






刷完 leetcode hot对map做一些总结和记录,有不对的地方欢迎大家指正~
hash方法,也叫散列方法,是按关键词编址的一项技术,以给定关键词k为自变量,通过某种函数关系h(k)直接计算出函数值,这个值被解释为存放以k为关键词记录的存储单元的地址。
散列函数h()通常要将变化范围很大并且其中又有些十分靠近的关键词k尽可能地 “ 混杂搅乱 ” ,从而使函数值h(k)尽可能地 " 散开 "。
散列方法的核心是
1.散列函数
对典型文件所做广泛的实验表明,有两类散列函数相当好,一类是以除法为基础(如同余), 另一类是以乘法为基础。
2.冲突消解方法(冲突是指,输入不同的关键词k,得到了相同的函数值)
两种常用的解决冲突的方法:
1.拉链法(开散列法),允许某些散列地址可以被多个关键词共享,在Java中, HashMap使用链表来解决碰撞问题,当碰撞发生了,对象将会存储在链表的下一个节点中。hashMap在每个链表节点存储键值对对象,以及指向下一个节点。
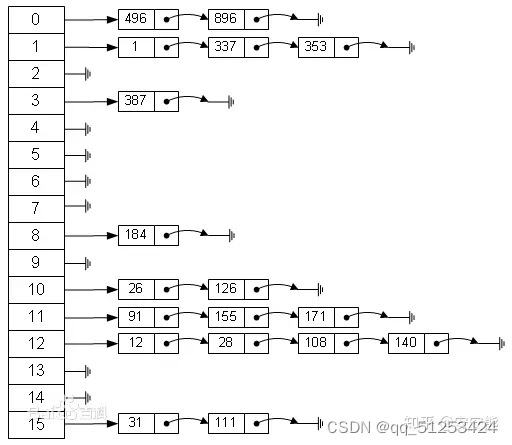
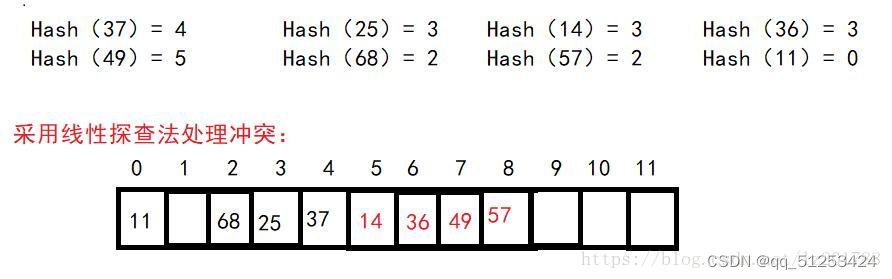
2.线性探查法(开地址法),该方法不建立链表,发生碰撞时,对以h(k)为基地址,按照固定的检索次序,直到找到一个空缺位置。
unordered_map 和 map 是 C++ 标准库中的两种关联容器,它们都用于存储键值对数据。它们的主要区别在于底层实现和性能特点。
1.底层实现:map 是基于红黑树(Red-Black Tree)实现的平衡二叉搜索树,而 unordered_map 则是基于哈希表(Hash Table)实现的。
2.排序:map 内部的元素默认按照键的升序进行排序,因为基于红黑树的特性使得元素在插入时就按照排序规则进行了调整。而 unordered_map 不对元素进行排序,元素在哈希表中根据哈希值进行存储。
3.查找操作:map 的查找操作的时间复杂度为 O(log n),其中 n 是元素的数量。由于红黑树的特性,查找操作的效率较高。unordered_map 的查找操作的平均时间复杂度为 O(1),但是最坏情况下会达到 O(n),其中 n 是桶的数量。哈希表的查找效率取决于哈希函数和桶的数量,当哈希函数出现冲突时,查找操作的效率会降低。
4.插入和删除操作:map 的插入和删除操作的时间复杂度为 O(log n),而 unordered_map 的插入和删除操作的平均时间复杂度也为 O(1),最坏情况下为 O(n),其中 n 是桶的数量。
5.内存占用:map 由于使用红黑树,需要存储额外的指针和颜色信息,因此通常比 unordered_map 占用更多的内存空间。















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









