







记fofa爬虫工具开发篇
前沿
开发这个工具的原因单纯是在 大一(目前已经大三了)的时候 ,在用fofa搜索时,只能 搜索到 前 5 页,而且 github 上也找不到一个好点的爬虫,全是需要
会员的,我就想着弄一个 在不同城市之前收集目标,这样不仅仅 只有 50 条了(如下图),每个国家 的每个城市分别爬取50条那么 一条查询语句至少,得有 500条吧 也是受到一款工具的启发(那个大哥的博客找不到了)而且 fofa的域名更改后,就找不到一个像样的爬虫工具了,要么需要手动 要么 只能爬取5页,真low 所以基于这种现实问题开发了一个爬虫工具(现在高级会员可以直接下载10000条哈哈哈哈,噶,嗯 这个工具如果开注册会员的话 完美代替高级会员,如果你钱多当我没说,哈哈哈)那么接下来就开搞
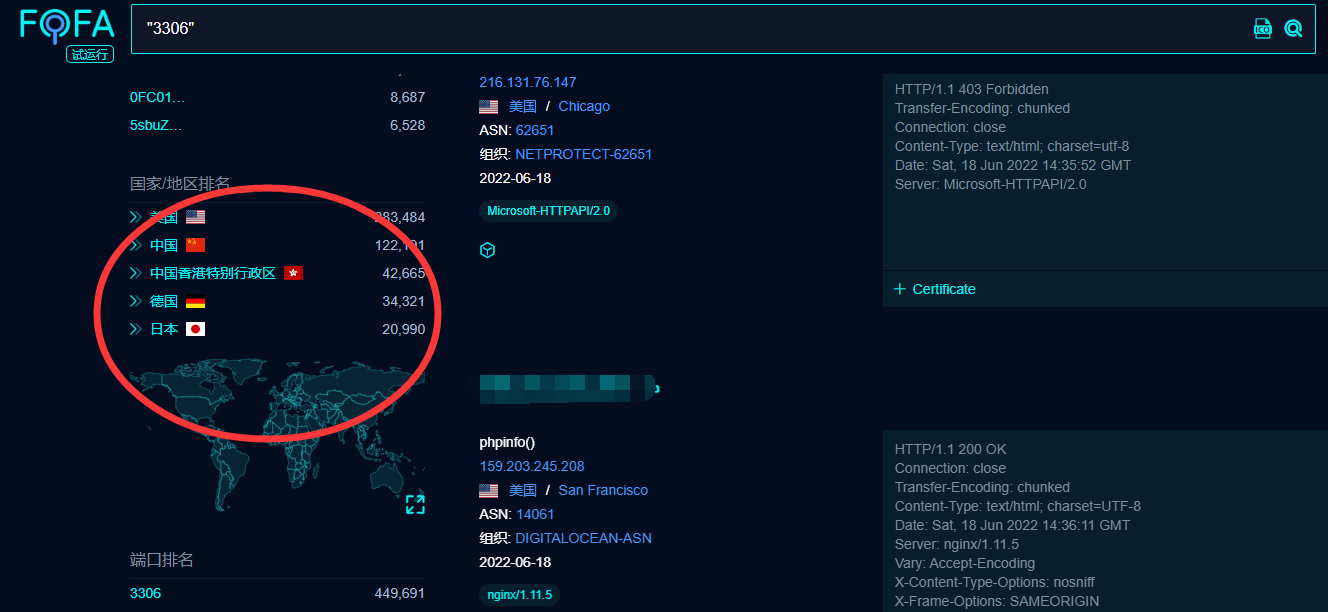
爬取的平台
目前有两个 fofaapp、fofaapi(这个写的太low了。。。。还是用别人写好了的吧 我这里给个链接 https://github.com/wgpsec/fofa_viewer 还是挺牛逼了别的不说)fofaapp 这个呢 就是面向 没钱的小朋友哈,我就属于其中的小朋友,所以我就有的摆了,来来来 下面说重点了
步骤
1. 爬取个人网页
我的思路跟上面前沿介绍的需求差不多嘛,先 请求一次 检查一下cookies的正确性,请求https://fofa.info/personalData 把相关的信息拿到 主要的信息就是用户组(没钱的组)
def getUserinfo(self):
"""
:return: 个人信息
"""
userinfo = {
}
requrl = self.url + '/personalData'
soup = self.getDriverSoup(requrl, True)
tags = soup.find_all(name="div", attrs={
"class": "personList"})
apiTag = soup.find(name="span", attrs={
"class": "apikeynumber"})
try:
if tags and apiTag:
userinfo['username'] = tags[1].contents[2].string
userinfo['useremail'] = tags[2].contents[2].string
userinfo['usergroup'] = tags[4].contents[2].string
userinfo['userApikey'] = apiTag.string.strip()
if (tags is None) or \
(userinfo['username'] is None) or \
(userinfo['useremail'] is None) or \
(userinfo['usergroup'] is None) or \
(userinfo['userApikey'] is None):
raise
except:
loguru.logger.warning("登录失败,检查cookies")
userinfo['usergroup'] = "未登录用户"
userinfo['username'] = "未登录用户"
userinfo['useremail'] = "未登录用户"
userinfo['userApikey'] = "未登录用户"
finally:
printfUserinfo(userinfo['username'], userinfo['useremail']< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









