







在开始之前,我们创建两个表用于演示将要介绍的其中JOIN类型。
建表
CREATE TABLE `tbl_dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`locAdd` VARCHAR(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;CREATE TABLE `tbl_emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`deptId` VARCHAR(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `fk_dept_id` (`deptId`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;初始化数据
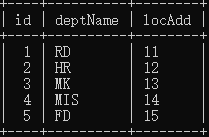
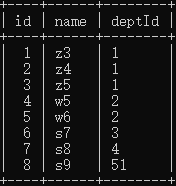
七种JOIN
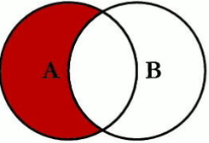
1. A ∩ B

SELECT < select_list >
FROM TableA A
INNER JOIN TableB B # 共有
ON A.Key = B.Key
2. A ( = A ∩ B + A* )

SELECT < select_list >
FROM TableA A
LEFT JOIN TableB B
ON A.Key = B.Key
3. B ( = A ∩ B + B* )

SELECT < select_list >
FROM TableA A
RIGHT JOIN TableB B
ON A.Key = B.Key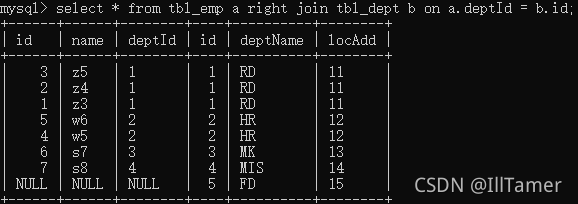
4. A* ( = A - A ∩ B )
SELECT < select_list >
FROM TableA A
LEFT JOIN TableB B
ON A.Key = B.Key # ON时主表保留
WHERE B.Key IS NULL # 筛选A表数据
5. B* ( = B - A ∩ B )
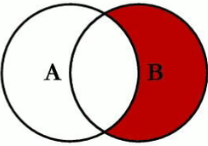
SELECT < select_list >
FROM TableA A
RIGHT JOIN TableB B
ON A.Key = B.Key
WHERE A.Key IS NULL
6. A ∪ B

SELECT < select_list >
FROM TableA A
FULL OUTER JOIN TableB B ## FULL OUTER 仅oracle支持
ON A.Key = B.Key 
7. A ∪ B - A ∩ B

SELECT < select_list >
FROM TableA A
FULL OUTER JOIN TableB B
ON A.Key = B.Key
WHERE A.Key IS NULL OR B.Key IS NULL














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









