









所以我尝试通过正则表达式元字符和正则表达式在线工具对代码进行逐字逐句的分析。
我将这段代码分为4行进行分析
preg_match //1
("/\b(?:(?:https?|ftp):\/\/|www\.) //2
[-a-z0-9+&@#\/%?=~_|!:,.;]* //3
[-a-z0-9+&@#\/%=~_|]/i",$website) //4
第1行,preg_match()用于正则表达式的匹配,我们常用的是
p
a
t
t
e
r
n
以及
pattern 以及
pattern以及subject,也就是匹配模式和要匹配的字符串。这是一个函数。
第2行("/\b(?:(?:https?|ftp):\/\/|www\.)
首先,这段字符串的两个"/“是一个定界符,delimiter,用来定义开始和结束。没有这个定界符就会报错。

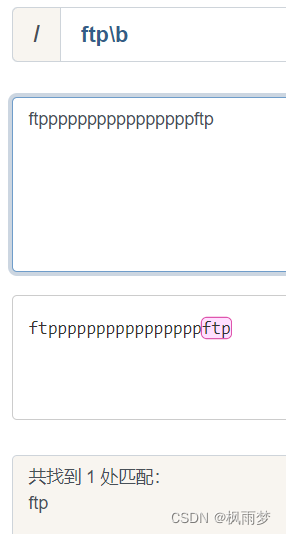
“\b"表示匹配一个单词边界,例如,”\bftp"表示"ftp"匹配单词开头是ftp,可以匹配"ftppppppp”;“ftp\b"表示匹配单词结尾是ftp,可以匹配"fffffffffftp”。括号表示一整个区域。


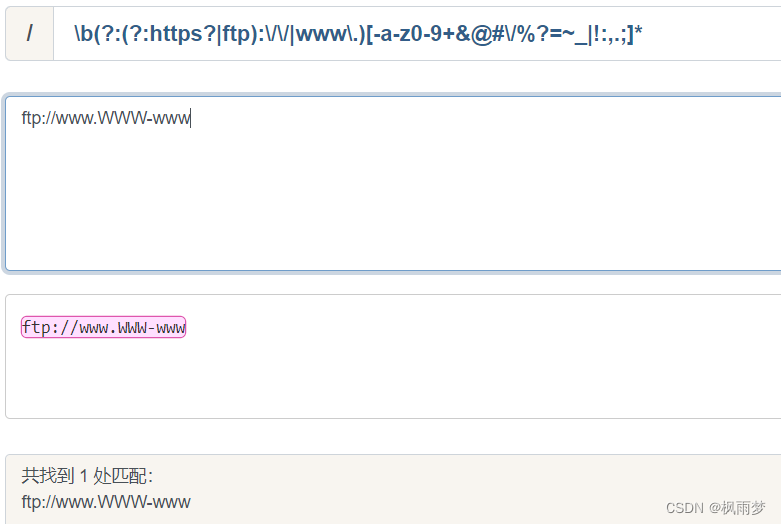
("/\b(?:(?:https?|ftp):\/\/|www\.)中的"?"表示匹配1个或0个,效果等价于{0,1},也就是说,"https?"的意思是,你输入的网址开头部分可以是http,也可以是https。
"?:“可以和”|"组合在一起用,可以理解为,匹配a或者匹配b都可以。
简化一下就是?:a|b
也就是说,内层的?:a|b,其实就是对你输入的字符串做一个模式的匹配,只能输入http(s)或者ftp,加上后面的:\/\/,连起来就是http://或https://,或者ftp://。
外面还有一层?:()|www\.,其实原理都是一样的,就是加上一个,你还可以匹配www这个字符串,也就是说,通过这个模式,我们最终可以输入的URL开头不外乎这几种:
1、http://
2、https://
3、ftp://
4、www.

接下来我们来分析代码的第3行
preg_match //1
("/\b(?:(?:https?|ftp):\/\/|www\.) //2
[-a-z0-9+&@#\/%?=~_|!:,.;]* //3
[-a-z0-9+&@#\/%=~_|]/i",$website) //4
中括号里面的内容就是要任意匹配的字符的集合,[str]*的中括号外面的*表示匹配中括号中的任意一个字符零次或多次。
第4行同理(但是我搞不懂为什么要多加这一段)
最末尾的i表示ignore,不区分大小写,也就是说,www.WWW这样的输入也是正确的URL。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









