






1.地址
ERA5 hourly data on pressure levels from 1940 to present (copernicus.eu)
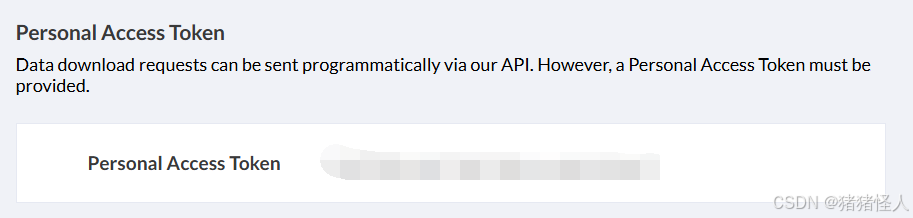
更新cdsapi库、更新token(新版和旧版的token不一致)
2.选择变量、时间、空间、格式
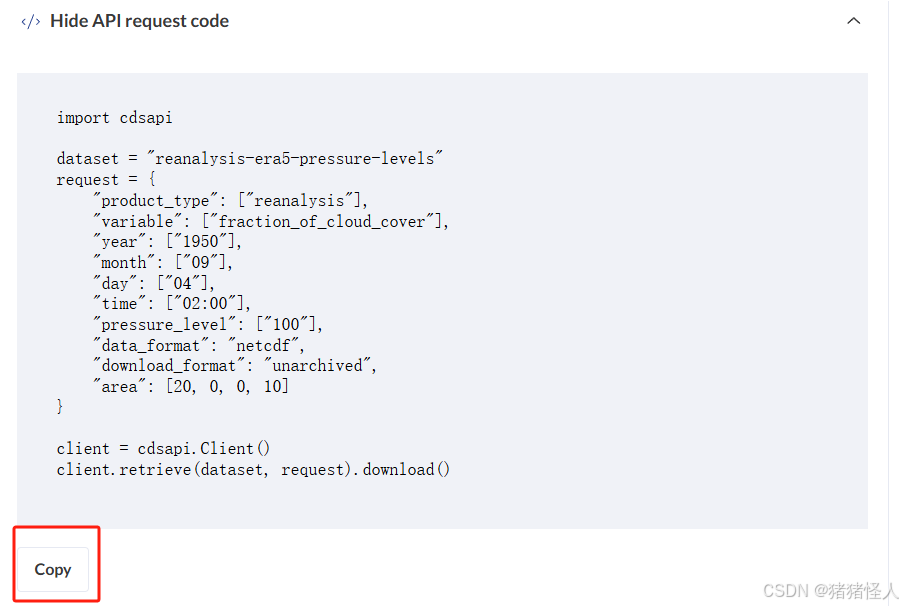
也可以直接提交表单,从浏览器下载。完整代码:
import cdsapi
dataset = "reanalysis-era5-pressure-levels"
request = {
"product_type": ["reanalysis"],
"variable": [
"u_component_of_wind",
"v_component_of_wind"
],
"year": ["2022"],
"month": [
"01", "02", "03",
"04", "05", "06",
"07", "08", "09",
"10", "11", "12"
],
"day": [
"01", "02", "03",
"04", "05", "06",
"07", "08", "09",
"10", "11", "12",
"13", "14", "15",
"16", "17", "18",
"19", "20", "21",
"22", "23", "24",
"25", "26", "27",
"28", "29", "30",
"31"
],
"time": [
"00:00", "01:00", "02:00",
"03:00", "04:00", "05:00",
"06:00", "07:00", "08:00",
"09:00", "10:00", "11:00",
"12:00", "13:00", "14:00",
"15:00", "16:00", "17:00",
"18:00", "19:00", "20:00",
"21:00", "22:00", "23:00"
],
"pressure_level": ["1000"],
"data_format": "netcdf",
"download_format": "unarchived",
"area": [35, 118, 31, 122]
}
target = "2020_wind.nc" #此处修改文件名称、后缀
client = cdsapi.Client()
client.retrieve(dataset, request).download()
完毕!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









