







用Selenium和requests爬取图片并保存
确定url选择一个网站
我选择的是wallhave.cc 检查网站 是阿贾克斯请求 即如下图操作
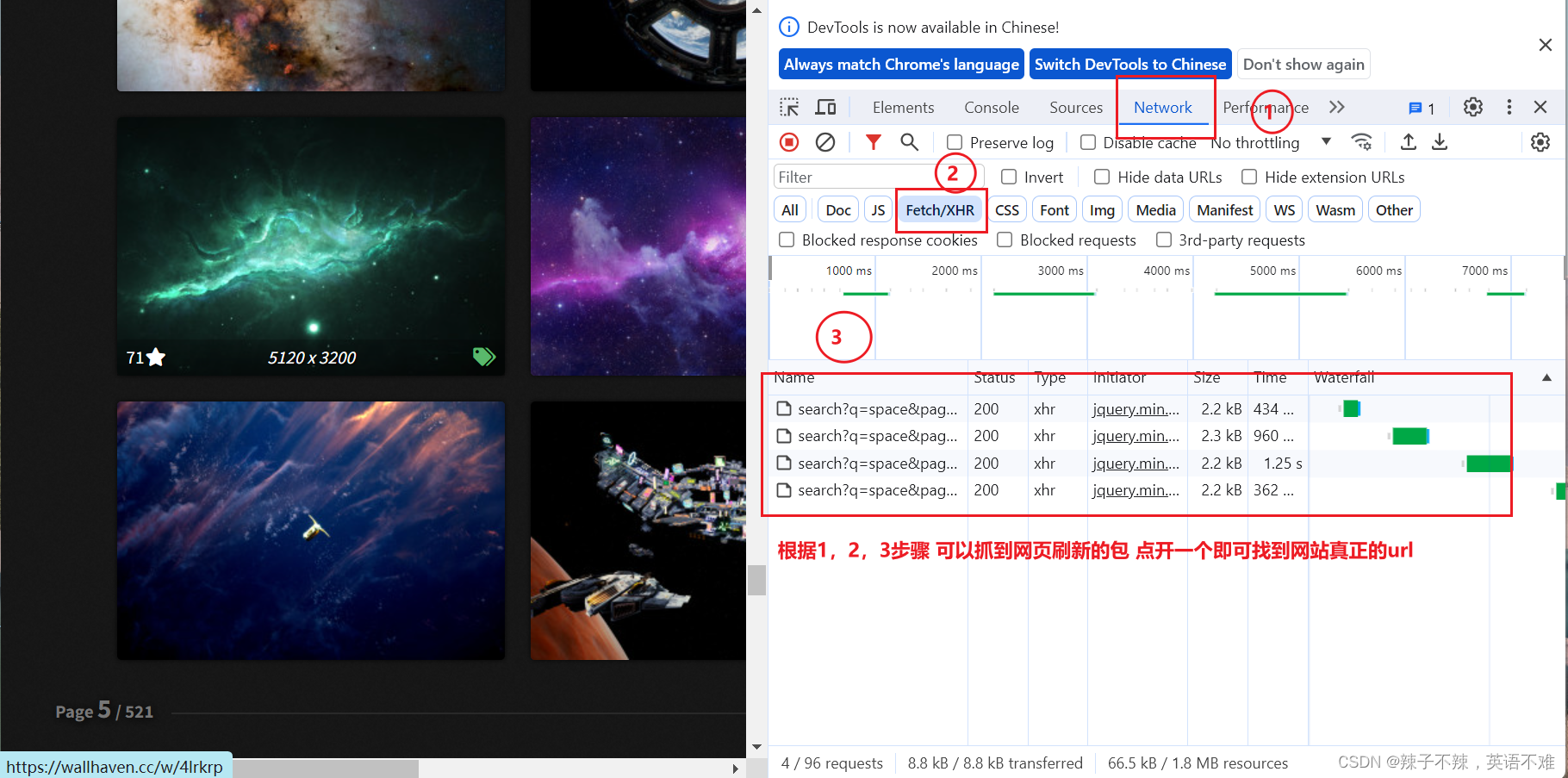
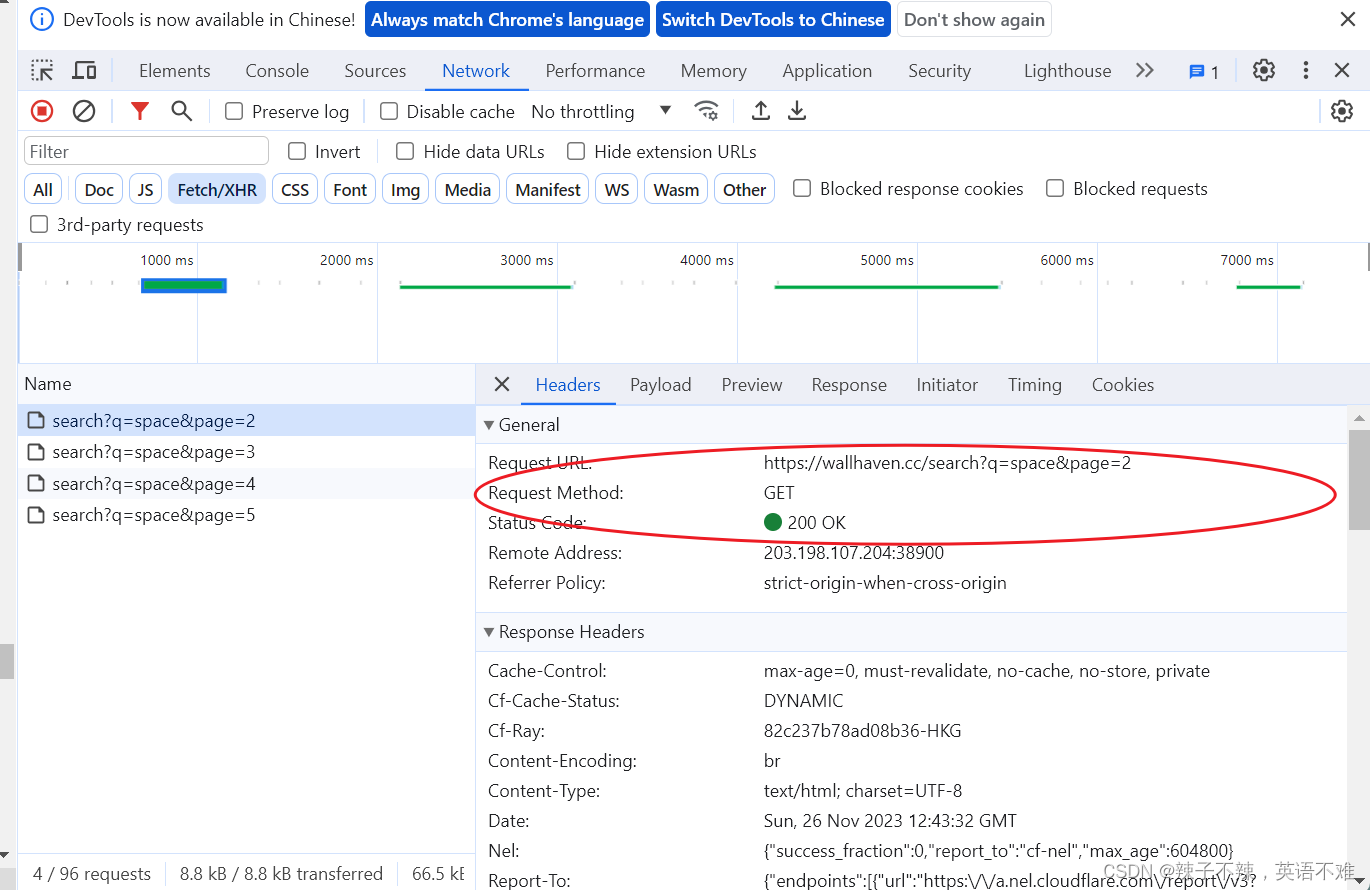
编写程序爬取
因为有不同的页面所以肯定需要一个for循环来循环页面的url
在页面中可以看到一个个小图片都在li标签里面
所以需要另一个for循环来循环 li 标签取到图片真正的url地址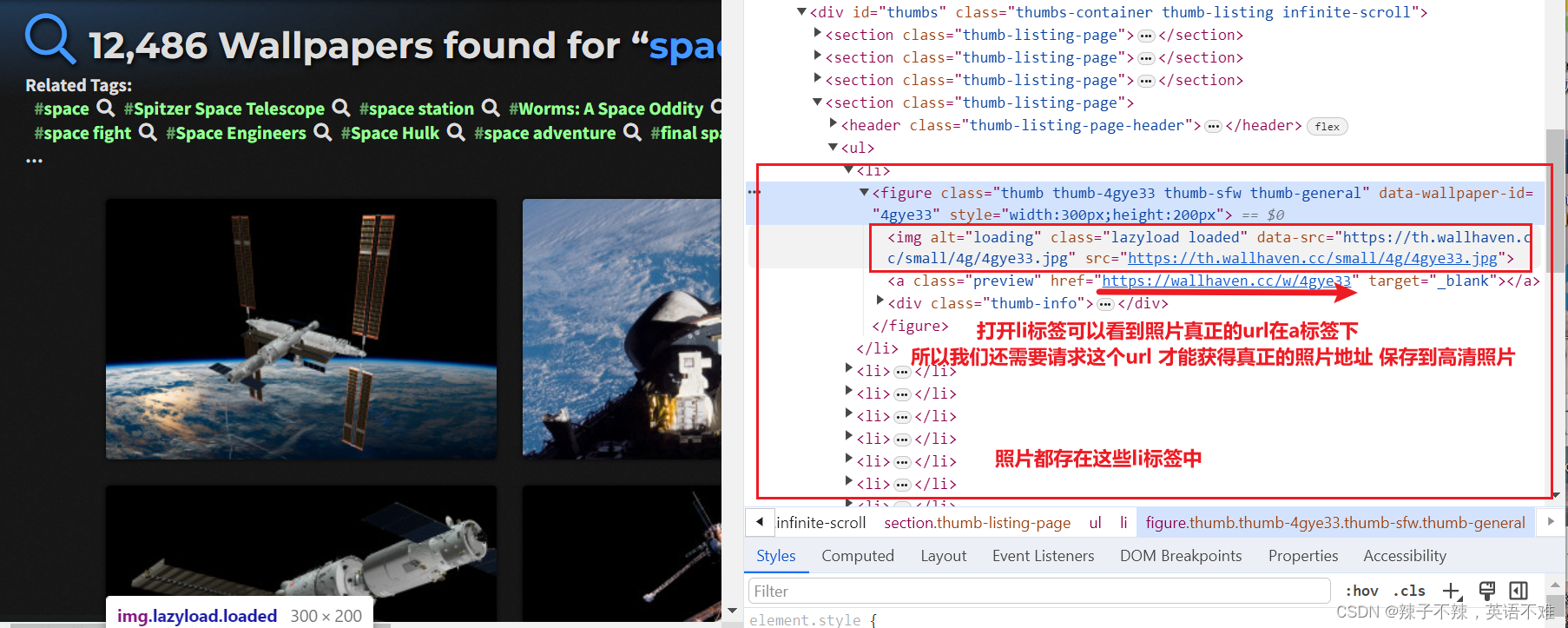
点开小图片 才是我们需要的高清照片
检查真正的照片url
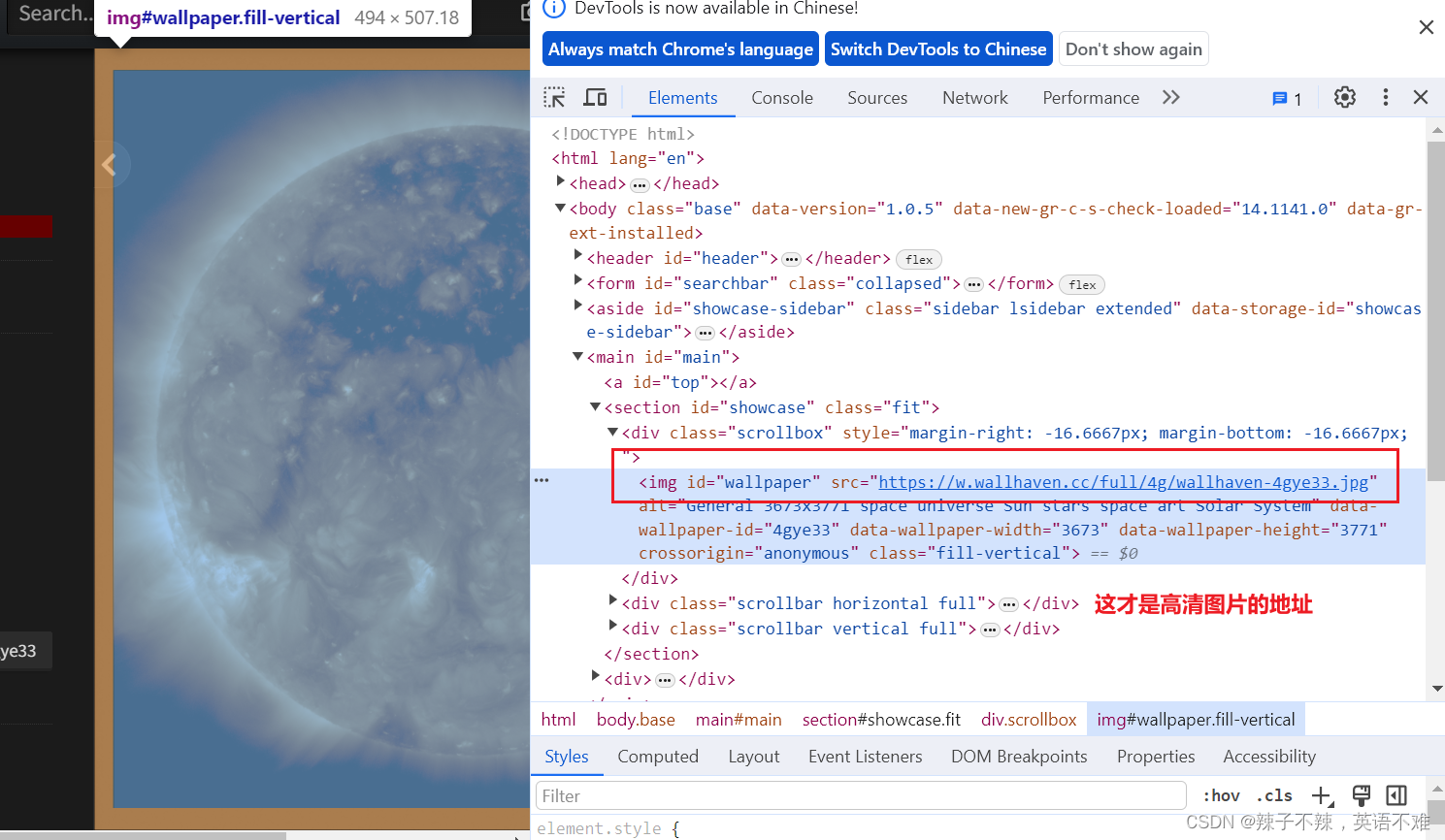
接着请求照片地址
用conten方法获得为二进制数据 再用with open()保存为照片即可
编写代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# time: 2023/11/26 19:48
# file: 爬图片.py
import time
import fake_useragent
from selenium import webdriver
from selenium.webdriver.common.by import By
import requests
from lxml import etree
tag = 0
for i in range(1,21):
url = (f'https://xxxxx/search?q=space&categories=110&purity=100&sorting=relevance&order=desc&ai_art_filter=1&page={i}')
driver = webdriver.Chrome()
driver.get(url)
time.sleep(5)
li_list = driver.find_elements(By.XPATH,"//div[@id='thumbs']/section/ul/li")
print(li_list)
for li in li_list:
tag += 1
print(tag)
time.sleep(4)
detail_url = li.find_element(By.XPATH,"figure/a").get_attribute("href")
print(detail_url)
response = requests.get(detail_url,headers={"User-Agent": fake_useragent.UserAgent().random})
res_text = response.text
tree = etree.HTML(res_text)
img_url = tree.xpath("//div[@class='scrollbox']/img/@src")[0]
print(img_url)
time.sleep(2)
pic_response = requests.get(img_url,headers={"User-Agent": fake_useragent.UserAgent().random})
pic_cont = pic_response.content
with open(f"./output/太空照片/{tag}.jpg", "wb") as fp:
fp.write(pic_cont)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











