






谈起数据库就不得不说MySQL了,对于MySQL主要分几部分来说:数据库特性、数据库索引、索引结构、索引优化、数据库事务、数据库日志、分库分表。这个顺序可是别有用心的呦!
数据库特性:
- 关系型数据库与非关系型数据库的区别:关系型常见有SqlServe、MySql、Oracle;非关系型常见有MongoDB、Redis。
- 非关系型数据库可存储:基础类型、对象、集合等格式(键值、文档、图片等) ,存在缓存中;而关系型数据库存储:仅基础类型,数据存在硬盘中。
- 关系型数据库的SQL语句可执行单表或多表间复杂的数据查询,且支持事务。
- 在MySQL中int最大4字节、 bigint最大64bit、 row_id(无符号位)所以最大2^48-1(当超过最大值时会索引从0重来,用新值覆盖旧值),而自增ID用完会报主键冲突异常,改用bigint型8字节=64bit=2^64-1,无需符号所以是2^64-1而非2^63-1。
- Hash表存储数据精准查询快,但不支持范围查询需要全表扫描,不支持排序和分组。
- 自适应哈希索引:因频繁访问的数据去(内存或磁盘B+树)中查找,Hash索引的存储方式耗费空间且Hash冲突多时会链式存储。自适应哈希索引记录访问数据位置,加快查频繁访问的数据,但因其不支持排序分组,MySQL会判断是否值得建自适应哈希索引。
- 数据脱敏:即敏感词汇用*表示,只有高权限可访问,或需申请访问、洗库:利用数据库信息非法牟利、撞库:利用用户在其它网站登录的信息尝试登录数据库、拖库:sql注入或文件上传漏洞进行入侵。
数据库索引:
- 索引往往存在磁盘上的,分为单独的索引文件和数据与索引存在一起。即非聚集索引和聚集索引。
- InnoDB:聚集索引、支持事务、支持行锁、支持外键、不保存行数(select count(*) from A无索引时会全表扫描)。
- MyISAM:非聚集索引、不支持事务、不支持行锁、不支持外键、 保存行数(通过一个变量记录行数)。
- 数据库存储结构(表、段、区、页、行):表、段是逻辑结构方便管理、区是物理磁盘结构,一张表千万级数据,数据再分页。
- 页:IO最小单位默认16KB,一页可以存储(上千条页号或几十条甚至更多条数据)。
- 行:存储数据的单元,一页(叶子节点)内的多行数据也可以建立索引,以主键或隐藏主键等。
- 索引类型:主键索引、唯一索引、全文索引、普通索引,还有联合索引、前缀索引等(与索引类型区分开)、以及覆盖索引(避免回表)方式。下面说一下不常介绍的几个。
- 前缀索引:字段前n个字符为索引,实际业务衡量n值 (如可以是某3个字段的各自的前20个字符组成索引,也要遵循联合索引规则)。其可以解决索引过长问题 UNIQUE KEY `table` (`name`(20),`account`(20), `city`(20))。
- 确定前缀索引n值,前缀的选择性=全列选择性时,即离散度越高索引效果越好,某列前缀选择性SELECT count(distinct left(列名, 前缀长度)) / count(*) FROM table 为1最大。
- 前缀索引:优点是占用空间小且查询快,缺点是无法使用order和group、无法覆盖扫描、可能会增加扫描行树。
- 跳跃索引:MySQL8支持,在联合索引中:前面的索引唯一值少,后面的索引唯一值多,则跳跃索引。
- 无索时引,读硬盘中表的部分数据(因为内存空间小于硬盘空间),所以在硬盘中读取,加载到内存中筛选,多次操作达到全表数据筛选完。
数据库结构:
- 为什么不是红黑树:因为其只有2叉在搜索数据时需要的IO次数多,节点存储数据少,远不足16KB会浪费空间。
- 为什么不是二叉树:缺点和红黑树一致,且极端情况会形成链表。
- 为什么不是平衡二叉树:虽然解决二叉树存储有序数据形成链表问题,但还是存在和红黑树一样的问题,且平衡操作过多会影响性能。
- 为什么不是B树:虽然解决AVL树节点存数据少远不足16KB和树深度高需要IO次数多的问题,但不如B+树更具优势。B树节点存储关键字+数据地址+子节点地址、分叉数=关键字数+1。
- B+树:相比B树,节点存关键字多则1次磁盘读更多关键字、仅叶子节点存数据IO次数稳定、叶子节点数据连成双向链-扫表与排序更强。B+树非叶子节点存储关键字+子节点地址、叶节点存=数据、分叉数=关键字数。
- B+树的1个节点存储:1页或n页则最优(n为整数),因为每次读取单位就是页,如果存储1.2页数据,则仍会读2页的空间,浪费了空间。
- 索引需要有序是因为叶子节点数据在磁盘上顺序存储,数据结成双链表,索引有顺序时会使最后1页为不满状态,在此页插入后序索引。如果插无序的索引数据,则B+树会调整,造成已满数据的页可能会分裂再重排序,再有序,频繁操作会影响性能。
- 为加快读写速度,B+树叶子节点数据顺序结成双链表,每页数据在磁盘上顺序存储。节点顺序存储+磁盘顺序寻址+磁头预读=磁头寻址少+预读命中高。
- B+树形成规则:正常建立索引也会页分裂进行变形,但分裂次数不多。
- B+树每个节点其关键字个数等于分叉数。
- 每个非叶子节点(除了根节点)至少有 (关键字/2)的子节点个数。
- 如果根节点不是叶子节点,则根节点至少要有两个子节点。
- 所有叶子节点都在同一水平,高度一致。
- 所有非叶子节点中仅含有其子树根结点中的最大或最小关键字。
数据库优化:(时刻考虑非主键构建的索引树,涉及回表、索引覆盖内容)
- 索引不适使用uuid等无顺序字段,否则插入时易造成B+树结构频繁分裂,性能下降。
- 主键索引字段不应过长,这样辅助索引的叶子节点能存更多主键,保证一次访问更多主键。
- 频繁更新的字段、离散度低(重复度高)的字段、不适合创建索引。
- where条件、order排序、join连接适合创建索引。
- 索引过多也不好:会需要更多额外空间存储、修改的效率较低。
- 索引失效:索引列使用函数运算、字符串不加 ’ ’ 、like ‘%查’、以及某些反向查询都会让索引失效。
- 索引是否被使用取决于优化器:最终根据最优策略决定是否用索引。
- 辅助索引查范围数据,优化器判断,若所查范围内数据量>80%~90%,则选全表扫描,优化器并非一定(索引)查,而选是最优查询策略,最优并非最快查询,而是综合性能(IO读写、CPU操作、查询时间、占用空间、执行效率)的最优。
- 最左匹配原则是因B+树节点关键字从左到右,则where条件也要按顺序一一对应。如where a=1 and b=2 and c>3 and d=4时,(a,b,c)可以最左匹配,因c范围查询则d不可继续匹配。
- 联合索引:索引字段用><、in、like "ab%"、between and,后面的索引字段不再使用索引。
- 索引下推:指联合普通索引首个条件过滤后,第二条件过滤,后序再过滤,最后确定查询范围,再回表找主键。因数据比较在Server层,索引比较在存储引擎进行,最后回表减少索引引擎操作,提高性能。
- 查询行数时:select count(*) from A(MySQL5.6后不再是全表扫描)与select count(1) from A。在有主键索引/辅助索引条件下的最优策略查表行数语句。
- select count(b) from A 只查b列不为Null的行数,而explain统计行数是采样估值。
- select *需解析数据字典,没有索引覆盖优化,但后续修改列名没有影响、select 具体列名则相反。
- 全文索引(比like ‘%某%’查询效率高):例如where a like "%某%",改为 match(a)against("某")。但text类型会消耗大量网络资源和IO次数,而单表中最多16个索引。
- char长度固定,在建表时声明(1~255)存储时会空格填充,检索时会删尾部空格。varchar长度可变,可指定最大长度,无需空格填充。
- 数据连接池的连接数一般约等于CUP核心数时最佳,减少线程切换,效率更快。而线程阻塞场景下线程多则快,常用有效线程数=2倍连接数。
- SQL语句优化中,select语句含子查询(或函数)会慢:因为每输出1行就执行一次子查询。
- MySQL执行计划explain(type)各值意义:设下例id为主键。
- ALL(扫描全表):select id,name from table。因查询了包含非索引字段所以为ALL,例如查询*。
- Index(扫描主索引树):select id from table。查询的字段是主键或联合主键中的字段,区别于索引覆盖Index没有where id 的条件。
- Range(扫描范围主键):如between、<、>=查询,例如select * from table where id>3。当条件列为主键时只扫描主B+树。
- Ref(普通索引的=条件查找):如设name为普通索引,select * from table where name = 'a'。区别于需要回表的查询Ref仅为=条件时。
- eq_ref(唯一索引数据):表的普通索引与另外表的主键关联,每条数据唯一对应。不能为一对多或无对应且结果集的数据唯一,不能重复。
- const(主键索引的=条件查询):select * from table where id=1。
- system:所查询的表(子查询结果集)仅1条数据select * from (select * from table where id = 1)。system是理想状态,实际可能const或all,取决于子集是否使用主键索引条件。
- NULL:不访问表或索引直接获得结果,如select 1 from table where 1=1。
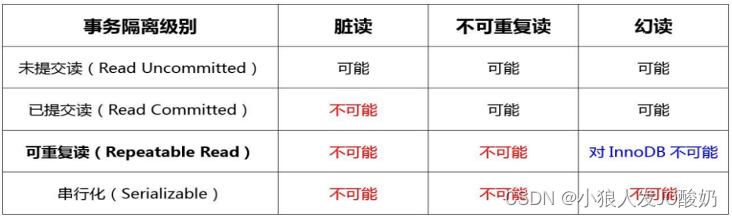
数据库事务: (InnoDB在分布式情况下采用可串行化)
- InnoDB引擎下,MVCC可解决select不可重复读。可串行化的3种锁解决update、delete、以及加锁select的不可重复读问题。MySQL行锁需要锁在索引上,无索引则会锁全表。
- 读未提交(RU)、读已提交(RC)、可重复读(RR)、串行化,LBCC(读也加锁)保证事务。
- MVCC:快照旧版本数据:创建版本号、删除版本号,只查询创建时间(版本号)<=当前事务ID和删除时间(版本号)>当前事务ID,即查询开启事务后删除的数据。
- 脏读:A事务中查询,B事务update/add/del后-未提交,但A事务中再次查询不一致。
- 不可重复读:A事务中查询,B事务update/del后-提交,但A事务中再次查询不一致。
- 幻读:A事务中范围查询数据,B事务add后-提交,但A事务中再次范围查询多出n行。
- 当前读(加锁select读): 读的是最新版本,读的记录加锁,阻塞其他事务,避免同时改相同记录。通过加(记录锁、间隙锁、临键锁)实现。
- 快照读:普通的select读。RR隔离级别,开启事务后第1个select语句才进行快照,之后会读取快照内容。
- 快照读(默认RR):通过MVCC(多版本控制)和undo log实现,快照读使用MVCC解决幻读。但并非完全意义上的解决幻读。如数据库2条数据,A开启事务后但未执行select时(不生成快照),此时B插入1条数据,A执行select获取3条数据。因为MVCC在首次select后才生成快照。
- 开启事务后,则数据就已锁定,才为完全意义上的解决幻读。
- InnoDB锁:表锁(意向共享锁,意向独占锁)、行锁(共享锁,独占锁)。
- 意向锁(2种):表无意向锁则可加表锁,表有意向锁则返回失败(说明已加意向表锁)。
- 某行已加(共享锁/独占锁)=全表已加(意向共享锁/意向独占锁)。
- 全表已加(意向共享锁/意向独占锁)=某行已加(共享锁/独占锁)。
- 表含有主键时,行锁会锁住范围内主键行;无索引时,行锁会锁全表。
- 表锁的意义:表的某行数据已加行锁,则表已加锁,其他事务判断已有表锁时会回滚,避免还要扫表判断是否有行锁。
- 不存在主键索引时:默认为(非Null的)唯一索引为主键、若也没有则用隐藏索引自增列row_id,但row_id不可用作主键条件。
- 记录锁会精准锁1行、间隙锁进行锁的范围命中0行(确保阻塞范围内insert,间隙锁相互不冲突)、临键锁则锁的范围会命中多行(额外锁住范围边界至表尾行,避免幻读)。临键锁=(记录锁+间隙锁),且可退化。
- 死锁:获取锁等待超50s、同1时刻多个事务持锁、未释放锁就强行剥离、多事务形成环路。
- 避免死锁:顺序操作多表、顺序批量操作单表数据、使用索引来避免锁表、独占锁操作。
- 数据库并发策略:乐观锁、悲观锁、时间戳,一致性算法Paxos。
- 分布式系统下事务:2PC、3PC、TCC、本地消息事务、最大努力通知。
- Spring开启事务并设置了隔离级别则会覆盖Mysql已有的事务隔离级别。若Mysql不支持该隔离级别,Spring的事务就也不会生效。
- 数据库连接池参数:
- 最小连接数:一直保持的连接数量,若程序对数据库连接使用量不足,则会浪费连接资源。
- 最大连接数:可申请的最大连接数,若连接请求数超过最大值,多出的连接请求加入等待队列中。
- 最大连接数的保活时间、获取连接超时的时间、超时后重试连接的次数。
数据库log(MySQL日志):
- redo log(重做日志):记录了对哪个页做了哪些变更,有缓存也会落地,顺序IO写磁盘更快。变更恢复功能:数据在缓存中则直接更新,数据库挂掉时用记录的变更顺序IO刷写恢复磁盘,更快速。redo log在事务开启时开始记录。
- bin log(二进制日志):记录表结构和表数据的变更,如记录(delete、update、alter等)增删改SQL语句,DDL和DML。恢复数据功能:数据库挂掉后,通过bin log的追加操作记录,恢复数据。bin log在事务提交时记录。
- MySQL原子性是通过写redo log和写bin log同时成功才提交事务,否则会回滚。
- 主从复制流程:(MySQL的3个线程实现主从复制)主库(bin log Dump线程)、从库(启动IO线程、SQL线程):从库启动IO线程连接主库,主库建binlogDump线程读bin log记录发送给从库IO线程。从库(中继日志Relay Log)获取后更新Relay Log,之后从库的SQL线程读Relay Log更新数据库事件并应用。
- 主从复制类型:基于语句复制(从库执行相同SQL语句)、基于行数据的复制、混合复制(语句不精准时行复制,否则语句复制)。
- MySQL接口是同步的,主从复制需要选择方式(全同步、半同步、异步)且存在丢失数据的情况。
- 异步复制模式:响应无影响,用户体验好,但数据可能不是最新的。
- 全同步复制模式:响应受影响,用户体验差,但数据确保是最新的。
- 半同步复制模式:介于2者之间,逐步同步,一般大多数企业采用。
- undo log(回滚日志):记录反向变更和旧数据,例如insert操作就会记录delete,update操作就会记录反向的update。回滚功能:在事务回滚时,因为undo log记录了反操作,即可反向恢复数据库。
- MVCC(多版本控制):因为undo log记录了事务提交前版本的数据,所以可以读取旧数据,实现可重复读。
- MySQL慢查询日志:记录执行时间超过指定时间的查询语句,查找低效率的查询语句,排查有问题的SQL语句,检查当前MySQL性能,但一般不建议启动,因为开启会有性能影响。
数据库分库分表:
- 主从复制+读写分离:(从库备份数据用于读多写少,且防丢失数据)主库数据用于更新、从库用于查询。
- 分库分表场景:大量请求且连接不足造成阻塞、单表数据过大造成SQL全表扫描慢、单库存储大量数据压力增大。
- 水平分库:某个表切分为多个部分数据的表,多个库各放一个。
- 水平分表:同一库里的某个表切分为多个部分数据的表。(根据Hash取模计算表分区、id范围分区、按时间分区)
- 垂直分库:将业务不同的表放在不同的库中。
- 垂直分表:即将表的多个字段切分为多个表。(按业务分、 按关联关系分)
- 复杂场景下一般是混合模式,根据业务需要有所使用。
- 水平分表按范围分表问题(尾部热点):即在插入数据时,总在最后的库上进行。应选用Hash取模分表。
- 分布式下数据库主键ID: 雪花算法生成(符号位1b+时间戳41b+机器ID10b+序列12b)值,特点是ID值定长、有序、分布式下唯一。遇到时间回拨问题可以设置最大容忍。
- 如果为UUID则其数据过长、无序不可读、查询效率低;如果是数据库自增ID(不同步长)成本高、性能有瓶颈;如果用Redis则增加了系统复杂度。
本文为个人总结,涉及到知识点如感兴趣还需详细查阅,相信细心的你们已经发现本章介绍数据库的知识点是相互关联的,由知识点到知识点的底层知识点。才疏学浅介绍不全,见谅见谅,如有错误还请指正,就这样完了,886。















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









