









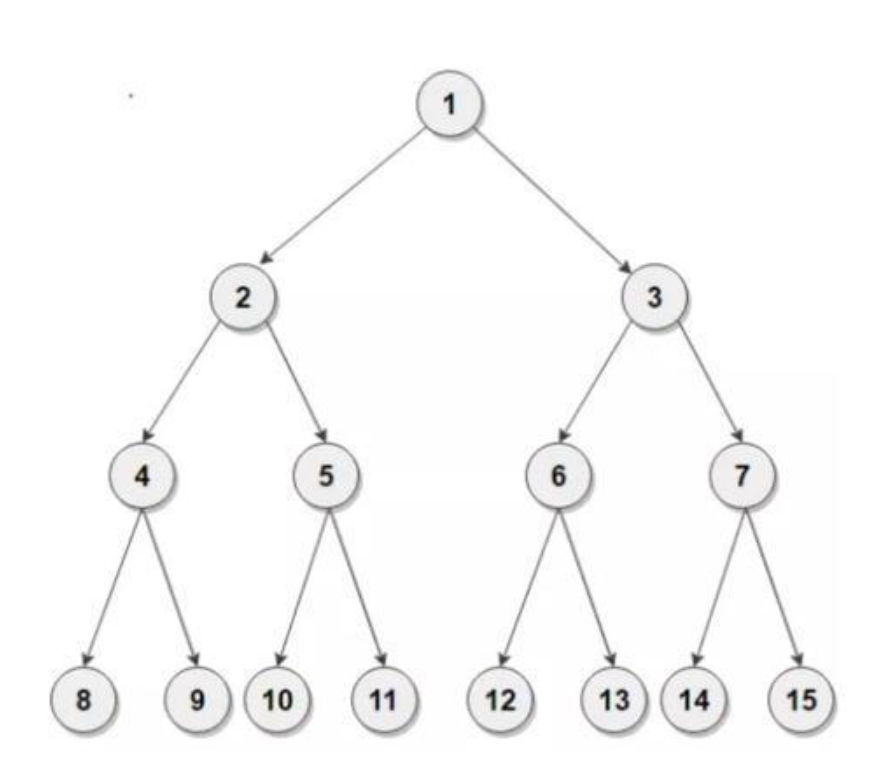
1. 概念
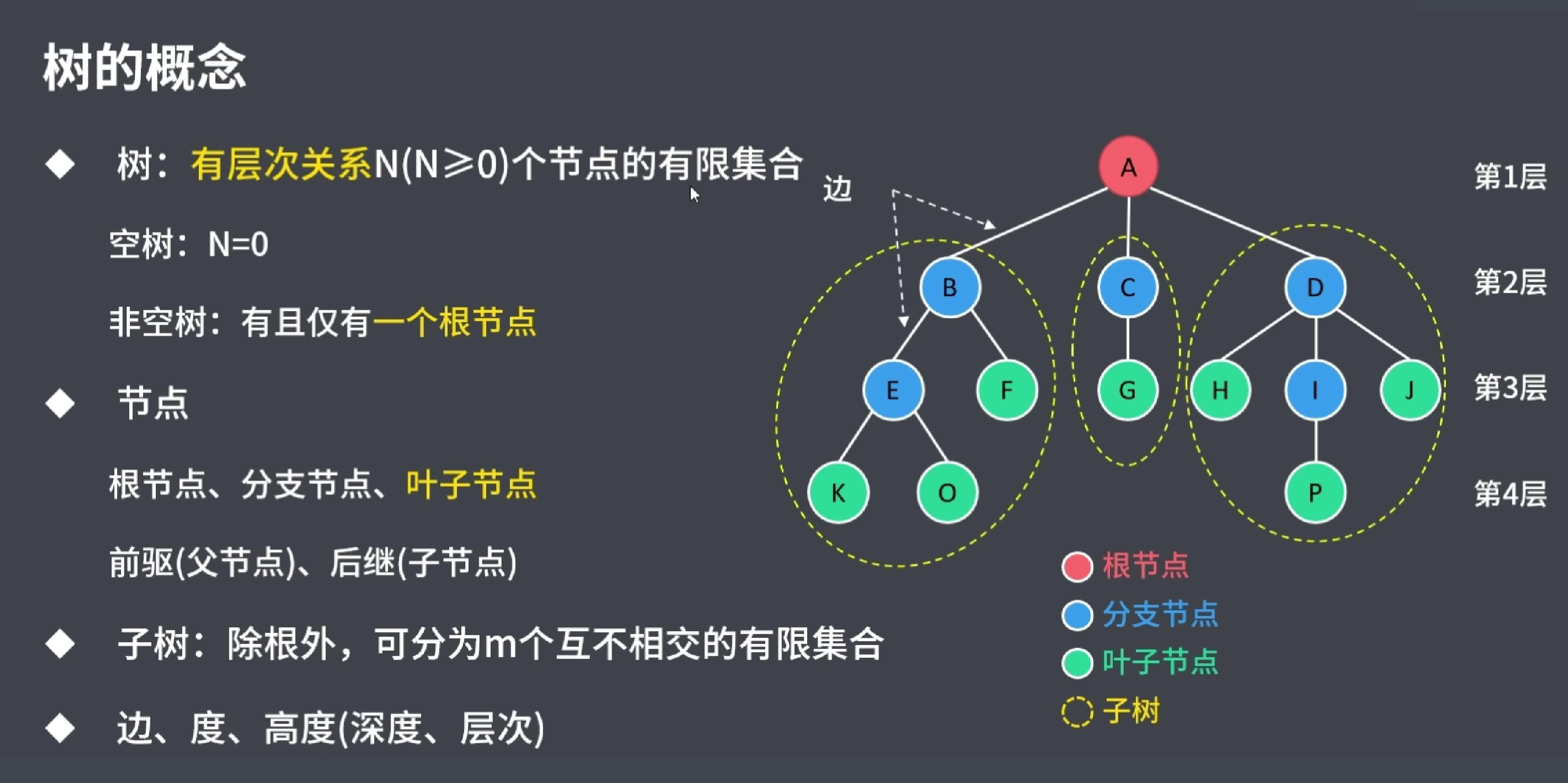
root:根节点
子节点:2、3是子节点,而4、5、6、7、8是2、3的子节点
叶子节点:4、6、8、9、10、11这种没后后代的称为叶子结点
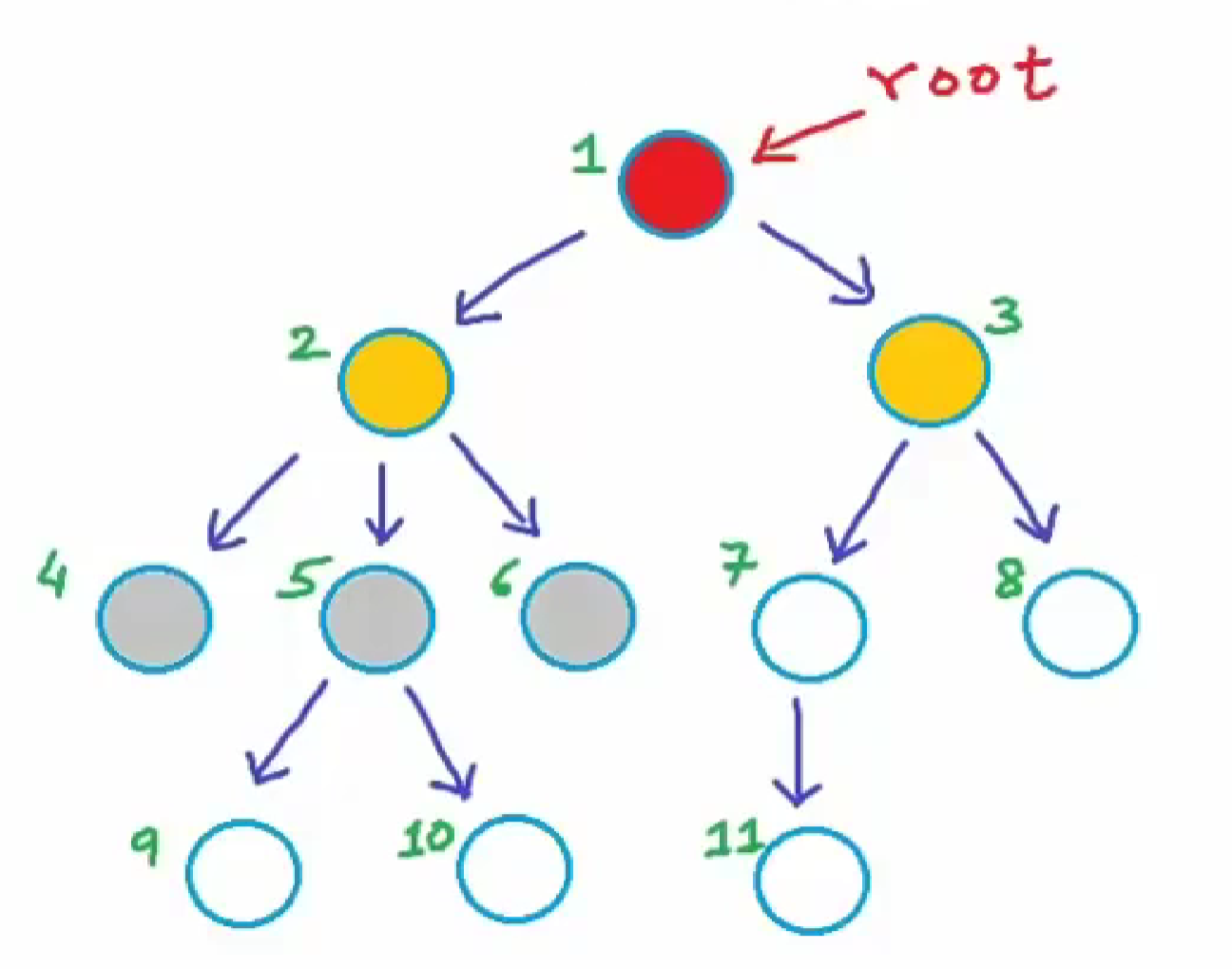
1.1. 边(edges)
除了根节点外,每个节点都会有一个边。在一个有效的树结构中,边=node-1

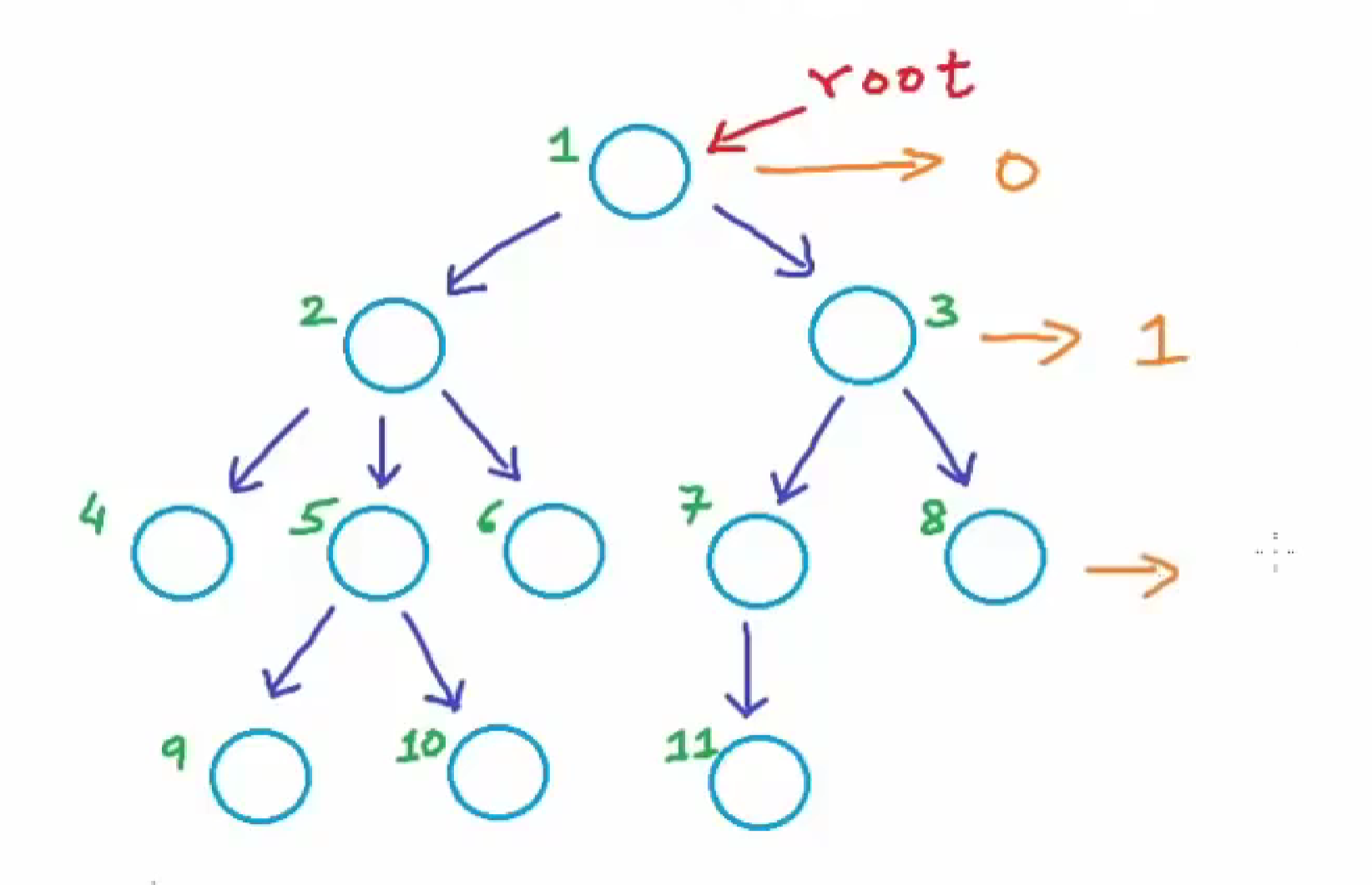
1.2. 深度
root:root的深度为0
2、3的深度为1
4、5、6、7、8深度为2
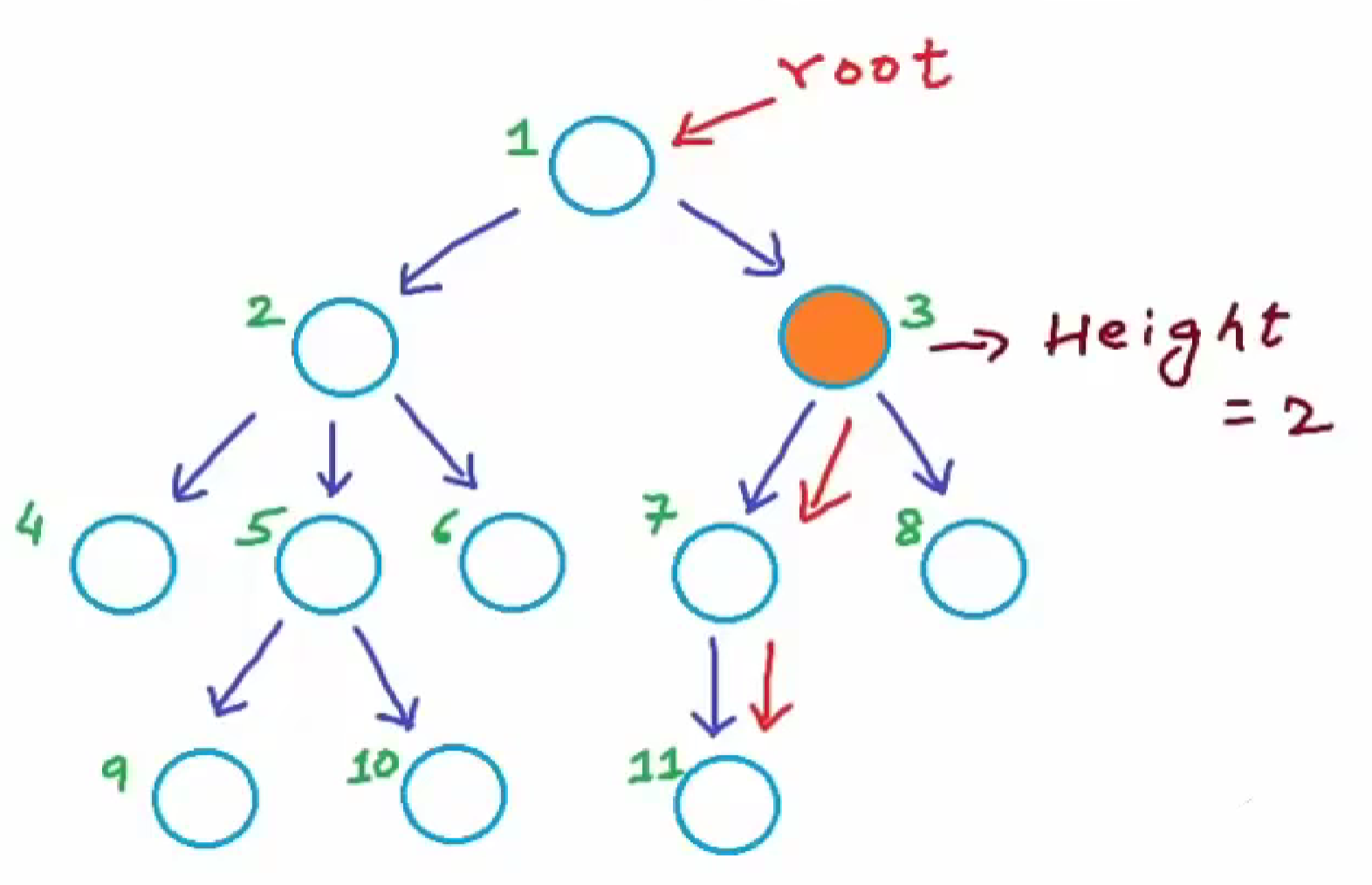
1.3. 高度
定义:从该节点到一个叶子节点的最长路径的边数
节点1的高度为3。
节点3的高度为2.
2. 种类
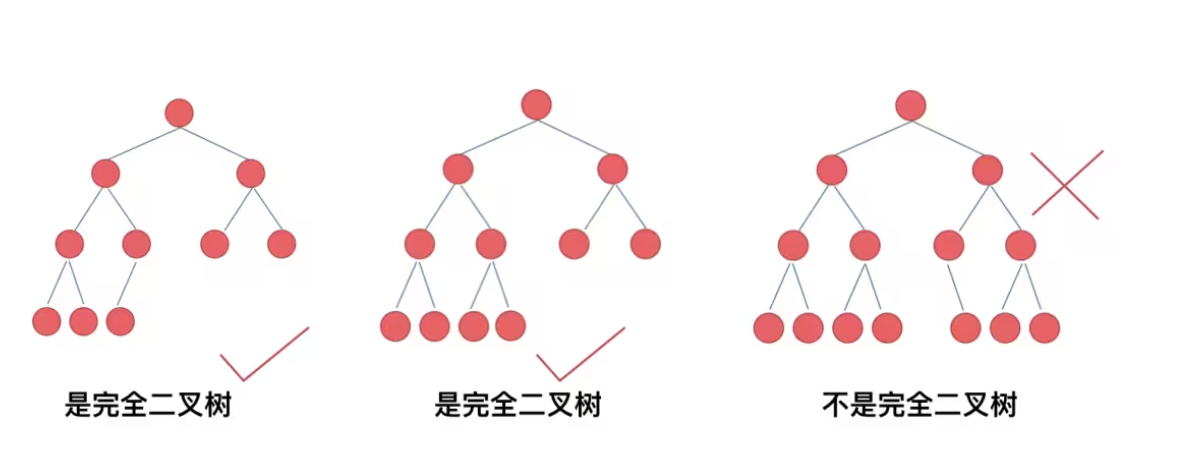
- 满二叉树
- 如果一棵二叉树中所有非叶子节点都有两个子节点,且所有叶子节点都在同一层上,则这棵二叉树为满二叉树。
特点:所有非叶子的节点均有左右子节点
- 完全二叉树
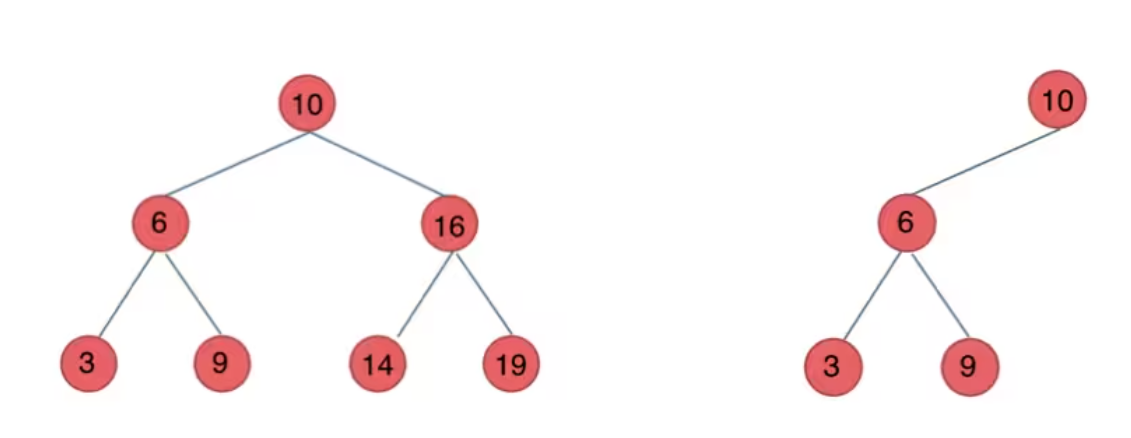
- 对于树中的每个节点,左子树中的所有节点的值都小于该节点的值
- 对于树中的每个节点,右子树中的所有节点的值都大于该节点的值
- 左子树和右子树也是二叉搜索树。
特点:节点由上到下,左到右排列
- 二叉搜索树
- 对于二叉搜索树中的每个节点,其左子树中的所有节点的值都小于它的值,而右子树中的所有节点的值都大于它的值。
- 对于二叉搜索树中的任意节点,其左子树和右子树也分别是二叉搜索树。
这个特性使得二叉搜索树具有如下特点:
- 对于任意节点,其左子树的值都小于该节点的值,右子树的值都大于该节点的值,这使得在二叉搜索树中查找、插入和删除操作都具有较高的效率。
- 二叉搜索树中的中序遍历是一个有序序列,可以很方便地进行有序性操作。
由于二叉搜索树的性质,它常被用于实现一些常见的数据结构和算法,例如集合、映射等。然而,需要注意的是,二叉搜索树的性能可能会受到树的平衡性的影响,不平衡的二叉搜索树可能会导致性能下降,因此出现了一些基于二叉搜索树的平衡算法,如 AVL 树、红黑树等。
特点:每个节点值大于等于左子节点值且小于等于右子节点值
3. 二叉树结构
二叉树是一种常见的树形数据结构,它由节点组成,每个节点最多有两个子节点,分别称为左子节点和右子节点。以下是二叉树的结构定义:
// TreeNode 表示二叉树的节点
type TreeNode struct {
Val int // 节点的值
Left *TreeNode // 左子节点
Right *TreeNode // 右子节点
}
在这个结构中,每个 TreeNode 都有一个整数值 Val,以及指向左右子节点的指针 Left 和 Right。如果某个节点没有左子节点或右子节点,则相应的指针为 nil。
使用这种结构,可以构建不同形态的二叉树,例如:
goCopy code
// 示例二叉树
// 1
// / \
// 2 3
// / \
// 4 5
root := &TreeNode{
Val: 1,
Left: &TreeNode{
Val: 2,
Left: &TreeNode{Val: 4},
Right: &TreeNode{Val: 5},
},
Right: &TreeNode{Val: 3},
}这个示例中的二叉树具有四个节点,根节点的值为 1,左子节点的值为 2,右子节点的值为 3,它的左子节点又有两个子节点,分别为 4 和 5。
4. 二叉树的遍历的三种方式
二叉树的遍历方式有三种:先序遍历、中序遍历和后序遍历。这里是它们的简要描述:
- 先序遍历(Pre-order traversal):
-
- 先访问根节点。
- 然后按照先序遍历的方式递归地访问左子树。
- 最后按照先序遍历的方式递归地访问右子树。
- 中序遍历(In-order traversal):
-
- 先按照中序遍历的方式递归地访问左子树。
- 然后访问根节点。
- 最后按照中序遍历的方式递归地访问右子树。
- 后序遍历(Post-order traversal):
-
- 先按照后序遍历的方式递归地访问左子树。
- 然后按照后序遍历的方式递归地访问右子树。
- 最后访问根节点。
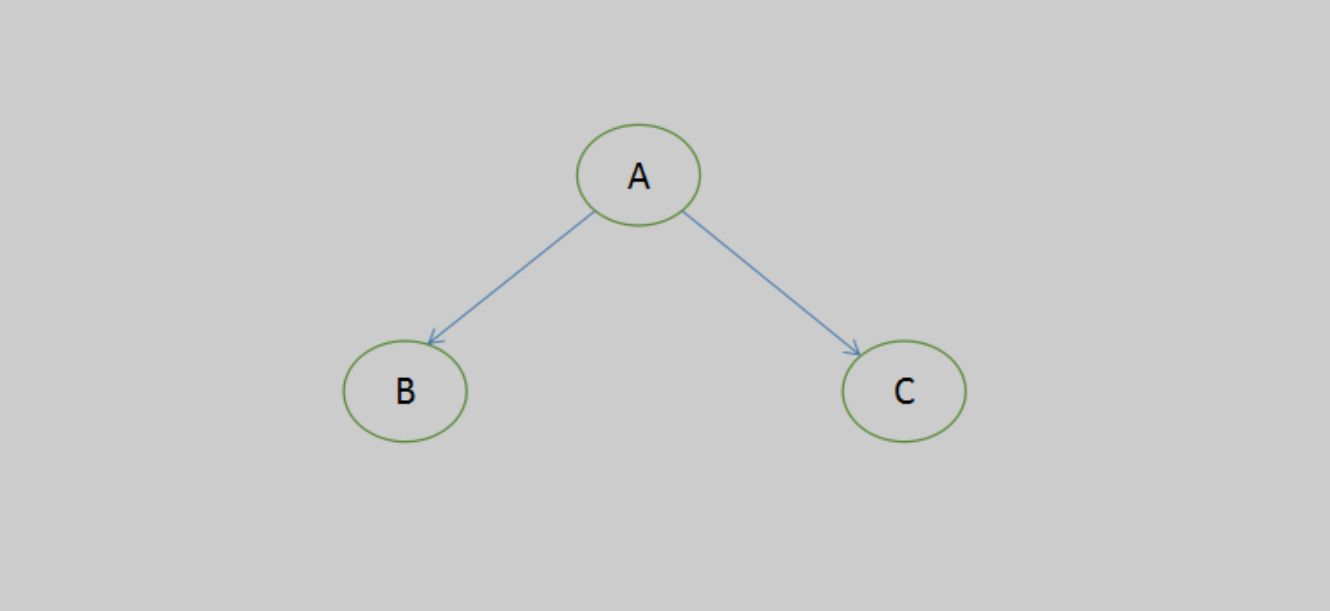
比如上图正常的一个满节点,A:根节点、B:左节点、C:右节点
- 前序顺序是ABC
- 中序顺序是BAC(先左后根最后右)
- 后序顺序是BCA(先左后右最后根)
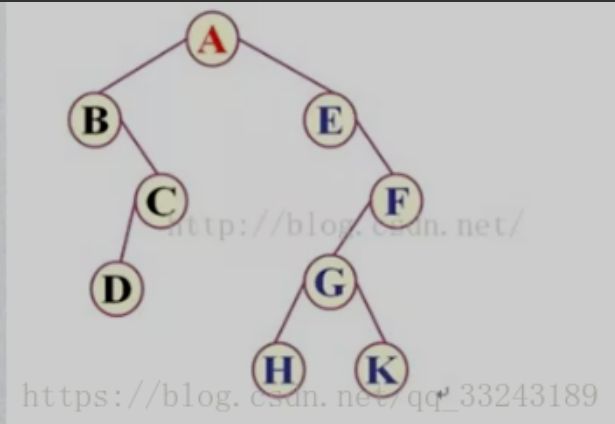
比如上图二叉树遍历结果
前序遍历:ABCDEFGHK
中序遍历:BDCAEHGKF
后序遍历:DCBHKGFEA
















 35万+
35万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









