他图片
other_images = []
# 遍历图片文件列表,从第二个图片开始
for img_path in img_paths[1:]:
# 读取图片文件,并转换为RGB模式
img = Image.open(img_path).convert("RGB")
# 将图片添加到图片列表中
other_images.append(img)
# 将第一个图片和其他图片一起保存为PDF文件,并返回PDF文件的路径
first_img.save(pdf_path, save_all=True, append_images=other_images)
return pdf_pathmain.py
注意:epub.close()非常重要!不关闭名为epub的zip对象会导致kindlegen在读取改EPUB文档时报错
主程序:
from tools import tool
from tools import doc_create as dc
import os
from tools import pubtools as pb
import zipfile
judge = 'y'
# 删除临时文件夹 "Temp"
if os.path.exists("Temp"):
tool.del_dir("Temp")
else:
pass
# 输入压缩包路径
path = str(input("请输入压缩包路径:")).strip("\"\'")
# 获取压缩包文件名
filename = tool.get_filename(path)
# 创建文件夹 Temp\images 存储解压的原图片
tool.create_dirs("Temp\\images")
# 创建文件夹 Temp\images_ori 存储转化为JPG格式原大小图片
tool.create_dirs("Temp\\images_ori")
# 创建文件夹 Temp\images_trans 存储转换过大小的JPG图片文件
tool.create_dirs("Temp\\images_trans")
# 对压缩包进行解压,解压到 "Temp\images" 文件夹---------Temp\images
tool.unzip_file(path, "Temp\\images")
# 获取 "Temp\images" 文件夹内的图片文件路径
img_path = tool.get_img_files("Temp\\images")
# 将原大小的JPG图片转移到 "Temp\\images_ori" 目录,获取并输出需要转换的图片文件数目并显示进度-----Temp\images_ori
img_all = len(img_path)
print("共%d个图片文件待生成" % img_all)
# 将原大小的JPG格式文件输出到 "Temp\\images_ori" 文件夹
for count in range(img_all):
tool.convert_to_jpg(img_path[count], "Temp\\images_ori")
print("进度:%d/%d" % (count + 1, img_all))
# 获取 "Temp\images_ori" 内原大小JPG图片路径
img_list_ori = tool.get_img_files("Temp\\images_ori")
# 将转换大小的JPG图片转移到 "Temp\\images_trans" 目录,获取并输出需要转换的图片文件数目并显示进度-----Temp\images_trans
img_all = len(img_path)
print("共%d个图片文件待生成" % img_all)
# 将转换大小的JPG格式文件输出到 "Temp\\images_trans" 文件夹
for count in range(img_all):
tool.convert_to_jpg(img_path[count], "Temp\\images_trans", True)
print("进度:%d/%d" % (count + 1, img_all))
# 获取 "Temp\images_trans" 内原大小JPG图片路径
img_list_trans = tool.get_img_files("Temp\\images_trans")
# output 文件夹操作---------------output
# 创建文件夹 "output\文件名"----------------------建立output图片文件夹
output_path = "output\\{f}".format(f=filename)
tool.create_dirs(output_path)
# 创建输出文件夹路径,用于存储输出的图片------------------存储JPG图片文件
output_img_path = "output\\{f}\\{f}".format(f=filename)
tool.create_dirs(output_img_path)
# 将输出的图片文件夹 "Temp\images_ori" 压缩为ZIP文件--------------------压缩图片zip
tool.zip_files("Temp\\images_ori", "output\\{f}\\{f}.zip".format(f=filename))
# 根据原大小JPG图片路径 "Temp\images_ori" 生成.pdf文件---------------生成PDF
dc.images_to_pdf(img_list_ori, "output\\{f}\\{f}.pdf".format(f=filename))
# ----------------------------------------生成.epub文件
# 书籍id
b_id = tool.create_book_id()
# 书籍contributer
c_tor = "img_to_pub ver1.0"
# 书籍creator
cr_tor = str(input("作者:"))
# 书籍生成时间
create_time = tool.create_time()
# 获取原大小JPG图片文件夹 "Temp\images_ori" 中图片文件路径列表
trans_images = tool.get_img_files("Temp\\images_ori")
# 获取原大小JPG图片文件夹 "Temp\images_ori" 中图片文件名列表
filename_list = []
for each in trans_images:
filename_list.append(tool.get_filename(each))
# 新文件名列表 "0000-author"
new_list = tool.trans_filename(filename_list, cr_tor)
# 根据已输出的图片路径生成.epub文件
# 生成 content.opf
manifest = pb.create_manifest(new_list)
spine = pb.create_spine(new_list)
# 构建后缀名为 '.epub' 的zip文件
epub_path = "output\\{f}\\{f}.epub".format(f=filename)
epub = zipfile.ZipFile(epub_path, 'w', zipfile.ZIP_STORED)
# 写入 epub 文件主要内容
pb.create_mimetype(epub)
pb.create_container(epub)
pb.create_content(epub, filename, b_id, c_tor, cr_tor, create_time, manifest, spine)
pb.create_nav(epub, filename, new_list, cr_tor)
pb.create_toc(epub, filename, new_list, cr_tor)
pb.create_style(epub)
pb.create_text(epub, filename, new_list, img_list_trans)
pb.write_images(epub, img_list_trans, new_list)
# 关闭 名为 'epub' 的zip对象
# 不关闭无法生成.mobi文件
epub.close()
# -----------------------生成.mobi文件
tool.create_mobi(epub_path)
tool.del_dir("Temp")关于Kindlegen
kindle简要说明
kindlegen.exe 是一款由 Amazon 开发的电子书格式转换工具,主要用于将 epub、html、opf 等格式的文件转换为 mobi 格式,以便在 Kindle 设备或应用上阅读。kindlegen.exe 是一个命令行程序,没有图形界面,因此需要在 cmd 中运行,并传递相应的参数。
kindlegen的全部cmd参数(Options)
根据官方文档和kinglegen wiki,kindlegen.exe 支持以下参数:
(原为英文文档,在此进行了简单翻译)
-preserve_img: Original Image size will be preserved
-preserve_img:将保留原始图像大小
-image64K: The maximum size of the image is restricted to 64K
-image64K:图像的最大大小限制为 64K
-image128K: The maximum size of the image is restricted to 128K
-image128K:图像的最大大小限制为 128K
-gif: gif image conversion (no jpeg)
-GIF:GIF图像转换(无JPEG)
-c0: No compression
-c0:无压缩
-c1: Standard PalmDOC compression
-c1:标准掌上电脑压缩
-c2: Kindle Huffdic compression
-c2:kindle赫夫迪克压缩
-allscript: Authorize all scripting
-allscript:授权所有脚本
-western: Forced Windows-1252 output
-western:强制Windows-1252输出
-verbose: Verbose output
-verbose:verbose输出
-noparseback: Parse back won't be built
-noparseback:不会构建解析回
-regserver: The XOPFPlugin type library has been registered
-regserver:XOPFPlugin 类型库已被注册
-unregserver: The XOPFPlugin type library has been unregistered
-unregserver:XOPFPlugin 类型库已取消注册
-donotaddsource: Source files will not be added. Replaced -dont_append_source.
-donotaddsource:不会添加源文件。已替换 -dont_append_source。
(hidden) Skip the HTML cleanup
(隐藏)跳过 HTML 清理
-genhdcontainers: eMM will be built with given resolutions
-genhdcontainers:eMM将以给定的分辨率构建
-locale <locale option> : To display messages in selected language
-locale <locale option>:以所选语言显示消息
(hidden) creates json position map file for debugging purpose.
(隐藏)创建用于调试目的的 JSON 位置映射文件。
-gen_ff_mobi7: (hidden) creates mobi for older devices.
-gen_ff_mobi7:(隐藏)为旧设备创建 mobi。
(hidden) Using manual(tag based) fragmentation mode for building Webkit reader compatible mobi.
(隐藏)使用手动(基于标签)碎片模式构建与Webkit阅读器兼容的mobi。
(hidden) Webkit reader Compatible mobi will be built
(隐藏)Webkit阅读器将构建兼容的mobi
(hidden) fragsize
(隐藏)碎裂
(hidden) custom image size will be used for resizing
(隐藏)自定义图像大小将用于调整大小
(hidden) Amazon creator tool or pipeline
(隐藏)亚马逊创建者工具或管道
kindlegen常用参数:
- -c0, -c1, -c2: 设置压缩级别,0 为无压缩,1 为标准压缩,2 为高级压缩。默认为 1。
- -dont_append_source: 不在生成的 mobi 文件中附加源文件。默认为附加。
- -gif: 将图片转换为 GIF 格式。默认为 JPEG 格式。
- -locale: 设置语言环境,例如 zh_CN, en_US 等。默认为系统语言环境。
- -o <file>: 指定输出文件的名称。默认为源文件的名称。
- -verbose: 显示详细的转换信息。默认为简单信息。
- -western: 使用西方文字编码。默认为自动检测。
kindlegen.exe 的基本用法
kindlegen.exe <source_file> [options]
其中 <source_file> 是要转换的源文件,可以是 zip、epub、html、opf 等格式,[options] 是可选的参数,可以是上述的任意一个或多个。
例如,如果想将一个名为 `book.epub` 的文件转换为 mobi 格式,并使用高级压缩和 GIF 图片格式,就在 cmd 中输入以下命令:
kindlegen.exe book.epub -c2 -gif
(本程序中kindle.exe使用kindle.exe的绝对路径替换,kindle.exe位于tool\kindle.exe)
如果想将一个名为 `book.opf` 的文件转换为 mobi 格式,并指定输出文件名为 `book.mobi`,就在 cmd 中输入以下命令:
kindlegen.exe book.opf -o book.mobi
完成本程序用到的主要文章链接(含源代码)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









