







六、Collection 子接口之 Set
java.util.Set 接口和 java.util.List 接口一样,同样继承自 Collection 接口,它与 Collection 接口中的方法基本一致,并没有对 Collection 接口进行功能上的扩充,只是比 Collection 接口更加严格了。与 List 接口不同的是, Set 接口中元素无序,并且都会以某种规则保证存入的 元素不出现重复。
Set 集合有多个子类,包括 HashSet、LinkedHashSet、TreeSet 等。
5.1 HashSet 集合
01、HashSet 的特点
-
HashSet 存入 Integer 类型的数据
/** * @author QHJ * @date 2022/10/13 09:25 * @description: HashSet存入Integer类型数据 */ public class IntegerInHashSet { public static void main(String[] args) { HashSet<Integer> hs = new HashSet<>(); System.out.println(hs.add(10)); // true hs.add(14); hs.add(8); System.out.println(hs.add(10)); // false hs.add(5); hs.add(32); System.out.println(hs.size()); // 5 System.out.println(hs); // [32, 5, 8, 10, 14] } }存入的数据是无序的、不可重复的。
-
HashSet 存入 String 类型的数据
/** * @author QHJ * @date 2022/10/13 09:29 * @description: HashSet存入String类型数据 */ public class StringInHashSet { public static void main(String[] args) { HashSet<String> hs = new HashSet<>(); hs.add("zhangsan"); System.out.println(hs.add("lisi")); // true hs.add("wangwu"); hs.add("hello"); System.out.println(hs.add("lisi")); // false System.out.println(hs.size()); // 4 System.out.println(hs); // [lisi, zhangsan, wangwu, hello] } }存入的数据是无序的、不可重复的。
-
HashSet 存入自定义类型的数据
/** * @author QHJ * @date 2022/10/13 09:32 * @description: HashSet存入自定义的引用数据类型数据 */ public class StudentInHashSet { public static void main(String[] args) { HashSet<Student> hs = new HashSet<>(); hs.add(new Student("青花椒", 22)); hs.add(new Student("lisi", 24)); hs.add(new Student("王五", 12)); hs.add(new Student("青花椒", 22)); hs.add(new Student("zhangsan", 44)); System.out.println(hs.size()); // 5 System.out.println(hs); // [Student{name='青花椒', age=22}, Student{name='青花椒', age=22}, Student{name='王五', age=12}, Student{name='zhangsan', age=44}, Student{name='lisi', age=24}] } }存入的元素是无序、可重复的。
为什么?
02、HashSet 底层原理
HashSet 由 HashMap 支持,存储唯一元素并允许空值,它是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。
扒一下 HashSet 的源码:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
// HashMap 集合,存数据时实际存放的是键值对(key, value)
private transient HashMap<E,Object> map;
// 占位符,存储到 map 时,相当于存入的 value 值
private static final Object PRESENT = new Object();
// 构造器,创建一个 map 集合
public HashSet() {
map = new HashMap<>();
}
// add() 方法,存入的实际是一个键值对,把值当做 key,PRESENT 当做 value
// 其实每次存入的 value 都是相同的,所以说,PRESENT 只是一个占位符
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
}
HashSet 集合存储数据的结构(哈希表=数组+链表):

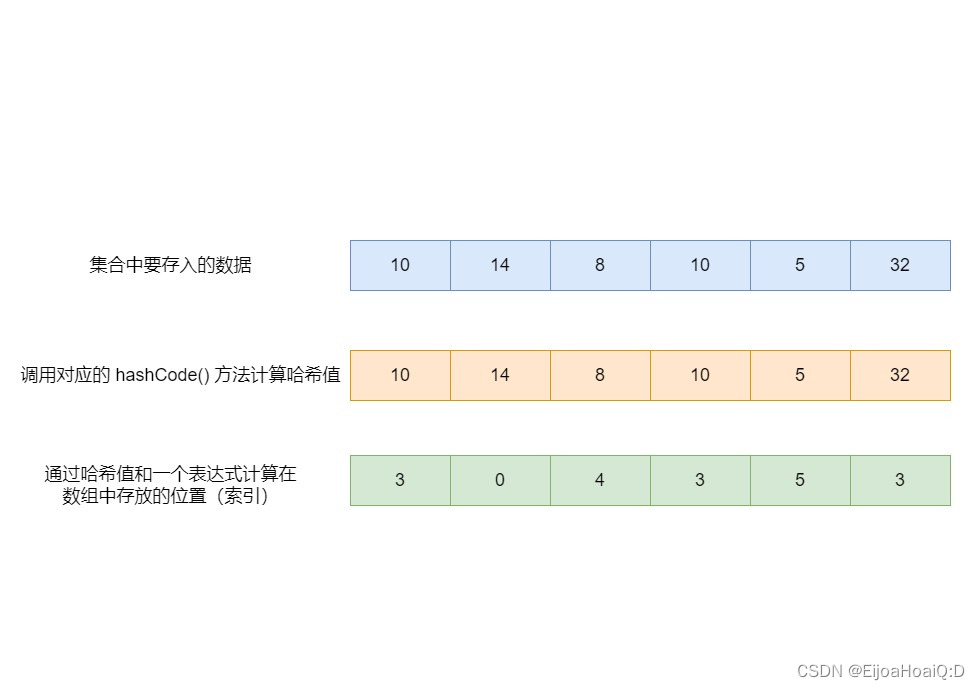
以 Integer 类型为例:
-
首先会调用对应的
hashCode()方法计算哈希值,得到的哈希码与传入的值是对应的:public final class Integer extends Number implements Comparable<Integer> { @Override public int hashCode() { // 调用 hashCode() 方法 return Integer.hashCode(value); } public static int hashCode(int value) { // hashCode() 方法实际上返回的就是存入的 value 值 return value; } }
-
通过哈希值和一个表达式计算元素在数组中存放的位置(索引):
-
判断哈希值(元素)与已经存入 HashSet 中的元素的哈希值是否相同:如果不同,就直接添加;如果相同,就继续调用
equals()方法和哈希值相同的这些元素依次比较:public final class Integer extends Number implements Comparable<Integer> { public boolean equals(Object obj) { if (obj instanceof Integer) { return value == ((Integer)obj).intValue(); } return false; } public int intValue() { // 返回 value 值 return value; } }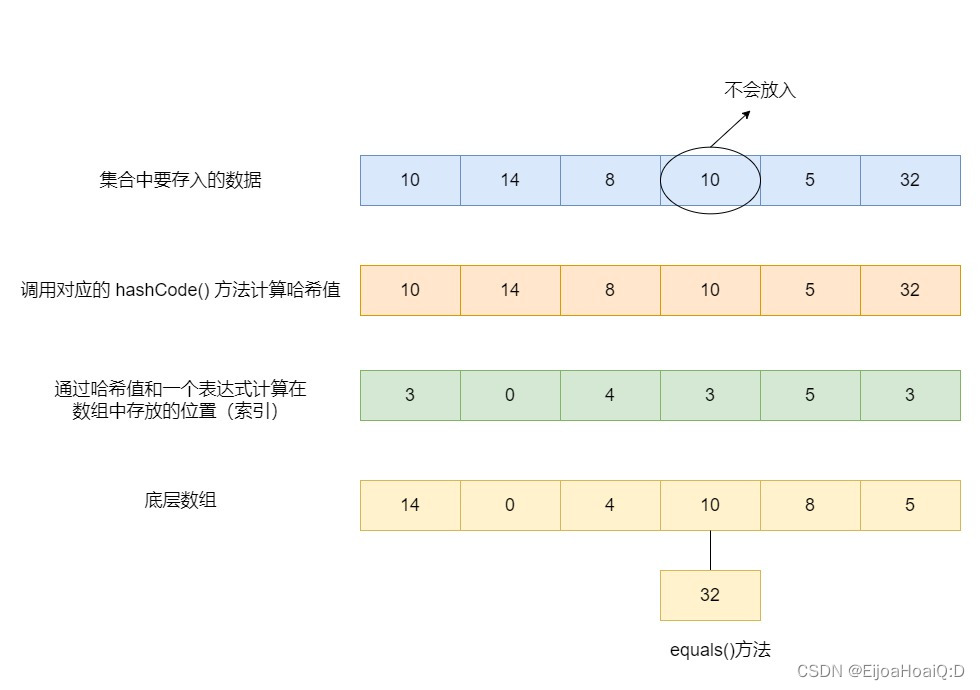
也就是说,保证元素唯一性的方式依赖于 hashCode() 与 equals() 方法。
这样上面的例子就很好解释了:因为 Integer 类型和 String 类型是系统封装好的数据类型,其中的 hashCode() 与 equals() 方法已经重写过了,所以存入的元素是唯一无序的;而自定义的数据类型我并没有重写它的 hashCode() 与 equals() 方法,所以存入的元素是不唯一的。
保证元素唯一性需要让元素重写两个方法:hashCode() 和 equals() 方法。HashSet 在存储元素的过程中首先会去调用元素的 hashCode() 值,看其哈希值与已经存入 HashSet 的元素的哈希值是否相同:如果不同,就直接添加;如果相同,则继续调用元素的 equals() 和哈希值相同的这些元素依次比较。如果说有返回 true 的,那就重复,不添加;如果比较结果都为 false,那就是不重复,要添加。
总而言之,JDK1.8引入红黑树大程度优化了 HashMap 的性能,那么对于我们来讲保证 HashSet 集合元素的唯一, 其实就是根据对象的 hashCode() 和 equals() 方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一, 就必须复写hashCode() 和 equals() 方法,建立属于当前对象的比较方式。
在自定义的数据类型中重写 hashCode() 与 equals() 方法后,再次测试:
/**
* @author QHJ
* @date 2022/10/13 09:32
* @description: HashSet存入自定义的引用数据类型数据
*/
public class StudentInHashSet {
public static void main(String[] args) {
HashSet<Student> hs = new HashSet<>();
hs.add(new Student("青花椒", 22));
hs.add(new Student("lisi", 24));
hs.add(new Student("王五", 12));
hs.add(new Student("青花椒", 22));
hs.add(new Student("zhangsan", 44));
System.out.println(hs.size()); // 4
System.out.println(hs); // [Student{name='zhangsan', age=44}, Student{name='青花椒', age=22}, Student{name='lisi', age=24}, Student{name='王五', age=12}]
}
}
5.2 LinkedHashSet 集合
在 HashSet 下面有一个子类 java.util.LinkedHashSet ,它是链表和哈希表组合的一个数据存储结构,其特点是有序且唯一(按照输入顺序进行输出)。
public class linkedset {
public static void main(String[] args) {
LinkedHashSet<String> set = new LinkedHashSet<>();
set.add("张三");
set.add("李四");
set.add("张三");
set.add("王五");
set.add("赵六");
for (String str:set){
System.out.println(str);// 输出:张三 李四 王五 赵六
}
}
}
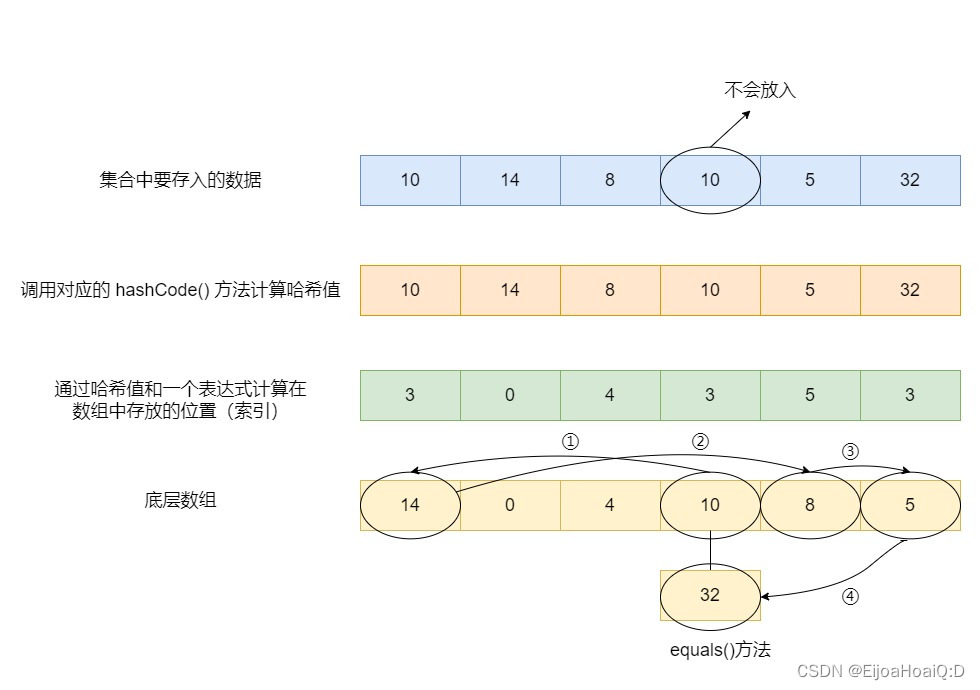
LinkedHashSet 其实就是在 HashSet 的基础上,多了一个总的链表,这个总的链表将放入的元素串在一起,方便有序的遍历:
5.3 TreeSet 集合
01、TreeSet 底层原理
TreeSet 的特点是元素唯一、无序(没有按照输入顺序进行输出,而是按照升序进行遍历)。
TreeSet 的底层原理其实就是实现内部比较器或者外部比较器,所以向 TreeSet 中存放数据的时候,自定义的类必须实现比较器。
扒一下 TreeSet 的源码:
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
// 属性
private transient NavigableMap<E,Object> m;
// 占位符
private static final Object PRESENT = new Object();
// 在调用空构造器的时候,底层创建了一个 TreeMap
public TreeSet() {
this(new TreeMap<E,Object>());
}
// 在此构造器中给 m 赋值
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
// 通过 TreeMap 的 key 来控制 TreeSet
// add() 方法,存入的实际是一个键值对,把值当做 key,PRESENT 当做 value
// 其实每次存入的 value 都是相同的,所以说,PRESENT 只是一个占位符
public boolean add(E e) {
// 这个调用的是 Map 的 put() 方法
return m.put(e, PRESENT)==null;
}
}
02、实现排序的方式
TreeSet 是基于 TreeMap 实现的,是一个包含有序的且没有重复元素的集合,它更重要的作用就是提供有序的 Set 集合,自然排序或者根据提供的 Comparator 进行排序:
-
方式一
让元素所在的类实现 Comparable 接口,并重写 CompareTo() 方法,并根据 CompareTo() 的返回值来进行添加元素。拿要添加的元素与已经添加的元素作比较:
- 返回正数:往二叉树的右边添加;
- 返回负数:往二叉树的左边添加;
- 返回 0:说明重复,不添加。
/** * @author QHJ * @date 2022/10/10 20:08 * @description: Set集合测试 */ public class SetTest { public static void main(String[] args) { TreeSet<Person> ts = new TreeSet<>(); ts.add(new Person("zhangsan", 23)); ts.add(new Person("lisi", 13)); ts.add(new Person("wangwu", 33)); ts.add(new Person("zhaoliu", 43)); ts.add(new Person("lisi", 13)); ts.add(new Person("aaaa", 11)); ts.add(new Person("bbbb", 15)); System.out.println(ts); // [Person{name='aaaa', age=11}, Person{name='lisi', age=13}, Person{name='bbbb', age=15}, Person{name='zhangsan', age=23}, Person{name='wangwu', age=33}, Person{name='zhaoliu', age=43}] } } class Person implements Comparable<Person> { private String name; private int age; public Person() { super(); } public Person(String name, int age) { super(); this.name = name; this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } @Override public int compareTo(Person o) { return this.age - o.age; } } -
方式二
使用 TreeSet 的有参构造方法创建 TreeSet 对象的时候,传入一个比较器 Comparator 进去,TreeSet 在添加元素的时候,根据比较器的 compare() 方法的返回值来添加元素。
- 返回正数:往二叉树的右边添加;
- 返回负数:往二叉树的左边添加;
- 返回 0:说明重复,不添加。
/** * @author QHJ * @date 2022/10/12 10:03 * @description: */ public class TreeSetTest { public static void main(String[] args) { // 在构造函数中传入比较器后 就不用再让 Person 实现 Comparable 接口了 // 这种实现是匿名内部类的方式 TreeSet<Person2> ts = new TreeSet<>(new Comparator<Person2>() { @Override public int compare(Person2 o1, Person2 o2) { return o1.getAge() - o2.getAge(; } }); ts.add(new Person("zhangsan", 23)); ts.add(new Person("lisi", 13)); ts.add(new Person("wangwu", 33)); ts.add(new Person("zhaoliu", 43)); ts.add(new Person("lisi", 13)); ts.add(new Person("aaaa", 11)); ts.add(new Person("bbbb", 15)); System.out.println(ts); } } class Person2 { private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public Person2() { super(); } public Person2(String name, int age) { super(); this.name = name; this.age = age; } @Override public String toString() { return "Person2{" + "name='" + name + '\'' + ", age=" + age + '}'; } }
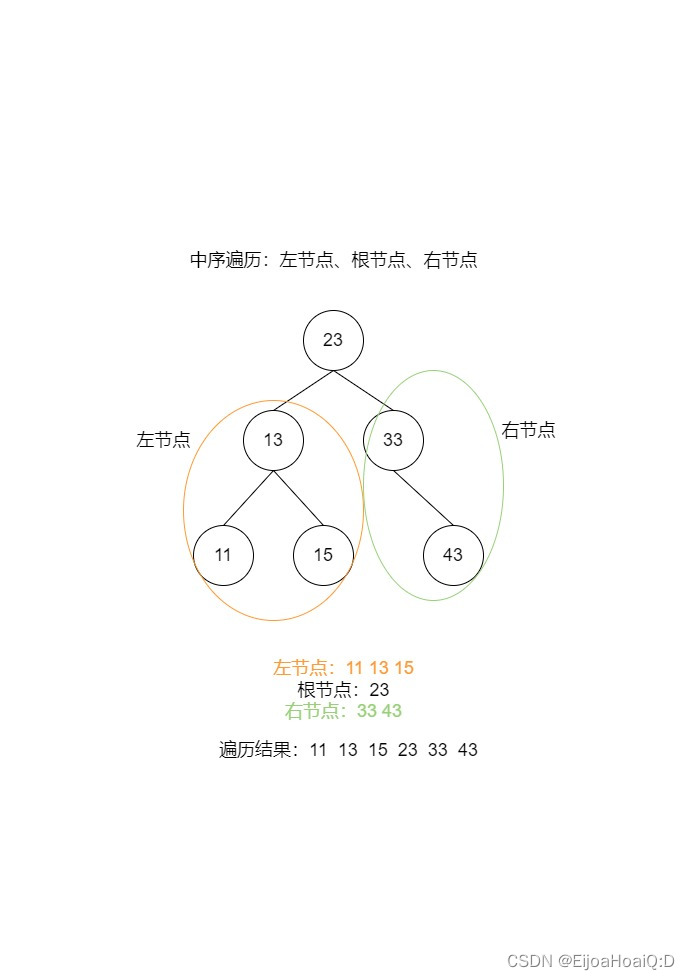
TreeSet 底层的二叉树的遍历是按照升序的结果出现的,这个升序是靠中序遍历得到的:
5.4 Comparable 和 Comparator 的区别
Comparable接口实际上是出自 java.lang 包,它有一个 compareTo(Object obj) 方法用来排序,此接口是将比较代码嵌入自身类中。Comparator接口实际上是出自 java.util 包,它有一个 compare(Object obj1, Object obj2) 方法用来排序,此接口是将比较代码放在一个独立的类中实现的。
| 参数 | Comparable | Comparator |
|---|---|---|
| 排序逻辑 | 排序逻辑必须在待排序对象的类中,所以称之为自然排序 | 排序逻辑在另一个类中实现 |
| 实现 | 实现 Comparable 接口 | 实现 Comparator 接口 |
| 排序方法 | int compareTo(Object o1) | int compare(Object o1, Object o2) |
| 触发排序 | Collections.sort(list) | Collections.sort(List, Comparator) |
| 接口所在包 | java.lang.Comparable | java.util.Comparator |
01、Comparable
Comparable 可以认为是一个内比较器,实现了 Comparable 接口的类有一个特点:就是这些类可以和自己比较,至于具体和另一个实现了 Comparable 接口的类如何比较,就依赖于 compareTo() 方法的实现,compareTo() 方法也被称为自然比较方法。如果你 add 进入一个 Collection 的对象想要 Collections 的 sort() 方法帮你进行自动排序的话,那么就必须实现 Comparable 接口。其中,compareTo() 方法的返回值是 int,有三种情况:
- 比较者大于被比较者(也就是compareTo方法里面的对象),返回正整数;
- 比较者等于被比较者,返回 0;
- 比较者小于被比较者,返回负整数。
例子:
定义一个类 Student.java,实现 Comparable 接口,并重写 compareTo() 方法,则默认比较的是当前 Student 类,通过 age 属性进行比较:
/**
* @author QHJ
* @date 2022/10/12 10:54
* @description: Student 类
*/
public class Student implements Comparable {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Object o) {
Student student = (Student) o;
return this.age - student.getAge();
}
}
/**
* @author QHJ
* @date 2022/10/12 10:56
* @description: 测试类
*/
public class Test {
public static void main(String[] args) {
List<Student> studentList = new ArrayList<>();
Student student;
for (int i = 0; i < 5; i++){
student = new Student("student:" + i, i);
studentList.add(student);
}
Collections.shuffle(studentList);
System.out.println("乱序后:");
studentList.stream().forEach(System.out::println);
Collections.sort(studentList);
System.out.println("排序后:");
studentList.stream().forEach(System.out::println);
}
}
打印输出结果:
02、Comparator
Comparator 可以认为是是一个外比较器,有两种情况可以使用实现Comparator接口的方式:
- 一个对象不支持自己和自己比较(没有实现 Comparable 接口),但是又想对两个对象进行比较。
- 一个对象实现了 Comparable 接口,但是开发者认为 compareTo 方法中的比较方式并不是自己想要的那种比较方式。
Comparator 接口里面有一个 compare 方法,方法有两个参数 T o1 和 T o2,是泛型的表示方式,分别表示待比较的两个对象,方法返回值和 Comparable 接口一样是int,有三种情况:
- o1 大于 o2,返回正整数;
- o1 等于 o2,返回 0;
- o1 小于 o3,返回负整数
例子:
同样是 Student 类,另外再定义一个 StudentComparator 类,实现 Comparator 接口,重写 compare() 方法,根据 age 进行比较:
/**
* @author QHJ
* @date 2022/10/12 11:06
* @description: Student 类
*/
public class Student2{
private String name;
private int age;
public Student2(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
/**
* @author QHJ
* @date 2022/10/12 11:07
* @description:
*/
public class StudentComparator implements Comparator<Student2> {
@Override
public int compare(Student2 o1, Student2 o2) {
return o1.getAge() - o2.getAge();
}
}
/**
* @author QHJ
* @date 2022/10/12 101:07
* @description: 测试类
*/
public class Test2 {
public static void main(String[] args) {
// 方式一
Set<Student2> set = new TreeSet<>(new Comparator<Student2>() {
@Override
public int compare(Student2 o1, Student2 o2) {
return o1.getAge() - o2.getAge();
}
});
// 方式二
Set<Student2> set = new TreeSet<>(new StudentComparator());
Student2 student2;
for (int i = 0; i < 5; i ++){
student2 = new Student2("student2:" + i, i);
set.add(student2);
}
set.stream().forEach(System.out::println);
}
}
打印输出结果:

03、总结
两种比较器,Comparator 比 Comparable 有几个优点:
- 个性化比较:如果实现类没有实现 Comparable 接口,又想对两个类进行比较(或者实现类实现了 Comparable 接口,但是对 compareTo() 方法内的比较算法不满意),那么可以实现 Comparator 接口,自定义一个比较器,写比较算法。
- 解耦:实现 Comparable 接口的方式比实现 Comparator 接口的耦合性要强一些,如果要修改比较算法,要修改 Comparable 接口的实现类,而实现 Comparator 的类是在外部进行比较的,不需要对实现类有任何修改。从这个角度说,其实有些不太好,尤其在我们将实现类的 .class 文件打成一个 .jar 文件提供给开发者使用的时候。
注意:一旦指定了外部比较器,那么就会按照外部比较器来比较。实际开发中利用外部比较器比较多,因为其扩展性好。
5.5 HashSet、LinkedHashSet、TreeSet 异同
- HashSet、LinkedHashSet 和 TreeSet 都是 Set 接口的实现类,都能保证元素唯一,并且都不是线程安全的。
- HashSet、LinkedHashSet 和 TreeSet 的主要区别在于底层数据结构不同。HashSet 的底层数据结构是哈希表(基于 HashMap 实现)。LinkedHashSet 的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。TreeSet 底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。
- 底层数据结构不同又导致这三者的应用场景不同。HashSet 用于不需要保证元素插入和取出顺序的场景,LinkedHashSet 用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet 用于支持对元素自定义排序规则的场景。
无序性和不可重复性的含义:
- 无序性不等于随机性,无序性是指存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值决定的。
- 不可重复性是指添加的元素按照 equals() 判断时 ,返回 false,需要同时重写 equals() 方法和 hashCode() 方法。
5.4 可变参数
在 JDK1.5 之后,如果我们定义一个方法需要接收多个参数,并且多个参数类型一致,我们可以对其简化成如下格式:
//这两种写法完全等价
修饰符 返回值类型 方法名(参数类型... 形参名){ }
修饰符 返回值类型 方法名(参数类型[] 形参名){ }
... 用在参数上,称之为可变参数。
public class kebiancanshu {
public static void main(String[] args) {
int[] arr1 = {1,2,3,4,5};
int s1 = getSum1(arr1);
int[] arr2 = {2,3,4,5,6};
int s2 = getSum2(arr2);
System.out.println("arr1:"+s1+"\tarr2:"+s2);//arr1:15 arr2:20
}
public static int getSum1(int[] arr){
int sum1 = 0;
for (int a:arr){
sum1 += a;
}
return sum1;
}
public static int getSum2(int... arr){
int sum2 = 0;
for (int a:arr){
sum2 += a;
}
return sum2;
}
}
















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









