







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
温度预测,实现过程
前言
主要了解训练过程

一、数据读取和预处理
二、使用步骤
1.引入库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.optim as optim
import datetime
from sklearn.preprocessing import StandardScaler
2.读入数据
代码如下(示例):
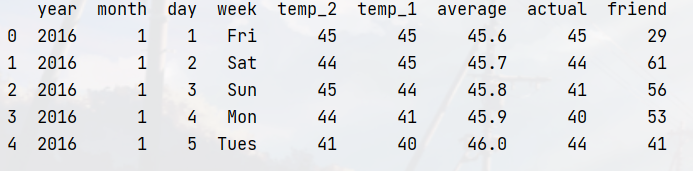
features = pd.read_csv('E:/code/map_code/神经网络实战分类与回归任务/temps.csv')
'''
temp_2:前天的最高温度值
temp_1:昨天的最高温度值
average:在历史中,每年这一天的平均最高温度值
actual:标签值,当天的真实最高温度
'''
print(features.head())
years = features['year']
months = features['month']
days = features['day']
#datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years,months,days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
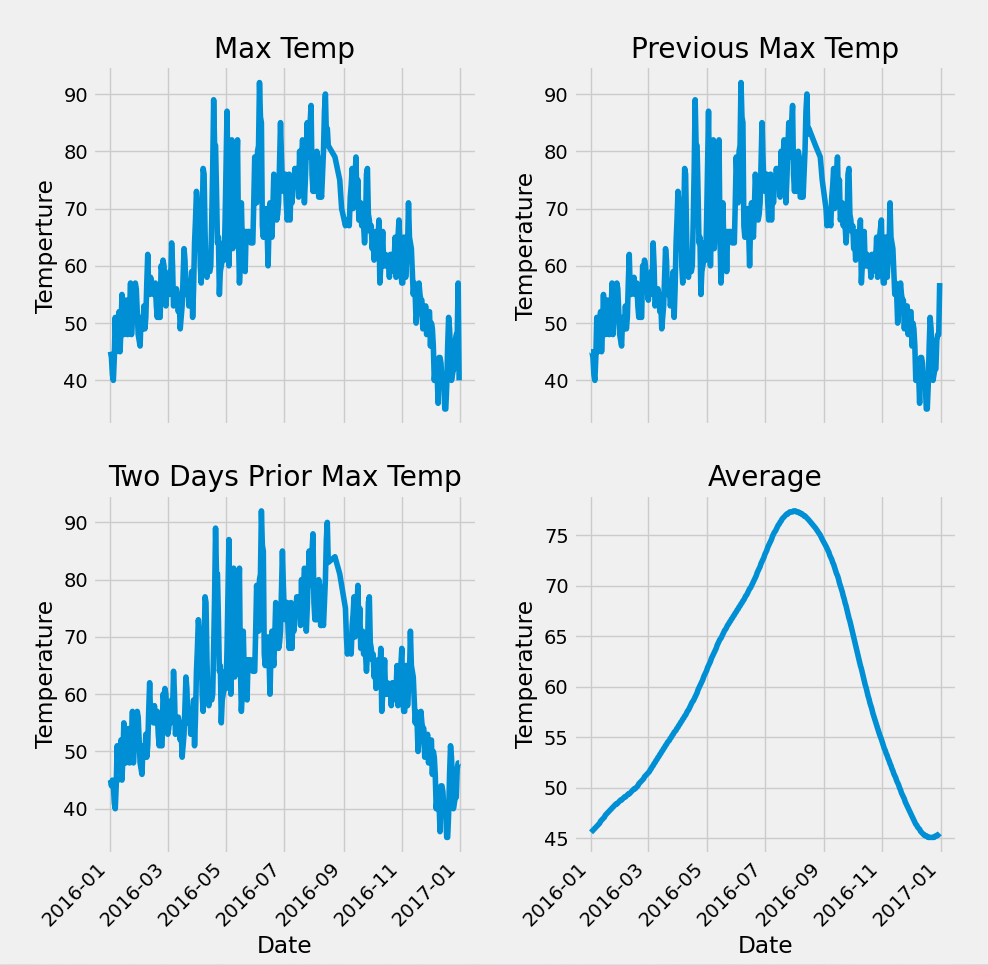
#数据展示
plt.style.use('fivethirtyeight')
#设置布局
fig, ((ax1, ax2),(ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10,10)) # 创建2×2的子图网格
fig.autofmt_xdate(rotation = 45) # 自动旋转x轴日期标签45度,避免重叠
# 标签值
ax1.plot(dates, features['actual']) #绘制日期与实际温度的关系曲线
ax1.set_xlabel('');ax1.set_ylabel('Temperture');ax1.set_title('Max Temp') #set_xlabel('') 移除了 x 轴标签(因为日期标签在底部子图中已有),set_ylabel() 和 set_title() 设置了 y 轴标签和子图标题
# 昨天
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel(''); ax2.set_ylabel('Temperature'); ax2.set_title('Previous Max Temp')
# 前天
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature'); ax3.set_title('Two Days Prior Max Temp')
#平均值
ax4.plot(dates, features['average'])
ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature'); ax4.set_title('Average')
plt.tight_layout(pad=2)
plt.show()
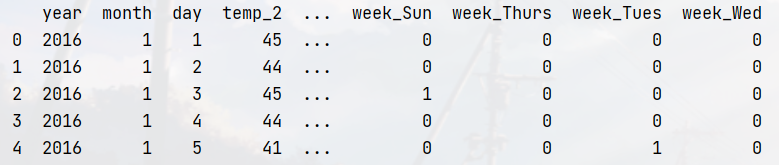
3.数据预处理
features = pd.get_dummies(features) #将week属性修改为独热编码
print(features.head())
#制作标签
labels = np.array(features['actual'])
#在特征中剔除标签
features = features.drop('actual', axis = 1)
#名字单独保存
feature_list = list(features.columns)
#特征转换为np格式
features = np.array(features)
#数据归一化
scaler = StandardScaler()
features = scaler.fit_transform(features) # 使每个特征的均值为0,方差为1
#创建归一化的变量x
x = torch.tensor(features,requires_grad=True) #torch.Size([348, 14])
y = torch.tensor(labels).unsqueeze(1) # shape: (348, 1) #torch.Size([348])
input_size = features.shape[1] # 14(从数据中获取输入特征数)
#初始化所有神经网络的权重和偏执值
hidden_size = 32 # 隐含层节点数
weights = torch.randn((input_size,hidden_size),dtype=torch.double, requires_grad=True)
biases = torch.randn(hidden_size,dtype=torch.double, requires_grad=True)
weights2 = torch.randn((hidden_size,1),dtype=torch.double,requires_grad=True)
#设置学习率
learning_rate = 0.01
losses = []
独热编码后的数据
4.训练过程
for i in range(10000):
#从输入层到隐藏层的计算
hidden = torch.matmul(x, weights) + biases
#将sigmoid函数作用在隐藏层的每一个神经元上
hidden = torch.sigmoid(hidden)
#隐藏层到输出层,计算得到最终预测
predictions = hidden.mm(weights2)
#通过与标签数据y比较,计算均方误差
loss = torch.mean((predictions - y) ** 2)
losses.append(loss.data.numpy())
#每隔1000个周期打印一次损失函数值
if i % 10 == 0:
print('loss:',loss)
#对损失函数进行梯度反转
loss.backward()
#利用上一步计算得到的weights,biases等梯度信息更新weights或biases中的data数值
weights.data.add_(-learning_rate * weights.grad.data)
biases.data.add_(-learning_rate * biases.grad.data)
weights2.data.add_(-learning_rate * weights2.grad.data)
#清空所有变量的梯度值,pytorch中的backward一次梯度信息会自动累加到各个变量上,因此需要清空,否则下一次迭代会累加,造成很大的偏差
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()
总结
完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.optim as optim
import datetime
features = pd.read_csv('E:/code/map_code/神经网络实战分类与回归任务/temps.csv')
'''
temp_2:前天的最高温度值
temp_1:昨天的最高温度值
average:在历史中,每年这一天的平均最高温度值
actual:标签值,当天的真实最高温度
'''
print(features.head())
years = features['year']
months = features['month']
days = features['day']
#datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years,months,days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
#数据展示
plt.style.use('fivethirtyeight')
#设置布局
fig, ((ax1, ax2),(ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10,10)) # 创建2×2的子图网格
fig.autofmt_xdate(rotation = 45) # 自动旋转x轴日期标签45度,避免重叠
# 标签值
ax1.plot(dates, features['actual']) #绘制日期与实际温度的关系曲线
ax1.set_xlabel('');ax1.set_ylabel('Temperture');ax1.set_title('Max Temp') #set_xlabel('') 移除了 x 轴标签(因为日期标签在底部子图中已有),set_ylabel() 和 set_title() 设置了 y 轴标签和子图标题
# 昨天
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel(''); ax2.set_ylabel('Temperature'); ax2.set_title('Previous Max Temp')
# 前天
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature'); ax3.set_title('Two Days Prior Max Temp')
#平均值
ax4.plot(dates, features['average'])
ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature'); ax4.set_title('Average')
plt.tight_layout(pad=2)
plt.show()
#独热编码
features = pd.get_dummies(features) #将week属性修改为独热编码
print(features.head())
#制作标签
labels = np.array(features['actual'])
#在特征中剔除标签
features = features.drop('actual', axis = 1)
#名字单独保存
feature_list = list(features.columns)
#特征转换为np格式
features = np.array(features)
#创建归一化的变量x
x = torch.tensor(features,requires_grad=True) #torch.Size([348, 14])
y = torch.tensor(labels).unsqueeze(1) # shape: (348, 1) #torch.Size([348])
input_size = features.shape[1] # 14(从数据中获取输入特征数)
#初始化所有神经网络的权重和偏执值
hidden_size = 32 # 隐含层节点数
weights = torch.randn((input_size,hidden_size),dtype=torch.double, requires_grad=True)
biases = torch.randn(hidden_size,dtype=torch.double, requires_grad=True)
weights2 = torch.randn((hidden_size,1),dtype=torch.double,requires_grad=True)
#设置学习率
learning_rate = 0.01
losses = []
print('维度',x.size(),y.size())
# x = x.view(50,-1)
# y = y.view(50,-1)
for i in range(10000):
#从输入层到隐藏层的计算
hidden = torch.matmul(x, weights) + biases
#将sigmoid函数作用在隐藏层的每一个神经元上
hidden = torch.sigmoid(hidden)
#隐藏层到输出层,计算得到最终预测
predictions = hidden.mm(weights2)
#通过与标签数据y比较,计算均方误差
loss = torch.mean((predictions - y) ** 2)
losses.append(loss.data.numpy())
#每隔1000个周期打印一次损失函数值
if i % 10 == 0:
print('loss:',loss)
#对损失函数进行梯度反转
loss.backward()
#利用上一步计算得到的weights,biases等梯度信息更新weights或biases中的data数值
weights.data.add_(-learning_rate * weights.grad.data)
biases.data.add_(-learning_rate * biases.grad.data)
weights2.data.add_(-learning_rate * weights2.grad.data)
#清空所有变量的梯度值,pytorch中的backward一次梯度信息会自动累加到各个变量上,因此需要清空,否则下一次迭代会累加,造成很大的偏差
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









