






这个系列CSDN博客是用来记录我做三小项目的一个历程: 第一篇:数据处理(对学习通数据进行处理)
1. 数据展示
本项目的所有数据都被存在课程数据这个文件夹,里面的各子目录分别包含了不同的数据特征
子目录的文件都是一样的格式,可以做统一处理:
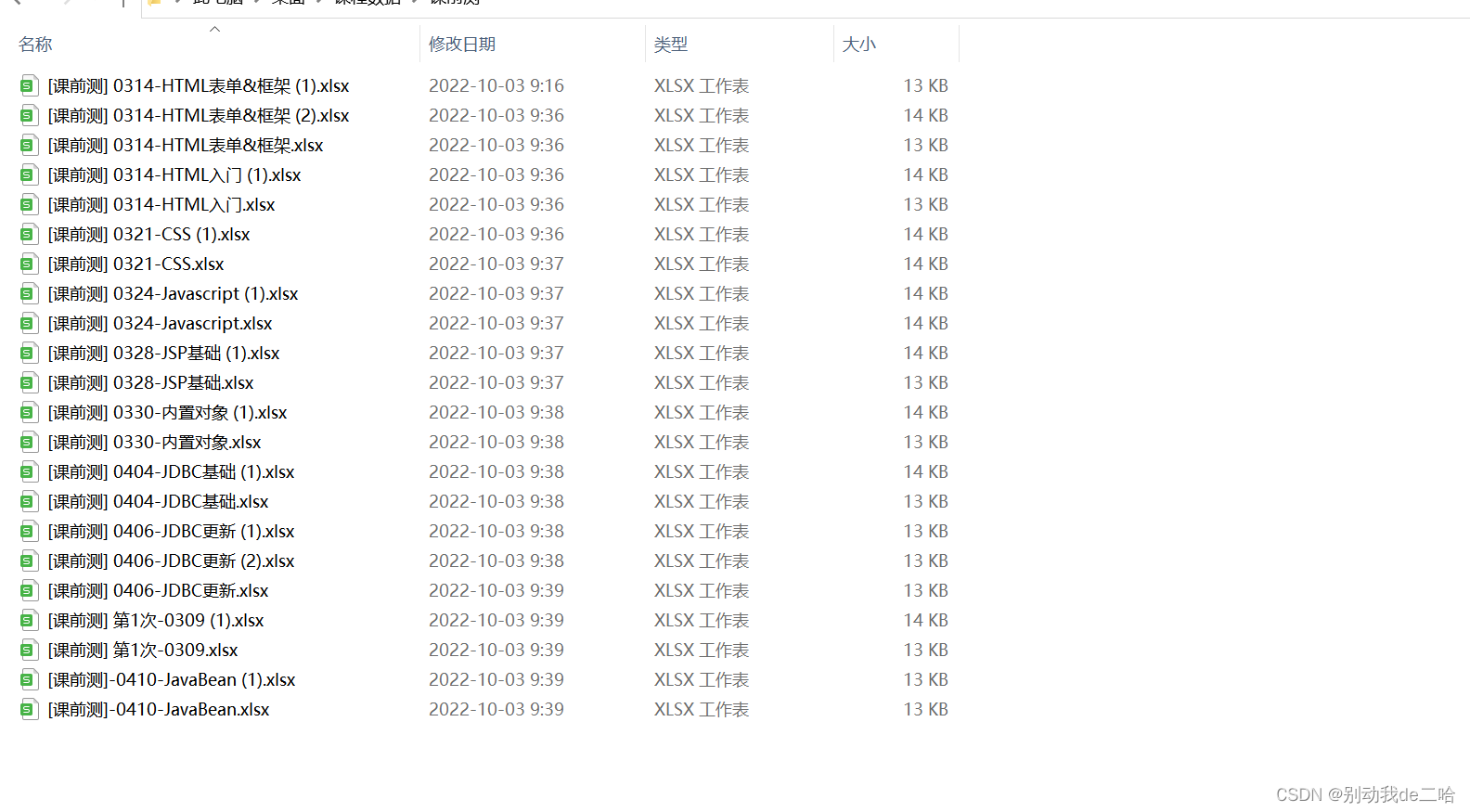
所以我们需要做的第一步就是去进入特定的文件夹,对里面的文件做统一的处理。
代码:
path = "C:/Users/25023/Desktop/课程数据/课前测" #文件夹目录
files= os.listdir(path) #得到文件夹下的所有文件名称
for item in files:
print(item)
try:
course_test = pd.read_excel('C:/Users/25023/Desktop/课程数据/课前测/'+item,header = 0)
except PermissionError as e:
print("没有权限打开该文件")
else:
这里需要用到python自带的os库.
os.listdir(path)中有一个参数,就是传入相应的路径,将会返回那个目录下的所有文件名。
这里会遇到一个问题我还没有解决:
- 就是在获取这个文件列表的时候,会发现有一些文件在目录里面看不见,但是会出现在列表中,并且不可读,我就用try,expect将其忽略了*
第二步就是去读取数据了:
代码:
try:
course_test = pd.read_excel('C:/Users/25023/Desktop/课程数据/视频观看(1-5)/'+item,header = 0)
except PermissionError as e:
print("没有权限打开该文件")
else:
这里我用的是pandas库中的pandas.read_excel()来读取EXCEL中的数据的
pandas.read_excel中有许多的参数可以用的,详细的内容我们可以看这个博主的一篇博客pandas.read_excel详细参数讲解
在这我就提一下一些主要的参数: pandas.read_excel(sheet_name=0,header = 0,index_col= ’‘,)
- sheet_name 这个参数可以是str类型(表名),int类型(表的索引,即是第几张表)
- header用于指定表头行号
- index_col用来指定索引列
读取文件中的数据的方式多用多样,不必拘泥于这一种方式,可以在不同项目中,选择不一样的读取方式
数据读进去了,第三步就是对数据进行一定的处理了:
我们先来看看数据:
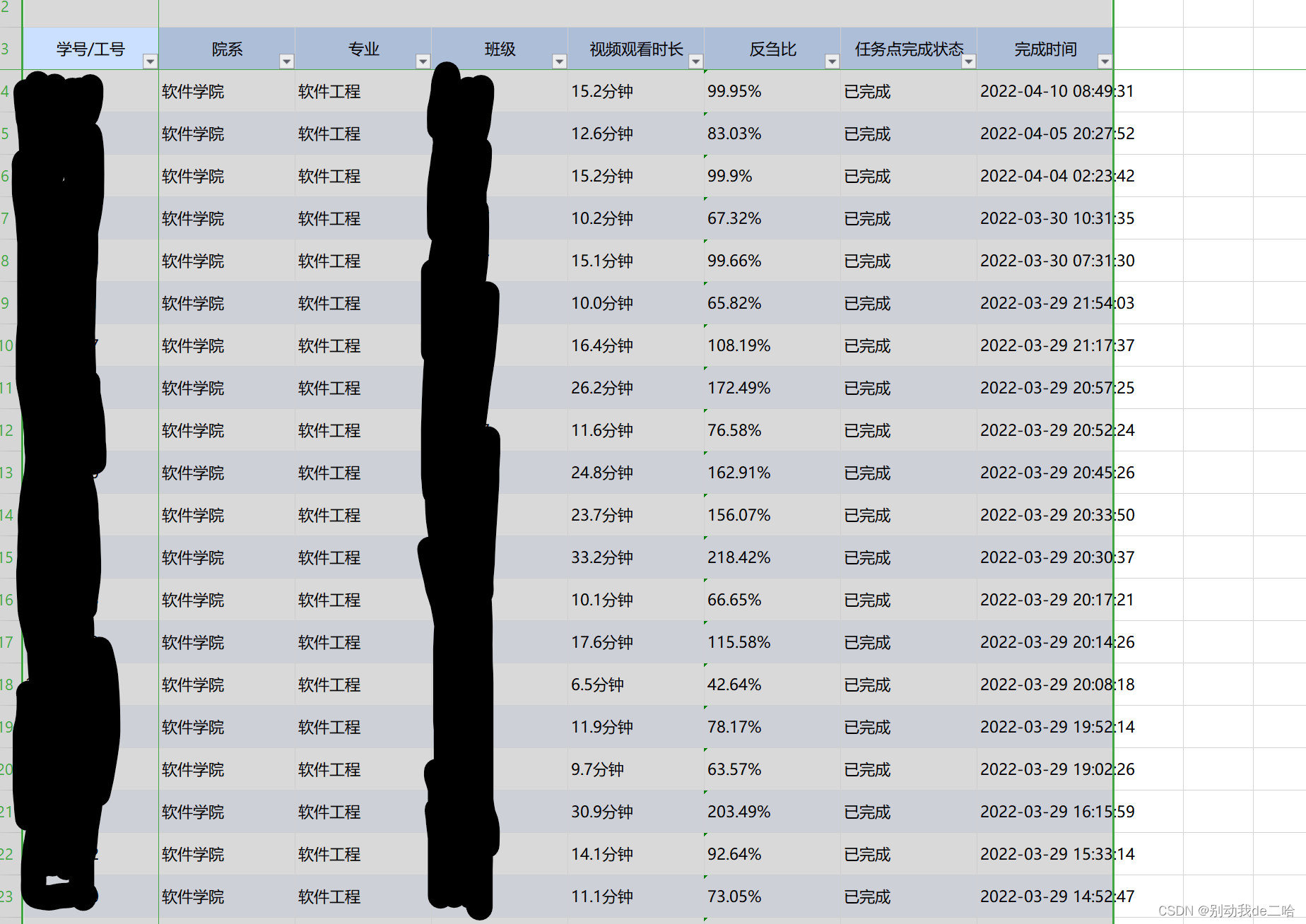
这是学生看网课的一些数据,有许多张表,我们需要的就是将完成状态变为数值型数据,然后再进行和表操作就行
将文本数据变数值型数据:
mapping = {'已完成':1,'未完成':0}
course_test['任务点完成状态'] = course_test['任务点完成状态'].map(mapping)
这是处理后的结果:
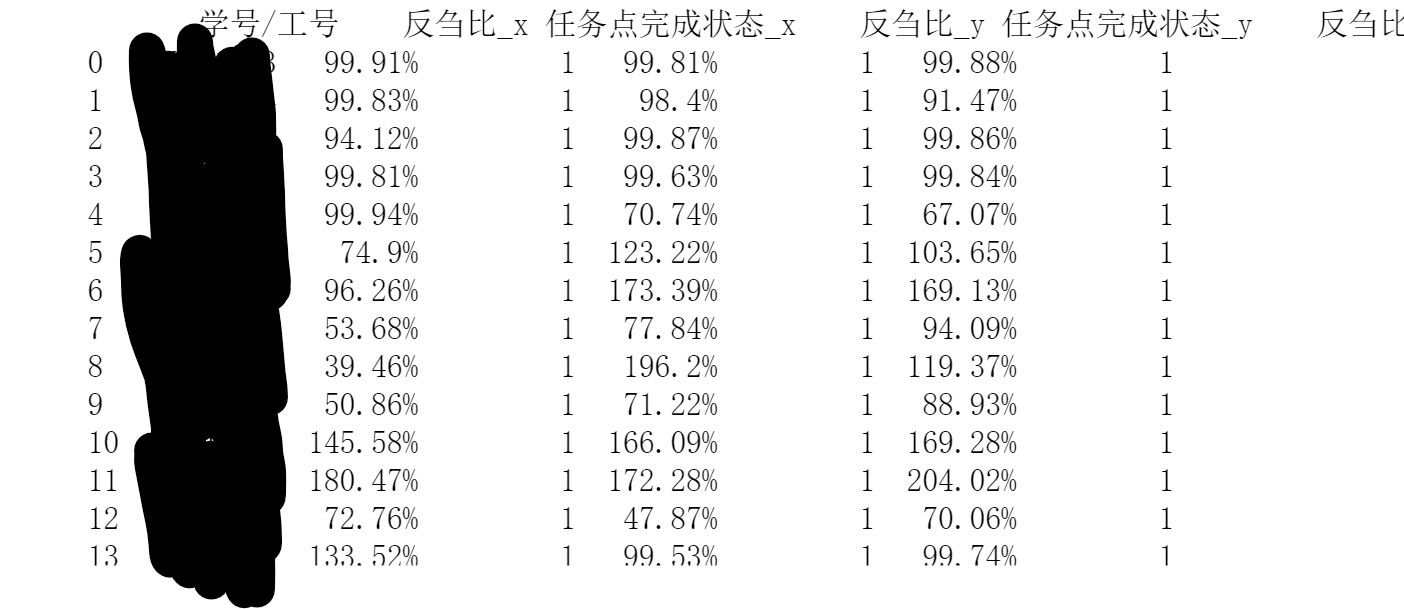
短短两行代码即可以搞定。
这里给大家讲一下map函数的作用和用法。
1)map()函数作用
将序列中的每一个元素,输入函数,最后将映射后的每个值返回合并,得到一个迭代器。
2)map()函数原理图
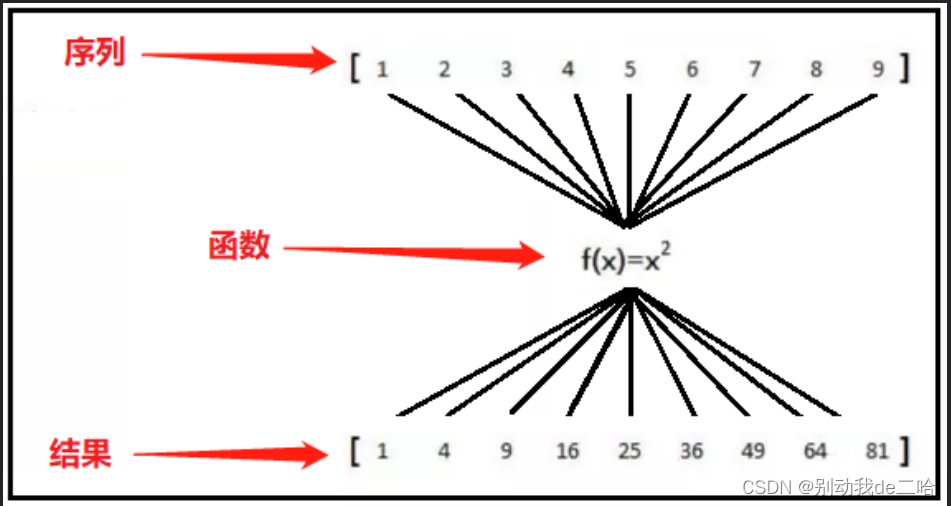
原理解释:
上图有一个列表,元素分别是从1-9。map()函数的作用就是,依次从这个列表中取出每一个元素,然后放到f(x)函数中,最终得到一个通过函数映射后的结果。
map的运用实例;
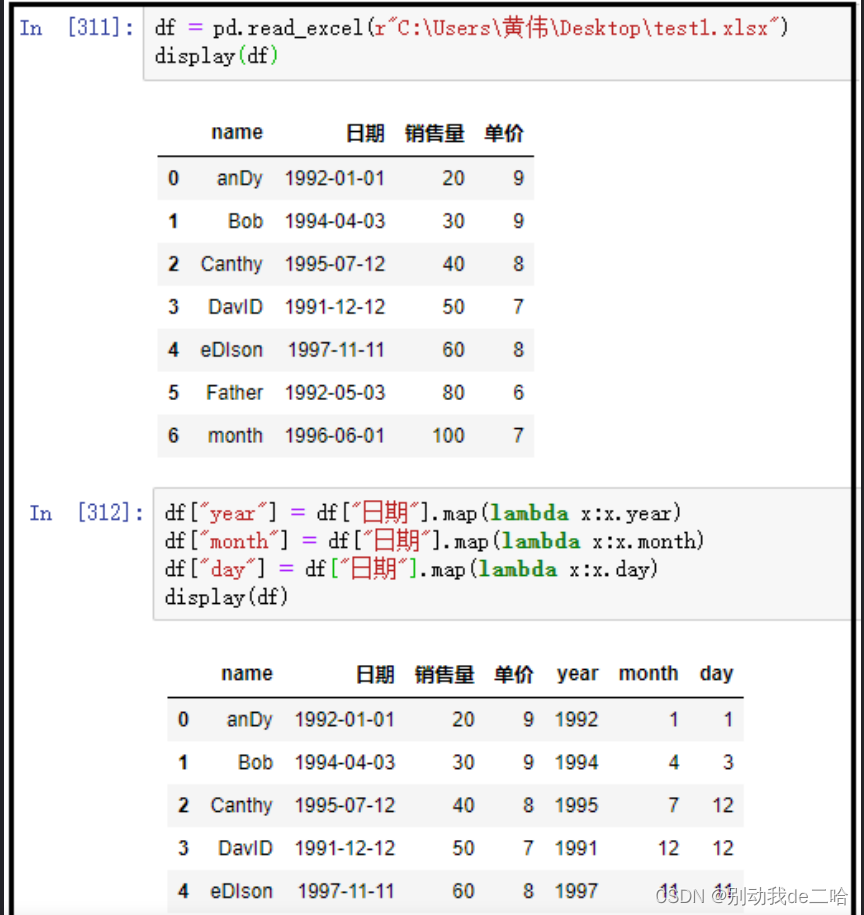
df = pd.read_excel(r"C:\Users\黄伟\Desktop\test1.xlsx")
display(df)
# 注意:这里的日期列,是时间格式
df["year"] = df["日期"].map(lambda x:x.year)
df["month"] = df["日期"].map(lambda x:x.month)
df["day"] = df["日期"].map(lambda x:x.day)
display(df)
效果:
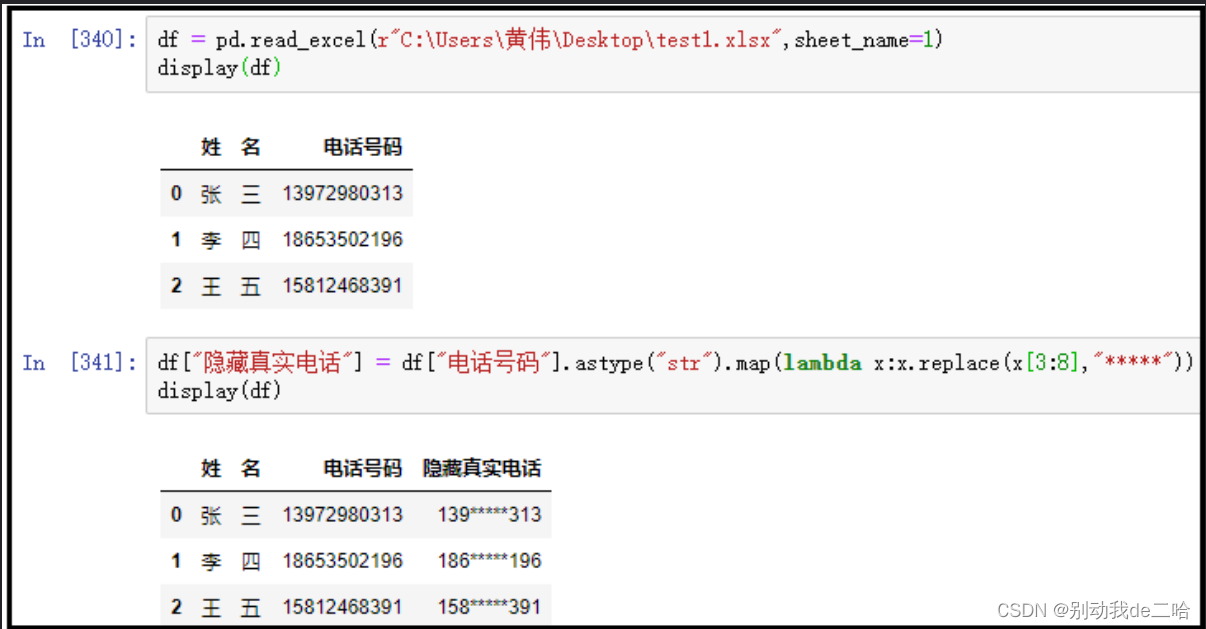
实例:
df = pd.read_excel(r"C:\Users\黄伟\Desktop\test1.xlsx",sheet_name=1)
display(df)
df["隐藏真实电话"] = df["电话号码"].astype("str").map(lambda x:x.replace(x[3:8],"*****"))
display(df)
效果:
接下来要做到的就是去将表做连接的一个操作:
这里我们可以用到pandas另外的一个强大的库 merge
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
参数如下:
-
left: 拼接的左侧DataFrame对象
-
right: 拼接的右侧DataFrame对象
-
on: 要加入的列或索引级别名称。必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。
-
left_on:左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
-
right_on: 左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
-
left_index: 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 对于具有MultiIndex(分层)的DataFrame,级别数必须与右侧DataFrame中的连接键数相匹配。
-
right_index:与left_index功能相似。
-
how: One of ‘left’, ‘right’, ‘outer’, ‘inner’.默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。'outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。
-
sort: 按字典顺序通过连接键对结果DataFrame进行排序。 默认为True,设置为False将在很多情况下显着提高性能。
-
suffixes: 用于重叠列的字符串后缀元组。 默认为(‘x’,’ y’)。
-
copy:始终从传递的DataFrame对象复制数据(默认为True),即使不需要重建索引也是如此。
-
indicator:将一列添加到名为_merge的输出DataFrame,其中包含有关每行源的信息。_merge是分类类型,并且对于其合并键仅出现在“左”DataFrame中的观察值,取得值为left_only,对于其合并键仅出现在“右”DataFrame中的观察值为right_only,并且如果在两者中都找到观察点的合并键,则为left_only。
补充:
运用pandas库去删除一些不需要的属性列或行
删除对应的属性列与行:
data3 = data3.drop(["学号/工号"],axis='columns',inplace=True)
第一个参数可以是对应属性列的列名或者对应行的索引,axis为0表示为对行进行删除,axis为1表示为对列进行删除。
凡是会对原数组作出修改并返回一个新数组的,往往都有一个 inplace可选参数。如果手动设定为True(默认为False),那么原数组直接就被替换。也就是说,采用inplace=True之后,原数组名对应的内存值直接改变;















 1521
1521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









