







文章目录
npm ||package.json
npm
npm(全称 Node Package Manager)是 Node.js 的包管理工具,它是一个基于命令行的工具,用于帮助开发者在自己的项目中安装、升级、移除和管理依赖项。
https://www.npmjs.com/
类似于 PHP 的工具:Composer。它是 PHP 的包管理器,可以用于下载、安装和管理 PHP 的依赖项,类似于 npm。
类似于 Java 的工具:Maven。它是 Java 的构建工具和项目管理工具,可以自动化构建、测试和部署 Java 应用程序,类似于 npm 和 webpack 的功能。
类似于 Python 的工具:pip。它是 Python 的包管理器,可以用于安装和管理 Python 的依赖项,类似于 npm。
类似于 Rust 的工具:Cargo。它是 Rust 的包管理器和构建工具,可以用于下载、编译和管理 Rust 的依赖项,类似于 npm 和 Maven 的功能。
npm 命令
-
npm init:初始化一个新的 npm 项目,创建 package.json 文件。 -
npm install:安装一个包或一组包,并且会在当前目录存放一个node_modules。 -
npm install <package-name>:安装指定的包。 -
npm install <package-name> --save:安装指定的包,并将其添加到 package.json 文件中的依赖列表中。 -
npm install <package-name> --save-dev:安装指定的包,并将其添加到 package.json 文件中的开发依赖列表中。 -
npm install -g <package-name>:全局安装指定的包。 -
npm update <package-name>:更新指定的包。 -
npm uninstall <package-name>:卸载指定的包。 -
npm run <script-name>:执行 package.json 文件中定义的脚本命令。 -
npm search <keyword>:搜索 npm 库中包含指定关键字的包。 -
npm infos <package-name>:查看指定包的详细信息。 -
npm list:列出当前项目中安装的所有包。 -
npm outdated:列出当前项目中需要更新的包。 -
npm audit:检查当前项目中的依赖项是否存在安全漏洞。 -
npm publish:发布自己开发的包到 npm 库中。 -
npm login:登录到 npm 账户。 -
npm logout:注销当前 npm 账户。 -
npm link: 将本地模块链接到全局的 node_modules 目录下 -
npm config list用于列出所有的 npm 配置信息。执行该命令可以查看当前系统和用户级别的所有 npm 配置信息,以及当前项目的配置信息(如果在项目目录下执行该命令) -
npm get registry用于获取当前 npm 配置中的 registry 配置项的值。registry 配置项用于指定 npm 包的下载地址,如果未指定,则默认使用 npm 官方的包注册表地址 -
npm set registry ,npm config set registry <registry-url>命令,将 registry 配置项的值修改为指定的 地址
Package json
执行npm init 便可以初始化一个package.json
name:项目名称,必须是唯一的字符串,通常采用小写字母和连字符的组合。version:项目版本号,通常采用语义化版本号规范。description:项目描述。main:项目的主入口文件路径,通常是一个 JavaScript 文件。keywords:项目的关键字列表,方便他人搜索和发现该项目。author:项目作者的信息,包括姓名、邮箱、网址等。license:项目的许可证类型,可以是自定义的许可证类型或者常见的开源许可证(如 MIT、Apache 等)。dependencies:项目所依赖的包的列表,这些包会在项目运行时自动安装。devDependencies:项目开发过程中所需要的包的列表,这些包不会随项目一起发布,而是只在开发时使用。比如webpack,vite,rollup相关的(生产环境不需要s)peerDependencies:项目的同级依赖,即项目所需要的模块被其他模块所依赖。(一般是给编写插件的人员,或者是编写npm包的开发人员使用的),比如开发一个vite-plugin-sz插件,无法凭空运行,需要宿主环境,我需要安装vite才行。这个vite就在peerDependencies下面scripts:定义了一些脚本命令,比如启动项目、运行测试等。repository:项目代码仓库的信息,包括类型、网址等。bugs:项目的 bug 报告地址。homepage:项目的官方网站地址或者文档地址。
version 三段式版本号一般是1.0.0 大版本号 次版本号 修订号,
大版本号一般是有重大变化才会升级,
次版本号一般是增加功能进行升级,
修订号一般是修改bug进行升级
npm install 安装模块的时候一般是扁平化安装的,但是有时候出现嵌套的情况是因为版本不同
A 依赖 C1.0,
B 依赖 C1.0,
D 依赖 C2.0,
此时C 1.0就会被放到A B的node_moduels,
C2.0 会被放入D模块下面的node_moduels
npm install 原理
在执行npm install 的时候发生了什么?
首先安装的依赖都会存放在根目录的node_modules,默认采用扁平化的方式安装,并且排序规则.bin第一个然后@系列,再然后按照首字母排序abcd等,并且使用的算法是广度优先遍历,在遍历依赖树时,npm会首先处理项目根目录下的依赖,然后逐层处理每个依赖包的依赖,直到所有依赖都被处理完毕。在处理每个依赖时,npm会检查该依赖的版本号是否符合依赖树中其他依赖的版本要求,如果不符合,则会尝试安装适合的版本
扁平化?
扁平化只是理想状态如下
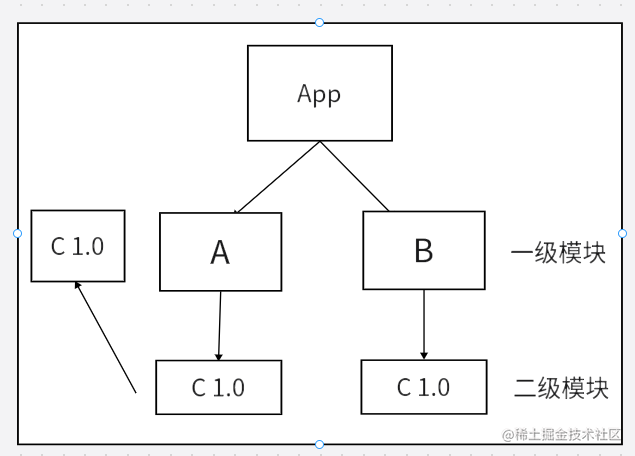
安装某个二级模块时,若发现第一层级有相同名称,相同版本的模块,便直接复用那个模块
因为A模块下的C模块被安装到了第一级,这使得B模块能够复用处在同一级下;且名称,版本,均相同的C模块
非理想状态下
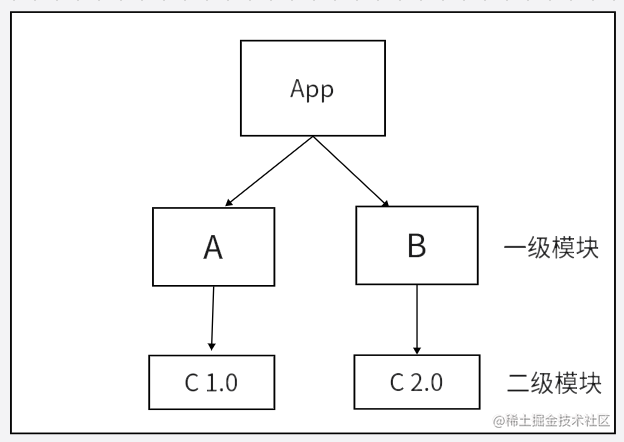
因为B和A所要求的依赖模块不同,(B下要求是v2.0的C,A下要求是v1.0的C )所以B不能像2中那样复用A下的C v1.0模块 所以如果这种情况还是会出现模块冗余的情况,他就会给B继续搞一层node_modules,就是非扁平化了。
npm install 后续流程
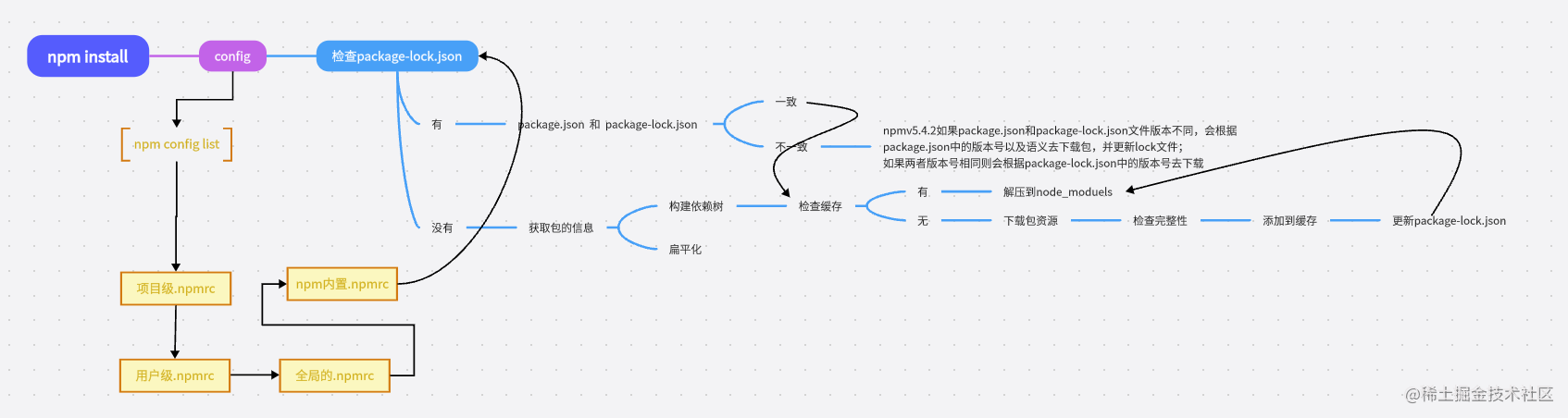
具体过程看图就可以了很详细
至于npmrc可以配置什么给大家一个demo参考
registry=http://registry.npmjs.org/
# 定义npm的registry,即npm的包下载源
proxy=http://proxy.example.com:8080/
# 定义npm的代理服务器,用于访问网络
https-proxy=http://proxy.example.com:8080/
# 定义npm的https代理服务器,用于访问网络
strict-ssl=true
# 是否在SSL证书验证错误时退出
cafile=/path/to/cafile.pem
# 定义自定义CA证书文件的路径
user-agent=npm/{npm-version} node/{node-version} {platform}
# 自定义请求头中的User-Agent
save=true
# 安装包时是否自动保存到package.json的dependencies中
save-dev=true
# 安装包时是否自动保存到package.json的devDependencies中
save-exact=true
# 安装包时是否精确保存版本号
engine-strict=true
# 是否在安装时检查依赖的node和npm版本是否符合要求
scripts-prepend-node-path=true
# 是否在运行脚本时自动将node的路径添加到PATH环境变量中
package-lock.json 的作用
很多朋友只知道这个东西可以锁定版本记录依赖树详细信息
-
version 该参数指定了当前包的版本号
-
resolved 该参数指定了当前包的下载地址
-
integrity 用于验证包的完整性
-
dev 该参数指定了当前包是一个开发依赖包
-
bin 该参数指定了当前包中可执行文件的路径和名称
-
engines 该参数指定了当前包所依赖的Node.js版本范围
知识点来了,package-lock.json 帮我们做了缓存,他会通过 name + version + integrity 信息生成一个唯一的key,这个key能找到对应的index-v5 下的缓存记录 也就是npm cache 文件夹下的
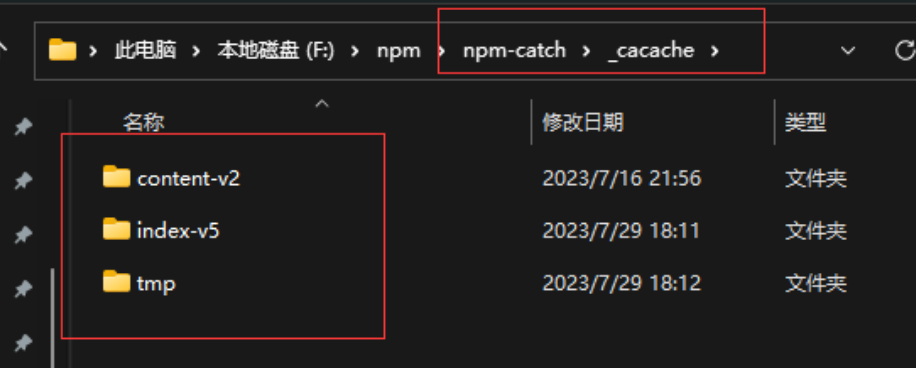 如果发现有缓存记录,就会找到tar包的hash值,然后将对应的二进制文件解压到node_modeules
如果发现有缓存记录,就会找到tar包的hash值,然后将对应的二进制文件解压到node_modeules
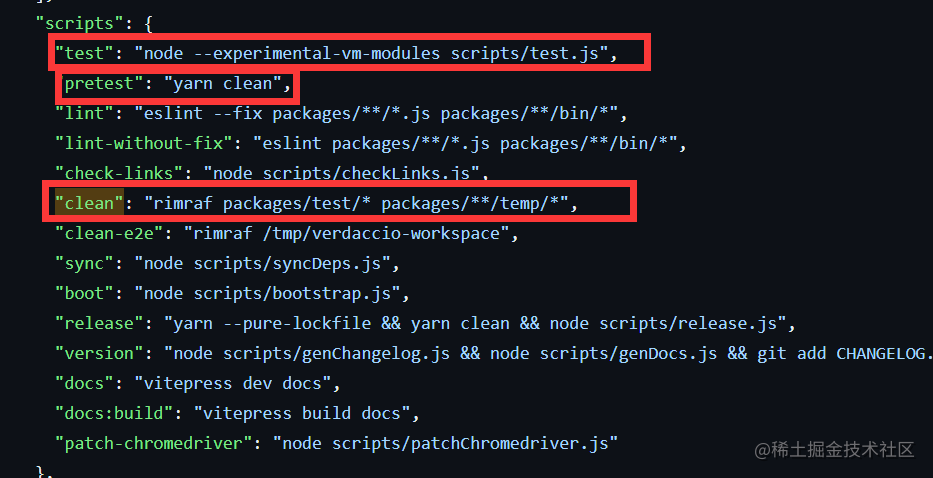
npm run 原理
npm run xxx 发生了什么
按照下面的例子npm run dev 举例过程中发生了什么
读取package json 的scripts 对应的脚本命令(dev:vite),vite是个可执行脚本,他的查找规则是:
- 先从当前项目的node_modules/.bin去查找可执行命令vite
- 如果没找到就去全局的node_modules 去找可执行命令vite
- 如果还没找到就去环境变量查找
- 再找不到就进行报错
如果成功找到会发现有三个文件
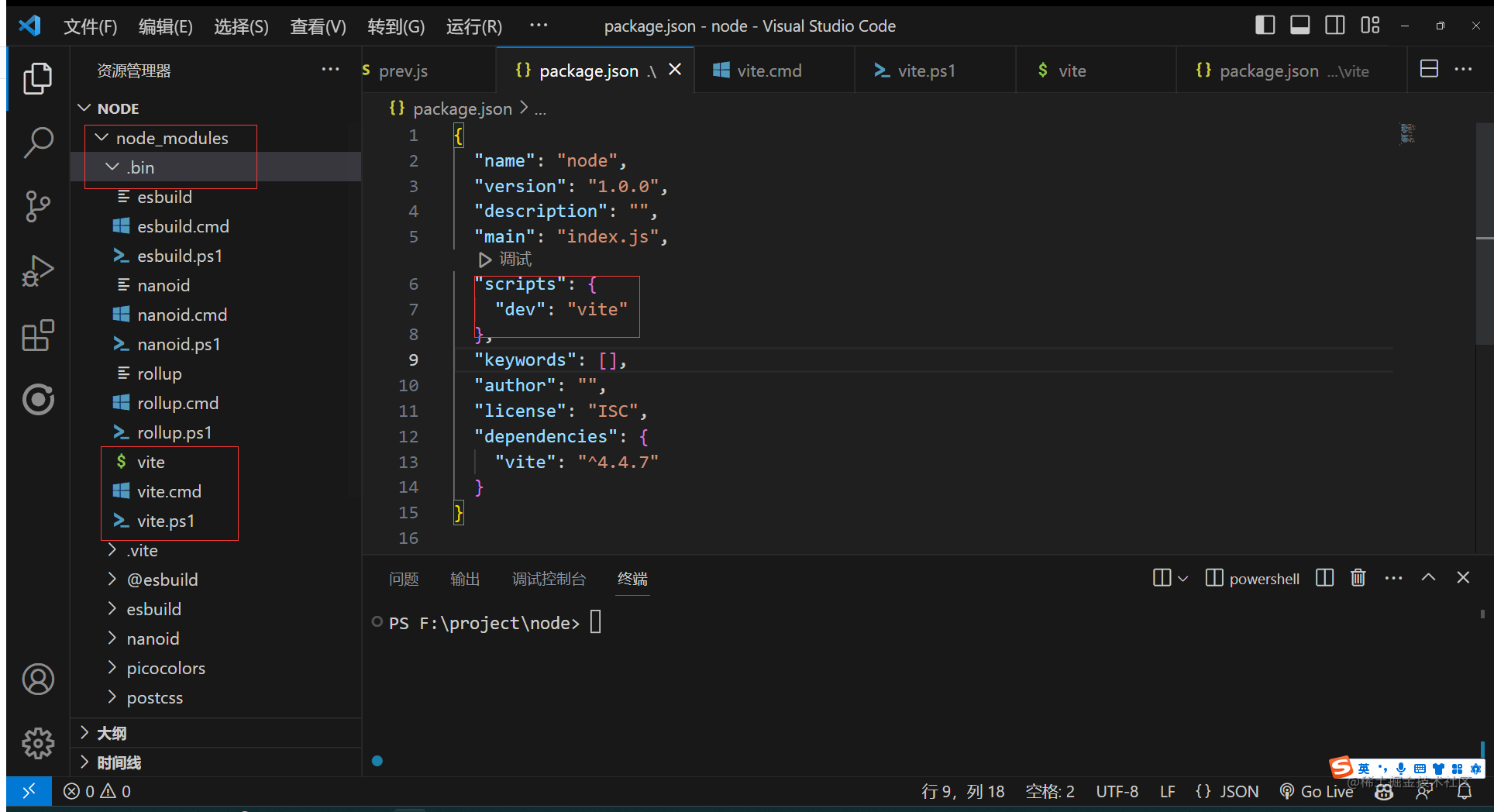
因为nodejs 是跨平台的所以可执行命令兼容各个平台
- .sh文件是给Linux unix Macos 使用
- .cmd 给windows的cmd使用
- .ps1 给windows的powerShell 使用
npm 生命周期
"predev": "node prev.js",
"dev": "node index.js",
"postdev": "node post.js"
执行 npm run dev 命令的时候 predev 会自动执行 他的生命周期是在dev之前执行,然后执行dev命令,再然后执行postdev,也就是dev之后执行
运用场景例如npm run build 可以在打包之后删除dist目录等等
post例如你编写完一个工具发布npm,那就可以在之后写一个ci脚本顺便帮你推送到git等等
谁用到了例如vue-cli
https://github.com/vuejs/vue-cli/blob/dev/package.json
npx
npx是什么
npx是一个命令行工具,它是npm 5.2.0版本中新增的功能。它允许用户在不安装全局包的情况下,运行已安装在本地项目中的包或者远程仓库中的包。
npx的作用是在命令行中运行node包中的可执行文件,而不需要全局安装这些包。这可以使开发人员更轻松地管理包的依赖关系,并且可以避免全局污染的问题。它还可以帮助开发人员在项目中使用不同版本的包,而不会出现版本冲突的问题。
1.npx优势
-
避免全局安装:npx允许你执行npm package,而不需要你先全局安装它。
-
总是使用最新版本:如果你没有在本地安装相应的npm package,npx会从npm的package仓库中下载并使用最新版。
-
执行任意npm包:npx不仅可以执行在package.json的scripts部分定义的命令,还可以执行任何npm package。
-
执行GitHub gist:npx甚至可以执行GitHub gist或者其他公开的JavaScript文件。
npm 和 npx 区别
npx侧重于执行命令的,执行某个模块命令。虽然会自动安装模块,但是重在执行某个命令
npm侧重于安装或者卸载某个模块的。重在安装,并不具备执行某个模块的功能。
示例
https://create-react-app.bootcss.com/docs/getting-started
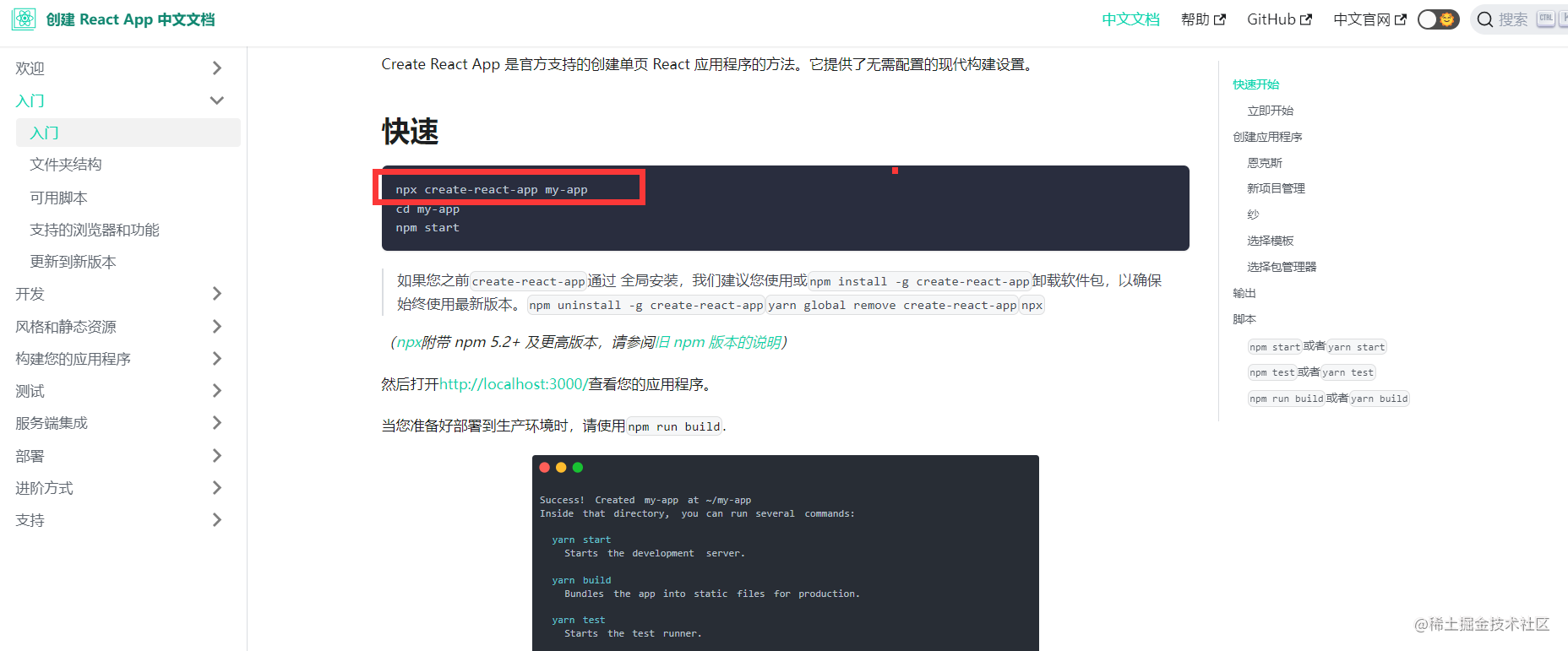
例如创建一个react项目 在之前需要安装到全局
npm install -g create-react-app
然后执行 create-react-app my-app 这样的话会有两个问题
- 首先需要全局安装这个包占用磁盘空间
- 并且如果需要更新还得执行更新命令
示例2
npm ls -g 查看全局安装的包
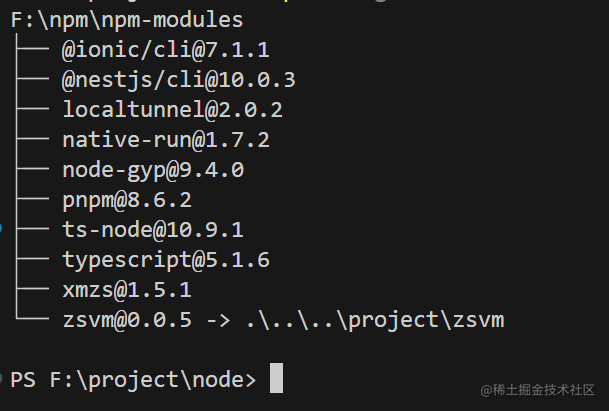
我全局并没有安装vite
当前项目安装vite
npm i vite -D
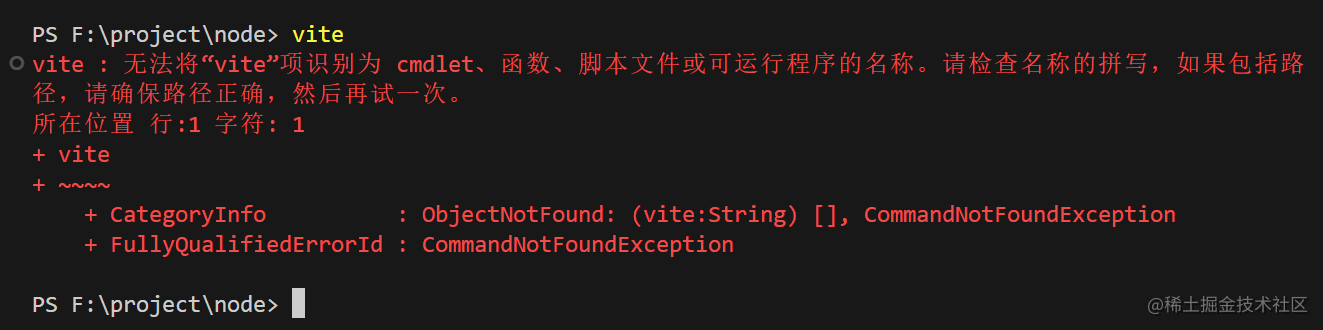
安装完成之后发现无法执行运行vite命令
这时候就可以使用npx vite 了
npx 的运行规则和npm 是一样的 本地目录查找.bin 看有没有 如果没有就去全局的node_moduels 查找,如果还没有就去下载这个包然后运行命令,然后删除这个包
发布npm包
发布npm的包的好处是什么
- 方便团队或者跨团队共享代码,使用npm包就可以方便的管理,并且还可以进行版本控制
- 做开源造轮子必备技术,否则你做完的轮子如何让别人使用难道是U盘拷贝?
- 面试题我面字节的时候就问到了这个
- 增加个人IP 让更多的人知道你的技术能力和贡献
发布前准备工作
npm adduser
首先先检查一下是否是npm源然后创建一个npm账号(可以去npm官网注册账号)

创建完成之后使用npm login 登录账号
发布
登录完成之后使用npm publish 发布npm包
如果出现403说明包名被占用了
npm搭建私服
构建npm私服
构建私服有什么收益吗?
可以离线使用,你可以将npm私服部署到内网集群,这样离线也可以访问私有的包。
提高包的安全性,使用私有的npm仓库可以更好的管理你的包,避免在使用公共的npm包的时候出现漏洞。
提高包的下载速度,使用私有 npm 仓库,你可以将经常使用的 npm 包缓存到本地,从而显著提高包的下载速度,减少依赖包的下载时间。这对于团队内部开发和持续集成、部署等场景非常有用
如何搭建npm 私服
https://verdaccio.org/zh-CN/
Verdaccio 是可以帮我们快速构建npm私服的一个工具
npm install verdaccio -g
使用方式非常简单
verdaccio 直接运行即可
然后访问4873默认端口即可
切换为中文简体即可

基本命令
#创建账号
npm adduser --registry http://localhost:4873/
# 账号 密码 邮箱
# 发布npm
npm publish --registry http://localhost:4873/
#指定开启端口 默认 4873
verdaccio --listen 9999
弹幕:可以新建.npmrc文件,里面指定镜像源,就不用在命令上带了
其他配置文件项
npm模块化
Nodejs 模块化规范遵循两套一 套CommonJS规范另一套esm规范
CommonJS 规范
package.json 设置 type:commonjs
package.json
引入模块(require)支持四种格式
- 支持引入内置模块例如 http os fs child_process 等nodejs内置模块
- 支持引入第三方模块express md5 koa 等
- 支持引入自己编写的模块 ./ …/ 等
- 支持引入addon C++扩展模块 .node文件
- 支持引入json文件
const fs = require('node:fs'); // 导入nodejs自带的核心模块,高版本需要node:
const express = require('express'); // 导入 node_modules 目录下的模块
const myModule = require('./myModule.js'); // 导入相对路径下的模块
const nodeModule = require('./myModule.node'); // 导入扩展模块
const data = require('./data.json') //导入json文件
导出模块exports 和 module.exports
module.exports = {
hello: function() {
console.log('Hello, world!');
}
};
如果不想导出对象直接导出值
module.exports = 123
ESM模块规范
引入模块 import 必须写在头部
注意使用ESM模块的时候必须开启一个选项
打开package.json 设置 type:module
import fs from 'node:fs'
如果要引入json文件需要特殊处理 需要增加断言并且指定类型json node低版本不支持
import data from './data.json' assert { type: "json" };
console.log(data);
加载模块的整体对象
import * as all from 'xxx.js'
动态导入模块
import静态加载不支持掺杂在逻辑中
如果非要参杂在逻辑里面,想动态加载请使用import函数模式
if(true){
import('./test.js').then()
}
模块导出
- 导出一个默认对象 default只能有一个不可重复export default
export default {
name: 'test',
}
- 导出变量
export const a = 1
export const name = 'sz123'
导入支持别名(防止出现)
import obj,{name as sz} from './test.js'//支持别名
let name = 'ssssss'//出现变量同名的情况
console.log(sz,name) //sz123 , sssssss
Cjs 和 ESM 的区别
- Cjs是基于运行时的同步加载,esm是基于编译时的异步加载
- Cjs是可以修改值的,esm值并且不可修改(可读的)
- Cjs不可以tree shaking,esm支持tree shaking
- commonjs中顶层的this指向这个模块本身,而ES6中顶层this指向undefined
nodejs部分源码解析
.json文件如何处理
Module._extensions['.json'] = function(module, filename) {
const content = fs.readFileSync(filename, 'utf8');
if (policy?.manifest) {
const moduleURL = pathToFileURL(filename);
policy.manifest.assertIntegrity(moduleURL, content);
}
try {
setOwnProperty(module, 'exports', JSONParse(stripBOM(content)));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};
使用fs读取json文件读取完成之后是个字符串 然后JSON.parse变成对象返回
.node文件如何处理
Module._extensions['.node'] = function(module, filename) {
if (policy?.manifest) {
const content = fs.readFileSync(filename);
const moduleURL = pathToFileURL(filename);
policy.manifest.assertIntegrity(moduleURL, content);
}
// Be aware this doesn't use `content`
return process.dlopen(module, path.toNamespacedPath(filename));
};
发现是通过process.dlopen 方法处理.node文件
.js文件如何处理
Module._extensions['.js'] = function(module, filename) {
// If already analyzed the source, then it will be cached.
//首先尝试从cjsParseCache中获取已经解析过的模块源代码,如果已经缓存,则直接使用缓存中的源代码
const cached = cjsParseCache.get(module);
let content;
if (cached?.source) {
content = cached.source; //有缓存就直接用
cached.source = undefined;
} else {
content = fs.readFileSync(filename, 'utf8'); //否则从文件系统读取源代码
}
//是不是.js结尾的文件
if (StringPrototypeEndsWith(filename, '.js')) {
//读取package.json文件
const pkg = readPackageScope(filename);
// Function require shouldn't be used in ES modules.
//如果package.json文件中有type字段,并且type字段的值为module,并且你使用了require
//则抛出一个错误,提示不能在ES模块中使用require函数
if (pkg?.data?.type === 'module') {
const parent = moduleParentCache.get(module);
const parentPath = parent?.filename;
const packageJsonPath = path.resolve(pkg.path, 'package.json');
const usesEsm = hasEsmSyntax(content);
const err = new ERR_REQUIRE_ESM(filename, usesEsm, parentPath,
packageJsonPath);
// Attempt to reconstruct the parent require frame.
//如果抛出了错误,它还会尝试重构父模块的 require 调用堆栈
//,以提供更详细的错误信息。它会读取父模块的源代码,并根据错误的行号和列号,
//在源代码中找到相应位置的代码行,并将其作为错误信息的一部分展示出来。
if (Module._cache[parentPath]) {
let parentSource;
try {
parentSource = fs.readFileSync(parentPath, 'utf8');
} catch {
// Continue regardless of error.
}
if (parentSource) {
const errLine = StringPrototypeSplit(
StringPrototypeSlice(err.stack, StringPrototypeIndexOf(
err.stack, ' at ')), '\n', 1)[0];
const { 1: line, 2: col } =
RegExpPrototypeExec(/(\d+):(\d+)\)/, errLine) || [];
if (line && col) {
const srcLine = StringPrototypeSplit(parentSource, '\n')[line - 1];
const frame = `${parentPath}:${line}\n${srcLine}\n${
StringPrototypeRepeat(' ', col - 1)}^\n`;
setArrowMessage(err, frame);
}
}
}
throw err;
}
}
module._compile(content, filename);
};
如果缓存过这个模块就直接从缓存中读取,如果没有缓存就从fs读取文件,并且判断如果是cjs但是type为module就报错,并且从父模块读取详细的行号进行报错,如果没问题就调用 compile
Module.prototype._compile = function(content, filename) {
let moduleURL;
let redirects;
const manifest = policy?.manifest;
if (manifest) {
moduleURL = pathToFileURL(filename);
//函数将模块文件名转换为URL格式
redirects = manifest.getDependencyMapper(moduleURL);
//redirects是一个URL映射表,用于处理模块依赖关系
manifest.assertIntegrity(moduleURL, content);
//manifest则是一个安全策略对象,用于检测模块的完整性和安全性
}
/**
* @filename {string} 文件名
* @content {string} 文件内容
*/
const compiledWrapper = wrapSafe(filename, content, this);
let inspectorWrapper = null;
if (getOptionValue('--inspect-brk') && process._eval == null) {
if (!resolvedArgv) {
// We enter the repl if we're not given a filename argument.
if (process.argv[1]) {
try {
resolvedArgv = Module._resolveFilename(process.argv[1], null, false);
} catch {
// We only expect this codepath to be reached in the case of a
// preloaded module (it will fail earlier with the main entry)
assert(ArrayIsArray(getOptionValue('--require')));
}
} else {
resolvedArgv = 'repl';
}
}
// Set breakpoint on module start
if (resolvedArgv && !hasPausedEntry && filename === resolvedArgv) {
hasPausedEntry = true;
inspectorWrapper = internalBinding('inspector').callAndPauseOnStart;
}
}
const dirname = path.dirname(filename);
const require = makeRequireFunction(this, redirects);
let result;
const exports = this.exports;
const thisValue = exports;
const module = this;
if (requireDepth === 0) statCache = new SafeMap();
if (inspectorWrapper) {
result = inspectorWrapper(compiledWrapper, thisValue, exports,
require, module, filename, dirname);
} else {
result = ReflectApply(compiledWrapper, thisValue,
[exports, require, module, filename, dirname]);
}
hasLoadedAnyUserCJSModule = true;
if (requireDepth === 0) statCache = null;
return result;
};
首先,它检查是否存在安全策略对象 policy.manifest。如果存在,表示有安全策略限制需要处理
将函数将模块文件名转换为URL格式,redirects是一个URL映射表,用于处理模块依赖关系,manifest则是一个安全策略对象,用于检测模块的完整性和安全性,然后调用wrapSafe
function wrapSafe(filename, content, cjsModuleInstance) {
if (patched) {
const wrapper = Module.wrap(content);
//支持esm的模块
//import { a } from './a.js'; 类似于eval
//import()函数模式动态加载模块
const script = new Script(wrapper, {
filename,
lineOffset: 0,
importModuleDynamically: async (specifier, _, importAssertions) => {
const loader = asyncESM.esmLoader;
return loader.import(specifier, normalizeReferrerURL(filename),
importAssertions);
},
});
// Cache the source map for the module if present.
if (script.sourceMapURL) {
maybeCacheSourceMap(filename, content, this, false, undefined, script.sourceMapURL);
}
//返回一个可执行的全局上下文函数
return script.runInThisContext({
displayErrors: true,
});
}
wrapSafe调用了wrap方法
let wrap = function(script) {
return Module.wrapper[0] + script + Module.wrapper[1];
};
//(function (exports, require, module, __filename, __dirname) {
//const xm = 18
//\n});
const wrapper = [
'(function (exports, require, module, __filename, __dirname) { ',
'\n})',
];
wrap方法 发现就是把我们的代码包装到一个函数里面
//(function (exports, require, module, __filename, __dirname) {
//const xm = 18 我们的代码
//\n});
然后继续看wrapSafe函数,发现把返回的字符串也就是包装之后的代码放入nodejs虚拟机里面Script,看有没有动态import去加载,最后返回执行后的结果,然后继续看_compile,获取到wrapSafe返回的函数,通过Reflect.apply调用因为要填充五个参数[exports, require, module, filename, dirname],最后返回执行完的结果。
全局变量
如何在nodejs定义全局变量呢?
在nodejs中使用global定义全局变量,定义的变量,可以在引入的文件中也可以访问到该变量,例如a.js global.xxx = ‘xxx’ require(‘xxx.js’) xxx.js 也可以访问到该变量,在浏览器中我们定义的全局变量都在window,nodejs在global,不同的环境还需要判断,于是在ECMAScript 2020 出现了一个globalThis全局变量,在nodejs环境会自动切换成global ,浏览器环境自动切换window非常方便
关于其他全局API
由于nodejs中没有DOM和BOM,除了这些API,其他的ECMAscriptAPI基本都能用
例如
setTimeout setInterval Promise Math console Date fetch(node v18) 等...
这些API 都是可以正常用的
nodejs内置全局API
__dirname
它表示当前模块的所在目录的绝对路径
__filename
它表示当前模块文件的绝对路径,包括文件名和文件扩展名
require module
引入模块和模块导出上一章已经详细讲过了
process //处理进程的
-
process.argv: 这是一个包含命令行参数的数组。第一个元素是Node.js的执行路径,第二个元素是当前执行的JavaScript文件的路径,之后的元素是传递给脚本的命令行参数。 -
process.env: 这是一个包含当前环境变量的对象。您可以通过process.env访问并操作环境变量。 -
process.cwd(): 这个方法返回当前工作目录的路径。 -
process.on(event, listener): 用于注册事件监听器。您可以使用process.on监听诸如exit、uncaughtException等事件,并在事件发生时执行相应的回调函数。 -
process.exit([code]): 用于退出当前的Node.js进程。您可以提供一个可选的退出码作为参数。 -
process.pid: 这个属性返回当前进程的PID(进程ID)。
这些只是process对象的一些常用属性和方法,还有其他许多属性和方法可用于监控进程、设置信号处理、发送IPC消息等。
需要注意的是,process对象是一个全局对象,可以在任何模块中直接访问,无需导入或定义。
Buffer//一般是处理二进制数据或者媒体数据
- 创建 Buffer 实例:
-
Buffer.alloc(size[, fill[, encoding]]): 创建一个指定大小的新的Buffer实例,初始内容为零。fill参数可用于填充缓冲区,encoding参数指定填充的字符编码。
-
Buffer.from(array): 创建一个包含给定数组的Buffer实例。
-
Buffer.from(string[, encoding]): 创建一个包含给定字符串的Buffer实例。
2.读取和写入数据:
- buffer[index]: 通过索引读取或写入Buffer实例中的特定字节。
- buffer.length: 获取Buffer实例的字节长度。
- buffer.toString([encoding[, start[, end]]]): 将Buffer实例转换为字符串。
- 转换数据:
- buffer.toJSON(): 将Buffer实例转换为JSON对象。
- buffer.slice([start[, end]]): 返回一个新的Buffer实例,其中包含原始Buffer实例的部分内容。
- 其他方法:
-
Buffer.isBuffer(obj): 检查一个对象是否是Buffer实例。
-
Buffer.concat(list[, totalLength]): 将一组Buffer实例或字节数组连接起来形成一个新的Buffer实例。
请注意,从Node.js 6.0版本开始,Buffer构造函数的使用已被弃用,推荐使用Buffer.alloc()、Buffer.from()等方法来创建
Buffer实例。
Buffer类在处理文件、网络通信、加密和解密等操作中非常有用,尤其是在需要处理二进制数据时
CSR SSR SEO
概述
在上一章的时候我们说过在node环境中无法操作DOM 和 BOM,但是如果非要操作DOM 和 BOM 也是可以的我们需要使用第三方库帮助我们jsdom
npm i jsdom
jsdom 是一个模拟浏览器环境的库,可以在 Node.js 中使用 DOM API
简单案例
const fs = require('node:fs')
const { JSDOM } = require('jsdom')
const dom = new JSDOM(`<!DOCTYPE html><div id='app'></div>`)
const document = dom.window.document
const window = dom.window
fetch('https://api.thecatapi.com/v1/images/search?limit=10&page=1').then(res => res.json()).then(data => {
const app = document.getElementById('app')
data.forEach(item=>{
const img = document.createElement('img')
img.src = item.url
img.style.width = '200px'
img.style.height = '200px'
app.appendChild(img)
})
// fs.writeFileSync:写入文件的一个操作。第一个参数是文件路径。第二个是要
//dom.serialize():序列化成一个拼装完成的一个字符串
fs.writeFileSync('./index.html', dom.serialize())
})
运行完该脚本会在执行目录下生成html文件里面内容都是渲染好的
效果:

CSR SSR
我们上面的操作属于SSR (Server-Side Rendering)服务端渲染请求数据和拼装都在服务端完成,而我们的Vue,react 等框架这里不谈(nuxtjs,nextjs),是在客户端完成渲染拼接的属于CSR(Client-Side Rendering)客户端渲染
CSR 和 SSR 区别
- 页面加载方式:
- CSR:在 CSR 中,服务器返回一个初始的 HTML 页面,然后浏览器下载并执行 JavaScript 文件,JavaScript 负责动态生成并更新页面内容。这意味着初始页面加载时,内容较少,页面结构和样式可能存在一定的延迟。
- SSR:在 SSR 中,服务器在返回给浏览器之前,会预先在服务器端生成完整的 HTML 页面,包含了初始的页面内容。浏览器接收到的是已经渲染好的 HTML 页面,因此初始加载的速度较快。
- 内容生成和渲染:
- CSR:在 CSR 中,页面的内容生成和渲染是由客户端的 JavaScript 脚本负责的。当数据变化时,JavaScript 会重新生成并更新 DOM,从而实现内容的动态变化。这种方式使得前端开发更加灵活,可以创建复杂的交互和动画效果。
- SSR:在 SSR 中,服务器在渲染页面时会执行应用程序的代码,并生成最终的 HTML 页面。这意味着页面的初始内容是由服务器生成的,对于一些静态或少变的内容,可以提供更好的首次加载性能。
- 用户交互和体验:
- CSR:在 CSR 中,一旦初始页面加载完成,后续的用户交互通常是通过 AJAX 或 WebSocket 与服务器进行数据交互,然后通过 JavaScript 更新页面内容。这种方式可以提供更快的页面切换和响应速度,但对于搜索引擎爬虫和 SEO(搜索引擎优化)来说,可能需要一些额外的处理。
- SSR:在 SSR 中,由于页面的初始内容是由服务器生成的,因此用户交互可以直接在服务器上执行,然后服务器返回更新后的页面。这样可以提供更好的首次加载性能和对搜索引擎友好的内容。
SEO
SEO (Search Engine Optimization,搜索引擎优化)
CSR应用对SEO并不是很友好
因为在首次加载的时候获取HTML 信息较少 搜索引擎爬虫可能无法获取完整的页面内容

而SSR就不一样了 由于 SSR 在服务器端预先生成完整的 HTML 页面,搜索引擎爬虫可以直接获取到完整的页面内容。这有助于搜索引擎正确理解和评估页面的内容
说了这么多哪些网站适合做CSR 哪些适合做SSR
CSR 应用例如 ToB 后台管理系统 大屏可视化 都可以采用CSR渲染不需要很高的SEO支持
SSR 应用例如 内容密集型应用大部分是ToC 新闻网站 ,博客网站,电子商务,门户网站需要更高的SEO支持
path
path模块在不同的操作系统是有差异的(windows | posix)
windows大家肯定熟悉,posix可能大家没听说过
posix(Portable Operating System Interface of UNIX)
posix表示可移植操作系统接口,也就是定义了一套标准,遵守这套标准的操作系统有(unix,like unix,linux,macOs,windows wsl),为什么要定义这套标准,比如在Linux系统启动一个进程需要调用fork函数,在windows启动一个进程需要调用creatprocess函数,这样就会有问题,比如我在linux写好了代码,需要移植到windows发现函数不统一,posix标准的出现就是为了解决这个问题。
Windows 并没有完全遵循 POSIX 标准。Windows 在设计上采用了不同于 POSIX 的路径表示方法。
在 Windows 系统中,路径使用反斜杠(\)作为路径分隔符。这与 POSIX 系统使用的正斜杠(/)是不同的。这是 Windows 系统的历史原因所致,早期的 Windows 操作系统采用了不同的设计选择。
windows posix 差异
path.basename() 方法返回的是给定路径中的最后一部分
在posix处理windows路径
windows兼容正反斜杠,如果posix系统环境下是只能用正斜杠/
path.basename('C:\temp\myfile.html');//
// 返回: 'C:\temp\myfile.html'
结果返回的并不对 应该返回 myfile.html
在posix环境下应该这样写
const path = require('node:path')
console.log(path.basename('C:/temp/myfile.html')); //返回myfile.html
如果要在posix系统处理windows的路径需要调用对应操作系统的方法应该修改为
path.win32.basename('C:\temp\myfile.html');//返回路径的最后一部分
如果在windows系统环境下,可以这样模拟posix去处理路径
path.posix.basename('C:/temp/myfile.html')
返回 myfile.html
path.dirname
这个API和basename正好互补
path.dirname('/aaaa/bbbb/cccc/index.html')
dirname API 返回 /aaaa/bbbb/cccc 除了最后一个路径的其他路径。
basename API 返回 最后一个路径 index.html
path.extname
这个API 用来返回扩展名例如/bbb/ccc/file.txt 返回就是.txt
path.extname('/aaaa/bbbb/cccc/index.html.ccc.ddd.aaa')
//.aaa
如果有多个 . 返回最后一个 如果没有扩展名返回空
path.join
这个API 主要是用来拼接路径的
path.join('/foo','/cxk','/ikun')
// /foo/cxk/ikun
可以支持 … ./ …/操作符
path.join('/foo','/cxk','/ikun','../')
// /foo/cxk/
path.resolve
用于将相对路径解析并且返回绝对路径
如果传入了多个绝对路径 它将返回最右边的绝对路径
path.resolve('/aaa','/bbb','/ccc')
// /ccc
传入绝对路径 + 相对路径
path.resolve(__dirname,'./index.js')
// /User/sz/DeskTop/node/index.js
如果只传入相对路径
path.resolve('./index.js')
// 返回工作目录 + index.js
path.parse ||path.format
path.format 和 path.parse 正好互补
parse
用于解析文件路径。它接受一个路径字符串作为输入,并返回一个包含路径各个组成部分的对象
path.parse('/home/user/dir/file.txt')
{
root: '/',
dir: '/home/user/dir',
base: 'file.txt',
ext: '.txt',
name: 'file'
}
root:路径的根目录,即/。dir:文件所在的目录,即/home/user/documents。base:文件名,即file.txt。ext:文件扩展名,即.txt。name:文件名去除扩展名,即file。
format 正好相反 在把对象转回字符串
path.format({
root: '/',
dir: '/home/user/documents',
base: 'file.txt',
ext: '.txt',
name: 'file'
})
// /home/user/dir/file.txt
path.sep
console.log(path.sep)
//如果是windows系统返回的是\(反斜杠)
//如果是posix系统是/ (正斜杠)
os
Nodejs os 模块可以跟操作系统进行交互
var os = require("node:os")
| 序号 | API | 作用 |
|---|---|---|
| 1 | os.type() | 它在 Linux 上返回 'Linux',在 macOS 上返回 'Darwin',在 Windows 上返回 'Windows_NT' |
| 2 | os.platform() | 返回标识为其编译 Node.js 二进制文件的操作系统平台的字符串。 该值在编译时设置。 可能的值为 'aix'、'darwin'、'freebsd'、'linux'、'openbsd'、'sunos'、以及 'win32' |
| 3 | os.release() | 返回操作系统的版本例如10.xxxx win10 |
| 4 | os.homedir() | 返回用户目录 例如c:\user\sz 原理就是 windows echo %USERPROFILE% posix $HOME |
| 5 | os.arch() | 返回cpu的架构 可能的值为 'arm'、'arm64'、'ia32'、'mips'、'mipsel'、'ppc'、'ppc64'、's390'、's390x'、以及 'x64' |
获取CPU的线程以及详细信息
cpu利用率计算可能会用到
const os = require('node:os')
os.cpus()
[
{
model: 'Apple M1',
speed: 24,
times: {
user: 149100860,
nice: 0,
sys: 184101060,
idle: 485590180,
irq: 0
}
},
{
model: 'Apple M1',
speed: 24,
times: {
user: 148111350,
nice: 0,
sys: 174919780,
idle: 496618830,
irq: 0
}
},
{
model: 'Apple M1',
speed: 24,
times: {
user: 145844980,
nice: 0,
sys: 163433130,
idle: 510972110,
irq: 0
}
},
{
model: 'Apple M1',
speed: 24,
times: {
user: 132358920,
nice: 0,
sys: 160138870,
idle: 528535610,
irq: 0
}
},
{
model: 'Apple M1',
speed: 24,
times: { user: 45987530, nice: 0, sys: 27702790, idle: 749207900, irq: 0 }
},
{
model: 'Apple M1',
speed: 24,
times: { user: 36318850, nice: 0, sys: 21949260, idle: 764798200, irq: 0 }
},
{
model: 'Apple M1',
speed: 24,
times: { user: 29863850, nice: 0, sys: 19386590, idle: 773960930, irq: 0 }
},
{
model: 'Apple M1',
speed: 24,
times: { user: 23659290, nice: 0, sys: 18179220, idle: 781475860, irq: 0 }
}
]
model: 表示CPU的型号信息,其中 “Intel® Core™ i7 CPU 860 @ 2.80GHz” 是一种具体的型号描述。speed: 表示CPU的时钟速度,以MHz或GHz为单位。在这种情况下,速度为 2926 MHz 或 2.926 GHz。times: 是一个包含CPU使用时间的对象,其中包含以下属性:user: 表示CPU被用户程序使用的时间(以毫秒为单位)。nice: 表示CPU被优先级较低的用户程序使用的时间(以毫秒为单位)。sys: 表示CPU被系统内核使用的时间(以毫秒为单位)。idle: 表示CPU处于空闲状态的时间(以毫秒为单位)。irq: 表示CPU被硬件中断处理程序使用的时间(以毫秒为单位)。
获取网络信息
const os = require('node:os')
os.networkInterfaces()
{
lo: [
{
address: '127.0.0.1',
netmask: '255.0.0.0',
family: 'IPv4',
mac: '00:00:00:00:00:00',
internal: true,
cidr: '127.0.0.1/8'
},
{
address: '::1',
netmask: 'ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff',
family: 'IPv6',
mac: '00:00:00:00:00:00',
scopeid: 0,
internal: true,
cidr: '::1/128'
}
],
eth0: [
{
address: '192.168.1.108',
netmask: '255.255.255.0',
family: 'IPv4',
mac: '01:02:03:0a:0b:0c',
internal: false,
cidr: '192.168.1.108/24'
},
{
address: 'fe80::a00:27ff:fe4e:66a1',
netmask: 'ffff:ffff:ffff:ffff::',
family: 'IPv6',
mac: '01:02:03:0a:0b:0c',
scopeid: 1,
internal: false,
cidr: 'fe80::a00:27ff:fe4e:66a1/64'
}
]
}
address: 表示本地回环接口的IP地址,这里是 ‘127.0.0.1’。netmask: 表示本地回环接口的子网掩码,这里是 ‘255.0.0.0’。family: 表示地址族(address family),这里是 ‘IPv4’,表示IPv4地址。mac: 表示本地回环接口的MAC地址,这里是 ‘00:00:00:00:00:00’。请注意,本地回环接口通常不涉及硬件,因此MAC地址通常为全零。internal: 表示本地回环接口是否是内部接口,这里是 true,表示它是一个内部接口,访问内网。如果是false表示可以访问外网。cidr: 表示本地回环接口的CIDR表示法,即网络地址和子网掩码的组合,这里是 ‘127.0.0.1/8’,表示整个 127.0.0.0 网络。
案例
知道这些信息有什么用?
非常经典的例子 webpack vite 大家应该都用过 他们有一个配置项可以打开浏览器 open:true 我们来简单复刻一下
const { exec } = require('child_process');
const os = require('os');
function openBrowser(url) {
if (os.platform() === 'darwin') { // macOS
exec(`open ${url}`); //执行shell脚本
} else if (os.platform() === 'win32') { // Windows
exec(`start ${url}`); //执行shell脚本
} else { // Linux, Unix-like
exec(`xdg-open ${url}`); //执行shell脚本
}
}
// Example usage
openBrowser('https://www.juejin.cn');
process
process 是Nodejs操作当前进程和控制当前进程的API,并且是挂载到globalThis下面的全局API
API介绍
1.process.arch
返回操作系统 CPU 架构 跟我们之前讲的os.arch 一样
'arm'、'arm64'、'ia32'、'mips'、'mipsel'、'ppc'、'ppc64'、's390'、's390x'、以及 'x64'
2.process.cwd()
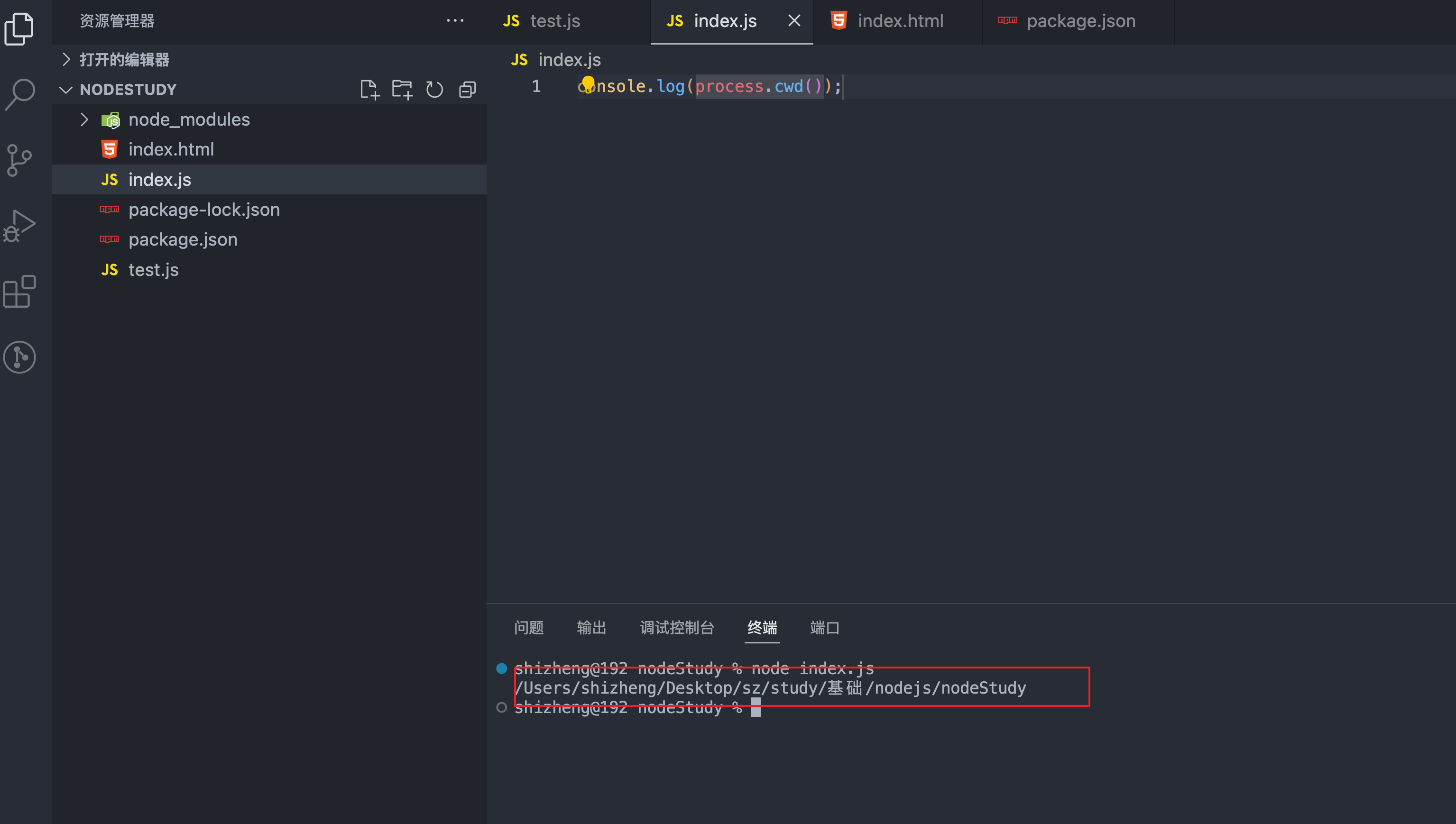
返回当前的工作目录 例如在 F:\project\node> 执行的脚本就返回这个目录 也可以和path拼接代替__dirname使用。
区别在于:__dirname在esm模式下用不了,可以用cwd()去代替
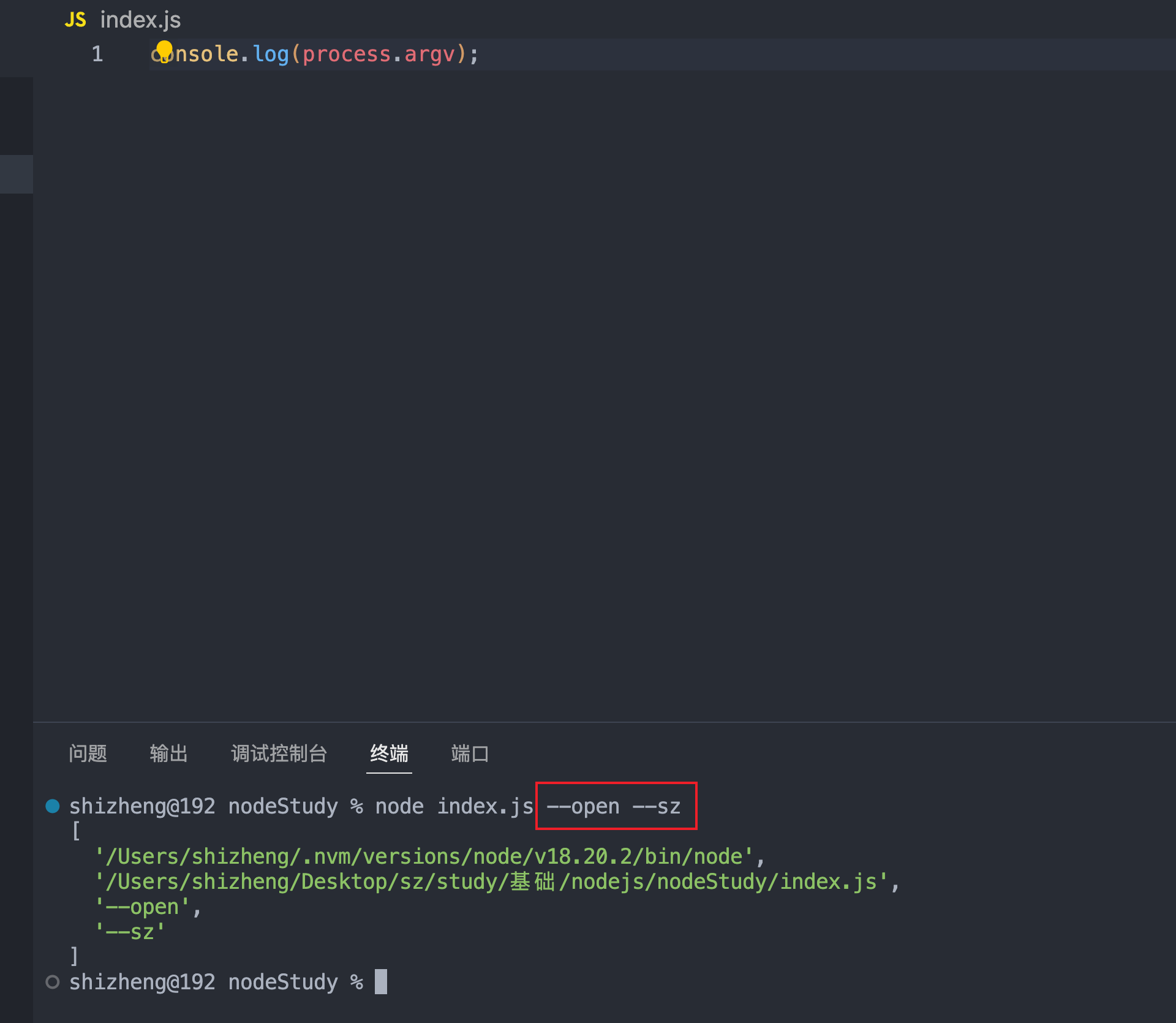
3.process.argv
获取执行进程后面的参数 返回是一个数组 后面我们讲到命令行交互工具的时候会很有用,各种cli脚手架也是使用这种方式接受配置参数例如webpack
 ### 4.process.memoryUsage
### 4.process.memoryUsage
用于获取当前进程的内存使用情况。该方法返回一个对象,其中包含了各种内存使用指标,如 rss(Resident Set Size,常驻集大小)、heapTotal(堆区总大小)、heapUsed(已用堆大小)和 external(外部内存使用量)等
console.log(process.memoryUsage());
打印结果:
{
rss: 36667392, //常驻集大小 =》物理内存的存量
heapTotal: 4816896,//堆区总大小 =》v8给我们分配的堆内存堆总大小包括未使用的内存
heapUsed: 3496472,//已用堆大小 =》已经使用的内存
external: 12328, //外部内存使用量 =》比如c c++使用的
arrayBuffers: 11182
}
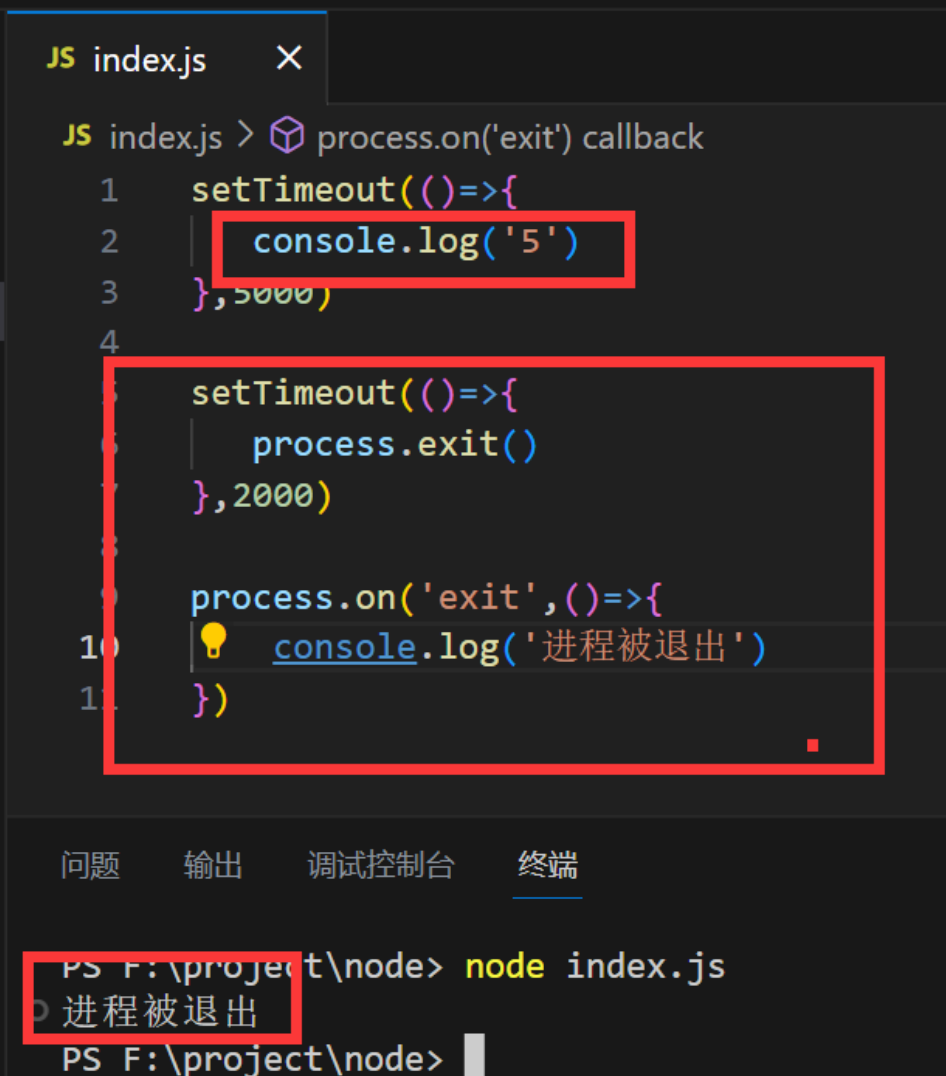
5.process.exit()
调用 process.exit() 将强制进程尽快退出,即使仍有未完全完成的异步操作挂起
下面例子5不会被打印出来 因为在2秒钟的时候就被退出了
6.process.kill
与exit类似,kill用来杀死一个进程,接受一个参数进程id可以通过process.pid 获取
process.kill(process.pid)
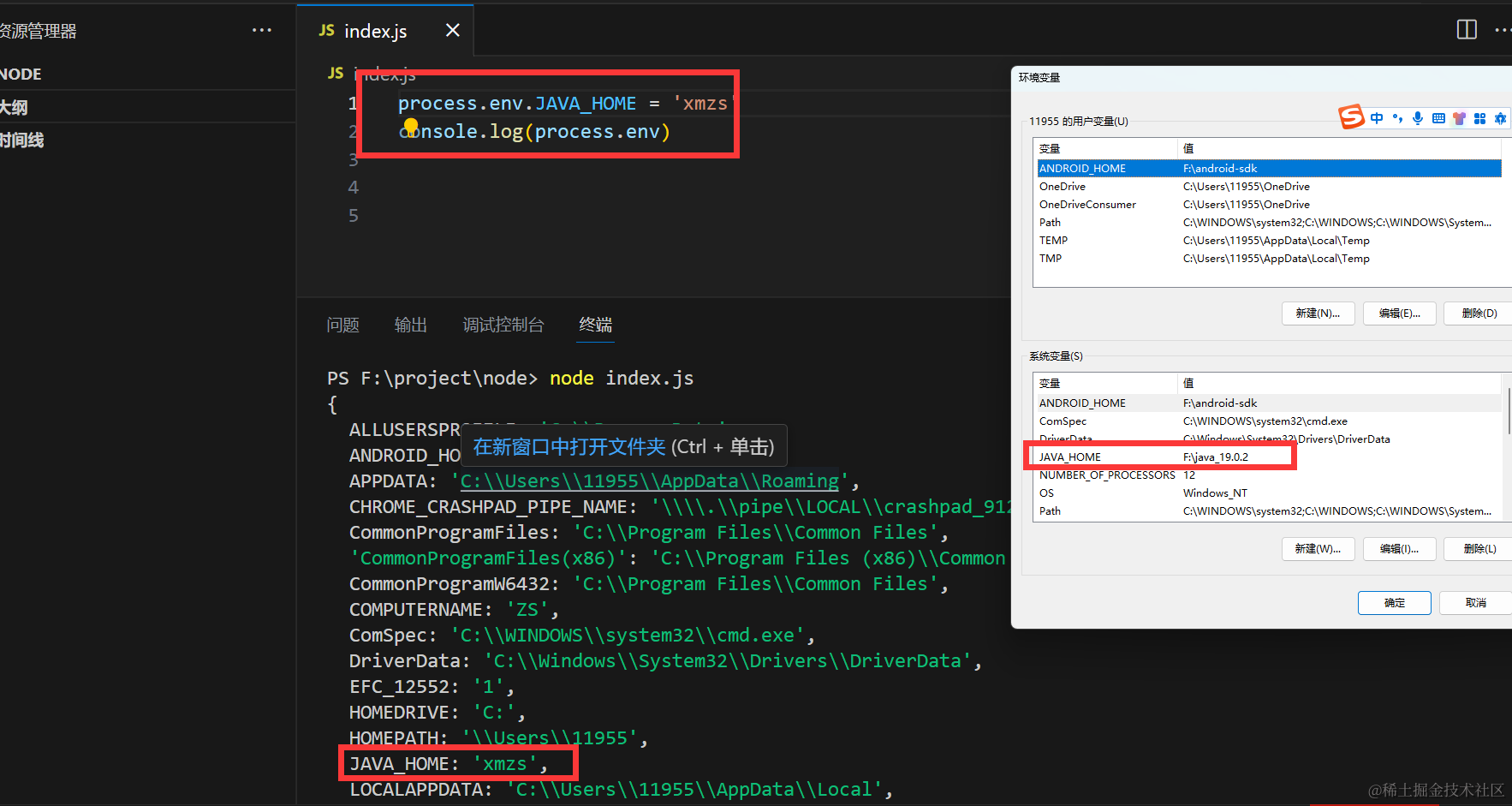
7.process.env
用于读取操作系统所有的环境变量,也可以修改和查询环境变量。
修改 注意修改并不会真正影响操作系统的变量,而是只在当前线程生效,线程结束便释放。
环境变量场景
区分开发环境 和 生产环境
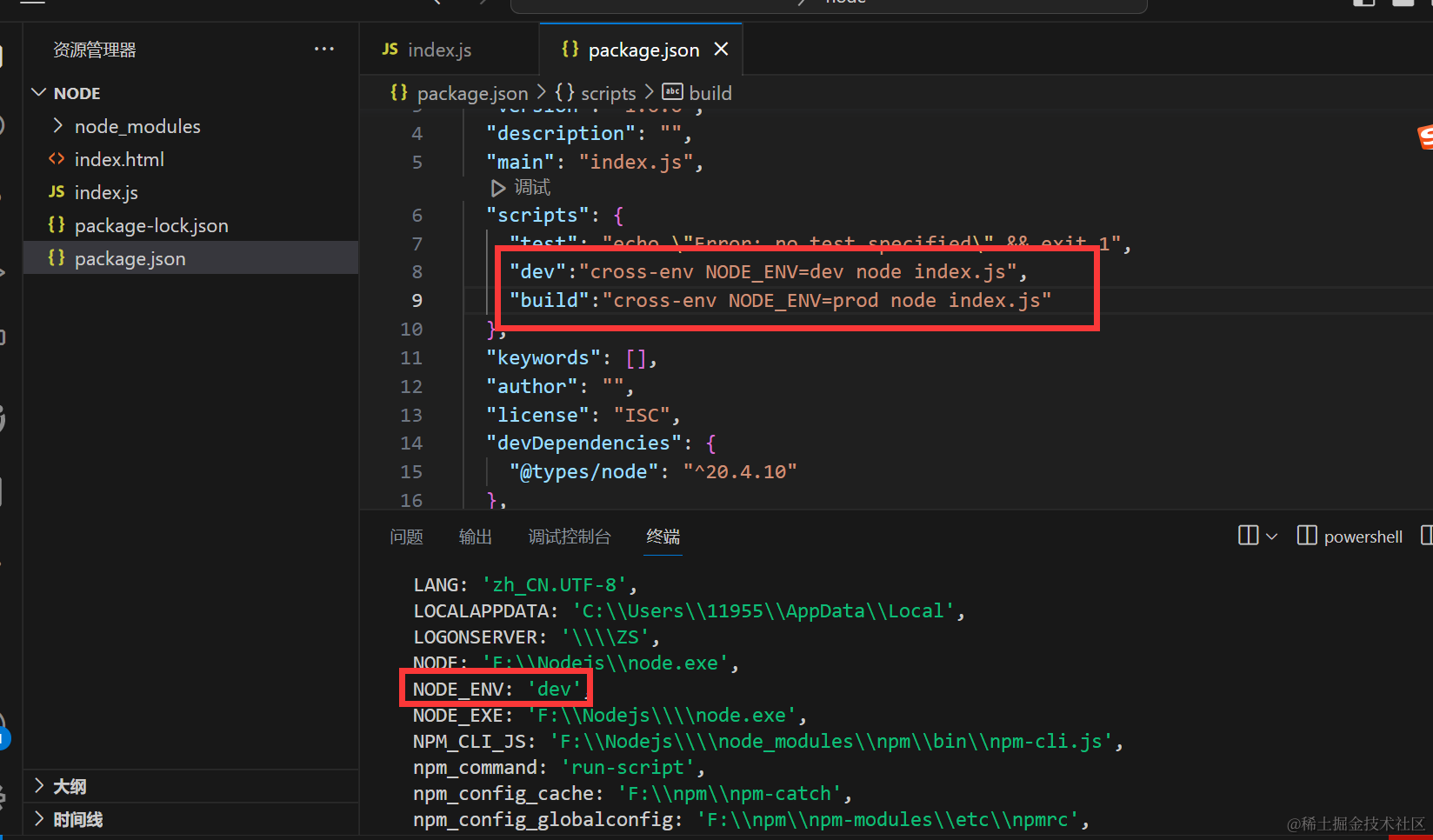
npm install cross-env
这个库是干什么的 cross-env 是 跨平台设置和使用环境变量 不论是在Windows系统还是POSIX系统。同时,它提供了一个设置环境变量的脚本,使得您可以在脚本中以unix方式设置环境变量,然后在Windows上也能兼容运行
usage
cross-env NODE_ENV=dev
区分开发和生产环境
console.log(process.env.NODE_ENV=='dev'?'开发环境':'生产环境');
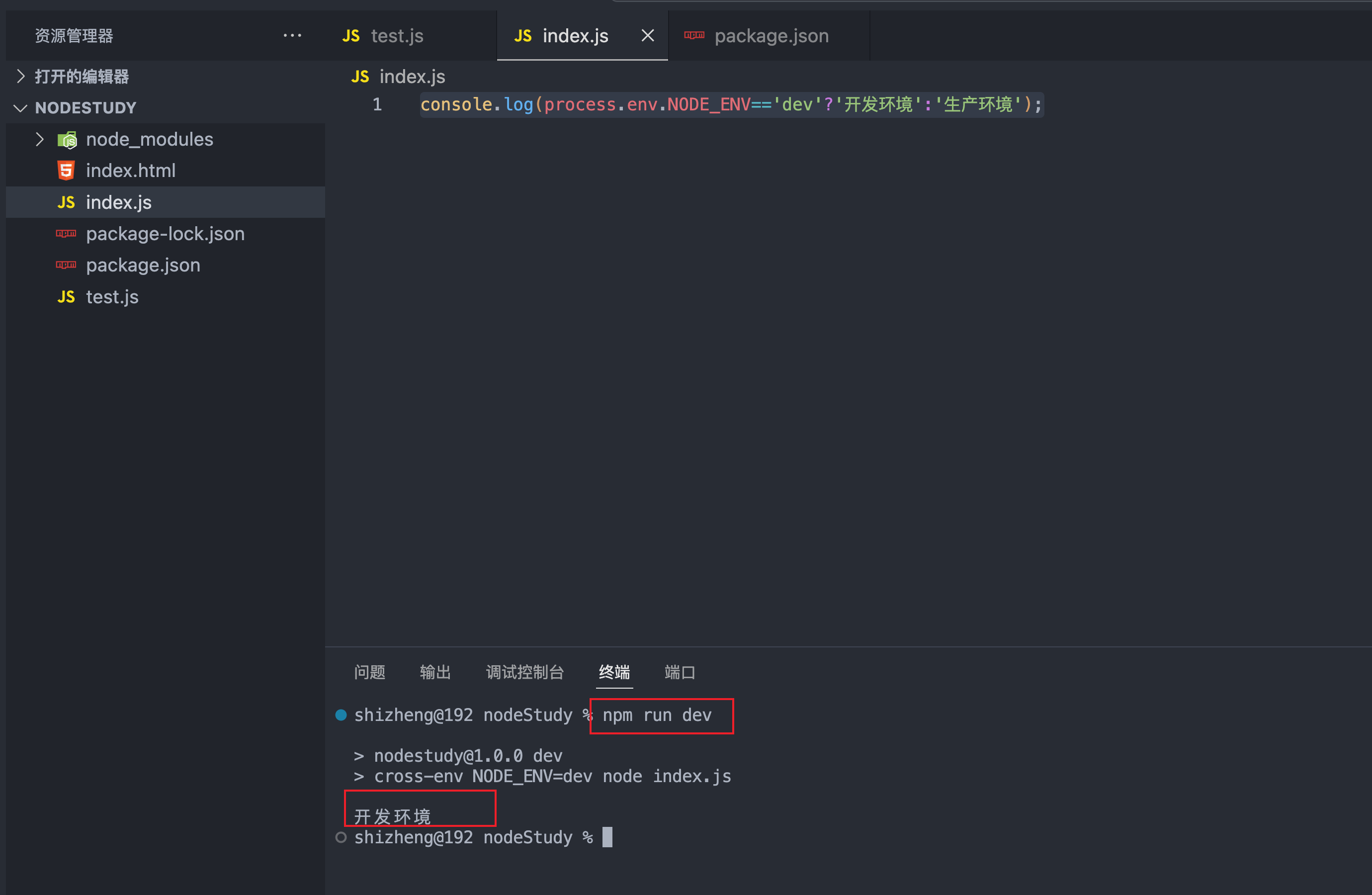
npm run build打印出来就生产环境
他的原理就是这个东西是跨平台的,如果是windows 就调用SET 如果是posix 就调用export 设置环境变量
set NODE_ENV=production #windows
export NODE_ENV=production #posix
child_process
子进程是Nodejs核心API,如果你会shell命令,他会有非常大的帮助,或者你喜欢编写前端工程化工具之类的,他也有很大的用处,以及处理CPU密集型应用。
创建子进程
Nodejs创建子进程共有7个API Sync同步API 不加是异步API
- spawn 执行命令
- exec 执行命令
- execFile 执行可执行文件
- fork 创建node子进程
execSync执行命令 同步执行execFileSync执行可执行文件 同步执行spawnSync执行命令 同步执行
exec
异步的方法 回调函数 返回buffer 可以帮助我们执行shell命令 或者跟软件交互
child_process.exec(command, [options], callback)
获取nodejs 版本号
const {exec} = require('child_process')
exec('node -v',(err,stdout,stderr)=>{
if(err){
return err
}
console.log(stdout.toString()) //node版本号
})
options 配置项
cwd <string> 子进程的当前工作目录。
env <Object> 环境变量键值对。
encoding <string> 默认为 'utf8'。
shell <string> 用于执行命令的 shell。 在 UNIX 上默认为 '/bin/sh',在 Windows 上默认为 process.env.ComSpec。 详见 Shell Requirements 与 Default Windows Shell。
timeout <number> 默认为 0。
maxBuffer <number> stdout 或 stderr 允许的最大字节数。 默认为 200*1024。 如果超过限制,则子进程会被终止。 查看警告: maxBuffer and Unicode。
killSignal <string> | <integer> 默认为 'SIGTERM'。
uid <number> 设置该进程的用户标识。(详见 setuid(2))
gid <number> 设置该进程的组标识。(详见 setgid(2))
execSync
一般同步的方法用的多一点
获取node版本号 如果要执行单次shell命令execSync方便一些 options同上
const nodeVersion = execSync('node -v')//返回的是一个buffer
console.log(nodeVersion.toString("utf-8"))
execSync用来执行一些较小的shell命令,想要立马拿到结果的shell,就比较适合。
exec字节上限200kb,超出200kb就会报错
打开谷歌浏览器 使用exec可以打开一些软件例如 wx 谷歌 qq音乐等 以下会打开百度并且进入无痕模式
execSync("start chrome http://www.baidu.com --incognito")//window系统
execSync('open -a "Google Chrome" http://www.baidu.com')//macos系统
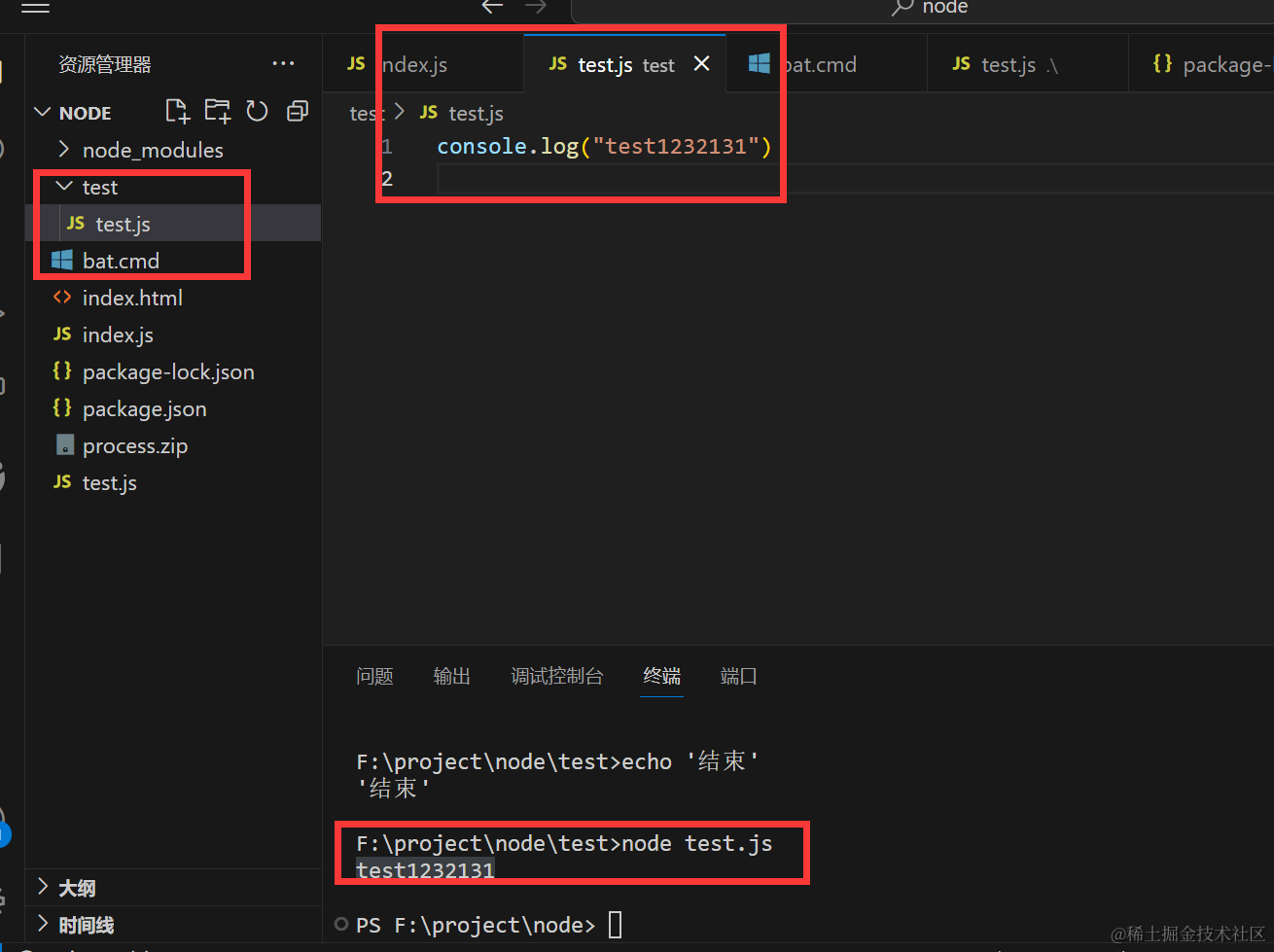
execFile
execFile 适合执行可执行文件,例如执行一个node脚本,或者shell文件,windows可以编写cmd脚本,posix,可以编写sh脚本
简单示例
bat.cmd
创建一个文件夹mkdir 进入目录 写入一个文件test.js 最后执行
echo '开始'
mkdir test
cd ./test
echo console.log("test1232131") >test.js
echo '结束'
node test.js
使用execFile 执行这个
execFile(path.resolve(process.cwd(),'./bat.cmd'),null,(err,stdout)=>{
console.log(stdout.toString())
})
spawn
spawn 用于执行一些实时获取的信息因为spawn返回的是流边执行边返回,exec是返回一个完整的buffer,buffer的大小是200k,如果超出会报错,而spawn是无上限的。
spawn在执行完成后会抛出close事件监听,并返回状态码,通过状态码可以知道子进程是否顺利执行。exec只能通过返回的buffer去识别完成状态,识别起来较为麻烦
// 命令 参数 options配置
const {stdout} = spawn('netstat',['-an'],{})
//返回的数据用data事件接受
stdout.on('data',(steram)=>{
console.log(steram.toString())
})
我的写法:
const { execSync, spawn } = require('child_process');
const child = spawn('netstat', ['-an']);
child.stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
});
child.stderr.on('data', (data) => {
console.error(`stderr: ${data}`);
});
child.on('close', (code) => {
console.log(`子进程退出,退出码 ${code}`);
});
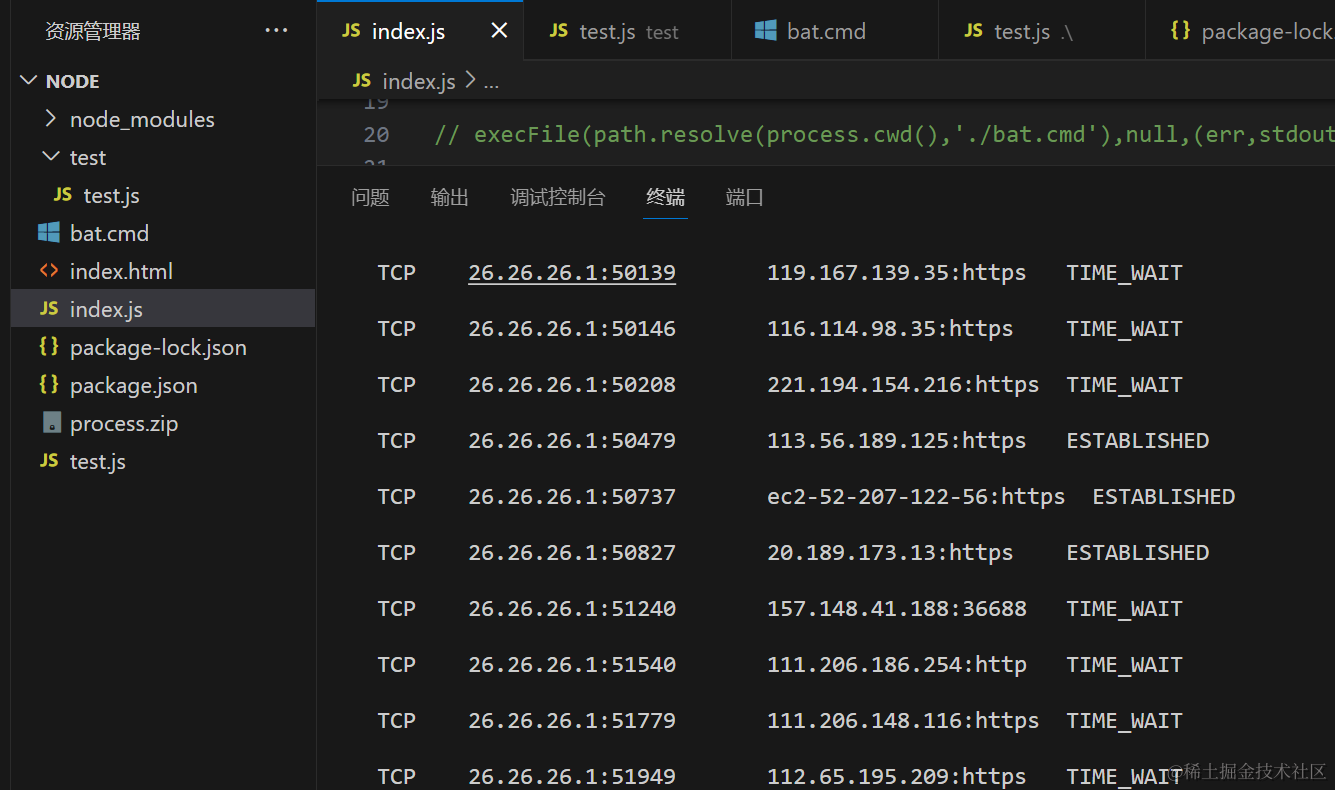
底层实现顺序:
exec -> execFile -> spawn
exec是底层通过execFile实现 execFile底层通过spawn实现
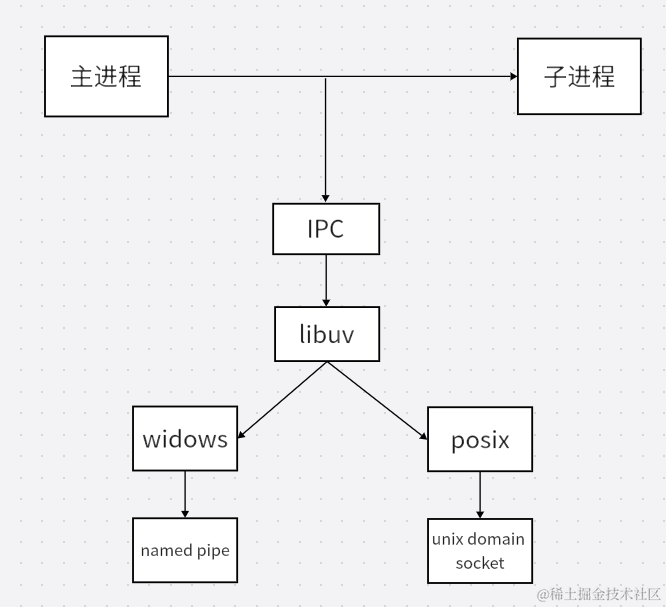
fork
只能接受js模块
场景适合大量的计算,或者容易阻塞主进程操作的一些代码,适合开发fork。
可以将阻塞主进程代码塞到子进程中执行,执行完之后再让子进程把值给吐出来。
index.js
const {fork} = require('child_process')
const testProcess = fork('./test.js')
testProcess.send('我是主进程')
testProcess.on("message",(data)=>{
console.log('我是主进程接受消息111:',data)
})
test.js
process.on('message',(data)=>{
console.log('子进程接受消息:',data)
})
process.send('我是子进程')
send 发送信息 ,message接收消息,可以相互发送接收。
fork底层使用的是IPC通道进行通讯的
ffmpeg
FFmpeg 是一个开源的跨平台多媒体处理工具,可以用于处理音频、视频和多媒体流。它提供了一组强大的命令行工具和库,可以进行视频转码、视频剪辑、音频提取、音视频合并、流媒体传输等操作。
FFmpeg 的主要功能和特性:
- 格式转换:FFmpeg 可以将一个媒体文件从一种格式转换为另一种格式,支持几乎所有常见的音频和视频格式,包括 MP4、AVI、MKV、MOV、FLV、MP3、AAC 等。
- 视频处理:FFmpeg 可以进行视频编码、解码、裁剪、旋转、缩放、调整帧率、添加水印等操作。你可以使用它来调整视频的分辨率、剪辑和拼接视频片段,以及对视频进行各种效果处理。
- 音频处理:FFmpeg 可以进行音频编码、解码、剪辑、混音、音量调节等操作。你可以用它来提取音频轨道、剪辑和拼接音频片段,以及对音频进行降噪、均衡器等处理。
- 流媒体传输:FFmpeg 支持将音视频流实时传输到网络上,可以用于实时流媒体服务、直播和视频会议等应用场景。
- 视频处理效率高:FFmpeg 是一个高效的工具,针对处理大型视频文件和高分辨率视频进行了优化,可以在保持良好质量的同时提供较快的处理速度。
- 跨平台支持:FFmpeg 可以在多个操作系统上运行,包括 Windows、MacOS、Linux 等,同时支持多种硬件加速技术,如 NVIDIA CUDA 和 Intel Quick Sync Video。
安装
http://ffmpeg.p2hp.com/download.html
选择对应的操作系统进行下载就可以了,下载完成配置一下环境变量就ok了
输入 ffmpage -version 不报错即可
子进程配合ffmpeg
1. 简单的demo 视频转gif -i 表示输入的意思
const {execSync} = require('child_process')
execSync(`ffmpeg -i test.mp4 test.gif`,{stdio:'inherit'})
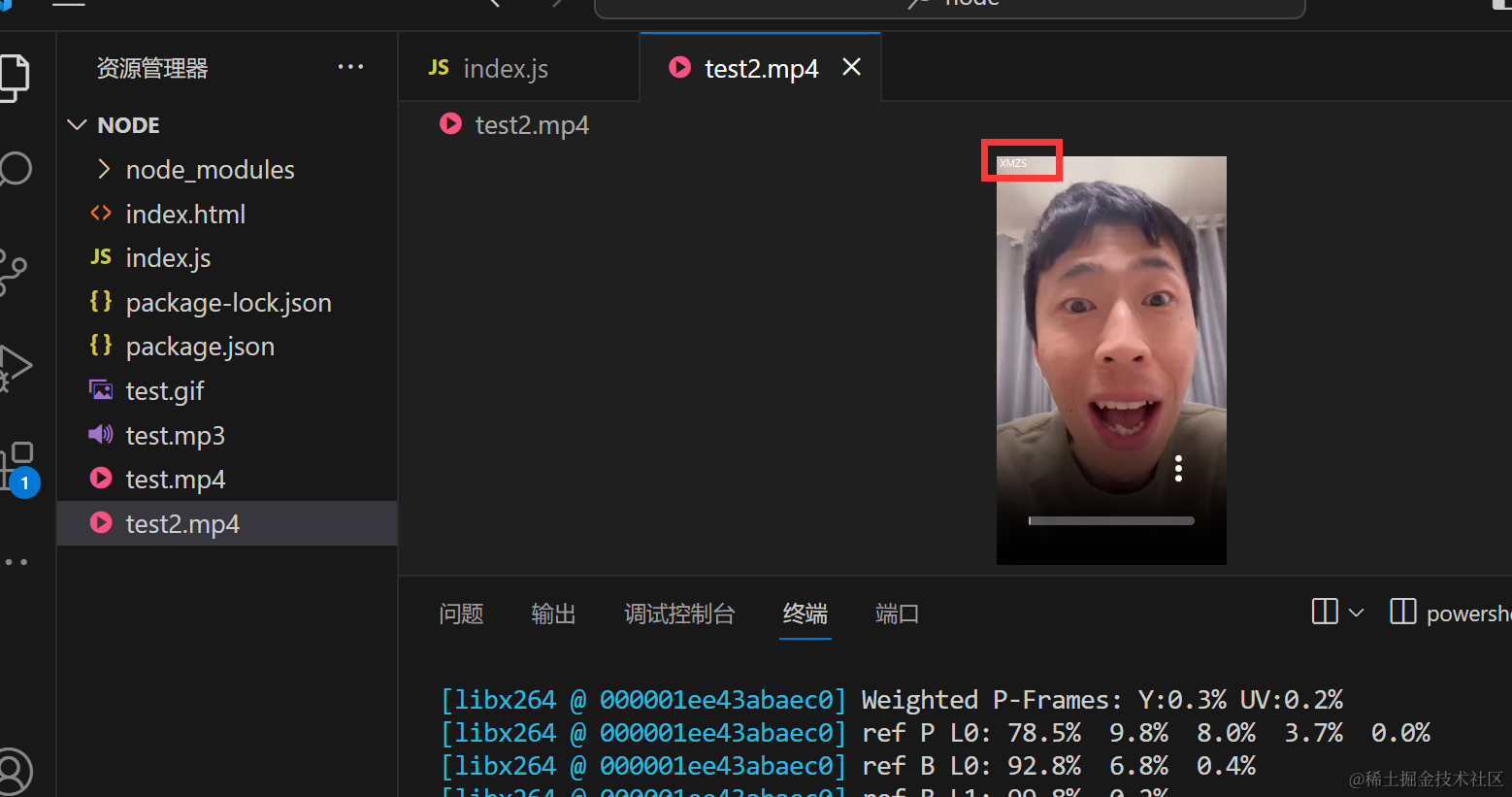
2.添加水印
-vf 就是video filter
drawtext 添加文字 fontsize 大小 xy垂直水平方向 fontcolor 颜色 text 水印文案 全部小写
const {execSync} = require('child_process')
execSync(`ffmpeg -i test.mp4 -vf drawtext=text="XMZS":fontsize=30:fontcolor=white:x=10:y=10 test2.mp4`,{stdio:'inherit'})
3. 视频剪裁+控制大小
-ss 起始时间
-to 结束事件
ss写在 -i的前面可能会导致精度问题,因为视频还没解析就跳转到了相关位置,但是解析速度快
ss写在 -i后面精度没问题,但是解析速度会变慢
const {execSync} = require('child_process')
execSync(`ffmpeg -ss 10 -to 20 -i test.mp4 test3.mp4`,{stdio:'inherit'})
4.提取视频的音频
const {execSync} = require('child_process')
execSync(`ffmpeg -i test.mp4 test.mp3`,{stdio:'inherit'})
5.去掉水印
w h 宽高
xy 垂直 水平坐标
delogo使用的过滤参数删除水印
const {execSync} = require('child_process')
execSync(`ffmpeg -i test2.mp4 -vf delogo=w=120:h=30:x=10:y=10 test3.mp4`,{stdio:'inherit'})
events事件触发器
EventEmitter
Node.js 核心 API 都是采用异步事件驱动架构,简单来说就是通过有效的方法来监听事件状态的变化,并在变化的时候做出相应的动作。
fs.mkdir('/tmp/a/apple', { recursive: true }, (err) => {
if (err) throw err;
});
process.on('xxx',()=>{
})
举个例子,你去一家餐厅吃饭,这个餐厅就是一个调度中心,然后你去点饭,可以理解注册了一个事件emit,然后我们等候服务员的喊号,喊到我们的时候就去取餐,这就是监听了这个事件on
事件模型
Nodejs事件模型采用了,发布订阅设计模式
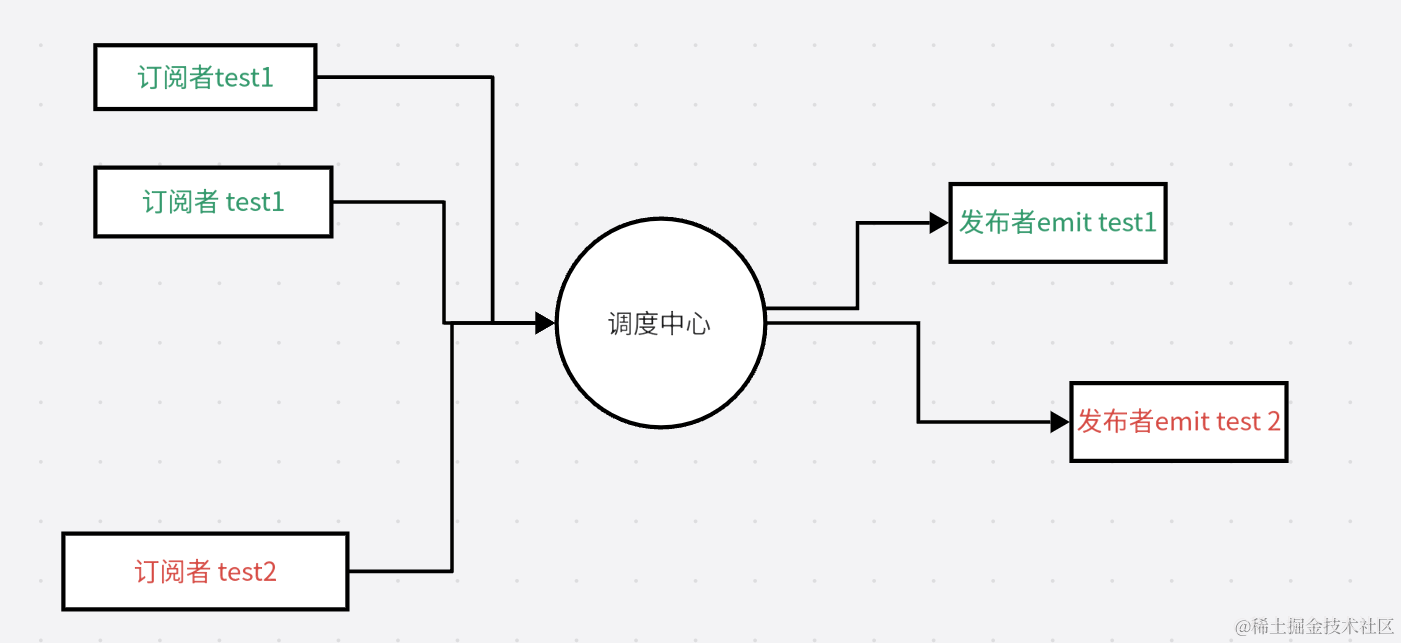
当一个发布者有新消息时,就将这个消息发布到调度中心。调度中心就会将这个消息通知给所有订阅者。这就实现了发布者和订阅者之间的解耦,发布者和订阅者不再直接依赖于彼此,他们可以独立地扩展自己
代码案例
const EventEmitter = require('events');
const event = new EventEmitter()
//监听test
event.on('test',(data)=>{
console.log(data)
})
event.emit('test','xmxmxmxmx') //派发事件
监听消息数量默认是10个
const EventEmitter = require('events');
const event = new EventEmitter()
event.on('test', (data) => {
console.log(data)
})
event.on('test', (data) => {
console.log(data)
})
event.on('test', (data) => {
console.log(data)
})
event.on('test', (data) => {
console.log(data)
})
event.on('test', (data) => {
console.log(data)
})
event.on('test', (data) => {
console.log(data)
})
event.on('test', (data) => {
console.log(data)
})
event.on('test', (data) => {
console.log(data)
})
event.on('test', (data) => {
console.log(data)
})
event.on('test', (data) => {
console.log(data)
})
event.on('test',(data)=>{
console.log(data)
})
event.on('test',(data)=>{
console.log(data)
})
event.emit('test', 'szszsz')
如何解除限制 调用 setMaxListeners 传入数量
event.setMaxListeners(20)
只想监听一次 once 即使emit派发多次也只触发一次once
const EventEmitter = require('events');
const event = new EventEmitter()
event.setMaxListeners(20)
event.once('test', (data) => {
console.log(data)
})
event.emit('test', 'xmxmxmxmx1')
event.emit('test', 'xmxmxmxmx2')
如何取消侦听 off
const EventEmitter = require('events');
const event = new EventEmitter()
const fn = (msg) => {
console.log(msg)
}
event.on('test', fn)
event.off('test', fn)
event.emit('test', 'xmxmxmxmx1')
event.emit('test', 'xmxmxmxmx2')
有谁用到了
process
打开nodejs 源码 搜索 setupProcessObject 这个函数
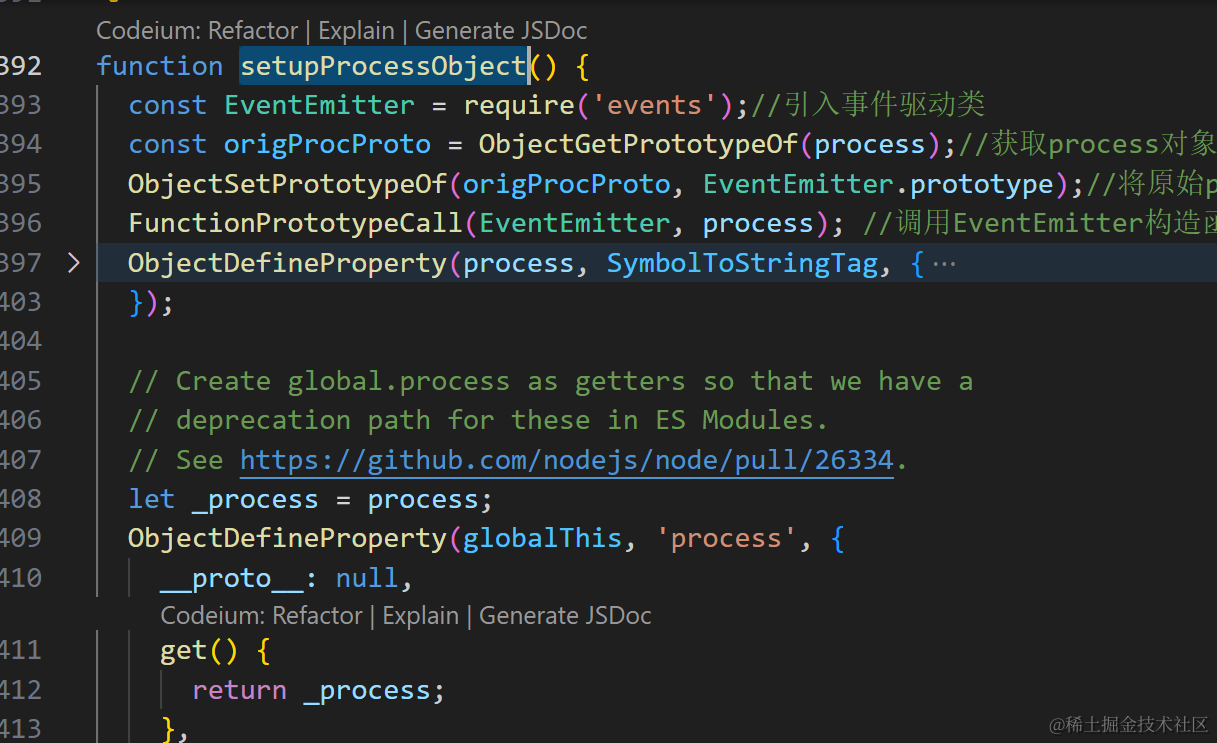
- 它首先引入 event模块
- 获取process 的原型对象(js可以通过Object.getPrototypeof()来获取原型对象)
- 将event的原型对象设给了process 的原型对象,(js通过Object.setPrototypeof()来合并原型对象,同名属性会覆盖,不同名会增加)
- 并且重新绑定上下文
- 将process 挂载到globalThis 所以我们可以全局访问这个API
until
util 是Node.js内部提供的很多实用或者工具类型的API,方便我们快速开发。
由于API比较多 我们介绍一些常用的API
util.promisify
Node.js 大部分API 都是遵循 回调函数的模式去编写的。
https://juejin.cn/post/7277045020422930488
例如我们之前讲的exec
获取Node版本
import { exec } from 'node:child_process'
exec('node -v', (err,stdout)=>{
if(err){
return err
}
console.log(stdout)
})
以上就是常规写法
我们使用util的promisify 改为promise 风格 Promiseify 接受 original一个函数体
import { exec } from 'node:child_process'
import util from 'node:util'
const execPromise = util.promisify(exec)//返回一个新的函数
execPromise('node -v').then(res=>{
console.log(res,'res')
}).catch(err=>{
console.log(err,'err')
})
剖析promiseify如何实现的
- 第一步Promiseify是返回一个新的函数
const promiseify = () => {
return () => {
}
}
- promiseify接受一个函数,并且在返回的函数才接受真正的参数,然后返回一个promise
const promiseify = (original) => {
return (...args) => {
return new Promise((resolve,reject)=>{
})
}
}
- 调用真正的函数,将参数透传给original,如果失败了就reject,如果成功了,就返回resolve,如果有多个返回一个对象。
const promiseify = (original) => {
return (...args) => {
return new Promise((resolve, reject) => {
original(...args, (err, ...values) => {
if (err) {
return reject(err)
}
if (values && values.length > 1) {
let obj = {}
console.log(values)
for (let key in values) {
obj[key] = values[key]
}
resolve(obj)
} else {
resolve(values[0])
}
})
})
}
}
这样可以大致实现但是拿不到values 的key 因为 nodejs内部 没有对我们开放 这个Symbol kCustomPromisifyArgsSymbol
所以输出的结果是 { '0': 'v18.16.0\n', '1': '' } 正常应该是 { stdout: 'v18.16.0\n', stderr: '' }
但是我们拿不到key,只能大概实现一下。
util.callbackify
这个API 正好是 反过来的,将promise类型的API变成 回调函数。
import util from 'node:util'
const fn = (type) => {
if(type == 1){
return Promise.resolve('test')
}
return Promise.reject('error')
}
const callback = util.callbackify(fn)
callback(1222,(err,val)=>{
console.log(err,val)
})
剖析callbackify
const callbackify = (fn) => {
return (...args) => {
let callback = args.pop()
fn(...args).then(res => {
callback(null, res)
}).catch(err => {
callback(err)
})
}
}
这个比较简单,因为考虑多个参数的情况,但是回调函数肯定在最后一个,所以使用pop把他取出来。
util.format
- %s: String 将用于转换除 BigInt、Object 和 -0 之外的所有值。 BigInt 值将用 n 表示,没有用户定义的 toString 函数的对象使用具有选项 { depth: 0, colors: false, compact: 3 } 的 util.inspect() 进行检查。
- %d: Number 将用于转换除 BigInt 和 Symbol 之外的所有值。
- %i: parseInt(value, 10) 用于除 BigInt 和 Symbol 之外的所有值。
- %f: parseFloat(value) 用于除 Symbol 之外的所有值。
- %j: JSON。 如果参数包含循环引用,则替换为字符串 ‘[Circular]’。
- %o: Object. 具有通用 JavaScript 对象格式的对象的字符串表示形式。 类似于具有选项 { showHidden: true, showProxy: true } 的 util.inspect()。 这将显示完整的对象,包括不可枚举的属性和代理。
- %O: Object. 具有通用 JavaScript 对象格式的对象的字符串表示形式。 类似于没有选项的 util.inspect()。 这将显示完整的对象,但不包括不可枚举的属性和代理。
- %c: CSS. 此说明符被忽略,将跳过任何传入的 CSS。
- %%: 单个百分号 (‘%’)。 这不消费参数。
语法 跟 C 语言的 printf 一样的
util.format(format, [args])
例子 格式化一个字符串
util.format('%s-----%s %s/%s','foo','bar','sz','yyds')
//foo-----bar sz/yyds 可以返回指定的格式
如果不传入格式化参数 就按空格分开
util.format(1,2,3)
//1 2 3
pngquant
什么是pngquant?
pngquant 是一个用于压缩 PNG 图像文件的工具。它可以显著减小 PNG 文件的大小,同时保持图像质量和透明度。通过减小文件大小,可以提高网页加载速度,并节省存储空间。pngquant 提供命令行接口和库,可轻松集成到各种应用程序和脚本中。
http://pngquant.com/
pngquant原理
pngquant 使用修改过的 Median Cut 量化算法以及其他技术来实现压缩 PNG 图像的目的。它的工作原理如下:
- 首先,pngquant 构建一个直方图,用于统计图像中的颜色分布情况。
- 接下来,它选择盒子来代表一组颜色。与传统的 Median Cut 算法不同,pngquant 选择的盒子是为了最小化盒子中颜色与中位数的差异。
- pngquant 使用感知模型给予图像中噪声较大的区域较少的权重,以建立更准确的直方图。
- 为了进一步改善颜色,pngquant 使用类似梯度下降的过程对直方图进行调整。它多次重复 Median Cut 算法,并在较少出现的颜色上增加权重。
- 最后,为了生成最佳的调色板,pngquant 使用 Voronoi 迭代(K-means)对颜色进行校正,以确保局部最优。
- 在重新映射颜色时,pngquant 只在多个相邻像素量化为相同颜色且不是边缘的区域应用误差扩散。这样可以避免在视觉质量较高且不需要抖动的区域添加噪声。
通过这些步骤,pngquant 能够在保持图像质量的同时,将 PNG 图像的文件大小减小到最低限度。
Median Cut 量化算法
假设我们有一张 8x8 像素的彩色图像,每个像素由红色、绿色和蓝色通道组成,每个通道的值范围是 0 到 255。
- 初始化:我们将图像中的每个像素视为一个颜色点,并将它们放入一个初始的颜色桶。
- 选择划分桶:在初始的颜色桶中选择一个具有最大范围的颜色通道,假设我们选择红色通道。
- 划分颜色:对于选定的红色通道,将颜色桶中的颜色按照红色通道的值进行排序,并找到中间位置的颜色值作为划分点。假设划分点的红色值为 120。
划分前的颜色桶:
- 颜色1: (100, 50, 200)
- 颜色2: (150, 30, 100)
- 颜色3: (80, 120, 50)
- 颜色4: (200, 180, 160)
划分后的颜色桶:
- 子桶1:
- 颜色1: (100, 50, 200)
- 颜色3: (80, 120, 50)
- 子桶2:
- 颜色2: (150, 30, 100)
- 颜色4: (200, 180, 160)
- 重复划分:我们继续选择颜色范围最大的通道,假设我们选择子桶1中的绿色通道。
划分前的颜色桶(子桶1):
-
颜色1: (100, 50, 200)
-
颜色3: (80, 120, 50)
划分后的颜色桶(子桶1):
-
子桶1.1:
- 颜色3: (80, 120, 50)
-
子桶1.2:
- 颜色1: (100, 50, 200)
子桶2中只有两个颜色,不需要再进行划分。
- 颜色映射:将原始图像中的每个像素颜色映射到最接近的颜色桶中的颜色。
假设原始图像中的一个像素为 (110, 70, 180),我们将它映射到颜色1: (100, 50, 200)
大概的公式为 sqrt((110-100)^2 + (70-50)^2 + (180-200)^2) ≈ 31.62
通过 Median Cut 算法,我们将原始图像中的颜色数目从 64 个(8x8 像素)减少到 4 个颜色桶,从而实现了图像的量化
nodejs中调用pngquant
我们同样还是可以用exec命令调用
import { exec } from 'child_process'
exec('pngquant 73kb.png --output test.png')
73kb 压缩完 之后 22kb
import { exec } from 'child_process'
exec('pngquant 73kb.png --quality=82 --output test.png')
quality表示图片质量0-100值越大图片越大效果越好
import { exec } from 'child_process'
exec('pngquant 73kb.png --speed=1 --quality=82 --output test.png')
--speed=1: 最慢的速度,产生最高质量的输出图像。--speed=10: 最快的速度,但可能导致输出图像质量稍微降低。
fs
概述
在 Node.js 中,fs 模块是文件系统模块(File System module)的缩写,它提供了与文件系统进行交互的各种功能。通过 fs 模块,你可以执行诸如读取文件、写入文件、更改文件权限、创建目录等操作,Node.js 核心API之一。
fs多种策略
import fs from 'node:fs'
import fs2 from 'node:fs/promises'
//读取文件
fs2.readFile('./index.txt').then(result => {
console.log(result.toString())
})
fs.readFile('./index.txt', (err, data) => {
if (err) {
return err
}
console.log(data.toString())
})
let txt = fs.readFileSync('./index.txt')
console.log(txt.toString())
- fs支持同步和异步两种模式 增加了Sync fs 就会采用同步的方式运行代码,会阻塞下面的代码,不加Sync就是异步的模式不会阻塞。
- fs新增了promise版本,只需要在引入包后面增加/promise即可,fs便可支持promise回调。
- fs返回的是一个buffer二进制数据 每两个十六进制数字表示一个字节
<Buffer 31 e3 80 81 e9 82 a3 e4 b8 80 e5 b9 b4 e5 86 b3 e8 b5 9b ef bc 8c e6 98 af 53 53 47 e5 af b9 e6 88 98 53 4b 54 ef bc 8c e6 9c 80 e7 bb 88 e6 af 94 e5 ... 635 more bytes>
常用API介绍
读取文件 readFile 读一个参数 读取的路径, 第二个参数是个配置项
encoding 支持各种编码 utf-8之类的
flag 就很多了
'a': 打开文件进行追加。 如果文件不存在,则创建该文件。'ax': 类似于 ‘a’ 但如果路径存在则失败。'a+': 打开文件进行读取和追加。 如果文件不存在,则创建该文件。'ax+': 类似于 ‘a+’ 但如果路径存在则失败。'as': 以同步模式打开文件进行追加。 如果文件不存在,则创建该文件。'as+': 以同步模式打开文件进行读取和追加。 如果文件不存在,则创建该文件。'r': 打开文件进行读取。 如果文件不存在,则会发生异常。'r+': 打开文件进行读写。 如果文件不存在,则会发生异常。'rs+': 以同步模式打开文件进行读写。 指示操作系统绕过本地文件系统缓存。
这主要用于在 NFS 挂载上打开文件,因为它允许跳过可能过时的本地缓存。 它对 I/O 性能有非常实际的影响,因此除非需要,否则不建议使用此标志。
这不会将 fs.open() 或fsPromises.open()变成同步阻塞调用。 如果需要同步操作,应该使用类似 fs.openSync() 的东西。
'w': 打开文件进行写入。 创建(如果它不存在)或截断(如果它存在)该文件。'wx': 类似于 ‘w’ 但如果路径存在则失败。'w+': 打开文件进行读写。 创建(如果它不存在)或截断(如果它存在)该文件。'wx+': 类似于 ‘w+’ 但如果路径存在则失败。
import fs2 from 'node:fs/promises'
fs2.readFile('./index.txt',{
encoding:"utf8",
flag:"",
}).then(result => {
console.log(result.toString())
})
使用可读流读取 使用场景适合读取大文件
const readStream = fs.createReadStream('./index.txt',{
encoding:"utf8"
})
readStream.on('data',(chunk)=>{
console.log(chunk)
})
readStream.on('end',()=>{
console.log('close')
})
创建文件夹 如果开启 recursive 可以递归创建多个文件夹
fs.mkdir('path/test/ccc', { recursive: true },(err)=>{
})
删除文件夹 如果开启recursive 递归删除全部文件夹
fs.rm('path', { recursive: true },(err)=>{
})
重命名文件 第一个参数原始名称 第二个参数新的名称
fs.renameSync('./test.txt','./test2.txt')
监听文件的变化 返回监听的事件如change,和监听的内容filename
fs.watch('./test2.txt',(event,filename)=>{
console.log(event,filename)
})
源码解析
https://github.com/libuv/libuv
fs的源码是通过 C++ 层的 FSReqCallback 这个类 对libuv 的uv_fs_t 的一个封装,其实也就是将我们fs 的参数透传给 libuv 层
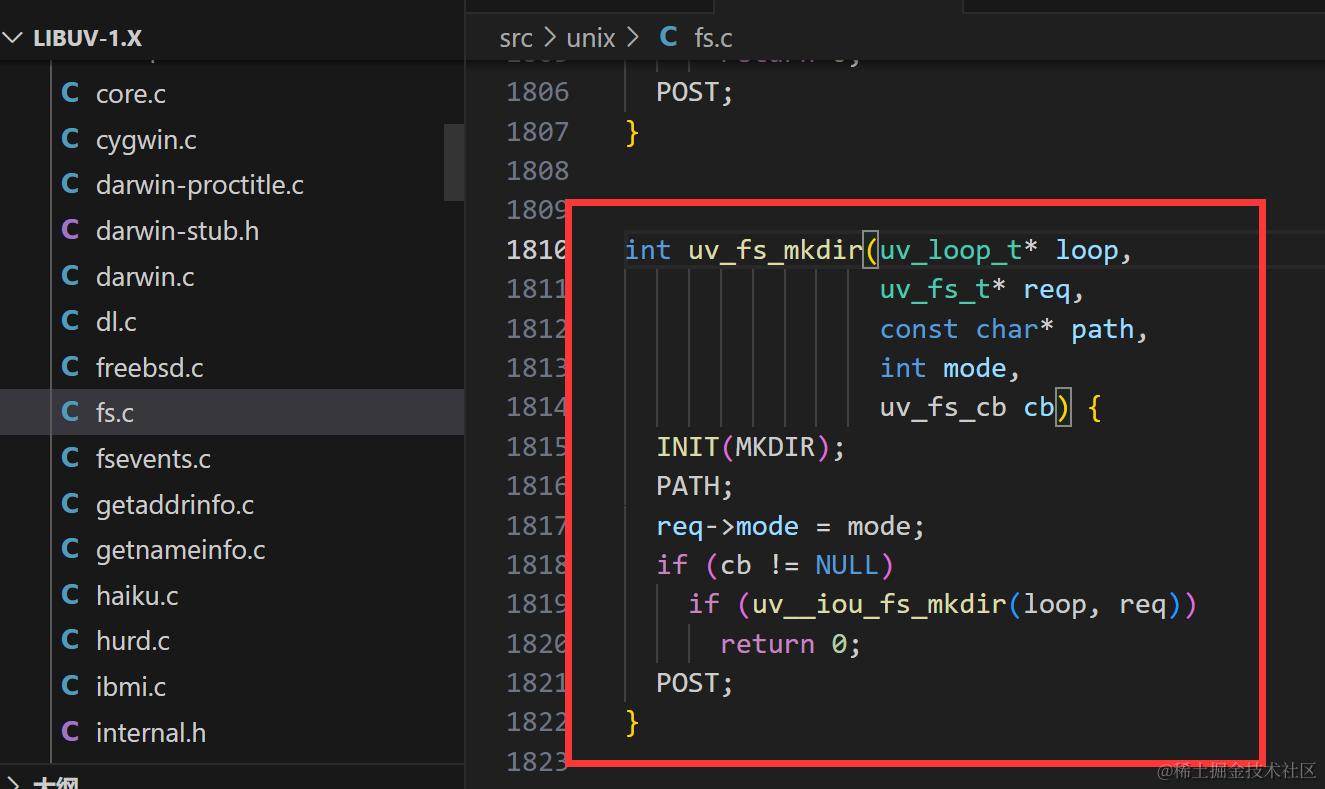
mkdir 举例
// 创建目录的异步操作函数,通过uv_fs_mkdir函数调用
// 参数:
// - loop: 事件循环对象,用于处理异步操作
// - req: 文件系统请求对象,用于保存操作的状态和结果
// - path: 要创建的目录的路径
// - mode: 目录的权限模式 777 421
// - cb: 操作完成后的回调函数
int uv_fs_mkdir(uv_loop_t* loop,
uv_fs_t* req,
const char* path,
int mode,
uv_fs_cb cb) {
INIT(MKDIR);
PATH;
req->mode = mode;
if (cb != NULL)
if (uv__iou_fs_mkdir(loop, req))
return 0;
POST;
}
注意事项
const fs = require('node:fs')
fs.readFile('./index.txt', {
encoding: 'utf-8',
flag: 'r'
}, (err, dataStr) => {
if (err) throw err
console.log('fs')
})
setImmediate(() => {
console.log('setImmediate')
})
为什么先走setImmediate 呢,而不是fs
Node.js 读取文件的时候是使用libuv进行调度的
而setImmediate是由V8事件循环进行调度的
文件读取完成后 libuv 才会将 fs的结果 推入V8的事件队列
追加内容
第一种方式 设置flag 为 a 也可以追内容
fs.writeFileSync('index.txt', '\nvue之父\n鱿鱼须',{
flag: 'a'
})
java之父
sz
vue之父
鱿鱼须
第二种方式,使用appendFileSync也可以追加内容
const fs = require('node:fs')
fs.appendFileSync('index.txt', '\nunshift创始人\n麒麟哥')
可写流
const fs = require('node:fs')
let verse = [
'待到秋来九月八',
'我花开后百花杀',
'冲天香阵透长安',
'满城尽带黄金甲'
]
let writeStream = fs.createWriteStream('index.txt')
verse.forEach(item => {
writeStream.write(item + '\n')
})
writeStream.end()// 关闭通道
writeStream.on('finish',()=>{
console.log('写入完成')
})
我们可以创建一个可写流 打开一个通道,可以一直写入数据,用于处理大量的数据写入,写入完成之后调用end 关闭可写流,监听finish 事件 写入完成
硬链接 和 软连接
fs.linkSync('./index.txt', './index2.txt') //硬链接
fs.symlinkSync('./index.txt', './index3.txt' ,"file") //软连接 需要管理员权限
硬链接的作用和用途如下:
- 文件共享:硬链接允许多个文件名指向同一个文件,这样可以在不同的位置使用不同的文件名引用相同的内容。这样的共享文件可以节省存储空间,并且在多个位置对文件的修改会反映在所有引用文件上。
- 文件备份:通过创建硬链接,可以在不复制文件的情况下创建文件的备份。如果原始文件发生更改,备份文件也会自动更新。这样可以节省磁盘空间,并确保备份文件与原始文件保持同步。
- 文件重命名:通过创建硬链接,可以为文件创建一个新的文件名,而无需复制或移动文件。这对于需要更改文件名但保持相同内容和属性的场景非常有用。
注:源文件删掉,其他文件不受影响
软链接的一些特点和用途如下:
- 软链接可以创建指向文 件或目录的引用。这使得你可以在不复制或移动文件的情况下引用它们,并在不同位置使用不同的文件名访问相同的内容。
- 软链接可以用于创建快捷方式或别名,使得你可以通过一个简短或易记的路径来访问复杂或深层次的目录结构。
- 软链接可以用于解决文件或目录的位置变化问题。如果目标文件或目录被移动或重命名,只需更新软链接的目标路径即可,而不需要修改引用该文件或目录的其他代码。
软连接有点像windows快捷方式。
注:源文件删除,其他文件也打不开
crypto(密码学)
概念
密码学是计算机科学中的一个重要领域,它涉及到加密、解密、哈希函数和数字签名等技术。Node.js是一个流行的服务器端JavaScript运行环境,它提供了强大的密码学模块,使开发人员能够轻松地在其应用程序中实现各种密码学功能。本文将介绍密码学的基本概念,并探讨Node.js中常用的密码学API。
对称加密
const crypto = require('node:crypto');
// 生成一个随机的 16 字节的初始化向量 (IV)
const iv = Buffer.from(crypto.randomBytes(16));//保证生成的密钥串每次是不一样的 密钥串缺少位数 还可以进行补码的操作
// 生成一个随机的 32 字节的密钥
const key = crypto.randomBytes(32);
// 创建加密实例,使用 AES-256-CBC 算法,提供密钥和初始化向量
const cipher = crypto.createCipheriv("aes-256-cbc", key, iv);
// 对输入数据进行加密,并输出加密结果的十六进制表示
cipher.update("zs", "utf-8", "hex");
const result = cipher.final("hex");
console.log(result);//16进制 32位
// 解密 相同的算法 相同的key 相同的iv
const de = crypto.createDecipheriv("aes-256-cbc", key, iv);
de.update(result, "hex");
const decrypted = de.final("utf-8");
console.log("Decrypted:", decrypted);
对称加密是一种简单而快速的加密方式,它使用相同的密钥(称为对称密钥)来进行加密和解密。这意味着发送者和接收者在加密和解密过程中都使用相同的密钥。对称加密算法的加密速度很快,适合对大量数据进行加密和解密操作。然而,对称密钥的安全性是一个挑战,因为需要确保发送者和接收者都安全地共享密钥,否则有风险被未授权的人获取密钥并解密数据。
非对称加密
const crypto = require('node:crypto')
// 生成 RSA 密钥对
const { privateKey, publicKey } = crypto.generateKeyPairSync('rsa', {
modulusLength: 2048,
});
// 要加密的数据
const text = 'zs';
// 使用公钥进行加密
const encrypted = crypto.publicEncrypt(publicKey, Buffer.from(text, 'utf-8'));
// 使用私钥进行解密
const decrypted = crypto.privateDecrypt(privateKey, encrypted);
console.log(decrypted.toString());
非对称加密使用一对密钥,分别是公钥和私钥。发送者使用接收者的公钥进行加密,而接收者使用自己的私钥进行解密。公钥可以自由分享给任何人,而私钥必须保密。非对称加密算法提供了更高的安全性,因为即使公钥泄露,只有持有私钥的接收者才能解密数据。然而,非对称加密算法的加密速度相对较慢,不适合加密大量数据。因此,在实际应用中,通常使用非对称加密来交换对称密钥,然后使用对称加密算法来加密实际的数据。
哈希函数
const crypto = require('node:crypto');
// 要计算哈希的数据
let text = '123456';
// 创建哈希对象,并使用 MD5 算法
const hash = crypto.createHash('md5');//或者sha256
// 更新哈希对象的数据
hash.update(text);
// 计算哈希值,并以十六进制字符串形式输出
const hashValue = hash.digest('hex');
console.log('Text:', text);
console.log('Hash:', hashValue);
不能被解密,因为是单向的 不可逆的。
不是很安全,具有唯一性。
比如用户的密码一般都是用md5去包裹一下存储到数据库,不可能明文存储。
就可以有机会用撞库,去碰你的密码。
哈希函数具有以下特点:
- 固定长度输出:不论输入数据的大小,哈希函数的输出长度是固定的。例如,常见的哈希函数如 MD5 和 SHA-256 生成的哈希值长度分别为 128 位和 256 位。
- 不可逆性:哈希函数是单向的,意味着从哈希值推导出原始输入数据是非常困难的,几乎不可能。即使输入数据发生微小的变化,其哈希值也会完全不同。
- 唯一性:哈希函数应该具有较低的碰撞概率,即不同的输入数据生成相同的哈希值的可能性应该非常小。这有助于确保哈希值能够唯一地标识输入数据。
使用场景
- 我们可以避免密码明文传输 使用md5加密或者sha256
- 验证文件完整性,读取文件内容生成md5 如果前端上传的md5和后端的读取文件内部的md5匹配说明文件是完整的
命令行工具(编写脚手架cli)
概念
例如:vue-cli Angular CLI Create React App
编写自己的脚手架是指创建一个定制化的工具,用于快速生成项目的基础结构和代码文件,以及提供一些常用的命令和功能。通过编写自己的脚手架,你可以定义项目的目录结构、文件模板,管理项目的依赖项,生成代码片段,以及提供命令行接口等功能
- 项目结构:脚手架定义了项目的目录结构,包括源代码、配置文件、静态资源等。
- 文件模板:脚手架提供了一些预定义的文件模板,如HTML模板、样式表、配置文件等,以加快开发者创建新文件的速度。
- 命令行接口:脚手架通常提供一个命令行接口,通过输入命令和参数,开发者可以执行各种任务,如创建新项目、生成代码文件、运行测试等。
- 依赖管理:脚手架可以帮助开发者管理项目的依赖项,自动安装和配置所需的库和工具。
- 代码生成:脚手架可以生成常见的代码结构,如组件、模块、路由等,以提高开发效率。
- 配置管理:脚手架可以提供一些默认的配置选项,并允许开发者根据需要进行自定义配置。
工具介绍
哪个前端不想拥有自己的一套脚手架,在这一章节你会学到非常多的第三方库,如
commander
Commander 是一个用于构建命令行工具的 npm 库。它提供了一种简单而直观的方式来创建命令行接口,并处理命令行参数和选项。使用 Commander,你可以轻松定义命令、子命令、选项和帮助信息。它还可以处理命令行的交互,使用户能够与你的命令行工具进行交互
inquirer
Inquirer 是一个强大的命令行交互工具,用于与用户进行交互和收集信息。它提供了各种丰富的交互式提示(如输入框、选择列表、确认框等),可以帮助你构建灵活的命令行界面。通过 Inquirer,你可以向用户提出问题,获取用户的输入,并根据用户的回答采取相应的操作。
ora
Ora 是一个用于在命令行界面显示加载动画的 npm 库。它可以帮助你在执行耗时的任务时提供一个友好的加载状态提示。Ora 提供了一系列自定义的加载动画,如旋转器、进度条等,你可以根据需要选择合适的加载动画效果,并在任务执行期间显示对应的加载状态。
download-git-repo
Download-git-repo 是一个用于下载 Git 仓库的 npm 库。它提供了一个简单的接口,可以方便地从远程 Git 仓库中下载项目代码。你可以指定要下载的仓库和目标目录,并可选择指定分支或标签。Download-git-repo 支持从各种 Git 托管平台(如 GitHub、GitLab、Bitbucket 等)下载代码。
编写代码
- index.js
#!/usr/bin/env node
import { program } from 'commander'
import inquirer from 'inquirer'
import fs from 'node:fs'
import { checkPath, downloadTemp } from './utils.js'
let json = fs.readFileSync('./package.json', 'utf-8') //读取文件
json = JSON.parse(json)//变成对象
program.version(json.version) //创建版本号
//添加create 命令 和 别名crt 以及描述 以及 执行完成之后的动作
program.command('create <project>').alias('ctr').description('create a new project').action((project) => {
//命令行交互工具
inquirer.prompt([
{
type: 'input', //输入 他还可以支持 confirm 确认框 list选择框 checkout等
name: 'projectName', //返回值的key
message: 'project name', //描述
default: project //默认值
},
{
type: 'confirm',
name: 'isTs',
message: '是否支持typeScript',
}
]).then((answers) => {
if (checkPath(answers.projectName)) { //判断文件名称是否存在
console.log('文件已存在')
return
}
if (answers.isTs) { //判断是否要创建ts的模版
downloadTemp('ts', answers.projectName) //
} else {
downloadTemp('js', answers.projectName)
}
})
})
program.parse(process.argv)//读到后面的参数 ,然后交给program去解析
为什么第一行要写 #!/usr/bin/env node
这是一个 特殊的注释 用于告诉操作系统用node解释器去执行这个文件,而不是显式地调用 node 命令
- utils.js
import fs from 'node:fs'
import download from 'download-git-repo'
import ora from 'ora'
const spinner = ora('下载中...')
//验证路径
export const checkPath = (path) => {
return fs.existsSync(path)
}
//下载
export const downloadTemp = (branch,project) => { //根据不同分支下载对应代码
spinner.start() //下载时的动画
return new Promise((resolve,reject)=>{
download(`direct:https://gitee.com/chinafaker/vue-template.git#${branch}`, project , { clone: true, }, function (err) {
if (err) {
reject(err)
console.log(err)
}
resolve()
spinner.succeed('下载完成')
})
})
}
- package.json
"type": "module", //使用import需要设置这个
"bin": {
"vue-cli": "src/index.js"
},
用于生成软连接挂载到全局,便可以全局执行vue-cli 这个命令,配置完成之后 需要执行
npm link
Markdown 转 html
参考链接:markdown 转 html 工具_哔哩哔哩_bilibili
所需的库:
- EJS:一款强大的JavaScript模板引擎,它可以帮助我们在HTML中嵌入动态内容。使用EJS,您可以轻松地将Markdown转换为美观的HTML页面。
- Marked:一个流行的Markdown解析器和编译器,它可以将Markdown语法转换为HTML标记。Marked是一个功能强大且易于使用的库,它为您提供了丰富的选项和扩展功能,以满足各种转换需求。
- BrowserSync:一个强大的开发工具,它可以帮助您实时预览和同步您的网页更改。当您对Markdown文件进行编辑并将其转换为HTML时,BrowserSync可以自动刷新您的浏览器,使您能够即时查看转换后的结果。
ejs语法
1.纯脚本标签
<% code %>
里面可以写任意的 js,用于流程控制,无任何输出。
<% alert('hello world') %> // 会执行弹框
2.输出经过 HTML 转义的内容
<%= value %> 可以是变量
<%= a ? b : c %> 也可以是表达式
<%= a + b %>
即变量如果包含 ‘<’、‘>’、'&'等HTML字符,会被转义成字符实体,像< > &
因此用<%=,最好保证里面内容不要有HTML字符
const text = '<p>你好你好</p>'
<h2><%= text %></h2> // 输出 <p>你好你好</p> 插入 <h2> 标签中
3.输出非转义的内容(原始内容)
<%- 富文本数据 %> 通常用于输出富文本,即 HTML内容
上面说到<%=会转义HTML字符,那如果我们就是想输出一段HTML怎么办呢?
<%-不会解析HTML标签,也不会将字符转义后输出。像下例,就会直接把 <p>我来啦</p> 插入
标签中
const content = '<p>标签</p>'
<h2><%- content %></h2>
4.引入其他模版
<%- include('***文件路径') %>
将相对于模板路径中的模板片段包含进来。
用<%- include指令而不是<% include,为的是避免对输出的 HTML 代码做转义处理。
// 当前模版路径:./views/tmp.ejs
// 引入模版路径:./views/user/show.ejs
<ul>
<% users.forEach(function(user){ %>
<%- include('user/show', {user: user}); %>
<% }); %>
</ul>
5.条件判断
<% if (condition1) { %>
...
<% } %>
<% if (condition1) { %>
...
<% } else if (condition2) { %>
...
<% } %>
// 举例
<% if (a && b) { %>
<p>可以直接放 html 内容</p>
<% } %>
<% if (a && b) { %>
<% console.log('也可以嵌套任意ejs模版语句') %>
<% } %>
6.循环
<% for(var i = 0; i < target.length; i++){ %>
<%= i %> <%= target[i] %>
<% } %>
<% for(var i in jsArr) { %>
<script type="text/javascript" src="<%= jsArr[i] %>" ref="preload"></script>
<% } %>
// 推荐
<% for(var css of cssArr) { %>
<link rel="stylesheet" href="<%= css %>" />
<% } %>
- template.ejs
初始化模板 到时候会转换成html代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title><%= title %></title>
<link rel="stylesheet" href="./index.css">
</head>
<body>
<%- content %>
</body>
</html>
marked
编写一个简易的md文档
### 标题
- test
将md 转换成html
const marked = require('marked')
marked.parse(readme.toString()) //调用parse即可
browserSync
创建browser 并且开启一个服务 设置根目录和 index.html 文件
const browserSync = require('browser-sync')
const openBrowser = () => {
const browser = browserSync.create()
browser.init({
server: {
baseDir: './',
index: 'index.html',
}
})
return browser
}
index.css
html代码有了 但是没有通用的markdown的通用css
/* Markdown通用样式 */
/* 设置全局字体样式 */
body {
font-family: Arial, sans-serif;
font-size: 16px;
line-height: 1.6;
color: #333;
}
/* 设置标题样式 */
h1,
h2,
h3,
h4,
h5,
h6 {
margin-top: 1.3em;
margin-bottom: 0.6em;
font-weight: bold;
}
h1 {
font-size: 2.2em;
}
h2 {
font-size: 1.8em;
}
h3 {
font-size: 1.6em;
}
h4 {
font-size: 1.4em;
}
h5 {
font-size: 1.2em;
}
h6 {
font-size: 1em;
}
/* 设置段落样式 */
p {
margin-bottom: 1.3em;
}
/* 设置链接样式 */
a {
color: #337ab7;
text-decoration: none;
}
a:hover {
text-decoration: underline;
}
/* 设置列表样式 */
ul,
ol {
margin-top: 0;
margin-bottom: 1.3em;
padding-left: 2em;
}
/* 设置代码块样式 */
pre {
background-color: #f7f7f7;
padding: 1em;
border-radius: 4px;
overflow: auto;
}
code {
font-family: Consolas, Monaco, Courier, monospace;
font-size: 0.9em;
background-color: #f7f7f7;
padding: 0.2em 0.4em;
border-radius: 4px;
}
/* 设置引用样式 */
blockquote {
margin: 0;
padding-left: 1em;
border-left: 4px solid #ddd;
color: #777;
}
/* 设置表格样式 */
table {
border-collapse: collapse;
width: 100%;
margin-bottom: 1.3em;
}
table th,
table td {
padding: 0.5em;
border: 1px solid #ccc;
}
/* 添加一些额外的样式,如图片居中显示 */
img {
display: block;
margin: 0 auto;
max-width: 100%;
height: auto;
}
/* 设置代码行号样式 */
pre code .line-numbers {
display: inline-block;
width: 2em;
padding-right: 1em;
color: #999;
text-align: right;
user-select: none;
pointer-events: none;
border-right: 1px solid #ddd;
margin-right: 0.5em;
}
/* 设置代码行样式 */
pre code .line {
display: block;
padding-left: 1.5em;
}
/* 设置代码高亮样式 */
pre code .line.highlighted {
background-color: #f7f7f7;
}
/* 添加一些响应式样式,适应移动设备 */
@media only screen and (max-width: 768px) {
body {
font-size: 14px;
line-height: 1.5;
}
h1 {
font-size: 1.8em;
}
h2 {
font-size: 1.5em;
}
h3 {
font-size: 1.3em;
}
h4 {
font-size: 1.1em;
}
h5 {
font-size: 1em;
}
h6 {
font-size: 0.9em;
}
table {
font-size: 14px;
}
}
完整代码:
const ejs = require('ejs'); // 导入ejs库,用于渲染模板
const fs = require('node:fs'); // 导入fs模块,用于文件系统操作
const marked = require('marked'); // 导入marked库,用于将Markdown转换为HTML
const readme = fs.readFileSync('README.md'); // 读取README.md文件的内容
const browserSync = require('browser-sync'); // 导入browser-sync库,用于实时预览和同步浏览器
const openBrowser = () => {
const browser = browserSync.create()
browser.init({
server: {
baseDir: './',
index: 'index.html',
}
})
return browser
}
ejs.renderFile('template.ejs', {
content: marked.parse(readme.toString()),
title:'markdown to html'
},(err,data)=>{
if(err){
console.log(err)
}
let writeStream = fs.createWriteStream('index.html')
writeStream.write(data)
writeStream.close()
writeStream.on('finish',()=>{
openBrowser()
})
})
效果图
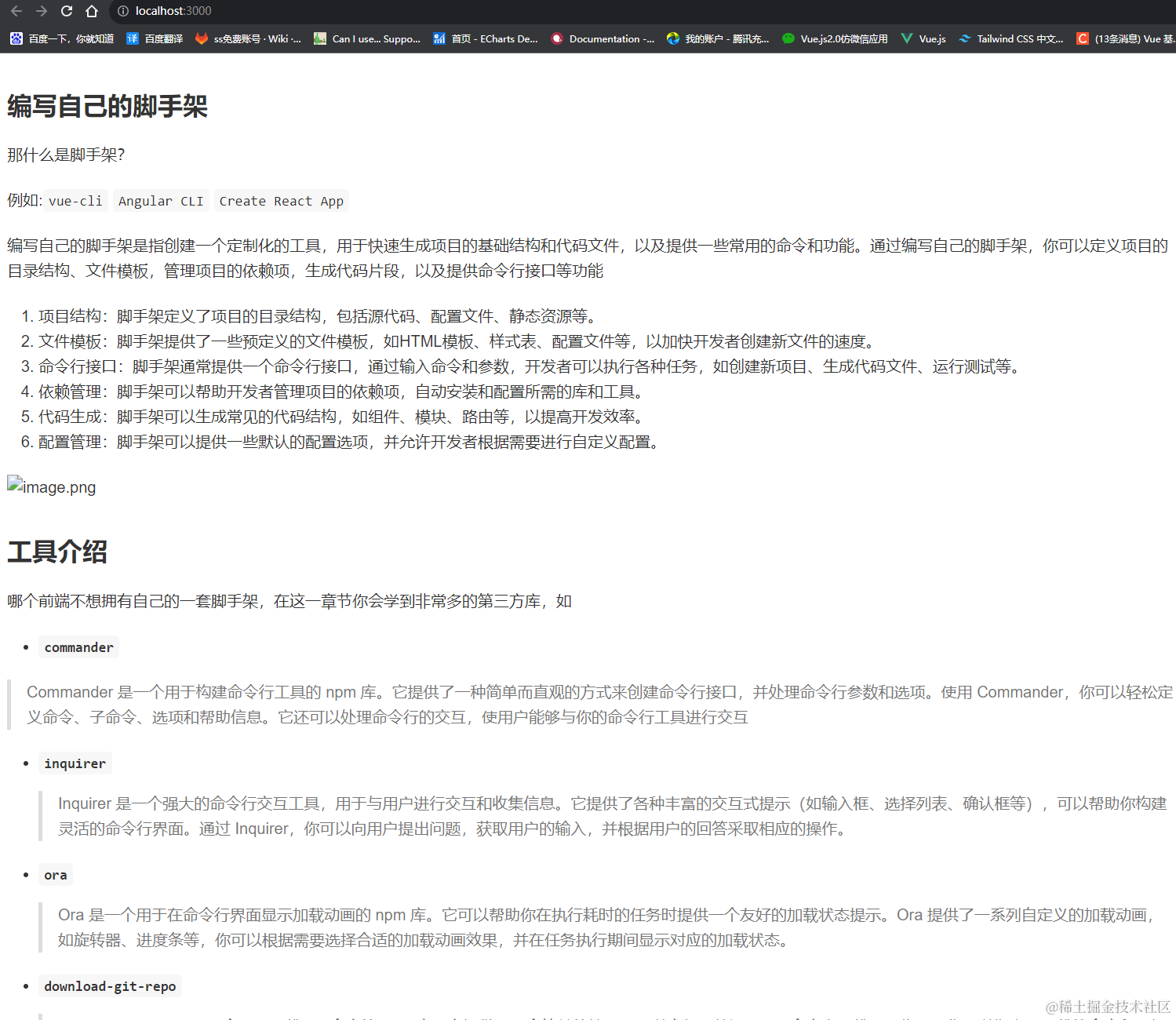
zlib(压缩,解压)
概念:
在 Node.js 中,zlib 模块提供了对数据压缩和解压缩的功能,以便在应用程序中减少数据的传输大小和提高性能。该模块支持多种压缩算法,包括 Deflate、Gzip 和 Raw Deflate。
作用:
zlib 模块的主要作用如下:
- 数据压缩:使用 zlib 模块可以将数据以无损压缩算法(如 Deflate、Gzip)进行压缩,减少数据的大小。这在网络传输和磁盘存储中特别有用,可以节省带宽和存储空间。
- 数据解压缩:zlib 模块还提供了对压缩数据的解压缩功能,可以还原压缩前的原始数据。
- 流压缩:zlib 模块支持使用流(Stream)的方式进行数据的压缩和解压缩。这种方式使得可以对大型文件或网络数据流进行逐步处理,而不需要将整个数据加载到内存中。
- 压缩格式支持:zlib 模块支持多种常见的压缩格式,如 Gzip 和 Deflate。这些格式在各种应用场景中广泛使用,例如 HTTP 响应的内容编码、文件压缩和解压缩等。
使用 zlib 模块进行数据压缩和解压缩可以帮助优化应用程序的性能和资源利用。通过减小数据的大小,可以减少网络传输的时间和带宽消耗,同时减少磁盘上的存储空间。此外,zlib 模块还提供了丰富的选项和方法,使得开发者可以根据具体需求进行灵活的压缩和解压缩操作。
代码案例:
压缩一个txt文件gzip index.txt(439kb) 压缩完index.txt.gz(4b)
// 引入所需的模块
const zlib = require('zlib'); // zlib 模块提供数据压缩和解压缩功能
const fs = require('node:fs'); // 引入 Node.js 的 fs 模块用于文件操作
// 创建可读流和可写流
const readStream = fs.createReadStream('index.txt'); // 创建可读流,读取名为 index.txt 的文件
const writeStream = fs.createWriteStream('index.txt.gz'); // 创建可写流,将压缩后的数据写入 index.txt.gz 文件
// 使用管道将可读流中的数据通过 Gzip 压缩,再通过管道传输到可写流中进行写入
readStream.pipe(zlib.createGzip()).pipe(writeStream)
解压 gzip
const readStream = fs.createReadStream('index.txt.gz')
const writeStream = fs.createWriteStream('index2.txt')
readStream.pipe(zlib.createGunzip()).pipe(writeStream)
无损压缩 deflate 使用 createDeflate方法
const readStream = fs.createReadStream('index.txt'); // 创建可读流,读取名为 index.txt 的文件
const writeStream = fs.createWriteStream('index.txt.deflate'); // 创建可写流,将压缩后的数据写入 index.txt.deflate 文件
readStream.pipe(zlib.createDeflate()).pipe(writeStream);
解压 deflate
const readStream = fs.createReadStream('index.txt.deflate')
const writeStream = fs.createWriteStream('index3.txt')
readStream.pipe(zlib.createInflate()).pipe(writeStream)
gzip 和 deflate 区别
- 压缩算法:Gzip 使用的是 Deflate 压缩算法,该算法结合了 LZ77 算法和哈夫曼编码。LZ77 算法用于数据的重复字符串的替换和引用,而哈夫曼编码用于进一步压缩数据。
- 压缩效率:Gzip 压缩通常具有更高的压缩率,因为它使用了哈夫曼编码来进一步压缩数据。哈夫曼编码根据字符的出现频率,将较常见的字符用较短的编码表示,从而减小数据的大小。
- 压缩速度:相比于仅使用 Deflate 的方式,Gzip 压缩需要更多的计算和处理时间,因为它还要进行哈夫曼编码的步骤。因此,在压缩速度方面,Deflate 可能比 Gzip 更快。
- 应用场景:Gzip 压缩常用于文件压缩,Deflate适用与网络传输和 HTTP 响应的内容编码。它广泛应用于 Web 服务器和浏览器之间的数据传输,以减小文件大小和提高网络传输效率。
http请求压缩
deflate 压缩前(8.2kb) -> 压缩后(236b)
const zlib = require('zlib');
const http = require('node:http');
const server = http.createServer((req,res)=>{
const txt = 'sz'.repeat(1000);
//res.setHeader('Content-Encoding','gzip')
res.setHeader('Content-Encoding','deflate')
res.setHeader('Content-type','text/plan;charset=utf-8')
const result = zlib.deflateSync(txt);
res.end(result)
})
server.listen(3000)
gizp 压缩前(8.2kb) -> 压缩后(245b)
const zlib = require('zlib');
const http = require('node:http');
const server = http.createServer((req,res)=>{
const txt = '小满zs'.repeat(1000);
res.setHeader('Content-Encoding','gzip')
//res.setHeader('Content-Encoding','deflate')
res.setHeader('Content-type','text/plan;charset=utf-8')
const result = zlib.gzipSync(txt);
res.end(result)
})
server.listen(3000)
http(web服务器)
“http” 模块是 Node.js 中用于创建和处理 HTTP 服务器和客户端的核心模块。它使得构建基于 HTTP 协议的应用程序变得更加简单和灵活。
- 创建 Web 服务器:你可以使用 “http” 模块创建一个 HTTP 服务器,用于提供 Web 应用程序或网站。通过监听特定的端口,服务器可以接收客户端的请求,并生成响应。你可以处理不同的路由、请求方法和参数,实现自定义的业务逻辑。
- 构建 RESTful API:“http” 模块使得构建 RESTful API 变得简单。你可以使用 HTTP 请求方法(如 GET、POST、PUT、DELETE 等)和路径来定义 API 的不同端点。通过解析请求参数、验证身份和权限,以及生成相应的 JSON 或其他数据格式,你可以构建强大的 API 服务。
- 代理服务器:“http” 模块还可以用于创建代理服务器,用于转发客户端的请求到其他服务器。代理服务器可以用于负载均衡、缓存、安全过滤或跨域请求等场景。通过在代理服务器上添加逻辑,你可以对请求和响应进行修改、记录或过滤。
- 文件服务器:“http” 模块可以用于创建一个简单的文件服务器,用于提供静态文件(如 HTML、CSS、JavaScript、图像等)。通过读取文件并将其作为响应发送给客户端,你可以轻松地构建一个基本的文件服务器。
创建http 服务器
const http = require('node:http')
const url = require('node:url')
http.createServer((req, res) => {
}).listen(98, () => { //端口号小于65535都是可以的
console.log('server is running on port 98')
})
我们前端发起请求 常用的就是 GET POST
那nodejs如何分清 GET 和 POST 呢
http.createServer((req, res) => {
//通过method 就可以了
if (req.method === 'POST') {
} else if (req.method === 'GET') {
}
}).listen(98, () => {
console.log('server is running on port 98')
})
完整版
const http = require('node:http'); // 引入 http 模块
const url = require('node:url'); // 引入 url 模块
// 创建 HTTP 服务器,并传入回调函数用于处理请求和生成响应
http.createServer((req, res) => {
const { pathname, query } = url.parse(req.url, true); // 解析请求的 URL,获取路径和查询参数 这边的ture是把参数序列化成一个对象
if (req.method === 'POST') { // 检查请求方法是否为 POST
if (pathname === '/post') { // 检查路径是否为 '/post'
let data = '';
req.on('data', (chunk) => {
data += chunk; // 获取 POST 请求的数据
console.log(data);
});
req.on('end', () => {
res. ('Content-Type', 'application/json'); // 设置响应头的 Content-Type 为 'application/json'
res.statusCode = 200; // 设置响应状态码为 200
res.end(data); // 将获取到的数据作为响应体返回
});
} else {
res.setHeader('Content-Type', 'application/json'); // 设置响应头的 Content-Type 为 'application/json'
res.statusCode = 404; // 设置响应状态码为 404
res.end('Not Found'); // 返回 'Not Found' 作为响应体
}
} else if (req.method === 'GET') { // 检查请求方法是否为 GET
if (pathname === '/get') { // 检查路径是否为 '/get'
console.log(query.a); // 打印查询参数中的键名为 'a' 的值
res.end('get success'); // 返回 'get success' 作为响应体
}
}
}).listen(98, () => {
console.log('server is running on port 98'); // 打印服务器启动的信息
});
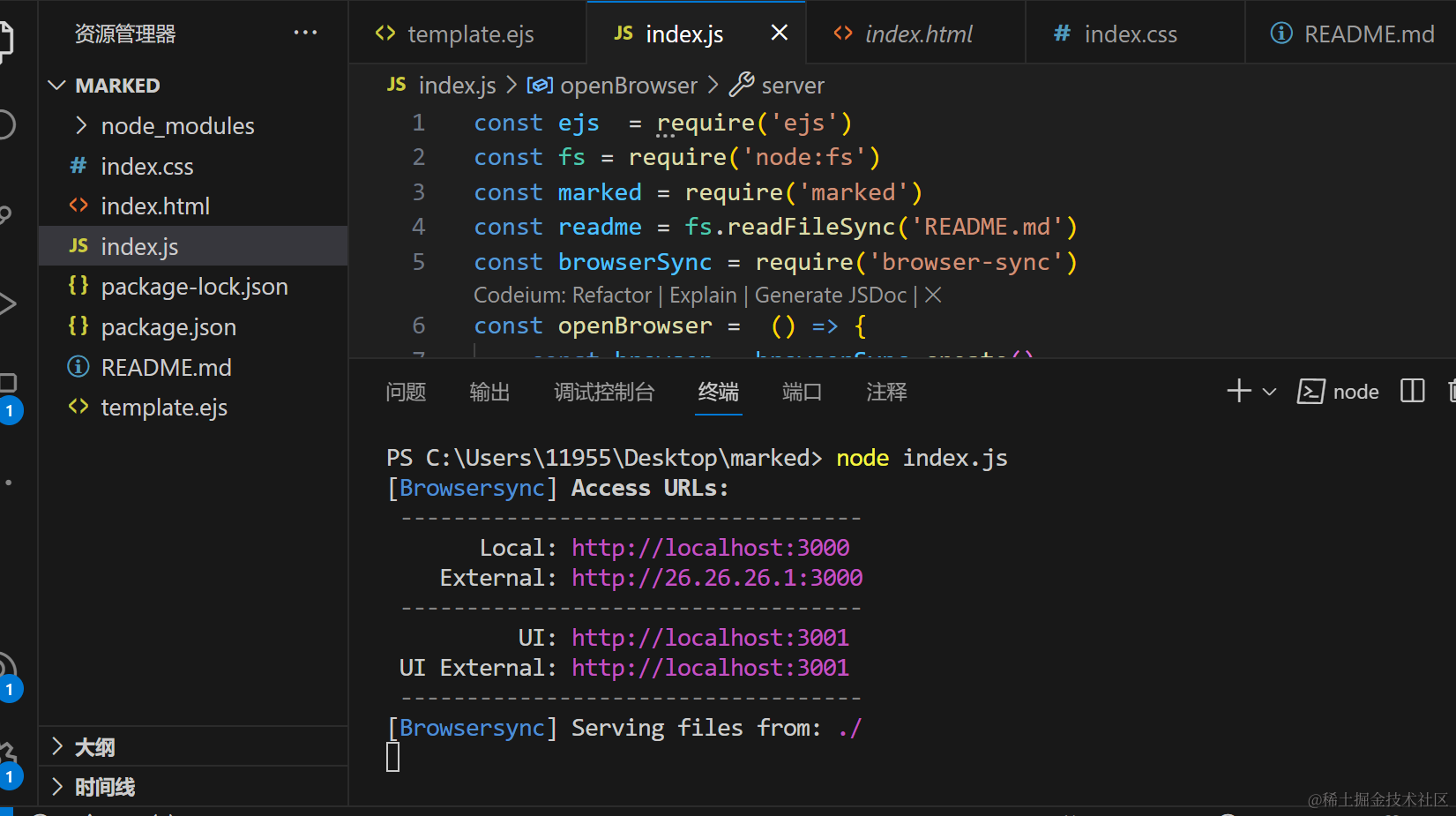
如何调试?
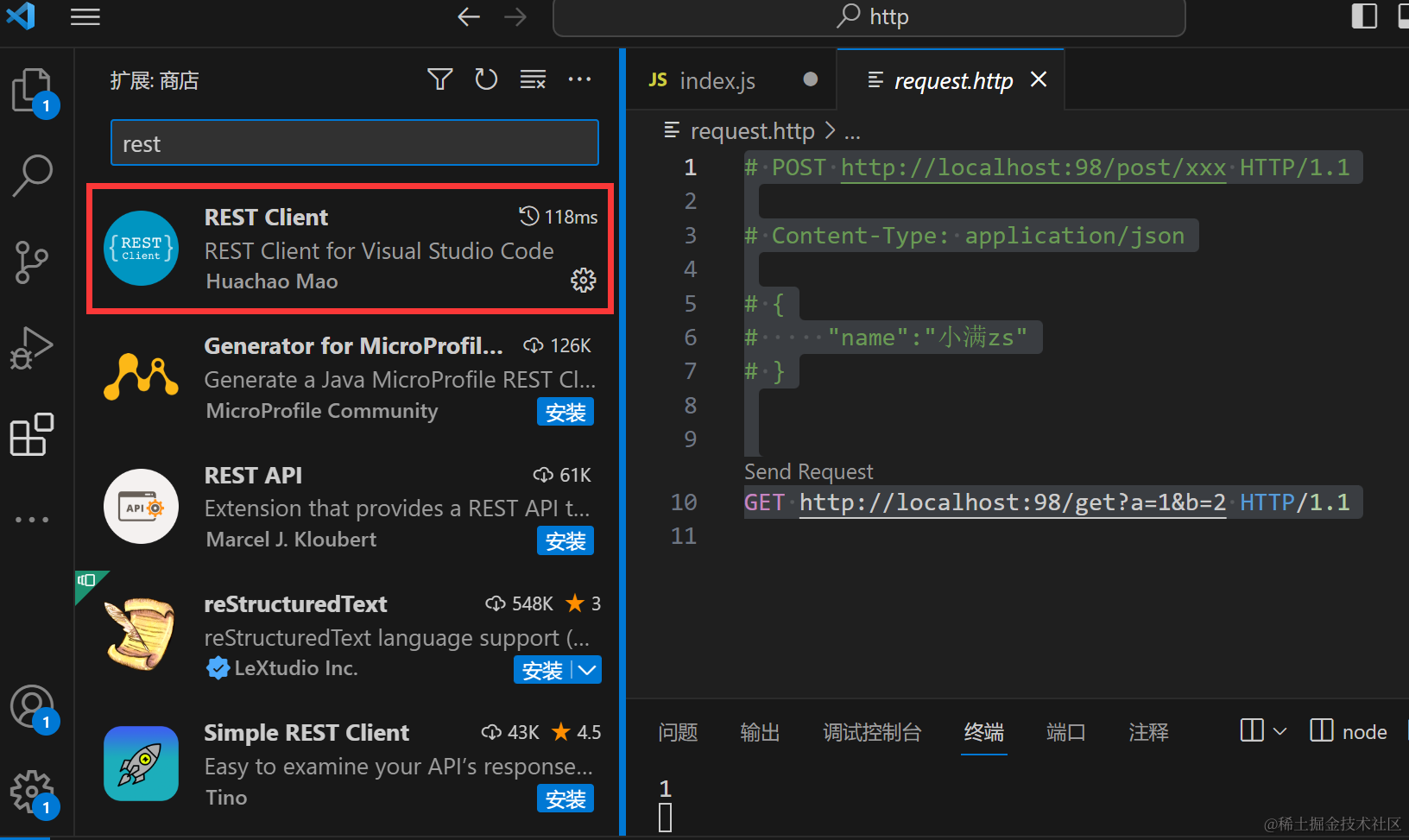
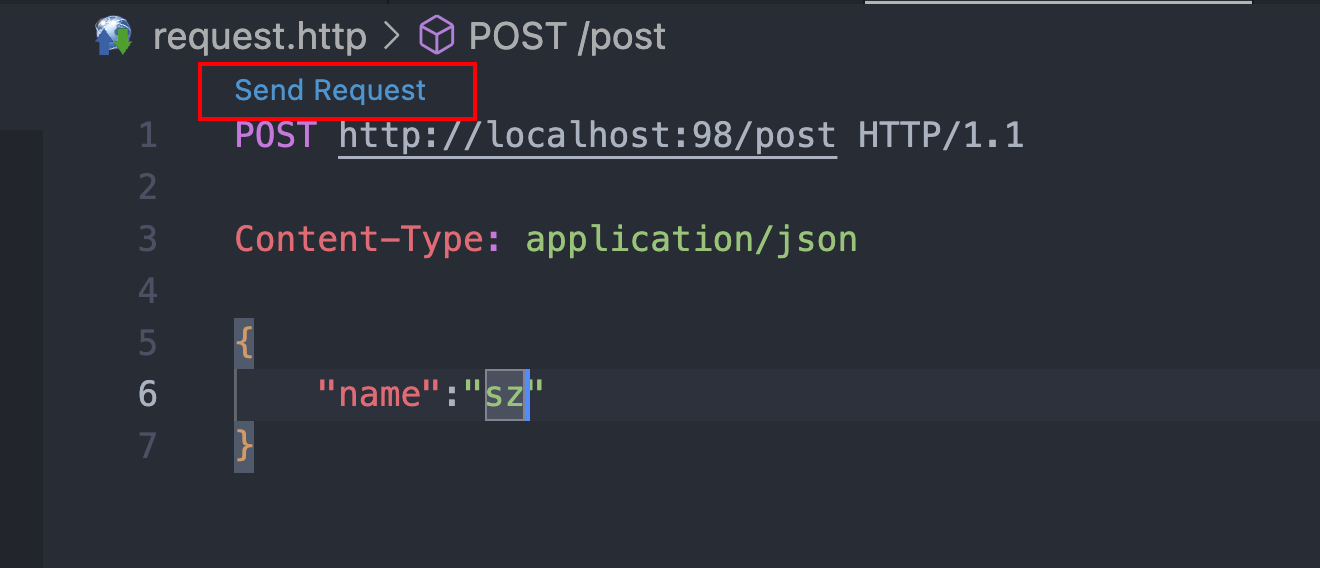
填写完毕,点击Send Request
安装完成之后编写简易的代码就可以直接发送请求了
[POST | GET | PUT] [URL] [http版本]
[请求头]
[传递的数据]
# POST http://localhost:98/post/xxx HTTP/1.1
# Content-Type: application/json
# {
# "name":"sz"
# }
GET http://localhost:98/get?a=1&b=2 HTTP/1.1
http(反向代理)
概念
什么是反向代理?
反向代理(Reverse Proxy)是一种网络通信模式,它充当服务器和客户端之间的中介,将客户端的请求转发到一个或多个后端服务器,并将后端服务器的响应返回给客户端。
- 负载均衡:反向代理可以根据预先定义的算法将请求分发到多个后端服务器,以实现负载均衡。这样可以避免某个后端服务器过载,提高整体性能和可用性。
- 高可用性:通过反向代理,可以将请求转发到多个后端服务器,以提供冗余和故障转移。如果一个后端服务器出现故障,代理服务器可以将请求转发到其他可用的服务器,从而实现高可用性。
- 缓存和性能优化:反向代理可以缓存静态资源或经常访问的动态内容,以减轻后端服务器的负载并提高响应速度。它还可以通过压缩、合并和优化资源等技术来优化网络性能。
- 安全性:反向代理可以作为防火墙,保护后端服务器免受恶意请求和攻击。它可以过滤恶意请求、检测和阻止攻击,并提供安全认证和访问控制。
- 域名和路径重写:反向代理可以根据特定的规则重写请求的域名和路径,以实现 URL 路由和重定向。这对于系统架构的灵活性和可维护性非常有用。
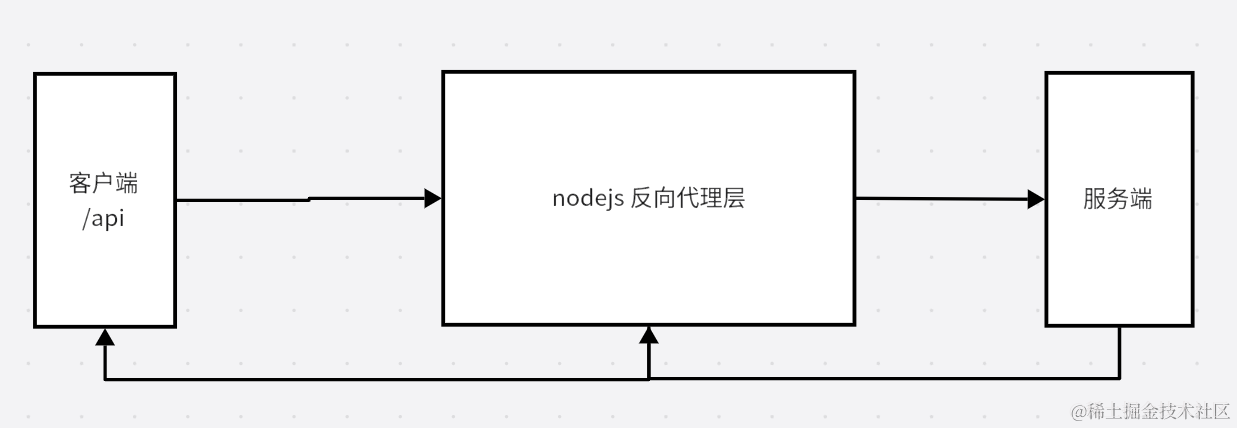 ## 代码实现
## 代码实现
用到的库
http-proxy-middleware
npm install http-proxy-middleware
根目录自定义配置文件
sz.config.js
配置proxy代理
module.exports = {
server:{
proxy:{
//代理的路径
'/api': {
target: 'http://localhost:3000', //转发的地址
changeOrigin: true, //是否有跨域
}
}
}
}
index.js实现层
const http = require('node:http');
const fs = require('node:fs')
const url = require('node:url')
const html = fs.readFileSync('./index.html') //给html文件起个服务
const {createProxyMiddleware} = require('http-proxy-middleware')
const config = require('./sz.config.js')
//将index.html文件与服务进行挂钩
const server = http.createServer((req, res) => {
const {pathname} = url.parse(req.url)
const proxyList = Object.keys(config.server.proxy) //获取代理的路径
if(proxyList.includes(pathname)){ //如果请求的路径在里面匹配到 就进行代理
const proxy = createProxyMiddleware(config.server.proxy[pathname]) //代理
proxy(req,res)
return
}
console.log(proxyList)
res.writeHead(200, {
'Content-Type': 'text/html'
})
res.end(html) //返回html
})
server.listen(80) //监听端口
test.js 因为我们从80端口转发到3000端口
const http = require('node:http')
const url = require('node:url')
http.createServer((req, res) => {
const {pathname} = url.parse(req.url)
if(pathname === '/api'){
res.end('success proxy')
}
}).listen(3000)
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script>
fetch('/api').then(res=>res.text()).then(res=>{
console.log(res);
})
</script>
</body>
</html>
这样就从80代理到了3000端口 并且无跨域
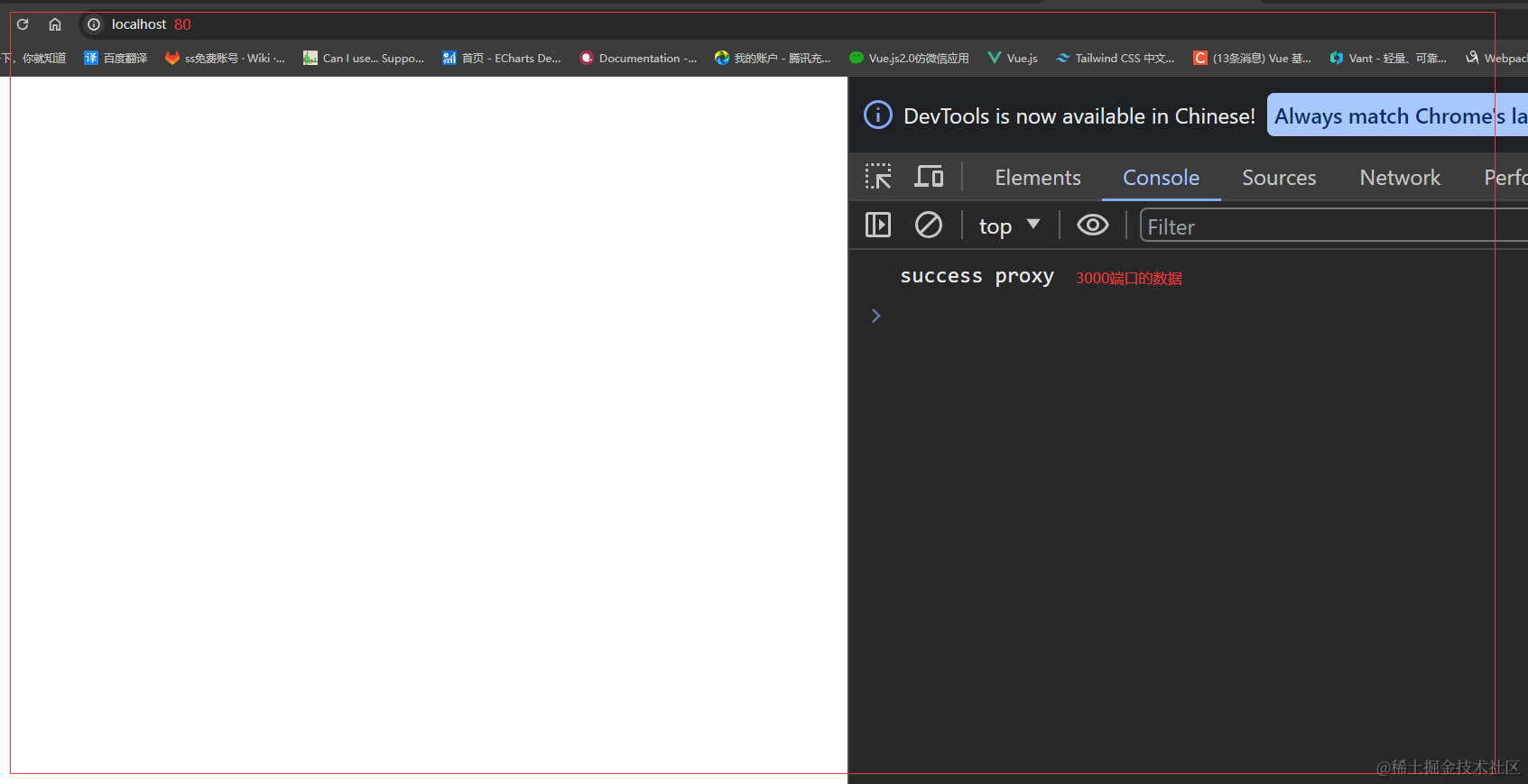
http(动静分离)
概念
什么是动静分离?
动静分离是一种在Web服务器架构中常用的优化技术,旨在提高网站的性能和可伸缩性。它基于一个简单的原则:将动态生成的内容(如动态网页、API请求)与静态资源(如HTML、CSS、JavaScript、图像文件)分开处理和分发。
通过将动态内容和静态资源存储在不同的服务器或服务上,并使用不同的处理机制,可以提高网站的处理效率和响应速度。这种分离的好处包括:
- 性能优化:将静态资源与动态内容分离可以提高网站的加载速度。由于静态资源往往是不变的,可以使用缓存机制将其存储在CDN(内容分发网络)或浏览器缓存中,从而减少网络请求和数据传输的开销。
- 负载均衡:通过将动态请求分发到不同的服务器或服务上,可以平衡服务器的负载,提高整个系统的可伸缩性和容错性。
- 安全性:将动态请求与静态资源分开处理可以提高系统的安全性。静态资源通常是公开可访问的,而动态请求可能涉及敏感数据或需要特定的身份验证和授权。通过将静态资源与动态内容分离,可以更好地管理访问控制和安全策略
实现动静分离的方法
使用反向代理服务器(如Nginx、Apache)将静态请求和动态请求转发到不同的后端服务器或服务。
将静态资源部署到CDN上,通过CDN分发静态资源,减轻源服务器的负载。
使用专门的静态文件服务器(如Amazon S3、Google Cloud Storage)存储和提供静态资源,而将动态请求交给应用服务器处理。
代码事例
下面是一个使用Node.js编写的示例代码,演示了如何处理动静分离的请求:
import http from 'node:http' // 导入http模块
import fs from 'node:fs' // 导入文件系统模块
import path from 'node:path' // 导入路径处理模块
import mime from 'mime' // 导入mime模块
const server = http.createServer((req, res) => {
const { url, method } = req
// 处理静态资源
if (method === 'GET' && url.startsWith('/static')) {
const filePath = path.join(process.cwd(), url) // 获取文件路径
const mimeType = mime.getType(filePath) // 获取文件的MIME类型
console.log(mimeType) // 打印MIME类型
fs.readFile(filePath, (err, data) => { // 读取文件内容
if (err) {
res.writeHead(404, {
"Content-Type": "text/plain" // 设置响应头为纯文本类型
})
res.end('not found') // 返回404 Not Found
} else {
res.writeHead(200, {
"Content-Type": mimeType, // 设置响应头为对应的MIME类型
"Cache-Control": "public, max-age=3600" // 设置缓存控制头
})
res.end(data) // 返回文件内容
}
})
}
// 处理动态资源
if ((method === 'GET' || method === 'POST') && url.startsWith('/api')) {
// ...处理动态资源的逻辑
}
})
server.listen(80) // 监听端口80
因为每个文件所对应的mime类型都不一样,如果手写的话有很多,不过强大的nodejs社区提供了mime库,可以帮我们通过后缀直接分析出 所对应的mime类型,然后我们通过强缓存让浏览器缓存静态资源
常见的mime类型展示
- 文本文件:
- text/plain:纯文本文件
- text/html:HTML 文件
- text/css:CSS 样式表文件
- text/javascript:JavaScript 文件
- application/json:JSON 数据
- 图像文件:
- image/jpeg:JPEG 图像
- image/png:PNG 图像
- image/gif:GIF 图像
- image/svg+xml:SVG 图像
- 音频文件:
- audio/mpeg:MPEG 音频
- audio/wav:WAV 音频
- audio/midi:MIDI 音频
- 视频文件:
- video/mp4:MP4 视频
- video/mpeg:MPEG 视频
- video/quicktime:QuickTime 视频
- 应用程序文件:
- application/pdf:PDF 文件
- application/zip:ZIP 压缩文件
- application/x-www-form-urlencoded:表单提交数据
- multipart/form-data:多部分表单数据
http(邮件服务)
邮件服务充当的角色
- 任务分配与跟踪:邮件服务可以用于分配任务、指派工作和跟踪项目进展。通过邮件,可以发送任务清单、工作说明和进度更新,确保团队成员了解其责任和任务要求,并监控工作的完成情况。
- 错误报告和故障排除:当程序出现错误或异常时,程序员可以通过邮件将错误报告发送给团队成员或相关方。这样可以帮助团队了解问题的性质、复现步骤和相关环境,从而更好地进行故障排除和修复。邮件中可以提供详细的错误消息、堆栈跟踪和其他相关信息,以便其他团队成员能够更好地理解问题并提供解决方案。
- 自动化构建和持续集成:在持续集成和自动化构建过程中,邮件服务可以用于通知团队成员构建状态、单元测试结果和代码覆盖率等信息。如果构建失败或出现警告,系统可以自动发送邮件通知相关人员,以便及时采取相应措施。
代码编写
需要用到库
npm install js-yaml
npm install nodemailer
我们邮件的账号(密码| 授权码)不可能明文写到代码里面一般存放在yaml文件或者环境变量里面
js-yaml 解析yaml文件
pass: 授权码 | 密码
user: xxxxx@qq.com 邮箱账号
import nodemailder from 'nodemailer'
import yaml from 'js-yaml'
import fs from 'node:fs'
import http from 'node:http'
import url from 'node:url'
const mailConfig = yaml.load(fs.readFileSync('./mail.yaml', 'utf8'))
const transPort = nodemailder.createTransport({
service: "qq",
port: 587,
host: 'smtp.qq.com',
secure: true,
auth: {
pass: mailConfig.pass,
user: mailConfig.user
}
})
http.createServer((req, res) => {
const { pathname } = url.parse(req.url)
if (req.method === 'POST' && pathname == '/send/mail') {
let mailInfo = ''
req.on('data', (chunk) => {
mailInfo += chunk.toString()
})
req.on('end', () => {
const body = JSON.parse(mailInfo)
transPort.sendMail({
to: body.to,
from: mailConfig.user,
subject: body.subject,
text: body.text
})
res.end('ok')
})
}
}).listen(3000)
nodemailder.createTransport 创建邮件服务这里用qq举例,
QQ邮件服务文档
POP3/SMTP 设置方法
用户名/帐户: 你的QQ邮箱完整的地址
密码: 生成的授权码
电子邮件地址: 你的QQ邮箱的完整邮件地址
接收邮件服务器: pop.qq.com,使用SSL,端口号995
发送邮件服务器: smtp.qq.com,使用SSL,端口号465或587
授权码生成
测试发送
POST http://localhost:3000/send/mail HTTP/1.1
Content-Type: application/json
{
"to":"xxxxx@qq.com",
"subject":"标题",
"text":"我想你了,你还好吗Rong"
}
express
基本用法
概念
什么是express?
Express是一个流行的Node.js Web应用程序框架,用于构建灵活且可扩展的Web应用程序和API。它是基于Node.js的HTTP模块而创建的,简化了处理HTTP请求、响应和中间件的过程。
简洁而灵活:Express提供了简单而直观的API,使得构建Web应用程序变得简单快捷。它提供了一组灵活的路由和中间件机制,使开发人员可以根据需求定制和组织应用程序的行为。
路由和中间件:Express使用路由和中间件来处理HTTP请求和响应。开发人员可以定义路由规则,将特定的URL路径映射到相应的处理函数。同时,中间件允许开发人员在请求到达路由处理函数之前或之后执行逻辑,例如身份验证、日志记录和错误处理。
路由模块化:Express支持将路由模块化,使得应用程序可以根据不同的功能或模块进行分组。这样可以提高代码的组织性和可维护性,使得多人协作开发更加便捷。
视图引擎支持:Express可以与各种模板引擎集成,例如EJS、Pug(以前称为Jade)、Handlebars等。这使得开发人员可以方便地生成动态的HTML页面,并将数据动态渲染到模板中。
中间件生态系统:Express有一个庞大的中间件生态系统,开发人员可以使用各种中间件来扩展和增强应用程序的功能,例如身份验证、会话管理、日志记录、静态文件服务等。
编码
- 启动一个http服务
import express from 'express';
const app = express() //express 是个函数
app.listen(3000, () => console.log('Listening on port 3000'))
- 编写get post接口
app.get('/', (req, res) => {
res.send('get')
})
app.post('/create', (req, res) => {
res.send('post')
})
- 接受前端的参数
app.use(express.json()) //如果前端使用的是post并且传递json 需要注册此中间件 不然是undefined
app.get('/', (req, res) => {
console.log(req.query) //get 用query
res.send('get')
})
app.post('/create', (req, res) => {
console.log(req.body) //post用body
res.send('post')
})
//如果是动态参数用 params
app.get('/:id', (req, res) => {
console.log(req.params)
res.send('get id')
})
模块化
我们正常开发的时候肯定不会把代码写到一个模块里面,Express允许将路由处理程序拆分为多个模块,每个模块负责处理特定的路由。通过将路由处理程序拆分为模块,可以使代码逻辑更清晰,易于维护和扩展
src
--user.js
--list.js
app.js
src/user.js
import express from 'express'
const router = express.Router() //路由模块
router.post('/login', (req, res) => {
res.send('login')
})
router.post('/register', (req, res) => {
res.send('register')
})
export default router
app.js
import express from 'express';
import User from './src/user.js'
const app = express()
app.use(express.json())
app.use('/user', User)
app.get('/', (req, res) => {
console.log(req.query)
res.send('get')
})
app.get('/:id', (req, res) => {
console.log(req.params)
res.send('get id')
})
app.post('/create', (req, res) => {
console.log(req.body)
res.send('post')
})
app.listen(3000, () => console.log('Listening on port 3000'))
中间件
中间件是一个关键概念。中间件是处理HTTP请求和响应的函数,它位于请求和最终路由处理函数之间,可以对请求和响应进行修改、执行额外的逻辑或者执行其他任务。
中间件函数接收三个参数:req(请求对象)、res(响应对象)和next(下一个中间件函数)。通过调用next()方法,中间件可以将控制权传递给下一个中间件函数。如果中间件不调用next()方法,请求将被中止,不会继续传递给下一个中间件或路由处理函数
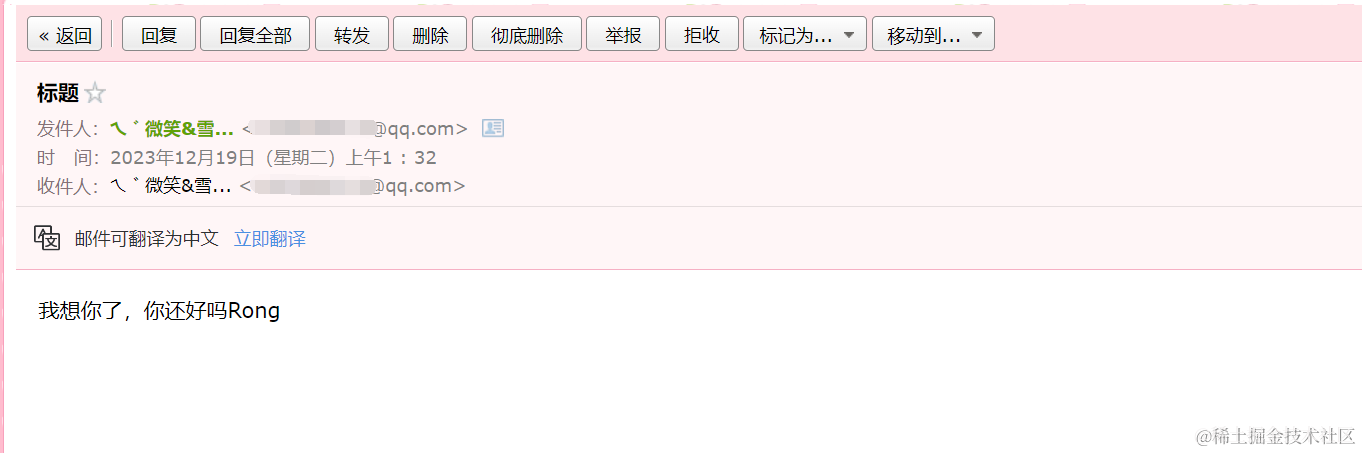
- 实现一个日志中间件
npm install log4js
log4js是一个用于Node.js应用程序的流行的日志记录库,它提供了灵活且可配置的日志记录功能。log4js允许你在应用程序中记录不同级别的日志消息,并可以将日志消息输出到多个目标,如控制台、文件、数据库等
express\middleware\logger.js
import log4js from 'log4js';
// 配置 log4js
log4js.configure({
appenders: {
out: {
type: 'stdout', // 输出到控制台
layout: {
type: 'colored' // 使用带颜色的布局
}
},
file: {
type: 'file', // 输出到文件
filename: './logs/server.log', // 指定日志文件路径和名称
}
},
categories: {
default: {
appenders: ['out', 'file'], // 使用 out 和 file 输出器
level: 'debug' // 设置日志级别为 debug
}
}
});
// 获取 logger
const logger = log4js.getLogger('default');
// 日志中间件
const loggerMiddleware = (req, res, next) => {
logger.debug(`${req.method} ${req.url}`); // 记录请求方法和URL
next();
};
export default loggerMiddleware;
app.js
import express from 'express';
import User from './src/user.js'
import loggerMiddleware from './middleware/logger.js';
const app = express()
app.use(loggerMiddleware)
防盗链
概念
防盗链(Hotlinking)是指在网页或其他网络资源中,通过直接链接到其他网站上的图片、视频或其他媒体文件,从而显示在自己的网页上。这种行为通常会给被链接的网站带来额外的带宽消耗和资源浪费,而且可能侵犯了原始网站的版权。
防盗措施
为了防止盗链,网站管理员可以采取一些措施:
- 通过HTTP引用检查:网站可以检查HTTP请求的来源,如果来源网址与合法的来源不匹配,就拒绝提供资源。这可以通过服务器配置文件或特定的脚本实现。
- 使用Referrer检查:网站可以检查HTTP请求中的Referrer字段,该字段指示了请求资源的来源页面。如果Referrer字段不符合预期,就拒绝提供资源。这种方法可以在服务器配置文件或脚本中实现。
- 使用访问控制列表(ACL):网站管理员可以配置服务器的访问控制列表,只允许特定的域名或IP地址访问资源,其他来源的请求将被拒绝。
- 使用防盗链插件或脚本:一些网站平台和内容管理系统提供了专门的插件或脚本来防止盗链。这些工具可以根据需要配置,阻止来自未经授权的网站的盗链请求。
- 使用水印技术:在图片或视频上添加水印可以帮助识别盗链行为,并提醒用户资源的来源。
编码
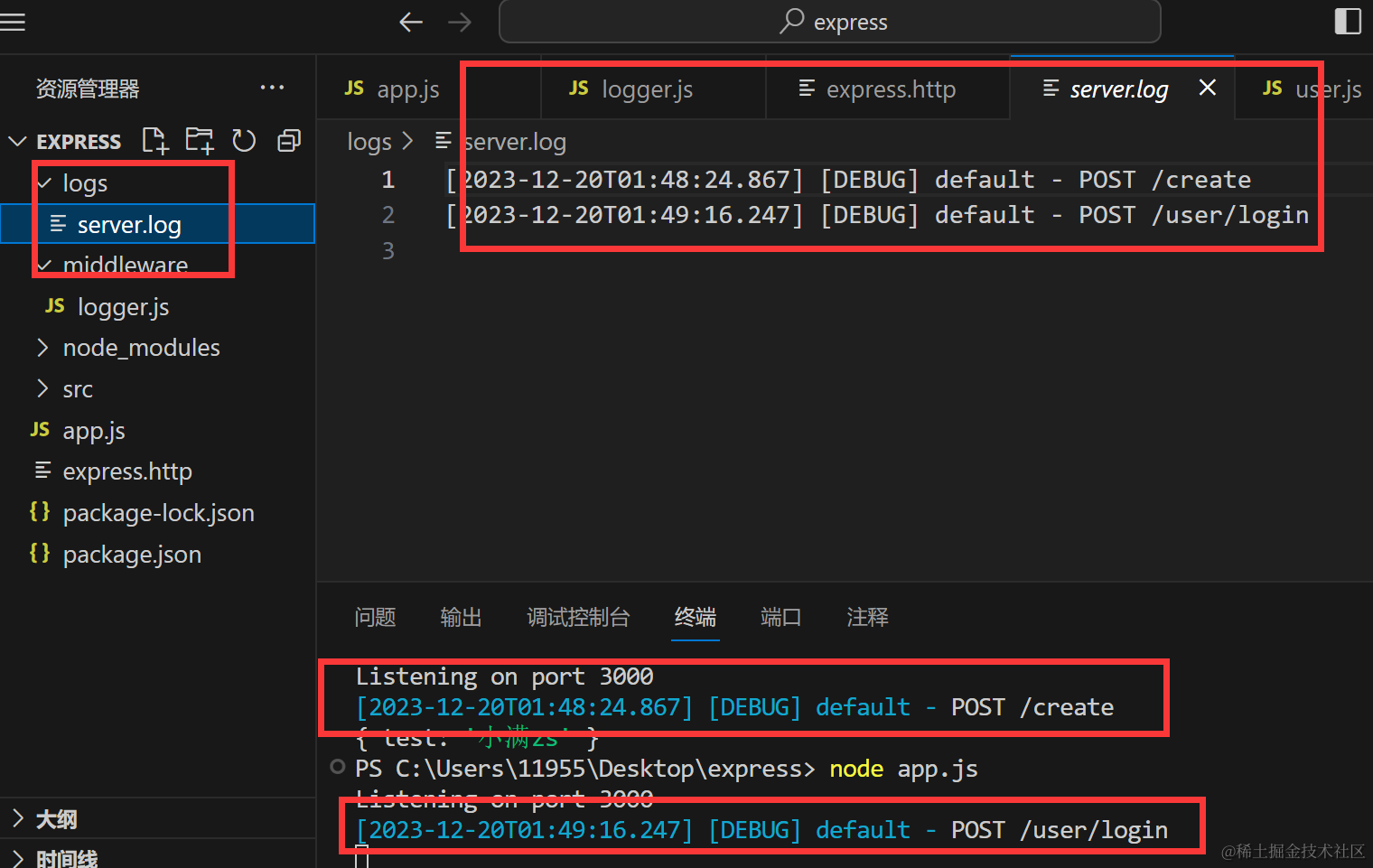
- 第一步需要初始化静态资源目录
express.static
import express from 'express'
const app = express()
//自定义前缀 初始化目录
app.use('/assets',express.static('static'))
app.listen(3000,()=>{
console.log('listening on port 3000')
})
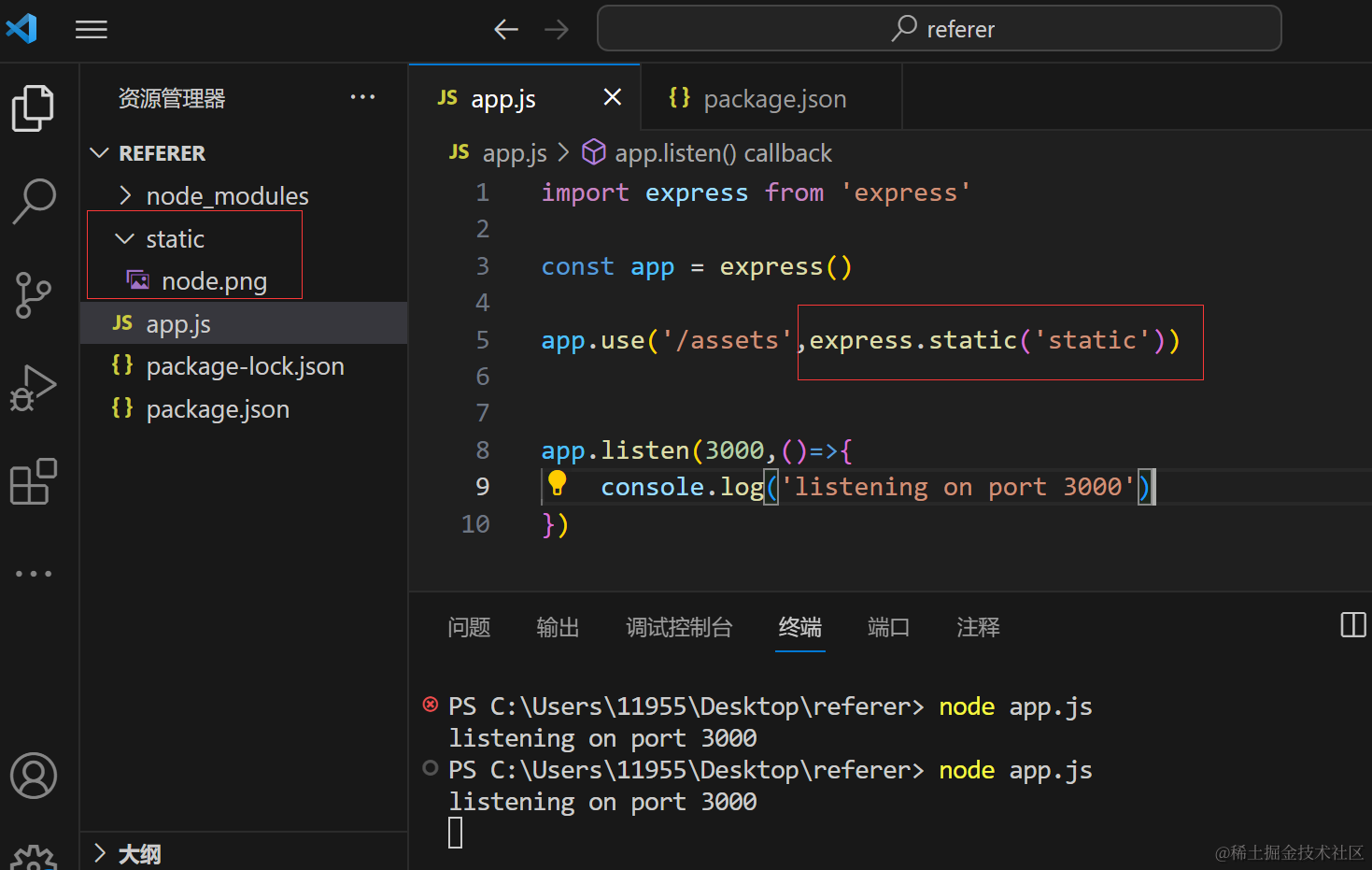

增加防盗链
防盗链一般主要就是验证host 或者 referer
import express from 'express';
const app = express();
const whitelist = ['localhost'];
// 防止热链中间件
const preventHotLinking = (req, res, next) => {
const referer = req.get('referer'); // 获取请求头部中的 referer 字段
if (referer) {
const { hostname } = new URL(referer); // 从 referer 中解析主机名
if (!whitelist.includes(hostname)) { // 检查主机名是否在白名单中
res.status(403).send('Forbidden'); // 如果不在白名单中,返回 403 Forbidden
return;
}
}
next(); // 如果在白名单中,继续处理下一个中间件或路由
};
app.use(preventHotLinking); // 应用防止热链中间件
app.use('/assets', express.static('static')); // 处理静态资源请求
app.listen(3000, () => {
console.log('Listening on port 3000'); // 启动服务器,监听端口3000
});
127.0.0.1 无权限
localhost 有权限
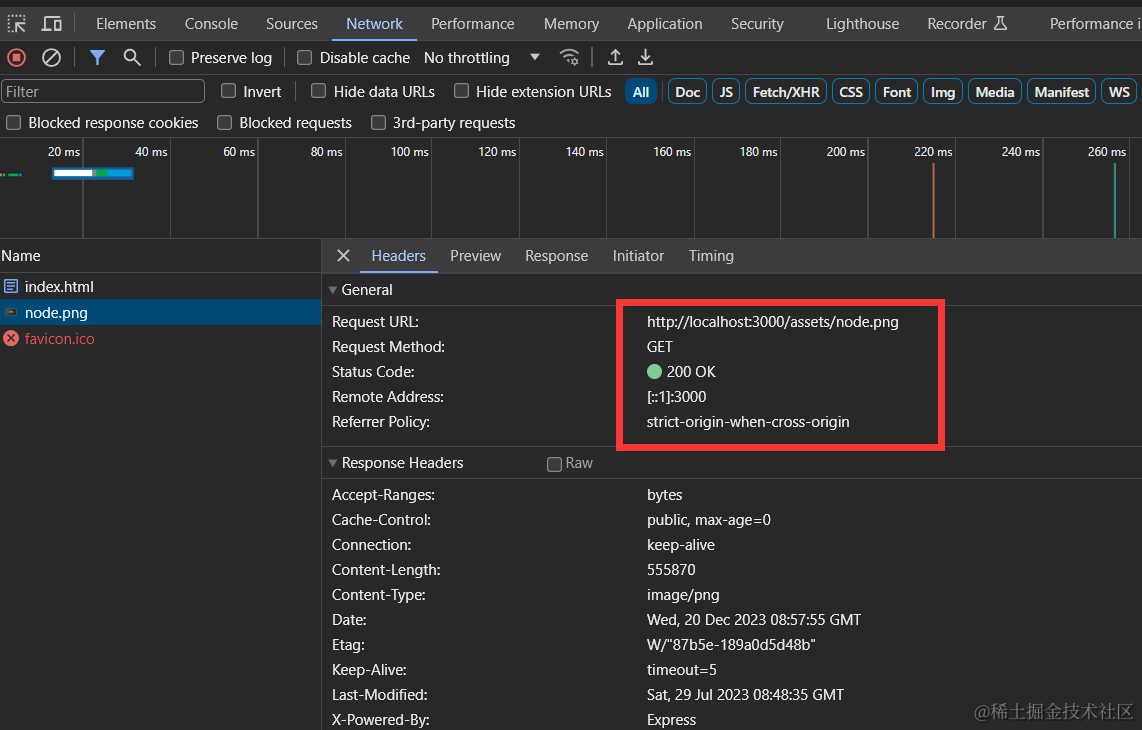
响应头和请求头
响应头
HTTP响应头(HTTP response headers)是在HTTP响应中发送的元数据信息,用于描述响应的特性、内容和行为。它们以键值对的形式出现,每个键值对由一个标头字段(header field)和一个相应的值组成。
例如以下示例
Access-Control-Allow-Origin:*
Cache-Control:public, max-age=0, must-revalidate
Content-Type:text/html; charset=utf-8
Server:nginx
Date:Mon, 08 Jan 2024 18:32:47 GMT
响应头和跨域之间的关系
- cors
跨域资源共享(Cross-Origin Resource Sharing,CORS)是一种机制,用于在浏览器中实现跨域请求访问资源的权限控制。当一个网页通过 XMLHttpRequest 或 Fetch API 发起跨域请求时,浏览器会根据同源策略(Same-Origin Policy)进行限制。同源策略要求请求的源(协议、域名和端口)必须与资源的源相同,否则请求会被浏览器拒绝
- 发送请求
fetch('http://localhost:3000/info').then(res=>{
return res.json()
}).then(res=>{
console.log(res)
})
- express 编写一个get接口
import express from 'express'
const app = express()
app.get('/info', (req, res) => {
res.json({
code: 200
})
})
app.listen(3000, () => {
console.log('http://localhost:3000')
})
发现是有报错的 根据同源策略我们看到协议一样,域名一样,但是端口不一致,端口也无法一致,会有冲突,否则就是前后端不分离的项目,前后端代码放在一起,只用一个端口,不过我们是分离的没法这么做。
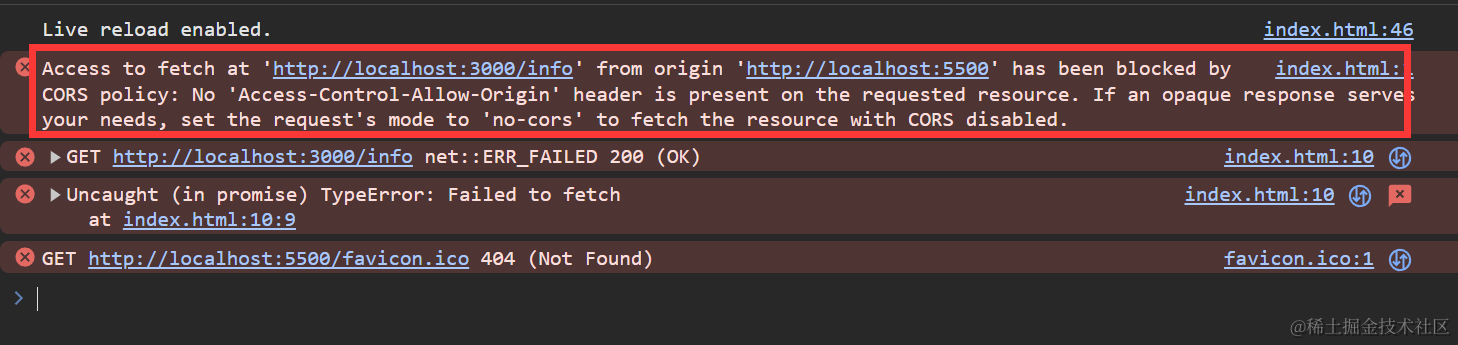
这时候我们就需要后端支持一下,跨域请求资源放行
Access-Control-Allow-Origin: * | Origin
增加以下响应头 允许localhost 5500 访问
app.use('*',(req,res,next)=>{
res.setHeader('Access-Control-Allow-Origin','http://localhost:5500') //允许localhost 5500 访问
next()
})
结果返回
请求头
默认情况下cors仅支持客户端向服务器发送如下九个请求头
tips 没有application/json
- Accept:指定客户端能够处理的内容类型。
- Accept-Language:指定客户端偏好的自然语言。
- Content-Language:指定请求或响应实体的自然语言。
- Content-Type:指定请求或响应实体的媒体类型。
- DNT (Do Not Track):指示客户端不希望被跟踪。
- Origin:指示请求的源(协议、域名和端口)。
- User-Agent:包含发起请求的用户代理的信息。
- Referer:指示当前请求的源 URL。
Content-type: application/x-www-form-urlencoded | multipart/form-data | text/plain
如果客户端需要支持额外的请求那么我们需要在客户端支持
'Access-Control-Allow-Headers','Content-Type' //支持application/json
请求方法支持
我们服务端默认只支持 GET POST HEAD OPTIONS 请求
例如我们遵循restFui 要支持PATCH 或者其他请求
增加patch
app.patch('/info', (req, res) => {
res.json({
code: 200
})
})
发送patch
fetch('http://localhost:3000/info',{
method:'PATCH',
}).then(res=>{
return res.json()
}).then(res=>{
console.log(res)
})
发现报错说patch不在我们的methods里面

修改如下
'Access-Control-Allow-Methods','POST,GET,OPTIONS,DELETE,PATCH'

预检请求 OPTIONS
预检请求的主要目的是确保跨域请求的安全性 它需要满足一定条件才会触发
- 自定义请求方法:当使用非简单请求方法(Simple Request Methods)时,例如 PUT、DELETE、CONNECT、OPTIONS、TRACE、PATCH 等,浏览器会发送预检请求。
- 自定义请求头部字段:当请求包含自定义的头部字段时,浏览器会发送预检请求。自定义头部字段是指不属于简单请求头部字段列表的字段,例如 Content-Type 为 application/json、Authorization 等。
- 带凭证的请求:当请求需要在跨域环境下发送和接收凭证(例如包含 cookies、HTTP 认证等凭证信息)时,浏览器会发送预检请求。
- 尝试发送预检请求
fetch('http://localhost:3000/info',{
method:'POST',
headers:{
'Content-Type':'application/json'
},
body:JSON.stringify({name:'szzs'})
}).then(res=>{
return res.json()
}).then(res=>{
console.log(res)
})















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









