









问题描述
渲染页面的时候,往往会遇到富文本编辑器里面的文章。文章内容有排版、字体样式,等等。
但是我们要提取其中前三行作为展示内容,里面又有标签内容。如下图


原因分析:
如果我们要让页面自己识别其中的html标签,那就需要用到v-html
但是这样的话。

不仅仅是布局蹦了,样式也蹦了,我们只需要其中的文字即可,不需要其中的颜色样式。
就需要先把其中的内容,转换成v-html能识别的东西。其中的样式标签就没有了。然后我们再从中提取出text文字。
这是正确用法
我用过另一种用法,就是去除标签。
return html.replace(/<(p|div)[^>]*>(<br\/?>| )<\/\1>/gi, ' ')
.replace(/<br\/?>/gi, ' ')
.replace(/<[^>/]+>/g, '')
.replace(/(\n)?<\/([^>]+)>/g, '')
.replace(/\u00a0/g, ' ')
.replace(/ /g, ' ')
.replace(/<img[^>]+src\\s*=\\s*['\"]([^'\"]+)['\"][^>]*>/g, '')
.replace(/<\/?(img|table)[^>]*>/g, "") // 去除图片和表格
.replace(/<\/?(a)[^>]*>/g, "") // 去除a标签
把它写在过滤器里面,那我们来看看去除标签之后的结果吧。
注意,用过滤器的话,标签就不能用v-html了

当我们用了这种方法之后,有一些空格标签之类的,去不掉

就会很头痛,然后我参考了大大小小很多的去除标签文章
解决方案:
我看到了下面的代码
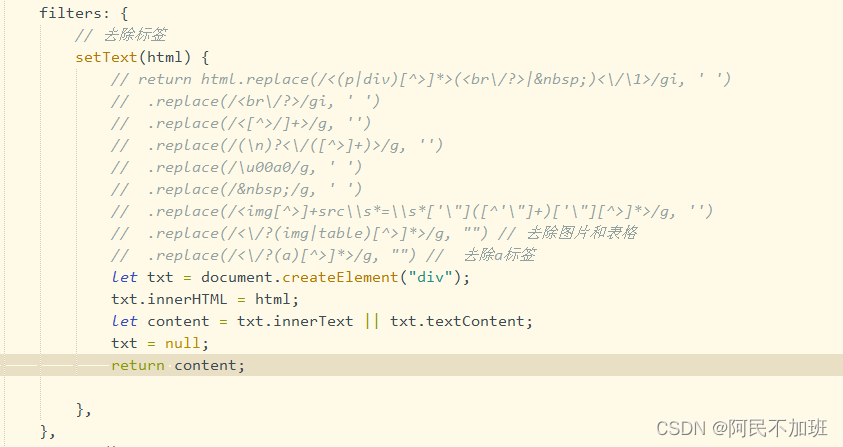
filters: {
// 去除标签
setText(html) {
let txt = document.createElement("div");
txt.innerHTML = html;
let content = txt.innerText || txt.textContent;
txt = null;
return content;
}
}
先把代码转化,然后再提取文字。

至于第二个图中出现的 &Idquo; 这些是古老的符号了,是那种十年前甚至更久的富文本编辑器中的符号,现在是转化不出来不被识别的。已经过时了的。
所以这个方法很好用。















 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











