






场景:现有一张人员导航表,内容如下,id是每条数据主键,human_id是人员id,nav_id是导航id
需求:现在人员导航表内有多条重复的人员导航关联数据(人员导航数据重复),需要删除human_id和nav_id都重复的数据,使表内human_id和nav_id相同的数据只有一条(每个人员导航数据都只有唯一一条)
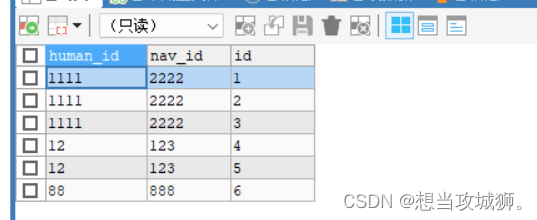
思路:
1、首先统计表内human_id和nav_id重复的数据条数
SELECT human_id,nav_id, COUNT(0) AS num
FROM test1
GROUP BY human_id, nav_id
HAVING COUNT(0) > 1执行结果如下:
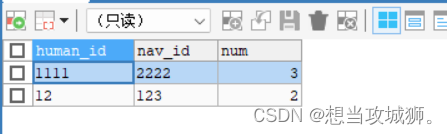
这里可以看到重复的数据有两条
2、查找出要保留的数据(这里假设保留重复记录中id最小的一个)
SELECT human_id,nav_id,MIN(id) AS id
FROM test1
GROUP BY human_id, nav_id执行结果如下:
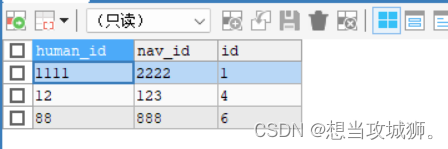
这里也可以和原表进行对比,确定下本步骤的查询结果是否是要保留的数据
3、步骤2的查询结果(要保留的数据)和原表数据对比,可以联想到,原表数据减去要保留的数据就是要删除的数据,那么此时可以使用左连接(left join)
question:这里为什么会想到要用左连接?
answer:下一步要筛选出要删除的数据,此步是为了下一步做铺垫,方便更直观展示出要删除的数据(最好的办法就是将原表与要保留的数据对比,左连接就可以实现)
注意点:左连接和右连接都是需要加on条件的,内连接不需要加on条件
SELECT * FROM test1 t1
LEFT JOIN (
SELECT human_id,nav_id,MIN(id) AS id
FROM test1
GROUP BY human_id, nav_id
) t2
ON t1.human_id = t2.human_id AND t1.nav_id = t2.nav_id执行结果如下:
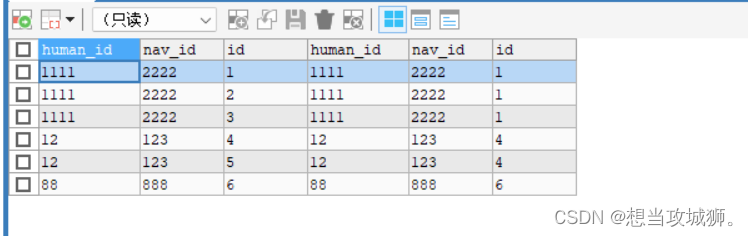 这里很容易看到,第一条,第四条,第六条数据就是我们想要保留的,第二、三、五条数据是我们要删除的,那么下一步就是要筛选出我们要删除掉的数据
这里很容易看到,第一条,第四条,第六条数据就是我们想要保留的,第二、三、五条数据是我们要删除的,那么下一步就是要筛选出我们要删除掉的数据
4、查询出要删除的数据(此步加了WHERE t1.id > t2.id )
SELECT *
FROM test1 t1 LEFT JOIN (
SELECT human_id,nav_id,MIN(id) AS id
FROM test1
GROUP BY human_id, nav_id
) t2
ON t1.human_id = t2.human_id AND t1.nav_id = t2.nav_id
WHERE t1.id > t2.id 执行结果如下:
 5、最后一步,将上一步的select * 改成delete t1 (这里可以将t1理解为上一步查询出来的要删除的记录)
5、最后一步,将上一步的select * 改成delete t1 (这里可以将t1理解为上一步查询出来的要删除的记录)
DELETE t1
FROM test1 t1 LEFT JOIN (
SELECT human_id,nav_id,MIN(id) AS id
FROM test1
GROUP BY human_id, nav_id
) t2
ON t1.human_id = t2.human_id AND t1.nav_id = t2.nav_id
WHERE t1.id > t2.id 执行结果为(与步骤二数据对比,可以发现,表内数据现在就是要保留的数据):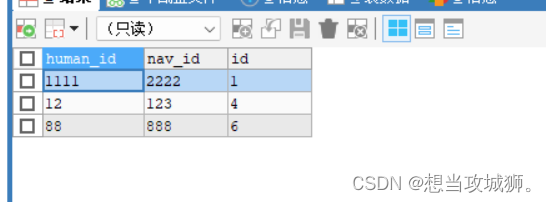















 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









