






5.堆
Heap堆
-
通过new关键字,创建对象都会使用堆内存
-
所有的对象实例以及数组都要在堆上分配
-
Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建
-
包含字符串常量池
特点:
-
他是线程共享的,堆中对象都需要考虑线程安全的问题
-
有垃圾回收机制
堆内存诊断
-
jps工具
-
查看当前系统中有哪些java进程
-
-
jmap工具
-
查看堆内存占用情况,jmap -heap 进程id
-
-
jconsole工具
-
图形界面的,多功能的检测工具,可以连续检测
-
-
jvirsualvm
-
图形化界面
-
6.方法区
-
所有虚拟机线程的共享区域
-
存储了和类相关的信息,比如:field成员变量、method data方法数据,以及成员方法和构造器方法代码部分,包括特殊方法就是类的构造器。总之就是放类的相关信息。
-
方法区在虚拟机启动时创建。
-
方法区逻辑上是堆的一个组成部分。概念上方法区是堆的一部分,但是实际上根据jvm厂商决定
-
存储已被虚拟机加载的类信息(如类名、访问修饰符、常量池、字段描述、方法描述(方法描述符是由方法的参数类型以及返回类型所构成。)等)、常量、静态变量、即时编译器编译后的代码、Class对象;
-
包含 运行时常量池、静态常量池、虚方法表
方法区的变更:
Java6和6之前,常量池是存放在方法区(永久代)中的。
Java7,将常量池是存放到了堆中。
Java8之后,取消了整个永久代区域,取而代之的是元空间。运行时常量池和静态常量池存放在元空间中,而字符串常量池依然存放在堆中。
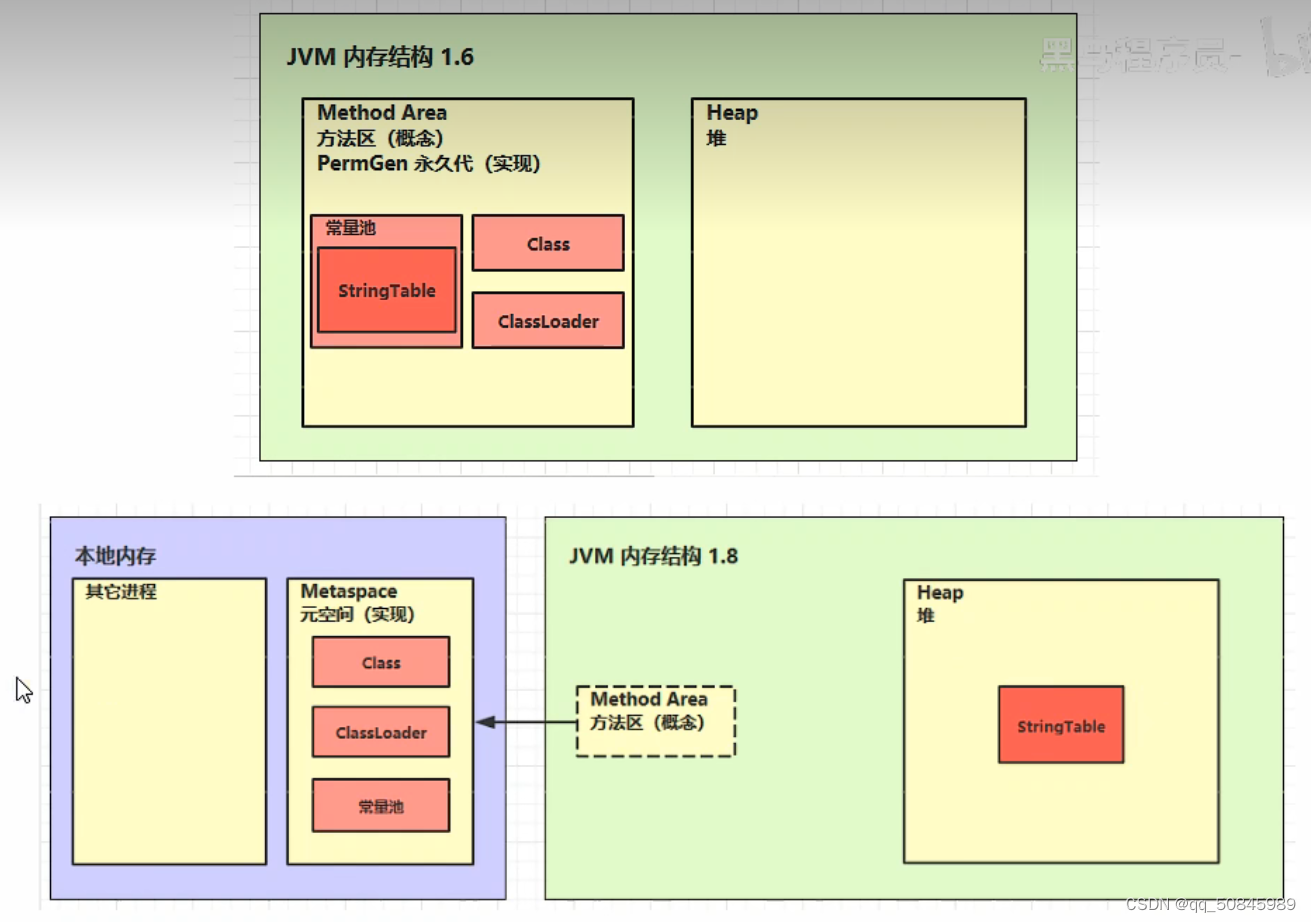
在1.8之后方法区由元空间实现,方法类、类加载、常量池及其他进程,这些都放在本地内存中,也就是操作系统的内存。
方法区内存溢出
动态生成类的字节码,动态的类加载,代理技术广泛应用了字节码动态生成技术
如spring和mybatis中都会用到cglib,spring中用其生成代理类,代理类是aop中的核心。mybatis中用cglib生成mapper接口的实现类。spring会产生大量的运行期间生成的类,也容易发生方法区内存溢出。
常量池
运行代码,会将代码编译为二进制字节码,其中包含:类基本信息、常量池,类方法定义(包含了虚拟机指令)
查看二进制字节码,通过class文件,借助jdk的一个工具,用javap - v 名称.class 来反编译字节码
java代码
类基本信息:
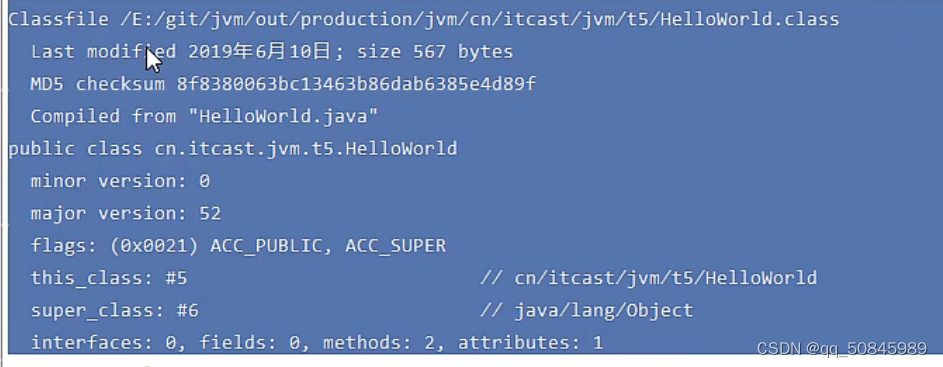
常量池:

类方法定义:
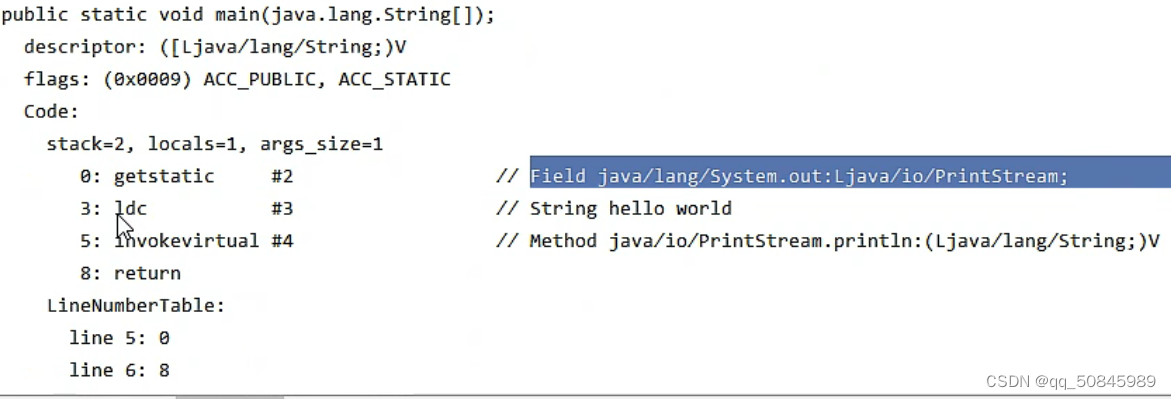
静态成员变量:通过#2找到#21和#22,#21找到#28,#28找到java/lang/system的成员变量。#22找到#29和#30,找到out变量并且其类型是java/lang/system
idc:通过#3找到#23,#23是一个utf8类型的字符串 内容是hello world。
虚方法调用invokevirtual:调用类实例方法,方法引用
常量池
常量池,就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量(字符串、整数、布尔类型)等信息
运行时常量池,常量池就是*.class文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并将里面的符号地址编程变成真实地址。运行时常量池就是放在内存中的位置。
面试题
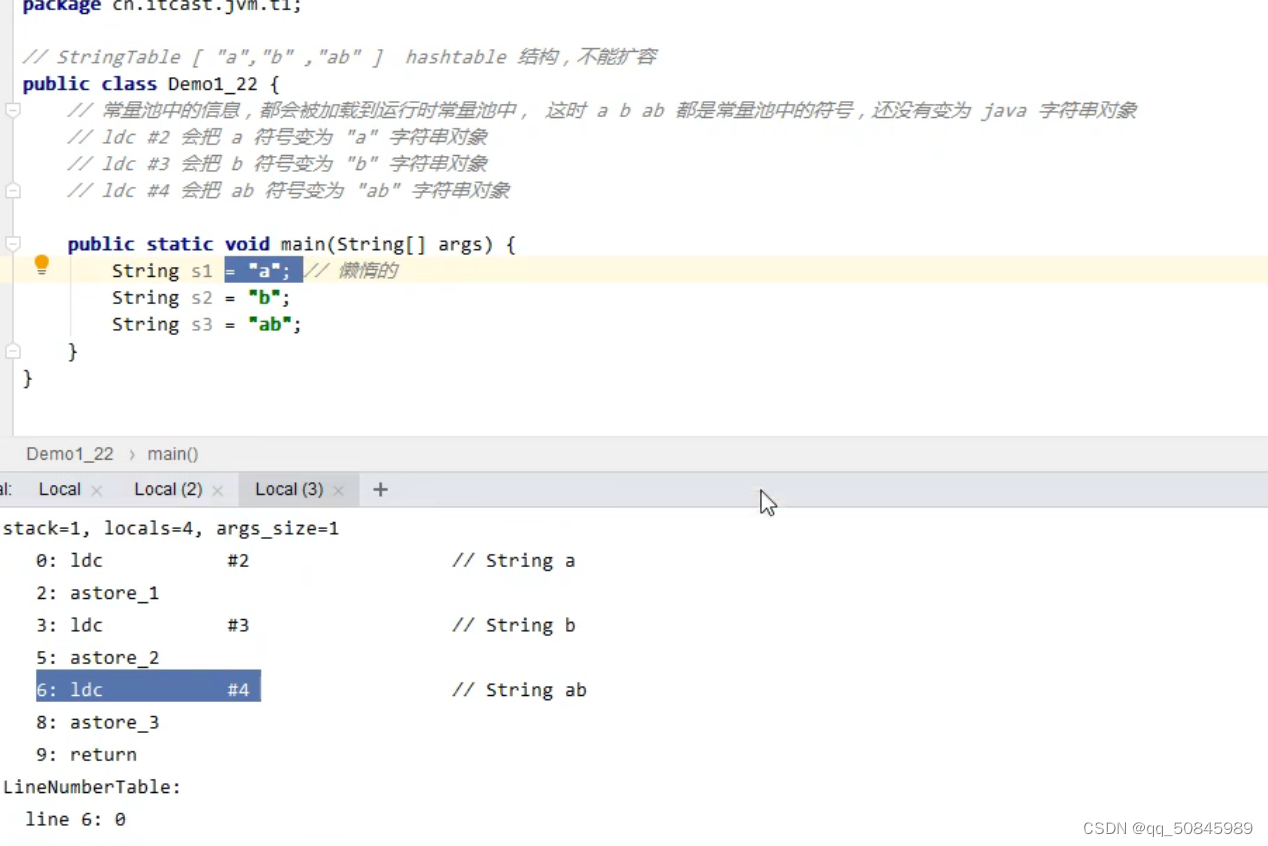
代码会编译为字节码文件,其中常量池中的信息会加载到本地的运行时常量池,也就是放入(StringTable)串池中,并且串池是懒惰的,只有代码执行时才会到串池中找,如果没有才会放入其中,如果有就会使用串池中的对象。
字符串拼接
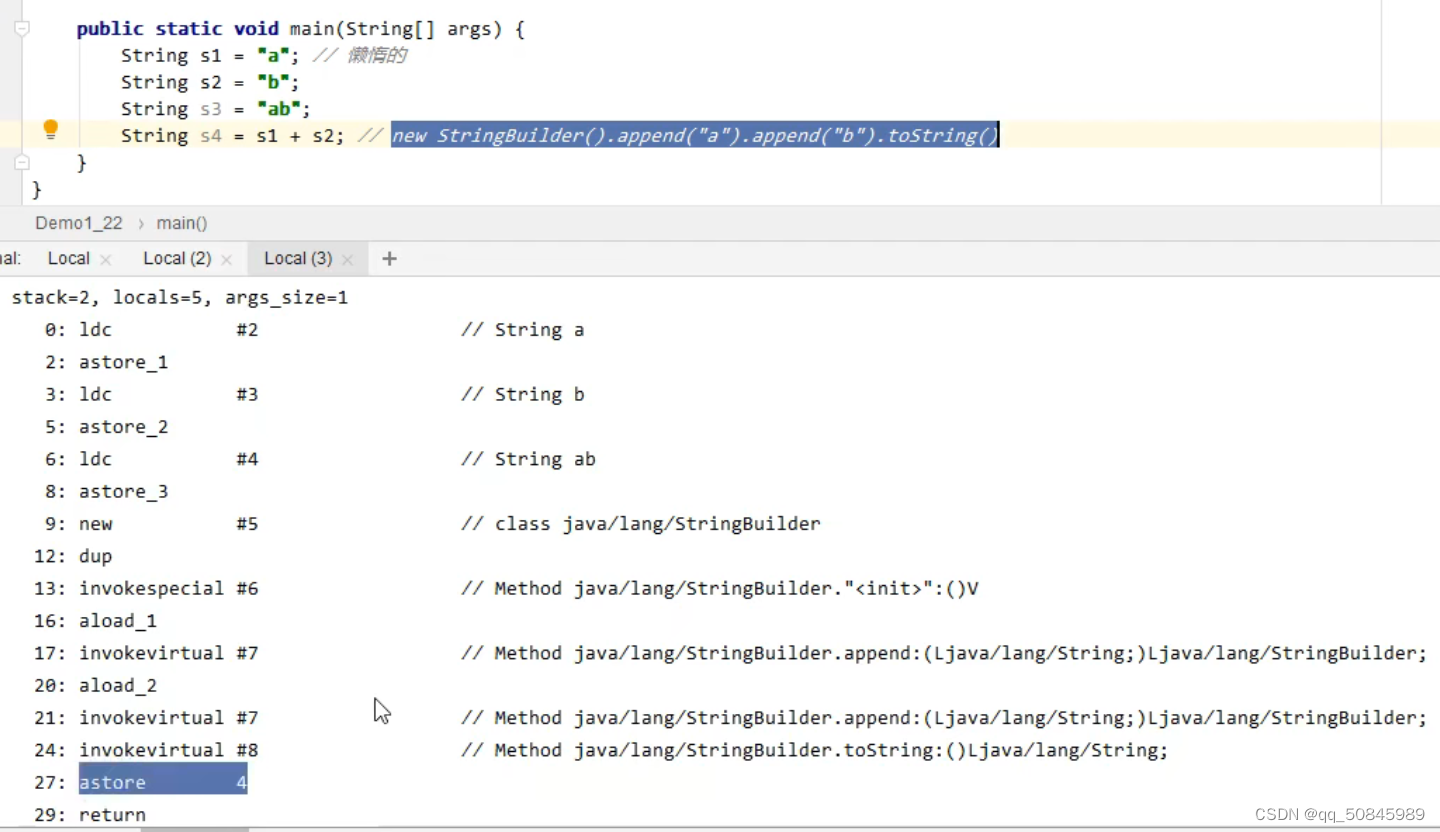
字符串拼接:new一个StringBuilder对象的构造器,准备s1参数,使用stringbuilder方法append,把参数s1放入其中,再准备s2参数,把参数s2放入append方法中,最后使用tostring方法,但是tostring方法是放回一个新创建的string对象,值为刚刚拼接的值。
如果拼接的是确定的字符串,如:String s5 = “a” + “b”; javac在编译期间的优化,结果已经在编译期间确定为ab,只需要再串池中寻找,找不到再在串池中创建。
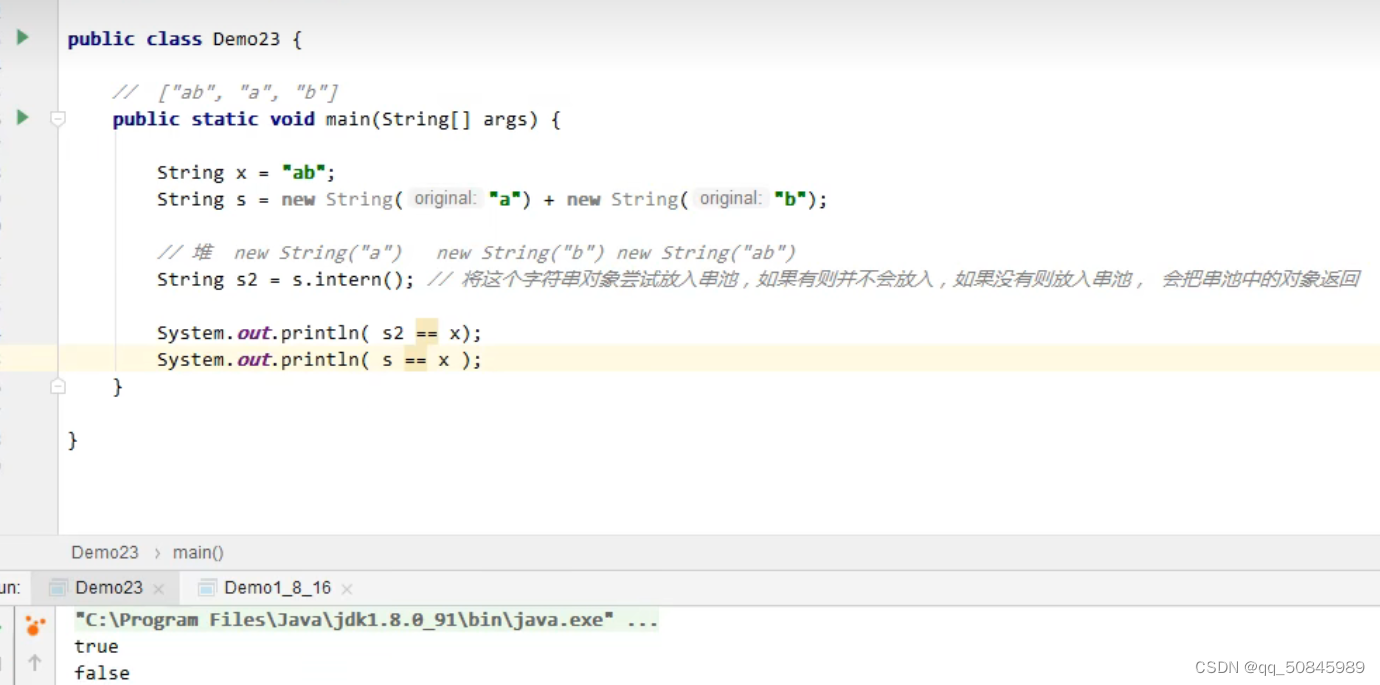
x是放入串池,s是两个变量,放入堆中。s2是不会放入,返回串池已有对象”ab“,以此s2等于x,s不等于x。
intern()这个方法可以将其放到串池中。
总结:
-
常量池中的字符串仅是符号,第一次用到时才变成对象
-
利用串池的机制,来避免重复创建字符串对象
-
字符串变量拼接的原理是StringBuilder(1.8)(字符串不确定),直接创建,堆中
-
字符串常量拼接的原理是编译期间优化(字符串可以确定),看串池有没有
-
可以使用intern方法,主动将串池中还没有的字符串对象放入串池
-
1.8将这个字符串对象尝试方法串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回
-
1.6将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池,把串池对象返回。
-
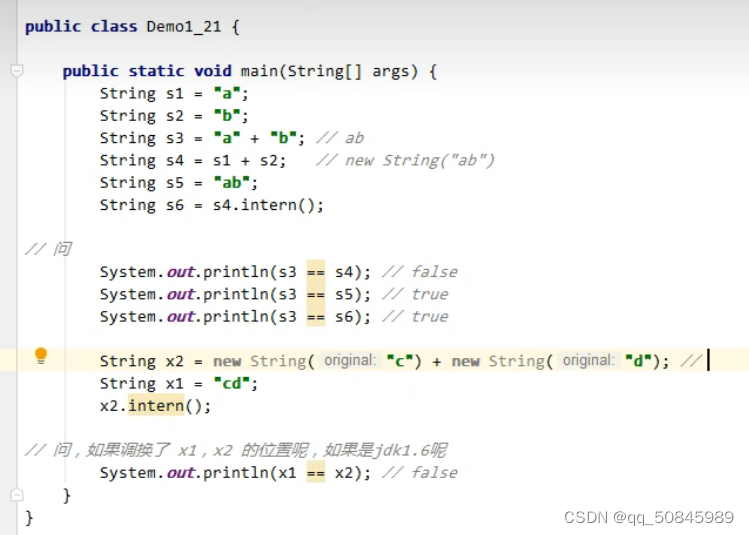
s3是常量字符串拼接编译器会优化为“ab”,而常量池中没有“ab”,放入常量池。
s4是两个变量的拼接,通过StringBuilder拼接,new String(“ab”)是在堆中。
s5是一个自变量,先检查常量池内容,发现已经有了“ab”,不会创建新的对象,直接引用常量池中已有的对象。
s6先看常量池中有“ab”,直接引用常量池中已有对象
x2堆中的对象
x1常量池中对象
x2.intern()发现常量池中已有“cd”对象,没能入池成功。
x1不等于x2

x2堆对象
x2.intern()发现常量池中没有“cd”对象,将”cd“放入常量池。堆中的”cd“对象和常量池中的”cd“对象是同一个对象。
x1发现常量池中已有”cd“对象,不会创建新的,直接引用常量池中的对象
x1等于x2
在jdk1.6中:x2.intern()不会直接入池,而是复制x2对象,将复制好的对象放到常量池中,x1引用的是常量池中复制好的对象。
x1不等于x2
总结:
new String()是在堆中创建对象。
两个new String()相加是通过StringBuilder()生成新的对象。或者是a="a"; b="b",c=a+b。
"a"这种确定的常量是先看运行时常量池在不在,在的话不放,直接引用,没有才放。
”a"+"b"这种是确定的,编译优化可以直接确定为“ab",也同样是看是否存在于常量池中。
==和equals的不同:
1)对于==,如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等;如果作用于引用类型的变量,则比较的是所指向的对象的地址。
2)对于equals不能作用于基本数据类型的变量(如:不能写成 int m=1;int n=1;n.equals(m);)如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。
== 基本类型:值,应用类型:地址。
equals 引用类型:地址,String重写:值
String a = "xiaomeng2";
final String b = "xiaomeng";
String d = "xiaomeng";
String c = b + 2;
String e = d + 2;
System.out.println((b == d));//true
System.out.println((a == e));//false
System.out.println((a == c));//truea放常量池。
b被final修饰的是常量,编译期间即可知道是什么,放到常量池中。
d直接引用b在常量池中的地址。
c中=运算中,由于b在编译期间即可知道是什么,就相当于“xiaoming”+2.直接引用a在常量池中的地址。
e中,d需要在连接中进行运算,会在堆中生成xiaoming2字符串。
移植StringTable位置原因
永久代内存低,永久代FGC(重GC)才会回收,等到老年代空间不足才会触发,触发时机晚,导致StringTable回收效率低,但是StringTable使用频率高,从而,将StringTable放到堆中,只需要minner GC就可以触发回收。降低字符串的内存占用。















 1591
1591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









