







 本文介绍了Scala中使用`scala.io.Source`包的`fromFile`函数读取文件,强调了其仅创建内存对象并未实际读取数据的特点。接着讨论了`getLines`返回惰性光标而非数据本身,以及如何通过`toArray`转换数据并使用`.foreach()`遍历操作。文章探讨了大数据处理中的计算向数据靠拢原则,并希望读者提供反馈。
本文介绍了Scala中使用`scala.io.Source`包的`fromFile`函数读取文件,强调了其仅创建内存对象并未实际读取数据的特点。接着讨论了`getLines`返回惰性光标而非数据本身,以及如何通过`toArray`转换数据并使用`.foreach()`遍历操作。文章探讨了大数据处理中的计算向数据靠拢原则,并希望读者提供反馈。
一、文件的读取
如Java一般在我们使用特定的操作时需要调用某个包的某一个函数实现。在Scala里我们在读取文件时需要使用一个叫“scala.io.Source”的包,使用包中的一个叫fromFile的函数实现。现在上代码!!
import scala.io.Source
object no7{
def main(args: Array[String]) {
val filepath ="/home/hadoop/mydata/1.2.txt"
val source = Source.fromFile(filepath, "UTF-8")//创建一个BufferedSource对象,读取格式为“UTF-8”
val lines = source.getLines().toArray//读取所有行,每一行就是一个数组元素
source.close()//BufferedSource对象是一个运行在内存的过程,使用完及时关闭避免资源浪费
lines.foreach(str=>println(str))//对lines的每个元素进行空行输出
}
}
效果则是每行都被当做一个元素被输出,如下图:
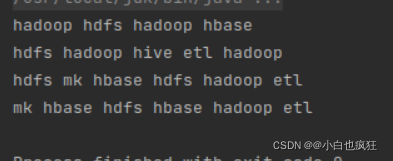
Source.fromFile()创建的仅仅是一个在内存中可供操作的对象。不要以为此时已经读取数据了,因为在面对数据量较大时读取数据是一件及其耗时的事情,何况是在如HDFS这种依靠网络的文件系统中。这就是我们常说的在处理大数据是我们需要做到的是计算向数据靠拢的原则,而不像传统的那样像提取数据后处理完再输出
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7967
7967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











