







文章目录

1. 如何停止正在运行的线程
- 设置一个共享变量作为线程退出的标记,当这个标记不满足时while循环,线程一直运行,另一个线程将这个共享变量设置为真,当然要保证两个线程间的可见性的话要加volatile,那这个一直运行的线程while不成立就会退出了,也就停止了
- interrupt打断线程,对于阻塞的线程的话(sleep、wait、join)会抛出异常,对于正常的线程的话我们判断打断标记,为ture的话表示被打断了,这时候break就能退出线程。
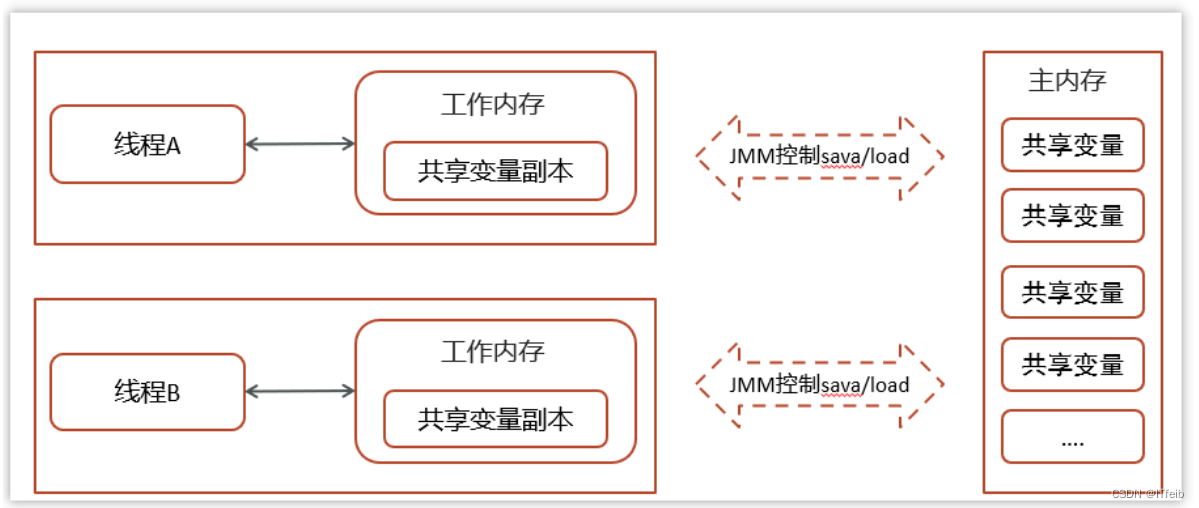
2. 请你谈谈JMM(java内存模型)
JMM定义了对我们定义的一些共享变量的访问的规则吧,其实就是在多线程的环境下怎么去正确的读写这些共享变量,JMM呢就提供了这种安全的保障,其实每一个线程都在自己的工作内存中去操作,工作内存中就是主存中的这些共享变量的副本,那就保证了当前这个线程的操作的正确性,但是要保证我们操作了工作内存后和主存数据的一致性,像volatile吧就其实也保证了别的线程读到了也是正确的 。

3. AQS
AQS,它是一种在并发的环境下的这种安全的队列吧,是一个并发的基础的一个框架吧,提供了这种锁的机制,像它也支持多个条件变量,条件不满足进入,以及这个先进先出的队列,争抢不到就会进入,内部的话其实它是一个双向链表,state属性呢就表示当前有没有获得锁,其实也是基于CAS机制实现的,像在Java中,它的子类的话ReentrantLock、Countdownlatch、信号量啊都是基于AQS实现的。
4. ReentrantLock实现原理
主要利用CAS+AQS实现
ReentrantLock 里面的加锁啊解锁啊这些其实都是调用AQS里面的相关的方法的,像加锁lock方法,AQS又有不同的实现比如说公平的非公平的,首先它会以CAS方式修改state状态,如果修改成功那就表示加锁成功,将Owner线程设置为当前这个线程,如果加锁失败,就会创建一个Node对象然后加入到队列中去,这个队列其实是一个双向链表,并且再将Node加入到队列的这部分代码中,它是一直循环的是一个死循环,它会记录当前节点的前驱节点,自己呢(线程)就park住,也就实现了加锁。解锁呢也是一样,也是调用AQS中的方法,将state设置为0,将owner线程设置为null,然后unpark恢复头节点后面的线程就是唤醒一个嘛,那这个线程就能接着在park住的位置继续执行,它是在一个死循环里面,然后又循环再获取锁,修改state状态修改owner线程。
5. 死锁怎么检测

6 ConcurrentHashMap
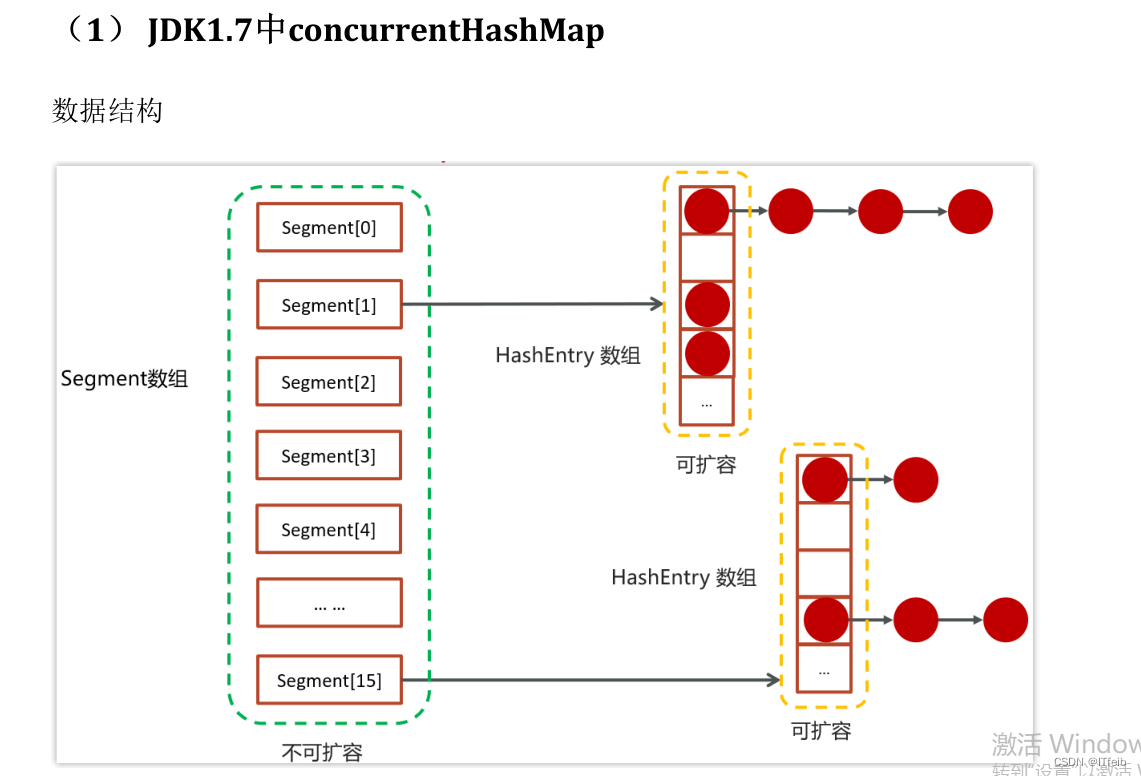
1.8 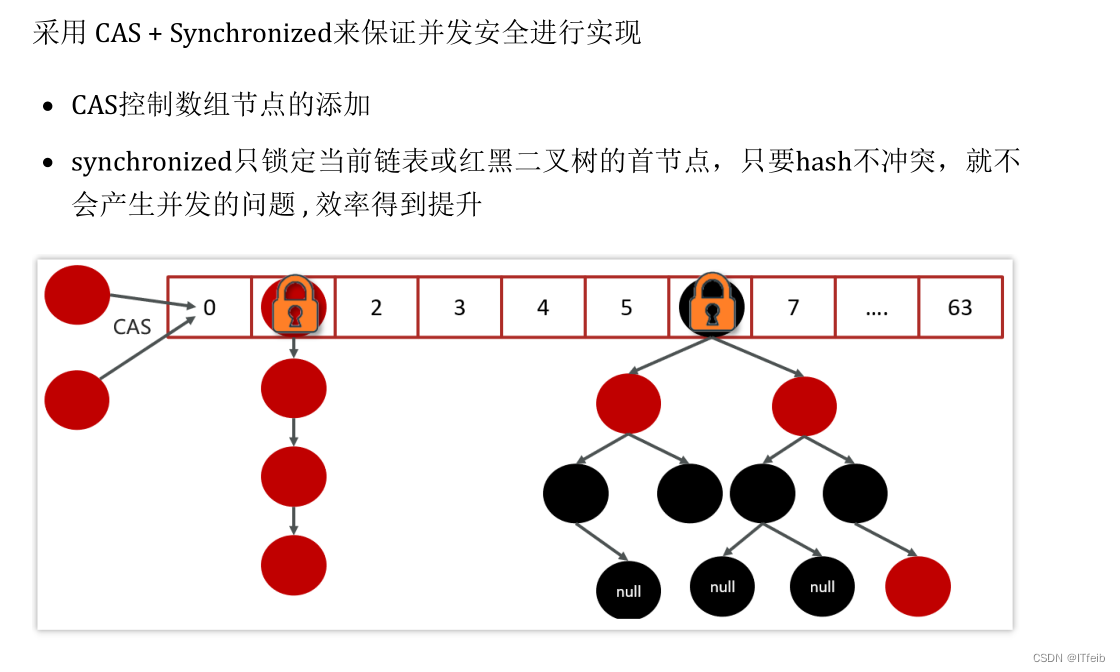
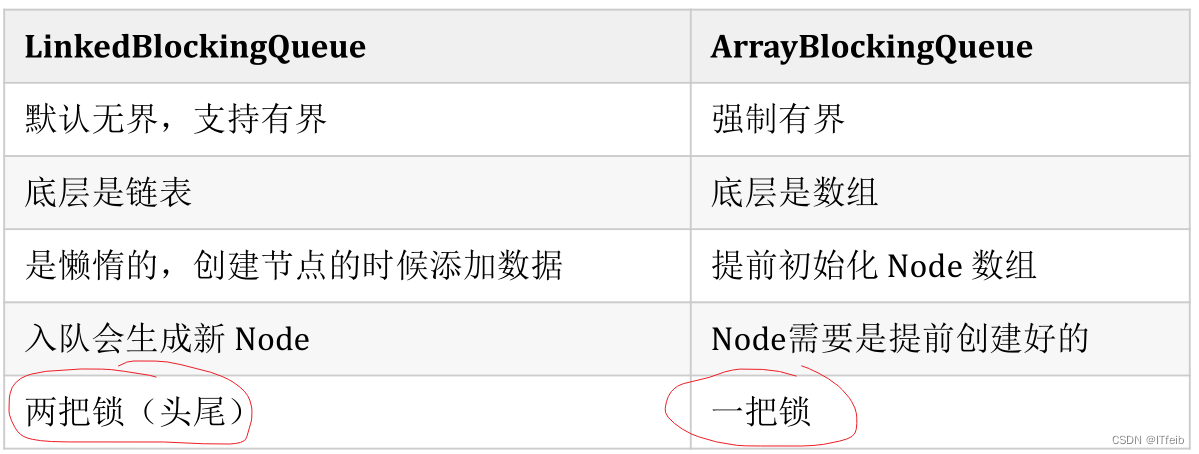
7 线程池中可以用哪些阻塞队列?
LinkedBlockQueue锁头尾,其实符合我们的需求,生产者放消费者取,不能说只能有一个操作,它两是可以同时操作的,ArrayBlockQueue只有一把锁,直接吧整个数组给锁住了,并发性不太好。
8 如何确定核心线程数

9. 为什么不建议用Executors创建线程池

10 线程池使用场景

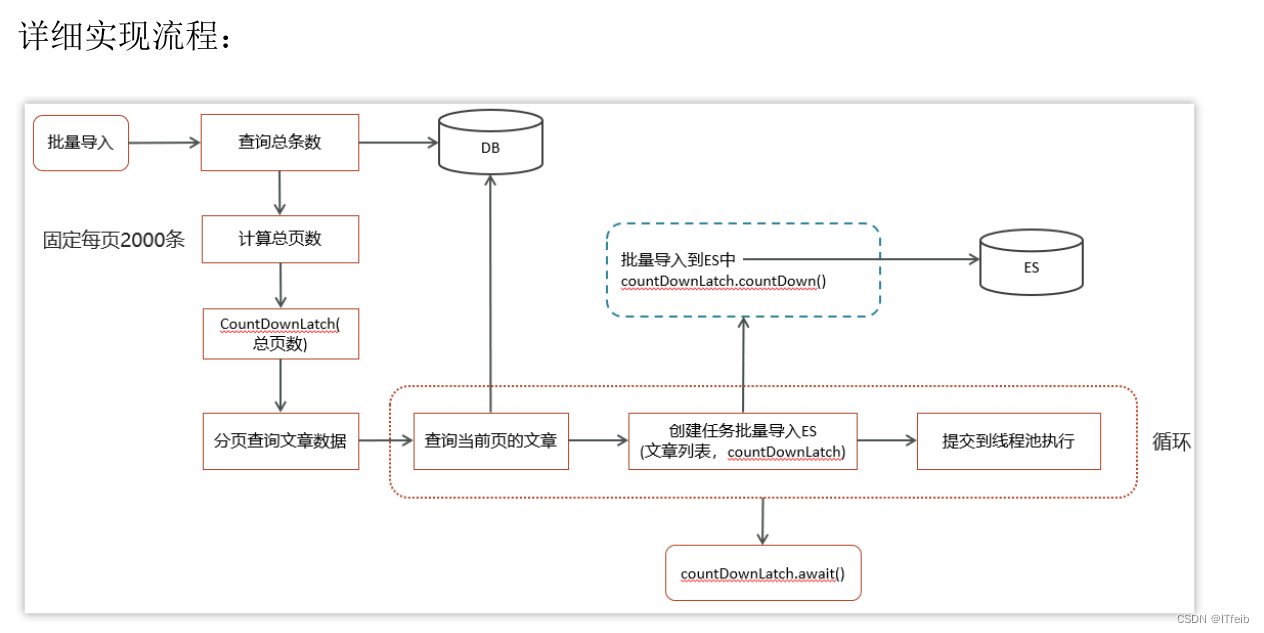
es数据批量导入:口述:比如说我们要同步数据库数据到es,数据量太大的话就用到了线程池和CountDownLatch,我们先查出有多少条记录,然后看看能分多少页,每页的数据同步就用到了线程池中的线程来同步,这页的数据同步完毕调用CountDownLatch。countDown,主线程这里调用CountDownLatch的await方法,当所有数据同步完那计数也就变为0了。


package com.itheima.cdl.service.impl;
import com.alibaba.fastjson.JSON;
import com.itheima.cdl.mapper.ApArticleMapper;
import com.itheima.cdl.pojo.SearchArticleVo;
import com.itheima.cdl.service.ApArticleService;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
@Service
@Transactional
@Slf4j
public class ApArticleServiceImpl implements ApArticleService {
@Autowired
private ApArticleMapper apArticleMapper;
@Autowired
private RestHighLevelClient client;
@Autowired
private ExecutorService executorService;
private static final String ARTICLE_ES_INDEX = "app_info_article";
private static final int PAGE_SIZE = 2000;
/**
* 批量导入
*/
@SneakyThrows
@Override
public void importAll() {
//总条数
int count = apArticleMapper.selectCount();
//总页数
int totalPageSize = count % PAGE_SIZE == 0 ? count / PAGE_SIZE : count / PAGE_SIZE + 1;
//开始执行时间
long startTime = System.currentTimeMillis();
//一共有多少页,就创建多少个CountDownLatch的计数
CountDownLatch countDownLatch = new CountDownLatch(totalPageSize);
int fromIndex;
List<SearchArticleVo> articleList = null;
for (int i = 0; i < totalPageSize; i++) {
//起始分页条数
fromIndex = i * PAGE_SIZE;
//查询文章
articleList = apArticleMapper.loadArticleList(fromIndex, PAGE_SIZE);
//创建线程,做批量插入es数据操作
TaskThread taskThread = new TaskThread(articleList, countDownLatch);
//执行线程
executorService.execute(taskThread);
}
//调用await()方法,用来等待计数归零
countDownLatch.await();
long endTime = System.currentTimeMillis();
log.info("es索引数据批量导入共:{}条,共消耗时间:{}秒", count, (endTime - startTime) / 1000);
}
class TaskThread implements Runnable {
List<SearchArticleVo> articleList;
CountDownLatch cdl;
public TaskThread(List<SearchArticleVo> articleList, CountDownLatch cdl) {
this.articleList = articleList;
this.cdl = cdl;
}
@SneakyThrows
@Override
public void run() {
//批量导入
BulkRequest bulkRequest = new BulkRequest(ARTICLE_ES_INDEX);
for (SearchArticleVo searchArticleVo : articleList) {
bulkRequest.add(new IndexRequest().id(searchArticleVo.getId().toString())
.source(JSON.toJSONString(searchArticleVo), XContentType.JSON));
}
//发送请求,批量添加数据到es索引库中
client.bulk(bulkRequest, RequestOptions.DEFAULT);
//让计数减一
cdl.countDown();
}
}
}
数据汇总:

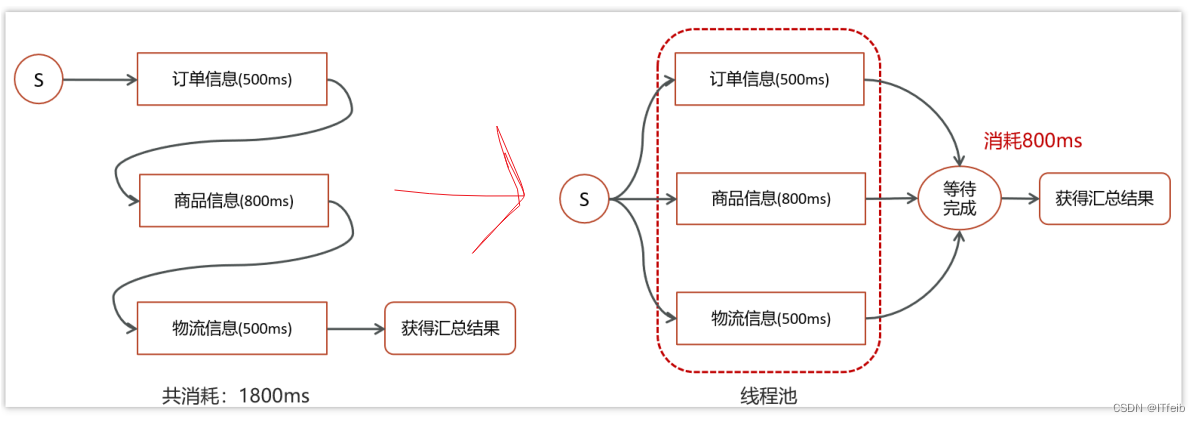

异步调用:

配合注解@Async开启异步调用。
11. 如何控制某个方法允许并发访问线程的数量

12. ThreadLocal
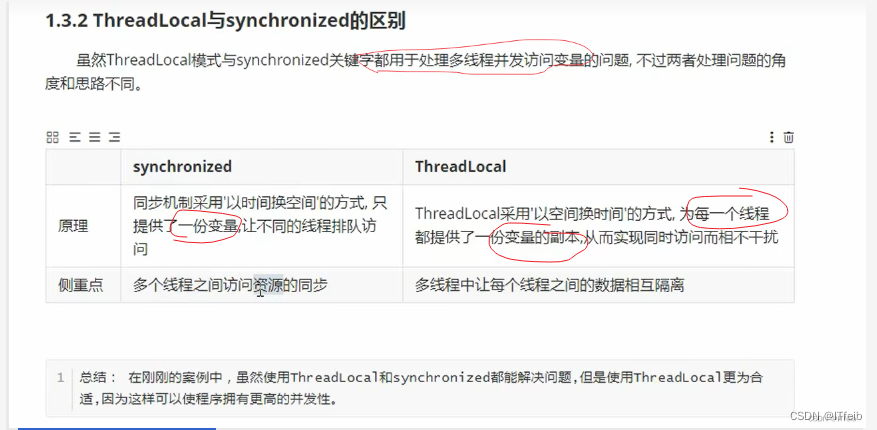
口述:ThreadLocal其实也是在并发的情况下对共享变量访问的一种方式吧,一种安全的方式吧,像加锁啊也能实现,只是说加锁的话其实是一种耗时的方式吧,这里的话其他线程就被挡外面了,那ThreadLocal其实是一种空间换时间的思想,其实就是将共享变量呢拷贝了一份,那对共享变量的访问肯定是安全的,它也是一种并发下的安全的保障吧。其实ThreadLocal它底层是用到了ThreadLocalMap,这个map呢在1.7之前呢是由ThreadLocal维护,在1.8之后呢是由Thread维护,map呢作为Thread的一个成员变量,map的生命周期就和线程是一样的,这样做的目的的话其实就是当线程销毁的时候map也能及时的销毁释放内存,而这个map中是维护了这样一个entry数组,并且我们存储的值呢就存储在数组中,是以key为ThreadLocal对象value值的这种形式存储的,而且这个key引用的ThreadLocal也是弱引用,也是为了尽量的去避免内存泄漏,我们在使用ThreadLocal的时候一定得去调用remove方法,来去释放掉entry,避免内存泄漏吧。
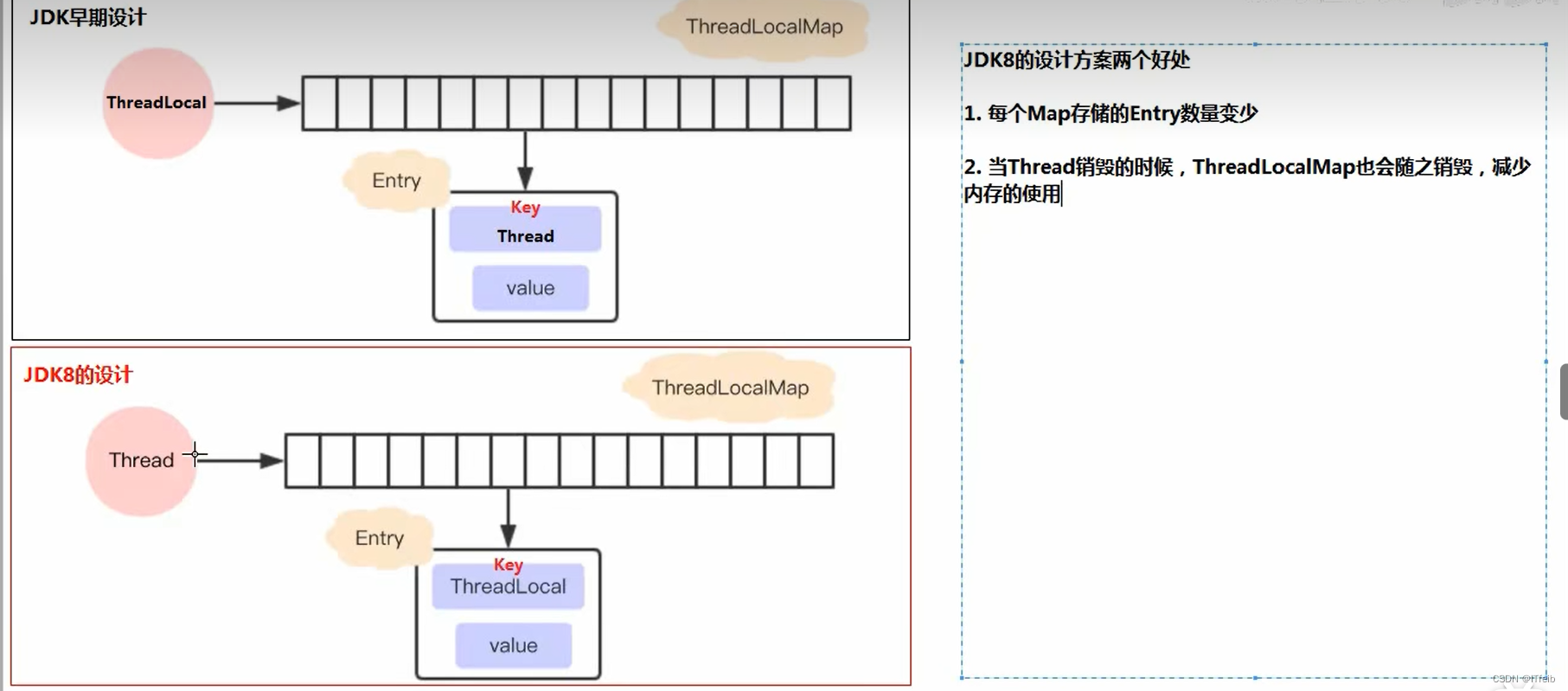
为什么不直接用线程id作为ThreadLocalMap的key呢?
口述:其实在1.7map中是采用线程id来作为key的,并且map是由ThreadLocal维护的,但是有些不足之后,在1.8也就做了改进,map是用ThreadLocal对象来作为key的,并且这个map是由Thread来维护,这样做的好处其实就是说如果我们有很多线程的话那entey中就得存好多个线程,开销有点大,key改为ThreadLocal对象的话不会出现很多的情况,那维护开销也就没那么大了,并且的话ThreadLocalMap改为了由Thread来维护,那就很好实现我们的需求吧,就是当Thread用完了要销毁的时候ThreadLocalMap也就销毁了。
entry的key为弱引用,目的是什么?
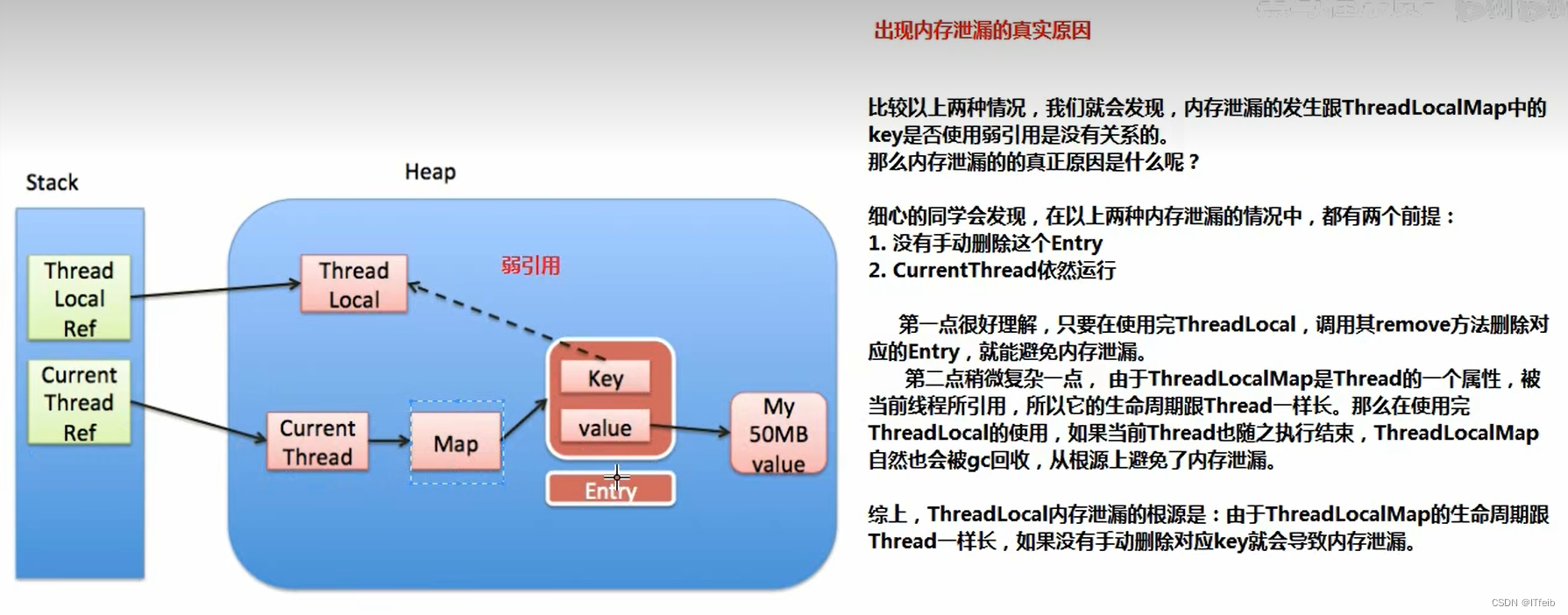
口述:其实设计成弱引用的目的也就是为了能及时的回收threadlocal对象吧,因为threadlocalMap它是由线程维护的,它作为thread的一个成员变量,map的生命周期和线程是一样的,map中的key它是指向threadlocal对象的,设计成弱引用其实也就是为了能及时的回收掉threadlocal对象,因为弱引用在下次GC就会被回收,那既然这个key指向的threadlocal对象被回收了,在下次调用threadlocal的get、set方法时,会将key为null的value也回收掉,也算是一种保障吧,避免内存泄漏的保障。

内存泄漏的本质是什么?当前线程没结束 + entry没删除。
口述:
内存泄漏和key的引用为强引用和弱引用没有关系,若是强引用即使ThreadLocal不用了,但是key还是指向堆中的ThreadLocal对象的,是不会回收的,如果Key使用弱引用:使用弱引用作为Entry的Key,可以多一层保障:弱引用ThreadLocal不会轻易内存泄漏,对应的value在下一次ThreadLocalMap调用set,get,remove的时候会被清除。但是虽然说在我们下次调用的时候会去清除过期Entry,但也是可能发生内存泄漏,如果说不调用threadlocal的get、set方法呢,那这个key为null的value就永远不能回收掉了,额也不是永远吧,当线程结束也就回收掉了,但如果说这个线程是线程池中的核心线程,线程不会销毁,那这个value就不会回收,所以在使用ThreadLocal时候要配合remove去删除不用的entry。
ThreadLocal使用场景:
















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









