






维护一个集合,支持如下几种操作:
I x,插入一个数 x;
Q x,询问数 x 是否在集合中出现过;
现在要进行 N 次操作,对于每个询问操作输出对应的结果。
输入格式
第一行包含整数 N,表示操作数量。
接下来 N 行,每行包含一个操作指令,操作指令为 I x,Q x 中的一种。
输出格式
对于每个询问指令 Q x,输出一个询问结果,如果 x 在集合中出现过,则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1≤N≤105
−109≤x≤109
输入样例:
5
I 1
I 2
I 3
Q 2
Q 5
输出样例:
Yes
No
哈希函数协助我们用更小的空间去存储更大范围的数。例如在此题中,我们渴望将范围为
−
1
0
9
−
1
0
9
-10^9 - 10^9
−109−109的数投射至
0
−
1
0
5
−
1
0-10^5-1
0−105−1范围,那么哈希函数就可以取为x%
1
0
5
10^5
105,更重要的,我们探讨当发生透射2冲突时我们的应对措施。
第一种方法叫“拉链法”,它的基本思想是将发生冲突的数存放于同一个位置,相当于在这个存储位置拉开了一条链,准确来说,是一条链表。
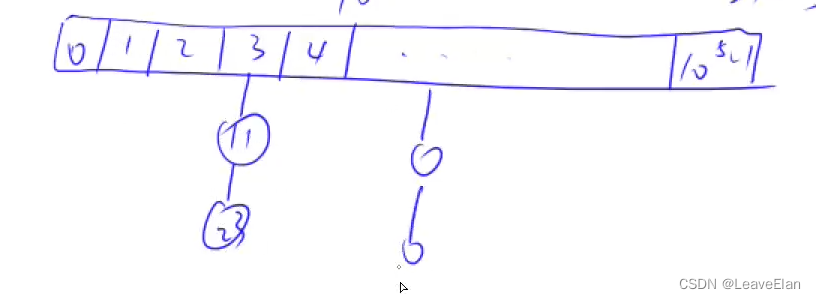
需要注意的一点是,这个拿来模除的数一般取质数,数学上可证明这样冲突的几率最小。
#include <cstring>
#include <iostream>
using namespace std;
const int N = 100003;
//h[N]为槽,e[N],ne[N],与idx与链表有关
int h[N], e[N], ne[N], idx;
void insert(int x)
{
//加N使得括号内的数一定是正数
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
//h[k]存的是第一个链表的下标
h[k] = idx ++ ;
}
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
if (e[i] == x)
return true;
return false;
}
int main()
{
int n;
scanf("%d", &n);
//清空槽
memset(h, -1, sizeof h);
while (n -- )
{
char op[2];
int x;
scanf("%s%d", op, &x);
if (*op == 'I') insert(x);
else
{
if (find(x)) puts("Yes");
else puts("No");
}
}
return 0;
}
作者:yxc
链接:https://www.acwing.com/activity/content/code/content/45308/
来源:AcWing
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
关于模数的问题,可以参考这个大佬的博客。
开放寻址法:开辟一个一维数组,这个一维数组大小为输入元素数量的两到三倍。当我们插入新元素时,我们通过哈希函数得到新元素的下标,若数组中对应下标已存在元素,则往后查找空闲的位置并插入。查找某个元素时,我们来到它对应的下标,先判断当前是否存在元素,若不存在,则说明查找元素不存在,若存在元素,则进行比较,若不匹配则往后继续查找,直到碰上空位或找到匹配元素。
#include <cstring>
#include <iostream>
using namespace std;
const int N = 200003, null = 0x3f3f3f3f;
int h[N];
int find(int x)
{
int t = (x % N + N) % N;
while (h[t] != null && h[t] != x)
{
t ++ ;
if (t == N) t = 0;
}
return t;
}
int main()
{
memset(h, 0x3f, sizeof h);
int n;
scanf("%d", &n);
while (n -- )
{
char op[2];
int x;
scanf("%s%d", op, &x);
if (*op == 'I') h[find(x)] = x;
else
{
if (h[find(x)] == null) puts("No");
else puts("Yes");
}
}
return 0;
}
作者:yxc
链接:https://www.acwing.com/activity/content/code/content/45308/
来源:AcWing
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
字符串哈希
给定一个长度为 n 的字符串,再给定 m 个询问,每个询问包含四个整数 l1,r1,l2,r2,请你判断 [l1,r1] 和 [l2,r2] 这两个区间所包含的字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式
第一行包含整数 n 和 m,表示字符串长度和询问次数。
第二行包含一个长度为 n 的字符串,字符串中只包含大小写英文字母和数字。
接下来 m 行,每行包含四个整数 l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从 1 开始编号。
输出格式
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1≤n,m≤105
输入样例:
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出样例:
Yes
No
Yes
对于字符串,我们首先建立一个数组h[N],并存放它所有前缀的哈希值。如h[0]=0,h[1]存放的是第一个字符的哈希值,h[2]存放的是前两个字符的哈希值。
以“ABCD”为例,我们求它的哈希值。首先我们为所有大写字母递增映射,映射值是字母对应的Ascii码,并让A的映射等于1 ,那么ABCD就等价于1234。接下来我们把“1234”这个数看作一个p进制的数,它的十进制的值等于
1
∗
p
3
+
2
∗
p
2
+
3
∗
p
1
+
4
∗
p
0
1*p^3+2*p^2+3*p^1+4*p^0
1∗p3+2∗p2+3∗p1+4∗p0,考虑到具体的字符串可能很长,计算出来的值相当巨大,我们还需要将这个值模除某个数Q,最终我们将“ABCD”映射至0~Q-1的区间。
需要注意的一点是我们不能把某个字符x映射为0,如果这样做的话会导致“x",“xxx”,"xxxxx"都映射到同一个 值,这不符合我们的预期。
这个做法不太严谨的地方在于,我们设定经验值p=131或13331与Q=
2
64
2^{64}
264,并假定这样做不会引发冲突。
下面着重讲述如何利用前缀数组求得任意
[
l
,
r
]
[l,r]
[l,r]范围的字符串哈希值。

我们有
h
[
l
−
1
]
与
h
[
r
]
h[l-1]与h[r]
h[l−1]与h[r]的哈希函数值,我们需要注意,在这里我们约定的是数轴左边才是高位。因此我们需要将
h
[
l
−
1
]
h[l-1]
h[l−1]左移至与
h
[
r
]
h[r]
h[r]等长,即让
h
[
l
−
1
]
∗
p
r
−
l
+
1
h[l-1]*p^{r-l+1}
h[l−1]∗pr−l+1,然后再让
h
[
r
]
h[r]
h[r]减去这个数,得到的才是
[
l
,
r
]
[l,r]
[l,r]字串的哈希函数值。
而在初始化时,我们使用下式初始前缀数组,数组元素为unsigned long long类型,这样省去了取模Q的操作,因为unsigned long long的范围为0~
2
64
−
1
2^{64}-1
264−1,当发生溢出时就相当于做了取模操作。
h
[
i
]
=
h
[
i
−
1
]
∗
p
+
s
t
r
[
i
]
h[i]=h[i-1]*p+str[i]
h[i]=h[i−1]∗p+str[i]
#include <iostream>
#include <algorithm>
using namespace std;
typedef unsigned long long ULL;
const int N = 100010, P = 131;
int n, m;
char str[N];
ULL h[N], p[N];
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int main()
{
scanf("%d%d", &n, &m);
scanf("%s", str + 1);
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i];
p[i] = p[i - 1] * P;
}
while (m -- )
{
int l1, r1, l2, r2;
scanf("%d%d%d%d", &l1, &r1, &l2, &r2);
if (get(l1, r1) == get(l2, r2)) puts("Yes");
else puts("No");
}
return 0;
}
作者:yxc
链接:https://www.acwing.com/activity/content/code/content/45313/
来源:AcWing
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









