







Selenium的学习与Python的多层爬取
python的request爬取的回忆
1.确定url
2.UA伪装 伪装成浏览器上网 【使用fake_useragent包】
3.request请求网页,获得响应的数据【注意返回的是json还是text格式的】
4.使用xpath解析数据
5.持久化保存数据
Selenium的基础用法
基本步骤
selenium又称为半自动化爬虫其基本的步骤如下
# 半自动化爬虫
from selenium import webdriver
from selenium.webdriver.common.by import By
# 驱动 想用哪个浏览器可以下载相应的驱动 使用Google浏览器不需要下载驱动
driver = webdriver.Edge()
# get一个地址
driver.get("https://www.xxxxx.com")
# 获取响应的数据
print(driver.page_source)
# 数据解析
# find_element 定位一个元素的位置
# driver.find_element()
# 定位多个元素的位置
# driver.find_elements()
driver.find_element(By.ID,"kw").send_keys("杨幂")
driver.find_element(By.ID,"su").click() # 模范鼠标点击
driver.find_element(By.XPATH,"//input[@id='kw']").send_keys("迪丽热巴")
time.sleep(5)
driver.close()
基本使用语法
# 直接获得一个标签下的文本数据
hero_name = li.find_element(By.XPATH, "div/p").text
# 获得一个标签下的属性数据:例如url 图片链接等等
hero_pic_url = li.find_element(By.XPATH, "div/div/img").get_attribute("src")
# 查找解析一个元素
driver.find_element(By.CLASS_NAME,"hero-list")
driver.find_element(By.XPATH,"//div[@class='herp-list']")
# 查找一个标签下面的多个相同的元素,如一个div标签下有多个li标签
driver.find_elements(By.XPATH,'//div[@class="hero-list"]/li')
# 取出来所有的li标签之后可以使用for 循环进行遍历
注意事项
有些网页的爬取需要渲染的时间如果打开就关闭则同样会爬不到数据。
这时候有两种方法可以使用。
1.直接使用time(5)休眠5秒 等待网页的渲染
from selenium import webdriver
from selenium.webdriver.common.by import By
# 打开一个驱动
driver = webdriver.Edge()
# 通过驱动发送请求
driver.get("https://xxxx.ttt.com/#/hero")
# 强制等待五秒
time.sleep(5)
2.使用一个selenium包进行等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 打开一个驱动
driver = webdriver.Edge()
# 通过驱动发送请求
driver.get("https://xxxx.ttt.com/#/hero")
# 等待需求的元素出现
element_wait = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, "//ul[@class='hero-list']"))
)
当然结束的时候不要忘记关闭浏览器
driver.close()
Python的多层爬取【实例:音乐网站】
查看网页信息
打开某音乐网站,你会发现他的欧美明星歌单的第一个页面是正常的,但是其第二个页面的body中的id为auto-id 即你每次打开页面它之后的数据都会变化。此时你会发现简单的xpath定位无法使用。
第二个页面
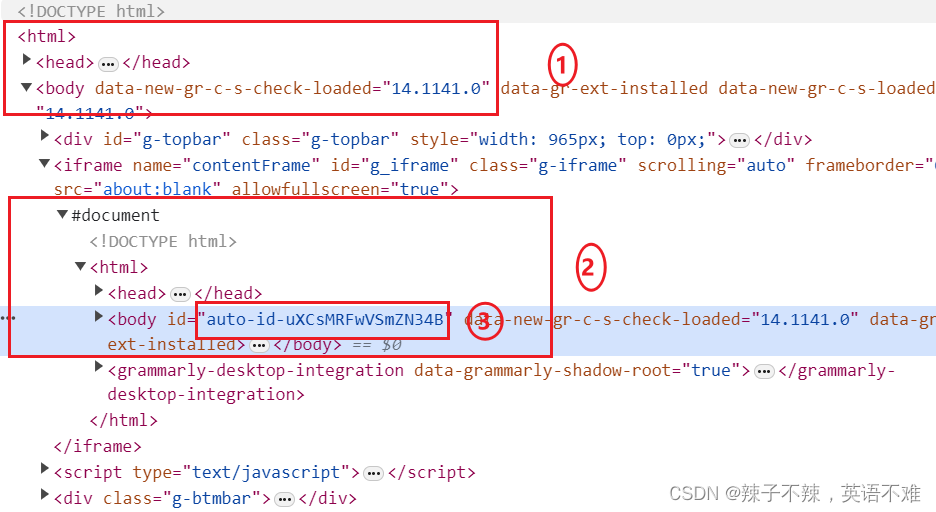
1.为第一个页面框
2.这个html中才是存放需要数据的地方,这个地方需要使用
driver_Edge.switch_to.frame(frame) 转换到第二个子页面中
3.动态的id需要使用bs4进行接下来的爬取
注意
即第一步将第一个歌手页面的中的链接爬出来,接着进入歌手的主页面进行深度爬取,由于是动态的并且还含有子页面。所以需要selenium与bs4混合使用爬取到每个歌手的最受欢迎的歌单名字。
多层爬取实例
1.导入包
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.edge import options
from bs4 import BeautifulSoup
import re
2.进入有所有歌手信息的第一个页面,并且获取每个歌手详细页面的url
# 不打开页面的方式
opt = options.Options()
opt.add_argument("--headless")
url = "https://music.xxxx.com/discover/artist/......"
driver = webdriver.Chrome()
# 请求页面
driver.get(url)
# 进入页面中的子页面
driver.switch_to.frame(driver.find_elements(By.TAG_NAME, "iframe")[0])
# 使用xpath解析找到每个歌手细节的url
li_list = driver.find_elements(By.XPATH,'//ul[@class="m-cvrlst m-cvrlst-5 f-cb"]/li')
3.遍历列表进行第二次爬取
for li in li_list:
# 获取包含歌手细节的url
detail_url = li.find_element(By.XPATH,"div/a[1]").get_attribute("href")
time.sleep(3)
print(detail_url)
# 驱动浏览器进行访问
driver_Edge = webdriver.Edge()
driver_Edge.get(detail_url)
# 进入歌手信息页面的子页面中
frame = driver_Edge.find_element(By.XPATH, '/html/body/iframe[1]')
driver_Edge.switch_to.frame(frame)
# 获取歌手的姓名
artist_name = driver_Edge.find_element(By.XPATH,'//h2[@id="artist-name"]').text
print(artist_name)
3.此时使用bs4进行后续的动态数据的查询以及获得歌曲的名字
(此代码在上述的for循环里面)
# 使用BeautifulSoup获得子页面
soup = BeautifulSoup(driver_Edge.page_source,'lxml')
body = soup.body
# 定位到信息的位置
music = body.select('table[class="m-table m-table-1 m-table-4"] > tbody')
# music name 使用正则表达式匹配到歌单的名字
music_name_list = re.findall('<b title="(.*?)">',str(music[0]))
name=[]
for music in music_name_list:
name.append(music.strip())
music_detail = pd.DataFrame()
music_detail["music_name"]=name
print(music_detail)
# 进行持久化保存
music_detail.to_excel(f"./output/欧美女歌手/{artist_name}.xlsx")
# 关闭浏览器 第一个歌手爬取完毕,进行下一个歌手的爬取
driver_Edge.close()
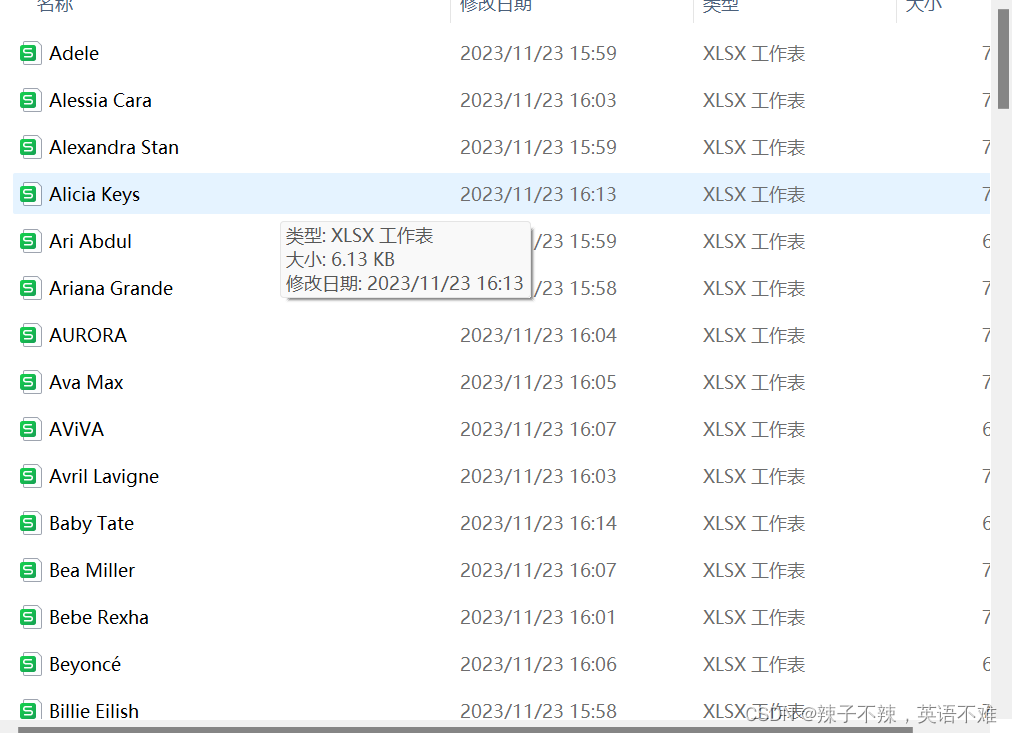
结果如下:
















 2135
2135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











